Abstract:
This project presents an innovative approach to text summarization by integrating audio-
to-text conversion with advanced natural language processing models, BERT and BART.
The system is designed to first transcribe spoken audio into text using state-of-the-art
speech recognition techniques. Following transcription, the text is then summarized using
a combination of BERT (Bidirectional Encoder Representations from Transformers) and
BART (Bidirectional and Auto-Regressive Transformers) models, which are fine-tuned
for the summarization task. The integration of these models provides a robust solution for
extracting concise and relevant information from lengthy audio inputs, making it highly
applicable in domains such as meeting transcription, podcast summarization, and
educational content synthesis. The results demonstrate the effectiveness of leveraging
deep learning models to automate and enhance the summarization process, significantly
improving efficiency and accessibility.
Introduction:
This research uses cutting edge deep learning models to automate the task of
summarizing spoken content[1]. To ensure proper transcription of spoken words, the system first uses cutting-edge speech recognition techniques to turn audio inputs into
text. Following transcription, BERT (Bidirectional Encoder Representations from
Transformers) and BART (Bidirectional and Auto-Regressive Transformers) models are
used to summarize the text[1]. In 2018, Google unveiled BERT, a pre-trained language
model renowned for its capacity to comprehend phrase context through bidirectional
analysis of words[2]. Because of this feature, BERT does especially well in tasks like text
categorization and summarization that call for a profound understanding of language.[1]
BART is a sequence-to-sequence model that was created by Facebook AI in 2020. It
mixes autoregressive and bidirectional features, which makes it ideal for jobs involving
text production and summarization.The integration of these models enables the system to
extract complex contextual data and produce meaningful, cogent summaries.[3] Using
Flask as the backend framework, MongoDB as the database solution, and HTML, CSS,
and JavaScript for the front end, the project is constructed as a full-stack web application.
Users may quickly upload audio, examine the transcribed text, and acquire succinct
summaries using an easy-to-use online interface, all of which contribute to a smooth user
experience[3]. Applications in fields including meeting transcriptions, podcast
summaries, and educational content—where accurate and timely summarizing of
extensive audio content is crucial—are included in the project's scope. Through the
integration of various technologies, the study demonstrates how deep learning may
improve the accuracy and efficiency of text processing operations[1], increasing
accessibility and facilitating better comprehension of information[3].
##Requirement Analysis:
###Functional Requirements:
The uploading and processing of audio files is the first step in the main functionality. It
should be possible for users to submit audio files in WAV and MP3 formats. Speech-to-
text services translate the audio recordings into text after they are uploaded, making it
possible for users to interact with spoken content with ease.[1] The ability to support
several file types ensures wider interoperability, which is an essential feature.Text
summarization is one more important function[2]. The system will generate concise
summaries from the transcription by utilizing advanced models like BERT for abstractive
summarization and BERT for expressive summarizing[3]. To meet a variety of demands,
the application will give users the option to select from a variety of summarizing styles,
including formal, casual, and technical.[3]An other noteworthy aspect is sentiment
analysis. Following the text's summary, the system will use pre-trained models—like
those provided by Hugging Face's sentiment analysis pipeline—to determine the content's
sentiment. By doing so, consumers will gain deeper insights and a better understanding of
the emotional tone of the summarized text.[1]
The system has text translation built in to improve accessibility. Summaries and
sentiment analysis results can be translated into other languages via the Google Translate
API. With the support of this function, a worldwide audience will be able to use the
site.Ensuring ease of use will be largely dependent on the user interface (UI).[4][5] Users
will find it easy to submit audio files, see summaries, and get translations thanks to the
web interface.[5] The design will prioritise ease of use and compatibility with popular
web browsers.[4]Additionally, the project will enable transcription from voice to text
utilising an API similar to Google Speech-to-Text or AssemblyAI. When applicable, this
feature will offer chapter- and category-based transcription in addition to text
transcription of the supplied audio[4].
###Non Functional Requirements:
The system's performance is very important. The program needs to process audio
recordings fast and effectively so that it can produce sentiment analysis and summaries in
a reasonable amount of time. The program must also be scalable, able to process several
requests at once without experiencing any latency or delays.One important non-
functional need is accuracy. The goal of both summarisation models—BERT and
BART—is to provide excellent summaries that capture the essence of the original text.
Comparably, the transcription system needs to accurately translate audio to text,
especially in cases where the audio is clear, and the sentiment analysis needs to
accurately categorise the text's sentiment.
