This research proposes a system that applies the LLMKnowledge2[1] framework to streamline the academic paper survey process for researchers and enable multifaceted analysis. Specifically, it implements a practical solution that automatically extracts essential research elements such as "novelty," "effectiveness," and "reliability" from a large number of academic papers and allows for their comparison and analysis in a structured format.
The core output of our system is the Knowledge Matrix, which organizes extracted information from multiple papers in a structured format, enabling researchers to efficiently compare and analyze papers across various dimensions.
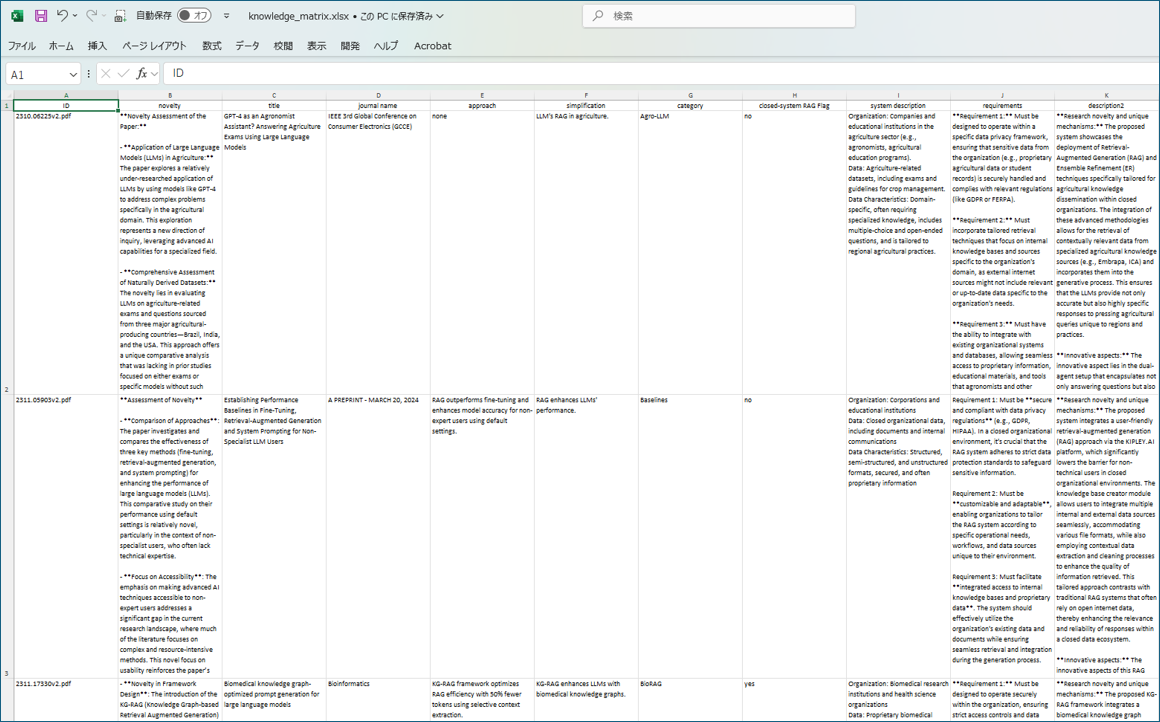
Figure 1: Knowledge Matrix - A structured representation of information extracted from multiple papers, with rows representing papers and columns representing different analytical perspectives
You can download this file from the following URL.
https://app.path-finder.jp/knowledge_matrix.xlsx
In this research, we developed a specialized application system for paper surveys based on the LLMKnowledge2 framework. This system streamlines the entire process from processing paper PDFs to information extraction and result display. The system consists of five main components that work together to automate and enhance the paper survey process. The detailed architecture and implementation of these components are described in Section 5.
In the evaluation experiment, we confirmed that the system could complete the processing of 11 types of knowledge prompts for 61 papers (a total of 671 tasks) in about 51 minutes. This achieves more than 100 times the efficiency compared to equivalent manual work.
