Introduction
Text-to-Image synthesis comes under Computer Vision and NLP. It involves converting a text input into a representation, say, a latent or feature vector and using this representation to generate an image matching the textual description.
GANs, or Generative Adversarial Networks, are an approach to generative modeling using Deep Learning methods. The GAN framework consists of two entities: Generator and Discriminator. The generator produces images and tries to trick the discriminator that the generated images are real. The discriminator’s job is to catch or detect the fake images generated. GANs are one of the best ways for the task of Text-to-Image synthesis. The quality of the images generated by GANs is better than one of the other models. There are many types of GANs implemented for this task, for instance, DC-GAN, RC-GAN, AttnGAN, etc. For this project, DC-GAN (Deep Convolutional Generative Adversarial Networks) was choosen. Our contribution in this work is utilizing an effective GAN architecture and training process. We used the Oxford-102 Flowers datasets.
Problem Statement
Developing a Text to Image synthesis model using DC-GAN. The model should capture the semantic meaning of text descriptions, or prompt, and generate realistic images. The model should handle a variety of text descriptions.
Related work
Reed et al. [1] proposed a method called LeicaGAN, consisting of a textual-visual co-embedding network (TVE), a multiple priors aggregation network (MPA) and a cascaded attentive generator (CAG). The text encoder was a pre-trained Bi-directional LSTM and the visual encoder was built upon the Inception-v3 model. The MPA network fused the sentence level embeddings. This acted as an input in the CAG, where an attention block, two residual blocks, an upsampling block and a convolution layer make up the generator. Word and Sentence-context features were produced. Two adversarial losses were employed: a visual realism adversarial loss to ensure that the generators generate visually realistic images and a text-image pair-aware adversarial loss to guarantee the semantic consistency between the input text and the generated image. For effectiveness LeicaGAN was compared with AttnGAN. CUB and Oxford-102 datasets were used and evaluation was done based on the Inception Score. LeicaGAN outperformed AttnGAN, on both the datasets.
Qiao et al.[2] proposed ControlGAN. For this, they introduced a word-level spatial and channel-wise attention-driven generator that could disentangle different visual attributes. Also, they proposed a word-level discriminator. The backbone architecture they used was AttnGAN and the text encoder was a pre-trained bi directional RNN. Conditioning Augmentation was applied. The generator exploited the attention mechanism via incorporating a spatial attention module and the channel-wise attention module. The spatial attention module dealt with words with individual spatial locations. The model was experimented on CUB and MS COCO datasets. The model proposed was compared with AttnGAN and StackGAN++ and the performance metrics were Inception Score, R-precision and L2 Error. ControlGAN gave the best results among the three for the CUB dataset.Inception Score = 4.58 ₫ 0.09, Top-1 Acc%) = 69.33 $ 3.23, L2 error = 0.18). For the COCO dataset, AttnGAN was the best in Inception Score and Top-1 Acc(%), but ControlGAN had the lowest L2 error, i.e., 0.17.
Li et al. [3] proposed the Self-Attention Generative Adversarial Network (SAGAN). This compared to convolutional GANs, helps with modeling long range, multi-level dependencies across image regions. Due to the self-attention, the generator can draw images in which fine details at every location are carefully coordinated with fine details in distant portions of the image. Moreover, the discriminator can also more accurately enforce complicated geometric constraints on the global image structure. Spectral Normalisation was used in the generator and discriminator. Spectral normalization in the generator can prevent the escalation of parameter magnitudes and avoid unusual gradients. The experiment was done on the ILSVRC 2012 dataset. The evaluation metrics chosen were Inception Score and Fréchet Inception distance. The model was compared with AC-GAN and SNGAN-projection, in which SAGAN performed best, having Inception score of 52.52 and Fréchet Inception distance of 18.65.
Zhang et al. [4] proposed a StackGAN model. The model is built in two stages: Stage 1 GAN giving Low Resolution images and Stage 2 GAN giving High resolution images. The model first processes the text input and generates corresponding text embeddings to feed into the generative adversarial networks. The model included a text encoder and decoder implemented with a word-level bidirectional recurrent neural network (RNN) consisting of two long short-term memory (LSTM). The generator and discriminator receive a conditioning variable. Dataset used was COCO. The pre-trained StackGAN model has decent performance on generating images from a text input that is similar to its training set, although, when the input contains multiple objects, StackGan fails to generate the correct number of instances with clear boundaries and spatial relationships.