The system will be easy to use, with an intuitive interface that makes it simple for users
to upload files and view results. When an issue occurs, such as with an unsupported file
format or a failed API call, it will handle it gently and give the user helpful error
messages.The application needs to be dependable and have fault tolerance built in. When
something goes wrong, like an unsuccessful API call, it ought to bounce back without
causing too much trouble. To guarantee users can use the system when needed, it should
also have minimal downtime and high availability.Another key priority is security. Using
encryption, the program will safeguard files supplied by users and guarantee secure data
transmission. We'll put in place proper API key management to guard against service
abuse.
The system will function flawlessly on a variety of browsers, including Chrome, Firefox,
and Safari, because it is compatible with numerous platforms. Users that access the
platform via mobile devices will also have a positive user experience thanks to the UI's
responsive design.
###Software Tools:
The program will use JavaScript for interactive parts and HTML/CSS for layout and
design on the front end. Python will be used in the construction of the backend, notably
utilising the Flask framework for web routing and logic. Pre-trained BART and BERT
models will be integrated using the Transformers library for summarisation, and
translations will be handled by the Google Translate API. The AssemblyAI API will offer
services for audio transcription.Hugging Face Transformers for pre-trained BERT and
BART models, as well as a sentiment analysis model from Hugging Face, will be used by
the project as models and APIs. Language translation will be handled by Google
Translate API, while speech-to-text transcription will be taken care of by AssemblyAI
API. Optionally, uploaded files and user data may be stored in a database such as SQLite
or PostgreSQL.
Assumptions and Constarints:
Important presumptions include that users will supply clean audio files so that
transcriptions are correct and that the application will use pre-trained models for
sentiment analysis and summarisation so that no new models need to be taught. One of
the constraints is that speech-to-text and translation features rely on third-party services,
like APIs, whose service limits may have an impact on availability and performance. The
size of the text and audio inputs may also affect how quickly the application runs.An
application for text summarisation and sentiment analysis that is both scalable and
effective can be developed using the requirements analysis as a clear guide.
##System Design:
###HTML:
The standard markup language used to produce the content and structure of web pages is
called HTML. It uses elements (tags) like headings, paragraphs, links, images, and forms
to determine the structure and arrangement of a webpage. Every element serves a distinct
function and helps organise the content so that browsers can display it correctly. The
foundation of your website is HTML, which also lets you layout the user interface of
your application and arrange content and incorporate media.
###CSS:
A style sheet language called CSS is used to manage how HTML elements appear and
are designed on a webpage. It lets you customise your HTML structure using styles for
fonts, colours, spacing, and layout. Making your website both aesthetically pleasing and
easy to use requires CSS. It makes it possible to separate content (HTML) from design,
giving you the freedom to update styles without changing the HTML structure and keep
your website looking and feeling consistent throughout.
###Java Script:
Programming languages like JavaScript allow web pages to include dynamic and
interactive features. It is frequently used to validate forms, handle events (like button
clicks), and work with the Document Object Model (DOM) to update content
dynamically. Additionally, AJAX requests—which allow users to communicate with a
server without refreshing the page—and other client-side actions cannot be implemented
without JavaScript. JavaScript may be used in your text summariser website to handle
user inputs, dynamically change content, and communicate with the backend.
###Flask:
A lightweight web framework for Python called Flask makes it simple and effective to
create web apps.[8] It is a well-liked option for small to medium-sized online applications
because of its versatility and reputation for simplicity[7]. Flask offers capabilities for
handling requests and answers, interacting with databases, and routing (mapping URLs to
functions).[6][7][8] Flask functions as the backend framework in your project, handling
user requests, communicating with the text summarisation model, and sending the output
back to the front end. Because Flask is modular, it's also simple to integrate it with other
services for data storage, such MongoDB.
###MongoDB:
MongoDB is a NoSQL database that stores information in BSON (Binary JSON), a
versatile format like JSON. MongoDB is perfect for applications with changing data
structures because it doesn't require a fixed schema like traditional relational databases
do. It can extend horizontally across numerous servers and is made to handle massive
volumes of data. MongoDB is probably being utilised in your text summariser project to
store logs, summaries, text inputs, and user data. Because of its adaptability, you may
effectively manage and retrieve data, meeting the dynamic requirements of your online
application.