Through this paper, readers can gain the following specific values:
Paper Survey Efficiency Methods: Learn how to efficiently extract information from a large number of papers and significantly reduce the time required for research surveys
Essential Research Element Extraction Techniques: Acquire effective prompt design techniques for automatically extracting abstract research elements such as "novelty," "effectiveness," and "reliability"
Multifaceted Analysis Approaches: Understand structured methods for comparing and analyzing multiple papers from various perspectives
Practical Applications of LLMKnowledge2: Learn specific implementation methods and settings for utilizing the LLMKnowledge2 framework for research support
Research Process Optimization: Gain practical approaches to improve the overall efficiency of research activities
This paper is structured according to four core questions based on Ready Tensor's evaluation criteria:
Each part is designed to clearly answer the corresponding core question, allowing readers to efficiently access the information they need.
In academic research, surveying related papers is an important process that forms the foundation of research. However, this task faces many challenges:
The number of papers published in the AI/ML field has increased explosively. According to statistics from the Computer Science (CS) category on arXiv, the number of papers in 2015 was about 17,577, but has increased significantly by 2023[2]. This increasing trend is also seen in AI-related subcategories (cs.AI, cs.CL, cs.CV, cs.LG, cs.NE).
Under these circumstances, it has become physically impossible due to time constraints to read all relevant papers in detail.
In conventional paper surveys, researchers need to read papers one by one, understand their content, and extract and organize important information. This task requires a significant amount of time and effort:
In particular, it is not easy to systematically extract essential research elements such as "novelty," "effectiveness," and "reliability" from multiple papers. Additionally, comparing and analyzing the extracted information requires further effort.
Manual paper surveys face the following consistency and structuring challenges:
These challenges reduce the quality and efficiency of paper surveys, affecting the overall productivity of research activities.
Existing approaches to support paper surveys have the following limitations:
Common literature management tools support the organization and search of papers but have the following limitations:
Large Language Models (LLMs) expand the possibilities for paper understanding and information extraction, but effective utilization faces the following challenges:
While these existing approaches have their respective values, they are insufficient as integrated solutions that streamline the entire paper survey process for researchers and enable multifaceted analysis.
This research aims to solve the following specific problems:
Efficiency in Information Extraction: Developing methods to efficiently extract essential research elements such as "novelty," "effectiveness," and "reliability" from a large number of papers
Achieving Consistency and Structure: Building mechanisms to structure extracted information with consistent criteria, facilitating comparison and analysis
Supporting Multifaceted Analysis: Providing a flexible framework that allows papers to be analyzed from various perspectives
Saving Researchers' Time: Significantly reducing the time and effort required for paper surveys, contributing to the efficiency of research activities
Effective Utilization of LLMs: Establishing appropriate prompt design and processing pipelines to maximize the capabilities of LLMs
By solving these problems, researchers will be able to efficiently extract information from a large number of papers and gain deeper insights.
We clearly define the application scope and limitations of the system proposed in this research:
It is important to utilize this system appropriately with an understanding of these application scopes and limitations.
The paper survey system applying LLMKnowledge2 proposed in this research has a significant impact on research efficiency.
The evaluation experiment results confirmed that the system could complete the processing of 11 types of knowledge prompts for 61 papers (a total of 671 tasks) in about 51 minutes. This represents a significant improvement in both time efficiency and processing capacity:
Time Efficiency:
Processing Capacity:
This dramatic improvement liberates researchers' valuable time for more creative activities and enables more comprehensive literature surveys, particularly valuable in:
The system streamlines the paper survey workflow:
These efficiencies significantly reduce the workload of paper surveys for researchers, allowing them to focus on the essential aspects of research.
The system not only saves time but also contributes to improving research quality.
In conventional paper surveys, if analysis from a new perspective becomes necessary after extracting information from a specific perspective, papers need to be re-read. This is a very labor-intensive task. While conducting research is important for researchers, so is getting sleep, eating good food, playing with children, and above all, cherishing their partners.
