In the field of time series analysis, step classification plays a critical role in interpreting sequential data by assigning class labels to each time step. This study presents a comprehensive benchmark of 25 machine learning models trained on five distinct datasets aimed at improving time series step classification accuracy. We evaluated each model's performance using four key metrics: accuracy, precision, recall, and F1-score. Our analysis provides insights into the effectiveness of various modeling approaches across different types of time series data, highlighting the strengths and limitations of each model. The results indicate significant variations in model performance, underscoring the importance of tailored model selection based on specific characteristics of the dataset and the classification task. This study not only guides practitioners in choosing appropriate models for time series step classification but also contributes to the ongoing discourse on methodological advancements in time series analysis.
| dataset | # of series | # classes | # features | min series length | max series length | time frequency | source link |
|---|---|---|---|---|---|---|---|
| har70plus | 18 | 7 | 6 | 871 | 1536 | OTHER | link |
| hmm_continuous | 500 | 4 | 3 | 50 | 300 | OTHER | synthetic |
| multi_frequency_sinusoidal | 100 | 5 | 2 | 109 | 499 | OTHER | synthetic |
| occupancy_detection | 1 | 2 | 5 | 20560 | 20560 | SECONDLY | link |
| pamap2 | 9 | 12 | 31 | 64 | 2725 | OTHER | link |
The HAR70 and PAMAP2 datasets are an aggregated version of the datasets from the UCI Machine Learning Repository. Data were mean aggregated to create a dataset with fewer time steps.
The datasets repository is available here
Our benchmarking study on time series step classification evaluates a diverse array of models, which we have categorized into two main types: Machine Learning (ML) models and Neural Network models. Each model is assessed individually to understand its specific performance characteristics and suitability for different types of time series data.
This category includes 17 ML models, each selected for its unique strengths in pattern recognition and handling of sequential dependencies within time series data. These models range from robust ensemble methods to basic regression techniques, providing a comprehensive overview of traditional machine learning approaches in time series classification.
Examples of models in this category include: Random Forest, K-Nearest Neighbors and Logistic Regression
Comprising 7 models, this category features advanced neural network architectures that excel in capturing intricate patterns and long-range dependencies in data through deep learning techniques. These models are optimized for handling large datasets and complex classification tasks that might be challenging for traditional ML models.
Examples of models in this category include: LSTM and CNN
Additionally, our study includes the Distance Profile model, which stands apart from the conventional categories. This model employs a technique based on computing the distances between time series data points, providing a unique approach to classification that differs from typical machine learning or neural network methods. For more information on distance profile, checkout the Distance Profile for Time-Step Classification in Time Series Analysis publication.
Each model, regardless of its category, is evaluated on its own merits across various datasets to pinpoint the most effective approaches for time series step classification. We have averaged the performance metrics for each model across all datasets. This consolidated data is presented in a heat map, where models are listed on the y-axis and the metrics—accuracy, precision, recall, and F1-score—on the x-axis. The values in the table represent the average of each metric for a model across all datasets, providing a clear, visual comparison of how each model performs generally in time series step classification. This method allows us to succinctly demonstrate the overall performance trends and identify which models consistently deliver the best results across various conditions.
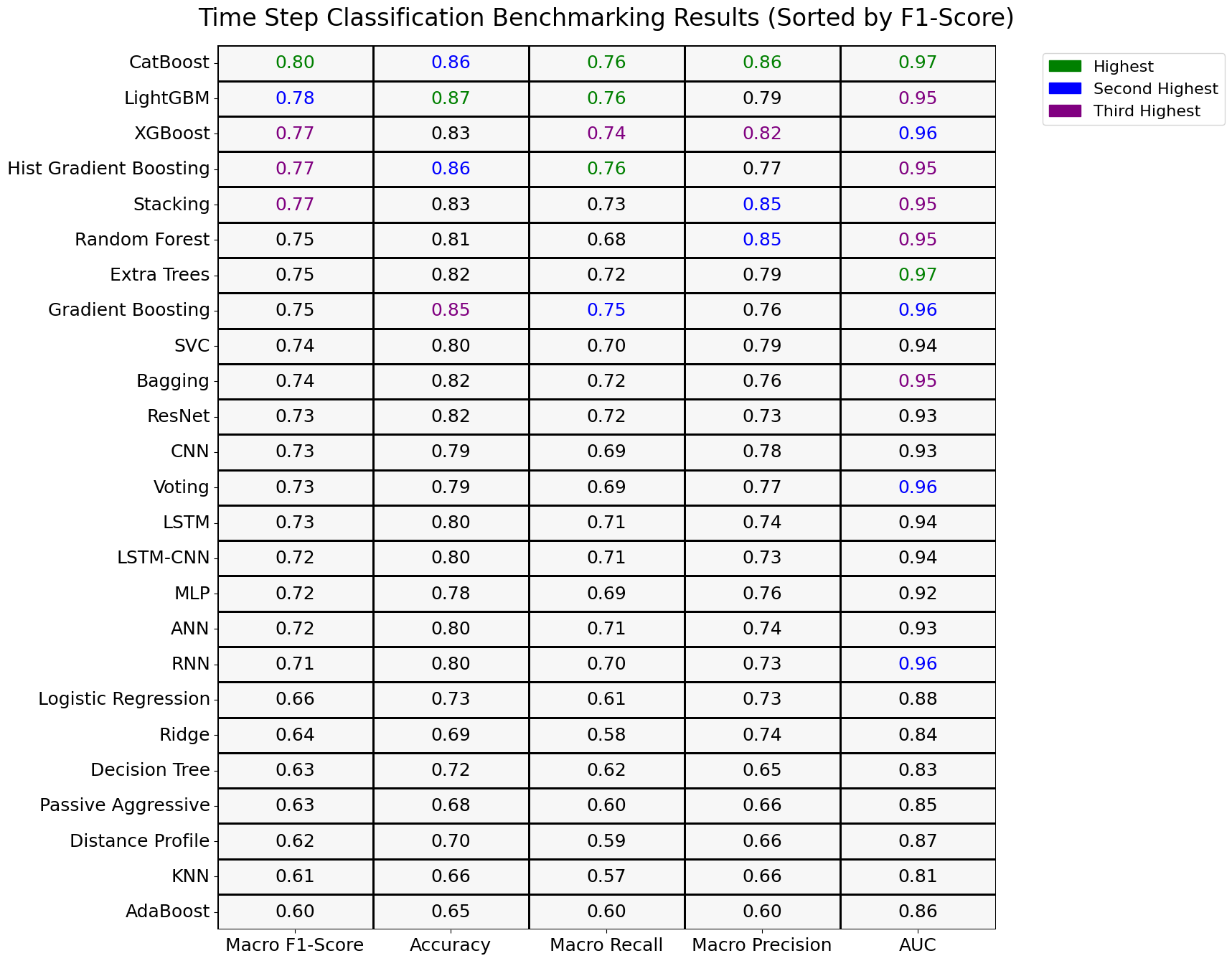