##Model Building:
###BERT:
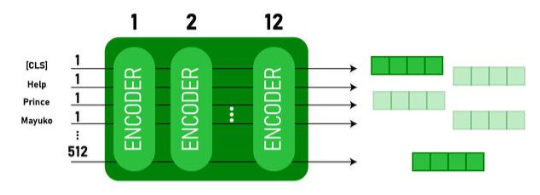
Model Building Process:
Foundation:
Transformers
Vaswani et al. (2017) introduced the Transformer architecture, upon which BERT is
based. By allowing models to handle data sequences (like text) effectively without
relying on recurrent neural networks (RNNs), transformers transformed natural language
processing (NLP). The self-attention mechanism, which enables the model to assess the
relative value of various words in a phrase, independent of their placement, is the
fundamental part of a Transformer.[9][10]
Bidirectional Contextual Understanding:
Traditional models process text unidirectionally (from left to right or from right to left),
such as RNNs or even the Transformer encoder-decoder models.[9] However, BERT is
extremely good at grasping linguistic nuances since it reads the complete string of words
at once and takes the context into account from both sides (bidirectional).
Pre-training:
BERT is pre-trained on a large corpus of text using two main tasks:
Masked Language Model (MLM): During pre-training, 15% of the words in each
sequence are randomly masked. The model then attempts to predict these masked words
based on the context provided by the unmasked words, forcing it to develop a deep
understanding of language.[9][12][11]
Next Sentence Prediction (NSP): BERT is also trained to predict if a given sentence
follows another sentence in the text.[10] This helps the model understand the relationship
between sentences, which is crucial for tasks like question answering and summarization.
Fine-tuning:
After pre-training, BERT can be fine-tuned on specific tasks, such as text summarization,
by adding a task-specific layer on top of the pre-trained model. Fine-tuning adjusts the
model weights slightly to adapt BERT to the new task while retaining its deep contextual
understanding.[11]
How It Works:
BERT analyses the relationships between every word in a sentence at the same time while
processing the text as a whole. As a result, BERT performs better on tasks like
summarisation, named entity recognition, and sentiment analysis by fully capturing a
word's context. Because of its bidirectional comprehension, BERT, for instance, is able to
recognise that the word "bank" refers to a financial institution and not the side of a river
in the statement "The bank will not open today due to the flood."[9][10][11][12]
###BART:
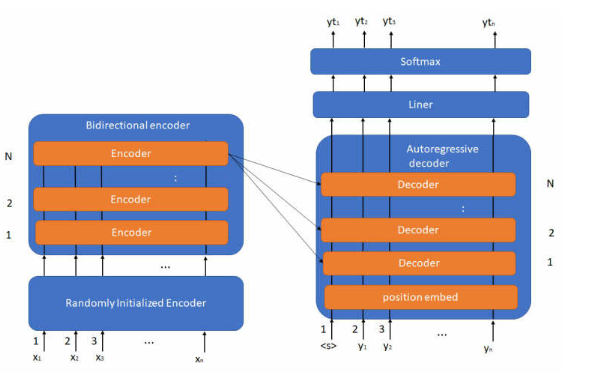
Model Building Process:
Foundation:
Transformer Architecture
BART is built on the Transformer architecture, just like BERT. Nevertheless, BART
combines an autoregressive decoder, akin to the one found in GPT (Generative Pre-
trained Transformer), with the bidirectional encoder of BERT[10]. Because of this
combination, BART performs exceptionally well in text creation tasks like translation and
summarisation.
Bidirectional Encoder:
The encoder in BART works similarly to BERT, processing the input text bidirectionally
to understand the full context of the sequence. This means BART's encoder is capable of
considering all words in a sentence simultaneously, understanding their relationships
comprehensively[11].
Autoregressive Decoder:
The decoder in BART operates autoregressive, meaning it generates one word at a time
while considering the words it has already generated.[12] This is particularly useful for
tasks like text summarization, where the model needs to generate coherent and
contextually appropriate summaries word by word.
Pre-training:
BART is pre-trained using a denoising autoencoder approach. The model is trained to
reconstruct the original text from a corrupted version. The corruption can involve tasks
such as:[9][10][11][12]
Token Masking: Randomly masking words in the input sequence.
Token Deletion: Removing some words entirely.
Sentence Permutation: Shuffling the order of sentences.
Text Infilling: Replacing a span of text with a single mask token.