With our system, new perspectives for information extraction can be applied to already processed papers simply by adding knowledge prompts. For example:
This feature allows researchers to analyze papers from various perspectives and gain deeper insights. A significant advantage is the flexibility to respond even when analysis from initially unanticipated perspectives becomes necessary.
In manual paper surveys, fatigue or subjective judgment may compromise the consistency of information extraction. Especially when processing a large number of papers over an extended period, extraction criteria may change between early and later papers.
With our system, information can be extracted from all papers with consistent criteria by using the same knowledge prompts. This enables fair comparison between papers.
Additionally, by specifying the output format through knowledge prompts, extracted information is obtained in a structured format. This facilitates subsequent analysis work, enabling advanced analysis utilizing features such as Excel filtering and pivot tables. While inwardly sighing "Excel again...", this green spreadsheet software is what researchers ultimately rely on in the late night. After a love-hate relationship, many researchers whisper in front of pivot tables, "In the end, I only have you."
In manual paper surveys, there is a risk of overlooking important information. In particular, fatigue from long reading sessions or bias from preconceptions may have an impact.
With our system, information is extracted based on explicitly defined knowledge prompts, allowing all papers to be processed with consistent criteria. This reduces the risk of overlooking important information.
The system makes the following contributions to the research community as a whole:
In paper surveys within research groups, task distribution among members and integration of results are challenges. In particular, integration becomes difficult when extraction criteria or formats differ among members.
With our system, consistent information extraction within the group is possible by using a common set of knowledge prompts. Additionally, sharing results in a unified format called knowledge matrix promotes efficient knowledge sharing and discussion within the group.
Furthermore, collaborative paper analysis leveraging diverse expertise is possible by having each member add knowledge prompts from their own perspectives.
In conventional paper surveys, extracted information is often fixed in the form of papers or reports, making re-analysis from new perspectives or comparison with new papers difficult.
With our system, extracted information is accumulated in a structured format in the database, enabling continuous utilization and expansion. For example:
Additionally, accumulated survey results can be utilized for knowledge sharing within the research group and education of new members. In particular, providing information in a structured format is very useful for new members who want to quickly grasp an overview of a specific research area.
In paper surveys using this system, transparency and reproducibility of the survey process are improved by explicitly showing the knowledge prompts used. This makes it easier for other researchers to verify results using the same method or apply it to different datasets.
To concretely demonstrate the value of this system, we present the following use cases and application scenarios:
A case where a researcher entering a new research field efficiently grasps the overview and latest trends of that field:
Effect: Work that normally takes 2-3 weeks is completed in 1-2 days, promoting systematic understanding of the field
A case of analyzing research trends for a specific technology (e.g., RAG systems):
Effect: Comprehensive trend analysis can be efficiently conducted, contributing to research strategy planning
A case of creating a related research section for a paper:
Effect: The time to create the related research section is significantly reduced, enabling a more comprehensive and accurate review
A case of identifying research gaps for research proposals or grant applications:
Effect: Systematic identification of research opportunities becomes possible, improving the quality and uniqueness of research proposals
These use cases demonstrate that the system can provide value at various stages of the research process. Researchers can customize the system according to their needs to improve the efficiency and quality of research activities.
LLMKnowledge2 is a framework for efficiently extracting structured knowledge from unstructured document data. This framework aims to utilize the capabilities of Large Language Models (LLMs) to extract specific knowledge from various formats of documents and provide it in a structured format.