Boosting algorithms and advanced ensemble methods generally perform exceptionally well in the task of time series step classification. The top performers include:
• CatBoost (0.80): Excels in managing complex features and imbalanced datasets, consistently delivering high performance.
• LightGBM (0.78): Known for its efficiency and accuracy, especially in large datasets, with strong overfitting prevention.
• Hist Gradient Boosting (0.77): A powerful algorithm that builds on the strength of traditional gradient boosting by optimizing performance with histogram-based methods.
• XGBoost (0.77): Offers robustness and scalability, making it an ideal choice for handling large datasets and complex tasks.
• Stacking (0.77): Combines multiple models to improve prediction accuracy, performing strongly in time series classification.
These models show good F1-scores but are not at the very top. They are reliable and can be considered for use cases where the top performers might be computationally expensive or overfit:
• Gradient Boosting (0.75): A solid model that performs well in a variety of conditions.
• Extra Trees (0.75) and Random Forest (0.75): These ensemble models provide robust performance, benefiting from their ability to reduce prediction variance.
These models perform moderately well and may serve as baselines or options when computational simplicity is desired:
• Bagging (0.74) and SVC (0.74): Both provide reasonable performance, though not as strong as the top models.
• CNN, RNN, and LSTM (all 0.73): Neural networks tailored for sequential data, performing moderately well in this context.
• Voting (0.73): A basic ensemble method that combines predictions from multiple models, offering solid but average results.
• MLP, ANN, and LSTM-CNN (all 0.72): These neural networks exhibit potential but may require additional tuning to excel in time series step classification.
These models have lower F1-scores and might need substantial tuning or are inherently less suitable for time series step classification:
• Logistic Regression (0.66), Ridge (0.64), and Decision Tree (0.63): These simpler models struggle to capture the complex temporal dependencies in time series data.
• Passive Aggressive (0.63) and Distance Profile (0.62): These models perform less effectively, likely due to their sensitivity to noise and outliers in the dataset.
• KNN (0.61): Its performance is hindered by high dimensionality and noise, which are common in time series data.
• AdaBoost (0.60): Despite being a boosting algorithm, it underperforms, likely due to its sensitivity to noise and imbalanced datasets.
Our benchmarking study has provided a comprehensive evaluation of 25 different models across four diverse datasets, focusing on the task of time series step classification. The results highlight the general efficacy of boosting algorithms—specifically CatBoost, LightGBM, and XGBoost—in managing the complexities associated with time series data, with the notable exception of AdaBoost, which did not perform as well.
The table visualization of average accuracy, precision, recall, and F1-score across all models and datasets has offered a clear and succinct comparison, underscoring the strengths and potential areas for improvement in each model. This analysis not only assists in identifying the most suitable models for specific types of time series classification tasks but also sheds light on the broader applicability of machine learning techniques in this evolving field.
As we continue to advance our understanding of time series analysis, it is crucial to consider not just the accuracy but also the computational efficiency and practical applicability of models in real-world scenarios. Future studies may explore the integration of more complex neural network architectures or the development of hybrid models that can leverage the strengths of both traditional machine learning and neural networks to further enhance classification performance.
In conclusion, this study serves as a valuable resource for researchers and practitioners in selecting the right models for their specific needs, ultimately contributing to more effective and efficient time series analysis and classification.