These corruption techniques encourage BART to develop a deep understanding of text
structure and content, which is crucial for generating coherent and meaningful
summaries.After pre-training, BART is fine-tuned on specific downstream tasks, such as text
summarization. During fine-tuning, the model learns to generate concise and relevant
summaries from given text inputs, optimizing its performance for this particular task.[12]
How It Works:
BART works by first encoding the input text to capture its full context using a
bidirectional encoder, similar to BERT. Then, it generates the output text using its
autoregressive decoder. This makes BART highly effective for tasks that require both
understanding and generating text. For summarization, BART takes the entire input text,
encodes it to understand the meaning and context, and then decodes it into a shorter, more
concise version that retains the original meaning.[11]
##Outputs:
The system testing stage was essential to guaranteeing the developed model's robustness
and functionality. We tested many parts of the model's functionality, such as sentiment
analysis, audio-to-text summarisation, text summarisation, and URL scraping and
summarisation.
Text Summarisation:
We confirmed that the model could correctly condense
substantial amounts of text into brief summaries while preserving the essential
details. The BERT and BART models worked effectively, generating pertinent
and logical summaries in a range of situations.
URL Scrape and Summarisation:
The model was put to the test using web content
extraction, and it was successful in retrieving information from provided URLs,
summarising it, and producing pertinent, excellent summaries of the material that
had been scraped. The summarisation maintained its contextual appropriateness
when viewed from various URLs, indicating that the system can manage a variety
of content kinds.
Audio-to-Text Summarisation: We used AssemblyAI to build an audio processing
pipeline that first converted audio data to text and then summarised the text. The
model's capacity to handle both written and audio inputs was demonstrated by the
accuracy of the audio-to-text conversion and the highly satisfactory summary of
the transcribed text.
Sentiment Analysis: The emotional tone of the condensed content was accurately
determined by the sentiment analysis module. The algorithm could add insightful
categories to the summarised data by categorising attitudes as neutral, negative, or
positive.
Prototype Web page:
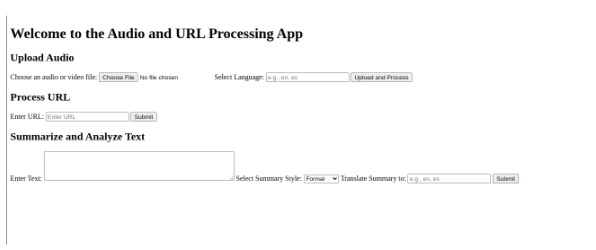
Original Web Page:
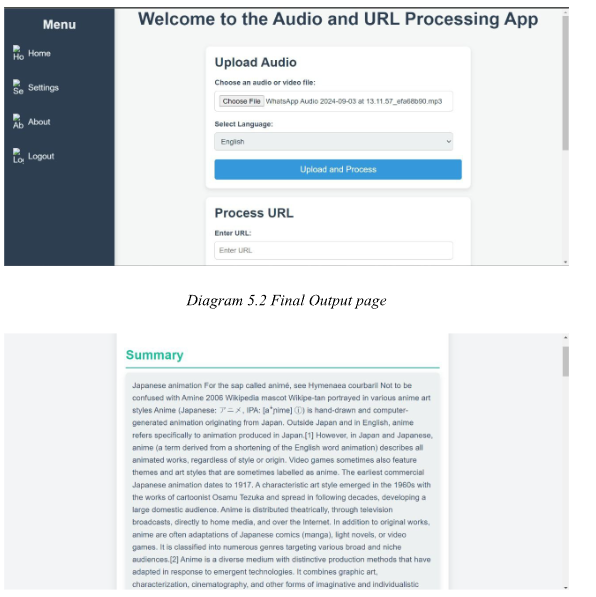
##Conclusion:
A comprehensive text summarisation system that can handle a variety of input formats,
including URLs, audio files, and raw text, was successfully created by the project. The
system uses sophisticated natural language processing (NLP) models, like BERT and
BART, to provide lengthy and succinct summaries. It also provides extra language
translation help. We showcased the system's capabilities through the prototype website,
which included sentiment analysis, language translation, and accurate summaries all
integrated into an easy-to-use interface made using HTML, CSS, JavaScript, and Flask.
With the capacity to summarise and translate text between several languages, this tool is
incredibly useful and adaptable. The system has the potential to be widely used in content
management, accessibility, and multilingual applications, as demonstrated by the
effective implementation of text and audio summarisation and the sentiment analysis
capability. The project achieved its goals and offered a strong platform for next
improvements and practical implementation.