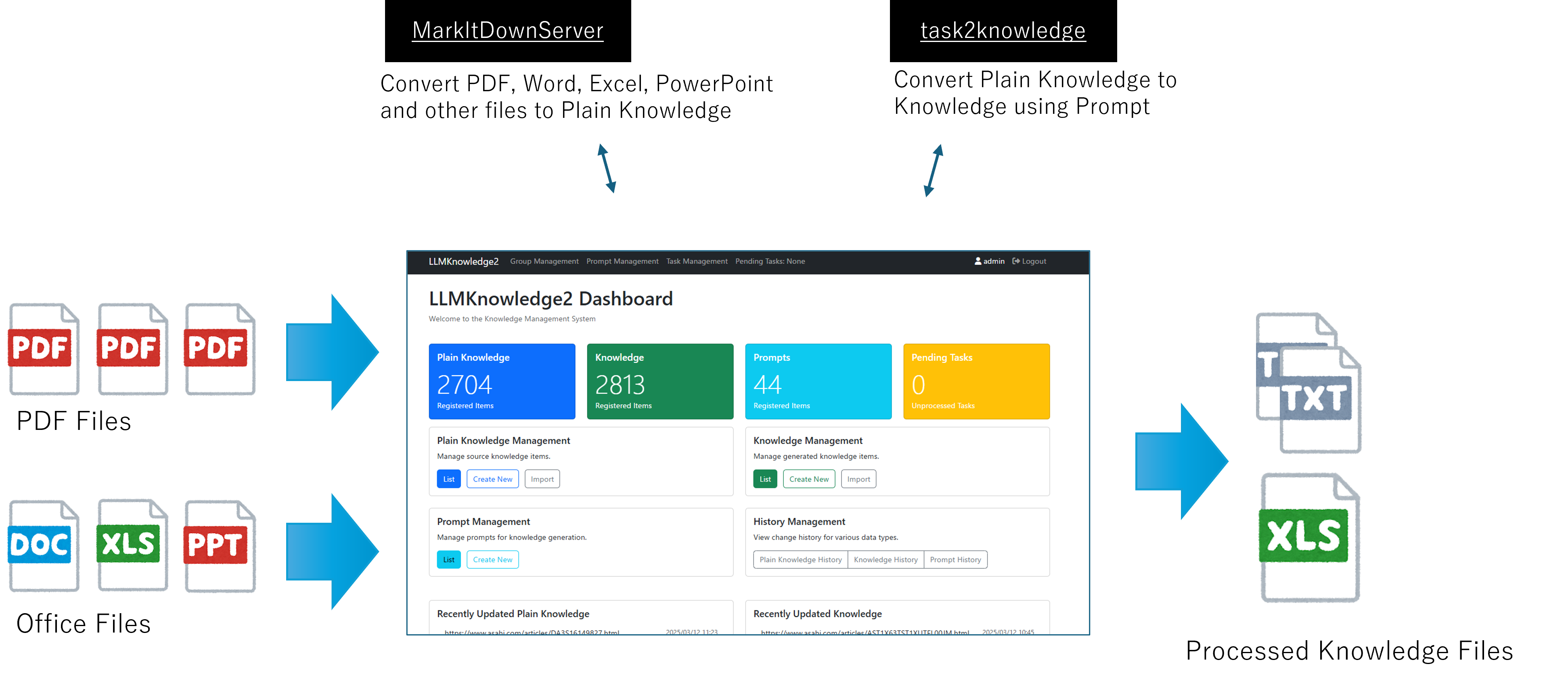
Figure 4.1 shows the basic architecture of LLMKnowledge2. This framework provides a conceptual model for knowledge extraction from documents, consisting of five main components that work together to transform unstructured document data into structured knowledge. Each component represents a logical function rather than a specific implementation, allowing for flexible adaptation to various use cases.
The key features of LLMKnowledge2 are as follows:
Provides functionality to flexibly design and improve prompts for extracting specific knowledge from documents. Knowledge prompts consist of the following elements:
Knowledge prompts can be optimized for specific knowledge extraction tasks and are managed as reusable components.
Efficiently processes large amounts of data by processing multiple documents in parallel. The task management module provides the following functions:
This parallel processing mechanism allows efficient processing of hundreds to thousands of tasks.
Can process various formats of documents including PDF, Word, Excel, PowerPoint, various text files, and web pages. The document processing module provides the following functions:
This enables consistent knowledge extraction for different formats of documents.
Various generative AI engines such as OpenAI (GPT-4.5, etc.), Anthropic (Claude, etc.), and local LLMs (Llama 3, etc.) can be selected according to the situation. The generative AI engine integration module provides the following functions:
This allows selection of the optimal engine according to requirements such as cost, performance, and availability.