Fu and Hou [5] implemented DC-GAN conditioned on text features encoded by a hybrid character-level
convolutional recurrent neural network. In the generator, a text query was encoded. The description embedding was compressed using a fully connected layer followed by LeakyReLU as the activation function. This was then concatenated with the noise. The discriminator consisted of several layers of strides-2 convolution with spatial batch normalization followed by LeakyReLU. The experiment was done on the CUB and Oxford-102 datasets. The GAN baseline was compared with GAN-CLS with image-text matching discriminator, GAN-INT learned with text manifold interpolation and GAN-INT-CLS which combined both.
Methodology
Base model: DC-GAN
This model uses the deep convolutional generative adversarial networks[5] to generate images from text prompts. We can use this model on different categories of images, like: faces, birds, flowers, animals, etc. We have used it on flower images. The model is capable of learning text representations from words and characters automatically using generative and discriminative capabilities. As a deep convolutional model it has many convolutional layers. The base model architecture is shown in the image below.
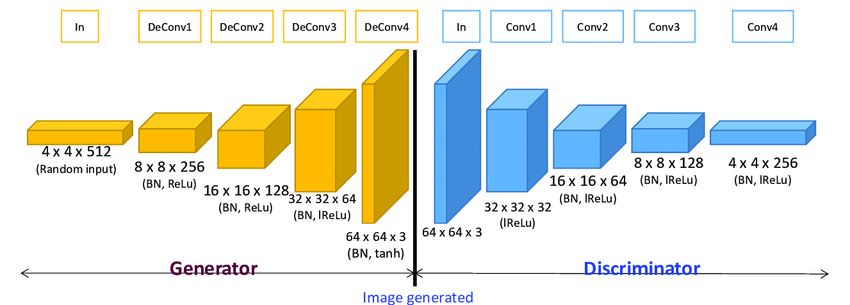
The GAN-CLS algorithm is shown in the image below, which is a matching-aware discriminator. In this approach, the DC-GAN is trained using (text, image) pairs. The discriminator is trained to observe these pairs and judge the pairs as real or fake. The algorithm is shown in the image below.

This is a simple yet powerful and accurate way of creating images from text. We have developed our code using this model as our base model.
Importing Libraries and GloVe Embedding:
The process started with mounting Google Drive with Colab. We imported a few libraries like NumPy, pandas, etc. In order to make our algorithm understand the captions more meaningfully, we need to create embeddings for the same. The term embeddings, means numeric vector representation of words or phrases. They improve the ability of the computer to understand the semantic meaning words/phrases convey to the model. There are many methods available to create the embeddings, some examples are GloVe embedding, gecko embedding, etc. For our project we used GloVe Embedding. It is an unsupervised learning algorithm for obtaining vector representations for words. In the function, the GloVe word embedding file is opened in read mode using UTF-8 encoding. In the iteration of each line in the GloVe word embedding file, the line is split into a list of tokens, the word and the embedding vector is extracted and the embedding vector is converted to a NumPy array. The GloVe model is loaded using 40000 words.
Paths are set up for the training images and captions. Then, we imported packages required to create a GAN system in Python/Keras. We then set the parameters that helped us feed the images with good resolution. While training the model, we get 28 images to preview. At the end, we get 1 image, when we enter the prompt. There are 5 stages involved in the process of generation of images. We explain them in the sub sections below.
Data Pre-processing:
In the data pre-processing step, the images are processed into a binary file. This helped us in quickly accessing, whenever we wanted to use the file. The dimensions of the image are also encoded into the filename of the binary file. Just like the images, the captions are also processed into a binary file. We saved the caption embeddings using NumPy. We used the 64x64, 128x128 pixel image size.
Loading and Combining NumPy
In this section, we prepared our data splits for training and testing. We created a list to store the preprocessed images and a DataFrame to store the captions. We saved some images , caption embeddings and captions for testing. We, then, shuffled the data for the training dataset. Finally, we created the combined dataset of these images and caption_embeddings.