##References:
D. J. Computing, "Unveiling Customer Sentiments E-Commerce Product Review
Analysis," DJComputing, [Online]. Available:
https://www.djcomputing.io/blog/e-commerce-review-analysis.php. [Accessed:
08-Sep-2024].
2. What Is ChatGPT, "Bing vs Bard vs ChatGPT: Which One Is Best?" [Online].
Available: https://www.whatischatgpt.co.uk/post/bing-vs-bard-vs-chatgpt-which-
one-is-best. [Accessed: 08-Sep-2024].
3. InfoQ, "Microsoft Releases Azure Open AI Service Including Access to Powerful
GPT-3 Models," InfoQ, 2021. [Online]. Available:
https://www.infoq.com/news/2021/11/azure-openai-service-gpt3/. [Accessed: 08-
Sep-2024].
4. GadgetsNow, "WhatsApp Expiring Groups: What is This New Feature, How it
Works and More," GadgetsNow, [Online]. Available:
https://www.gadgetsnow.com/featured/whatsapp-expiring-groups-what-is-this-
new-feature-how-it-works-and-more/articleshow/98521904.cms?frmapp=yes.
[Accessed: 08-Sep-2024].
5. GadgetsNow, "WhatsApp Expiring Groups: What is This New Feature, How it
Works and More," GadgetsNow, [Online]. Available:
https://www.gadgetsnow.com/featured/whatsapp-expiring-groups-what-is-this-
new-feature-how-it-works-and-more/articleshow/98521904.cms?frmapp=yes.
[Accessed: 08-Sep-2024].
6. Square Cloud Blog, "Flask: A Complete Introduction to the Web Framework in
Python," Square Cloud Blog, [Online]. Available:
https://blog.squarecloud.app/posts/practical-guide-to-flask. [Accessed: 08-Sep-
2024].
7. NileshBlog.Tech, "Flask Archives," [Online]. Available:
https://www.nileshblog.tech/tag/flask/. [Accessed: 08-Sep-2024].
8. Tutor Joe’s, "Python Flask Complete Tutorial," [Online]. Available:
https://www.tutorjoes.in/python_flask_tutorial/index. [Accessed: 08-Sep-2024].
Department of Statistics and Data Science, Christ (Deemed to be University)
9. T. Vaj, "Dynamic Mask for RoBERTa VS Static Mask for BERT," Medium,
[Online]. Available: https://vtiya.medium.com/dynamic-mask-for-roberta-vs-
static-mask-for-bert-
c997edc9a939?responsesOpen=true&sortBy=REVERSE_CHRON&source=read
_next_recirc-----c5c8c192b5f9----1---------------------
cc642b27_1afd_4829_a14e_b9f429c3dbb9-------. [Accessed: 08-Sep-2024].
10. Scifolio Blog, "Sci, Fi and AI," Scifolio Blog, [Online]. Available:
https://scifolio.blogspot.com/. [Accessed: 08-Sep-2024].
11. Speak Free, "Word2vec Vs BERT," [Online]. Available:
https://speakai.co/word2vec-vs-bert/. [Accessed: 08-Sep-2024].
12. W. Ji, Z. Cao, X. Li, and X. Li, "Small Sample Building Energy Consumption
Prediction Using Contrastive Transformer Networks," Sensors, vol. 23, no. 22, p.
9270, 2023. [Online]. Available: https://doi.org/10.3390/s23229270. [Accessed:
08-Sep-2024].
13. Avanka, "The Evolution of Voice Recognition Technology," Avanka, [Online].
Available: https://avanka.com/technology/evolution-of-voice-recognition-
technology/. [Accessed: 08-Sep-2024].
14. Kandi Open Weaver, "Automatic Speech Recognition Framework for Python,"
Kandi, [Online]. Available: https://kandi.openweaver.com/collections/artificial-
intelligence/automatic-speech-recognition-framework-for-python. [Accessed: 08-
Sep-2024].
15. ContractSafe, "Optical Character Recognition," ContractSafe, [Online]. Available:
https://www.contractsafe.com/glossary/optical-character-recognition. [Accessed:
08-Sep-2024].
16. S. Zahedian, "Introducing a Graph-Based Neural Network for Network-Wide
Traffic Volume Estimation," 2021. [Online]. Available:
https://doi.org/10.13016/ht0h-uxhe. [Accessed: 08-Sep-2024].