Provides functionality to group and manage multiple documents and the knowledge prompts that process them. Knowledge groups bring the following benefits:
This enables efficient management and processing of document sets related to specific themes or purposes.
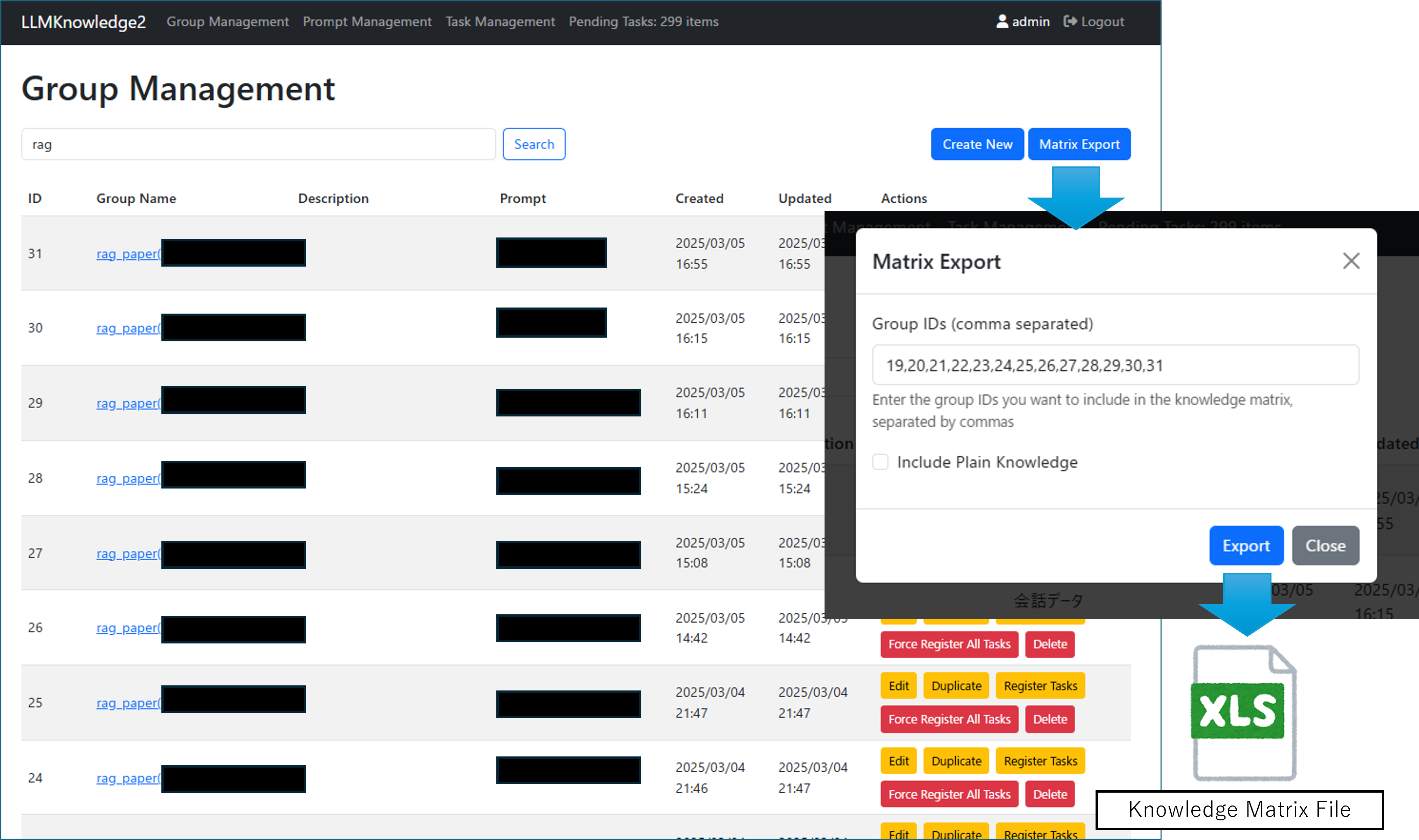
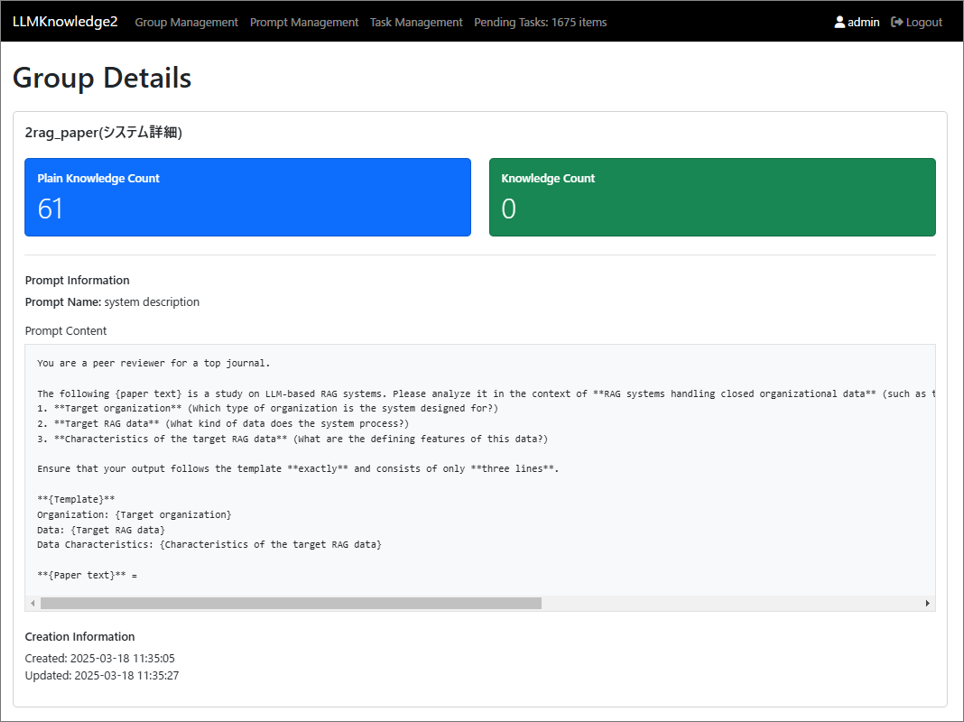
Figure 4.2: Knowledge Groups and How to Export Knowledge Matrix
Based on the conceptual framework described in Section 4, we implemented a concrete system for paper surveys with the following specific components:
Paper PDF Processing Module:
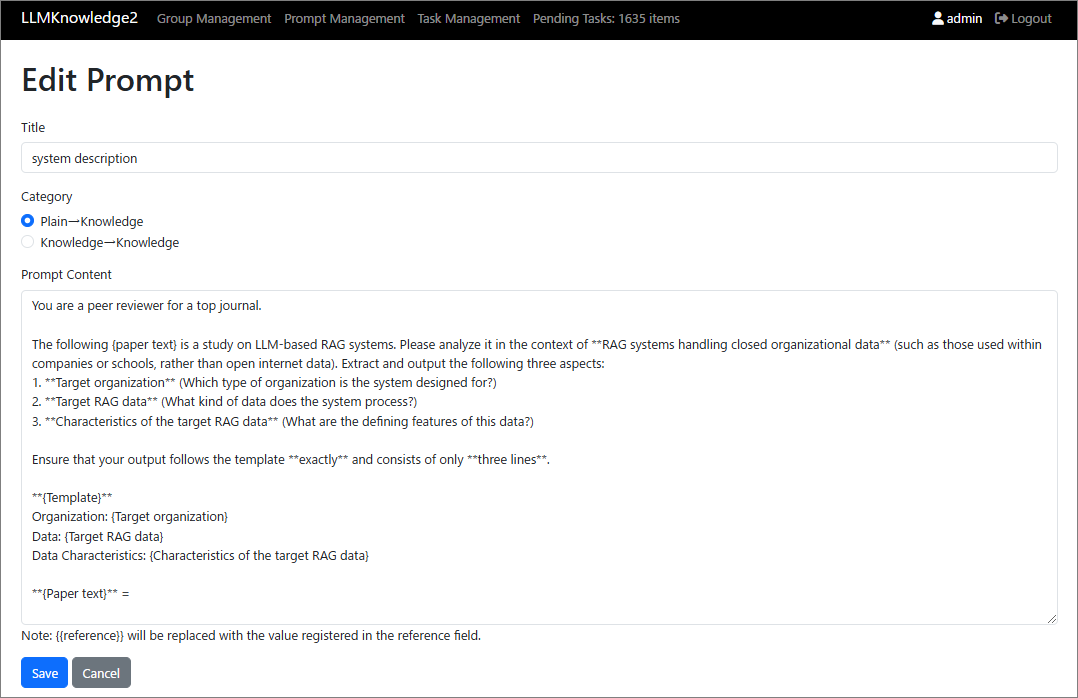
Knowledge Prompt Management Module:
Knowledge Group Management Module:
Knowledge Matrix Generation Module:
Generative AI Engine Integration Module:
For detailed implementation, refer to the following GitHub repositories:
ArXiv-Downloader was used for paper collection, efficiently collecting 61 papers.
Results of applying 11 types of knowledge prompts to 61 papers (a total of 671 tasks):