Data Modelling
In this section, we defined the generator and discriminator. In DC-GAN generator and discriminator functions work in minmax approach just like in gaming. Using these two functions the algorithm further comes to a conclusion about which images are correct/appropriate output. We created a function to save the images into a folder. We initialized the generator and discriminator. To see the output from the generator, we add noise with the caption embeddings. A helper function was defined for computing the loss for discriminator and generator. Adam optimizer is used for both the generator and discriminator.
Training
We defined two functions for the training. The training started with 1 epoch, after which we got the weights file for the generator and discriminator. We used the weights for the generator to check the improvement in the output image from the generator. Gradually, we changed the epochs in the training to 10, 100, 200, 500 and 1000 and obtained the updated weights file for all these epochs. The quality of the generated image improved with the increase in the number of epochs.
Generating images using trained model
This section is our testing segment, by using the trained model we generated the images.
Two functions were defined one to save the test images generated by the prompt and another to display the images.
We trained our model for approximately 1800+ epochs and in each epoch nearly 16000+ images were processed with their captions in a randomized way. During the testing, we provided multiple prompts to check the image’s appropriateness. We used three types of prompts:
- Prompts very similar to caption data.
- Prompts created using some combination of words from the embeddings.
- Prompts which are totally random.
The following table shows some prompts and the resulting images for the same.
Results
| Prompt | Image generated |
|---|---|
| Prompts very similar to caption data | |
| the petals on this flower are white with an elaborate pistil. |  |
| a flower that has vivid yellow petals and dark purple stamen |  |
| Prompts created using some combination of words from the embeddings | |
| this is a blue flower with round petals |  |
| the pistil is white and is very noticeable, and the petals are purple. |  |
| Prompts which are totally random | |
| rose |  |
| white flower with yellow stigma |  |
Conclusion
During this study, we were successful in building our first GAN for image generation. As mentioned before, the approach is simple and helps us in understanding the core components of the model. Our model was able to generate 64x64 pixel images as per the text prompt and was able to understand the text prompt fairly well in many cases. Following limitations were encountered:
- The image resolution has a great impact on the time and resources needed for model training and prediction.
- DC-GAN requires more iterations (thousands of epochs) to start showing permissible results.
- The dataset size matters a lot, if we could bring in a bigger dataset, the model will generate more appropriate images and learns well.
- The execution framework/environment is important as it can make the development process simple and quick.
References
-
Reed, S., Akata, Z., Yan, X., Logeswaran, L., Schiele, B., & Lee, H. (2016, June). Generative
adversarial text to image synthesis. In International conference on machine learning (pp. 1060-1069).
PMLR. -
Qiao, T., Zhang, J., Xu, D., & Tao, D. (2019). Learn, imagine and create: Text-to-image generation
from prior knowledge. Advances in neural information processing systems, 32. -
Li, B., Qi, X., Lukasiewicz, T., & Torr, P. (2019). Controllable text-to-image generation. Advances in
Neural Information Processing Systems, 32. -
Zhang, H., Goodfellow, I., Metaxas, D., & Odena, A. (2019, May). Self-attention generative adversarial
networks. In International conference on machine learning (pp. 7354-7363). PMLR. -
Fu, A., & Hou, Y. (2017). Text-to-image generation using multi-instance stackgan. Class Project for
Stanford CS231N: Convolutional Neural Networks for Visual Recognition, Sprint 2017, 225-231.
Explore the Work
Feel free to explore our codebase, experimental results, and detailed learnings. Your engagement and feedback are highly valued as we continue refining and expanding our project. Check out our Colab Notebook.
GloVe Embedding:
For semantic enhancement of captions, we utilized GloVe Embedding.
Project Files and Output:
Explore the generated images and project files on our Google Drive.
Explore our GitHub Link
Team
- Anish Borkar
- Godavarthi Sai Nikhil
Mentor
We extend our sincere gratitude to Dr. Soharab Hossain Shaikh for being our guiding force throughout this journey. His mentorship and insights have been instrumental in the success of our project.
Contact Us
For inquiries, collaboration opportunities, or further information, please feel free to reach out to us:
Godavarthi Sai Nikhil: nikhilgodavarthi9@gmail.com
Anish Borkar: anishborkar73@gmail.com