These results demonstrate that the system can significantly streamline the paper survey process for researchers while maintaining high accuracy.
The current implementation faces specific technical limitations, and for each, we propose concrete improvement directions:
| Technical Limitation | Specific Issue | Improvement Direction |
|---|---|---|
| Extraction Accuracy | Difficulty with complex tables and figures in PDFs | Implement specialized OCR and image analysis modules |
| Limited accuracy for highly specialized terminology | Develop domain-specific fine-tuning for LLMs | |
| Generative AI Constraints | Token limit restrictions (context window) | Implement chunk-based processing with context preservation |
| Hallucination in synthesizing information | Develop fact-checking mechanisms against original text | |
| System Performance | Processing bottlenecks with large paper sets | Implement distributed processing architecture |
| Memory constraints with complex PDFs | Optimize memory management and implement streaming processing |
This system is not a substitute for researchers' deep understanding of papers, but a tool to support efficient information extraction and multifaceted analysis.
The system setup and basic usage are detailed in the following GitHub repository:
The basic workflow is as follows:
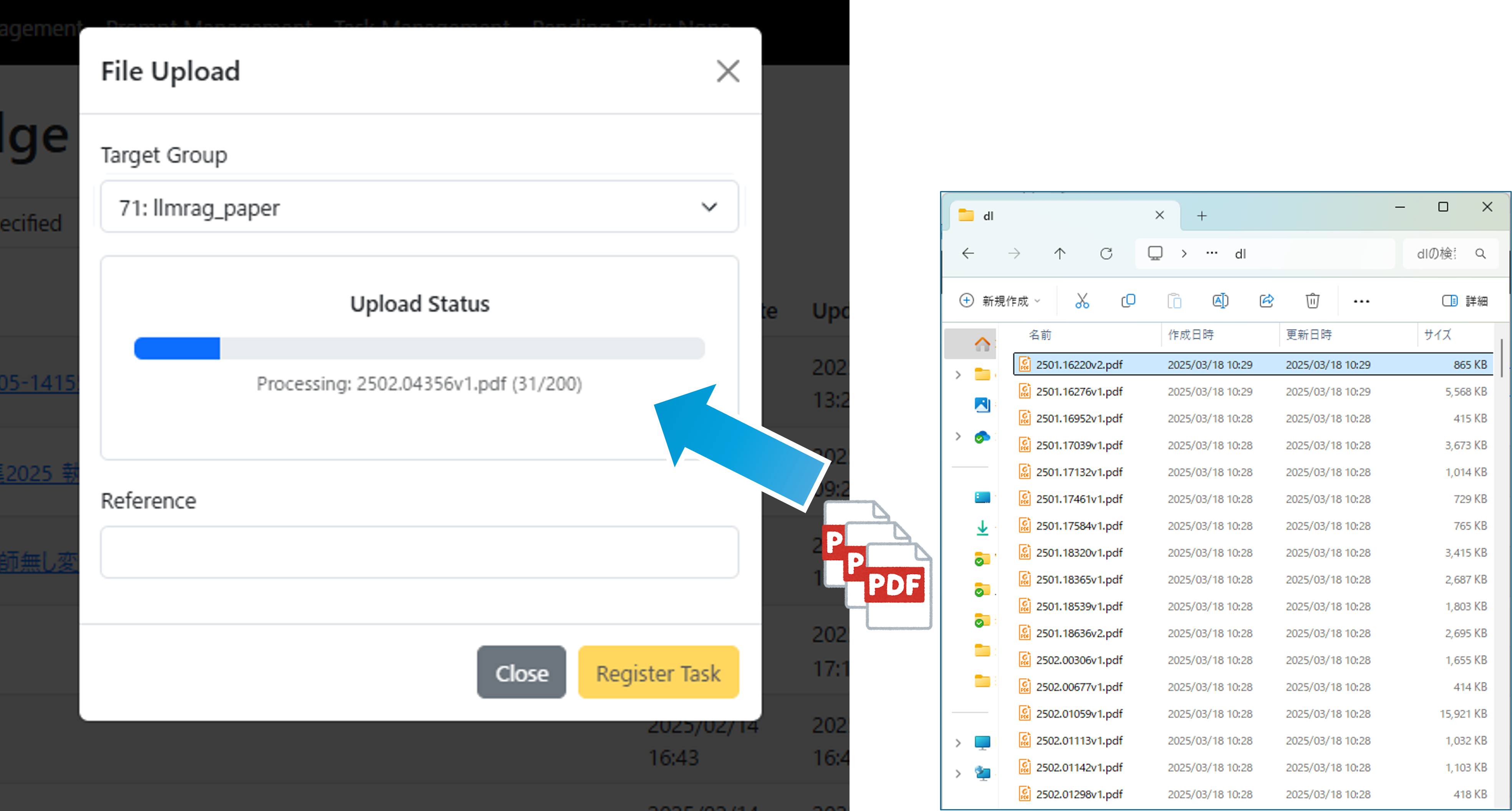
The major application scenarios of this system are shown below. For detailed use cases, please refer to Section 3 "Specific Use Cases and Application Scenarios".
Here we focus on the technical implementation aspects of these scenarios:
Technical Implementation for New Research Field Entry
Technical Implementation for Research Trend Analysis
Key points for effective prompt design:
In this research, we developed a system that applies the LLMKnowledge2 framework to streamline the paper survey process for researchers. In the evaluation experiment, we achieved about 394 times the efficiency compared to manual work, successfully liberating researchers' time for creative activities.
By appropriately utilizing this system, researchers can efficiently extract information from a large number of papers and gain deeper insights.
This research proposes the LLMKnowledge2 framework as an evolving system with significant potential for further development, implements its application through system development, and discusses evaluation outcomes. The author, whose research interests span natural language processing, system development, and generative AI, is actively seeking collaboration partners (individuals and organizations) to expand this research. If you are interested in collaborative research opportunities or can recommend suitable journals or academic publications for this work, please feel free to reach out. Your expertise, insights, and suggestions regarding potential publication venues would be highly valuable in advancing this research.
[1] readytensor.ai, "LLMKnowledge2: A Framework for Automated Knowledge Extraction and RAG Integration", https://app.readytensor.ai/publications/llmknowledge2-a-framework-for-automated-knowledge-extraction-and-rag-integration-wGUpD2eWWOpg
[2] arXiv.org, "Computer Science (cs) Statistics," https://arxiv.org/archive/cs, accessed March 2025.
[3] MarkItDown, https://github.com/microsoft/markitdown
