This paper presents a Text-to-Video Generation System capable of synthesizing videos from textual descriptions, images, or their combination. The system leverages state-of-the-art diffusion models integrated with FastAPI for backend processing and Streamlit for user interaction. This approach showcases the potential of generative AI in bridging the gap between natural language and video synthesis.
Video generation from natural language or image inputs represents a challenging task in generative AI due to its complexity and resource requirements. Recent advancements in diffusion models have made significant strides in addressing this challenge. This project implements a practical pipeline to achieve text-to-video generation by combining powerful generative models, such as damo-vilab/text-to-video-ms-1.7b and ali-vilab/i2vgen-xl, with robust backend and frontend solutions. The project aims to provide an easy-to-use system for generating high-quality videos for applications in creative content generation, education, and entertainment.
The proposed system integrates a modular backend and frontend architecture:
Backend:
Frontend:
Deployment:
ngrok for exposing endpoints.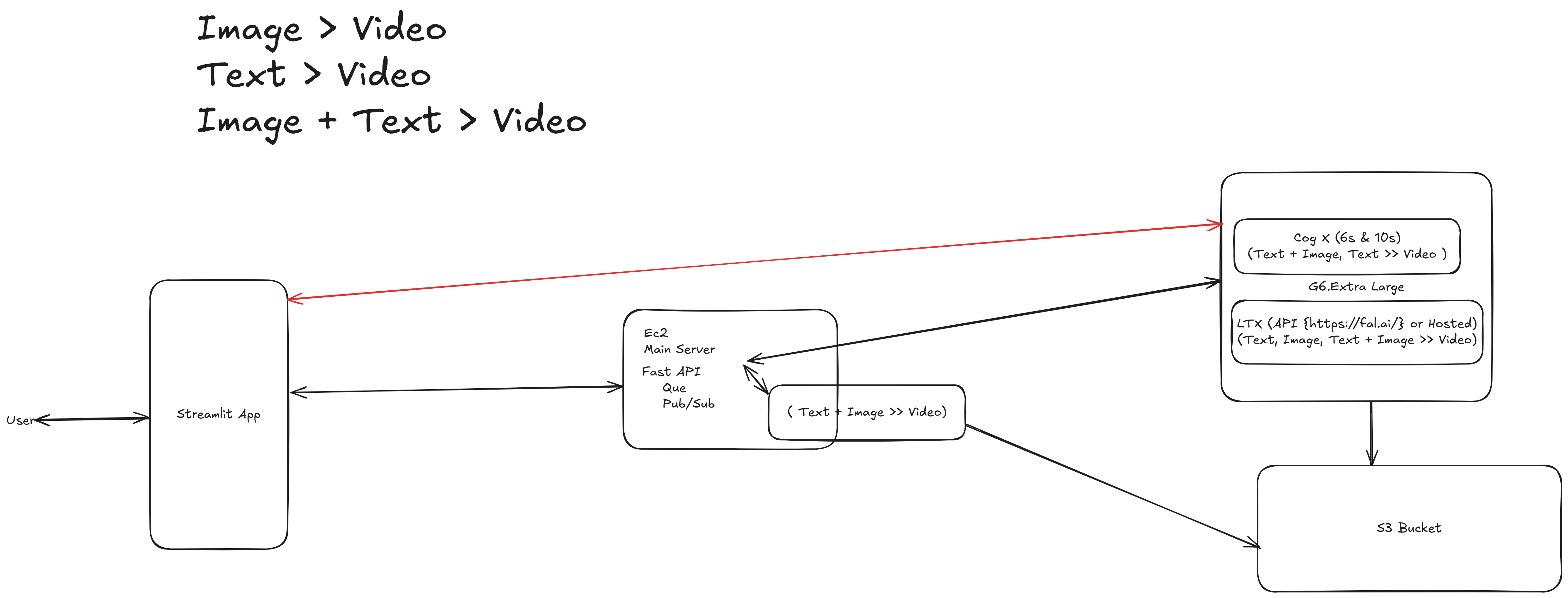
Experiments were conducted using various prompts and image inputs to evaluate the system's ability to generate coherent and contextually accurate videos:
Performance metrics included inference time, output quality, and user satisfaction.
The system successfully generated videos that matched the input prompts and images. Key findings include:
ngrok and GPU acceleration in Google Colab.Challenges observed included occasional artifacts in video outputs, which can be mitigated by improving the diffusion models or fine-tuning hyperparameters.
The Text-to-Video Generation System demonstrates the practical application of generative AI for video synthesis. By combining advanced diffusion models with an intuitive interface, the project bridges the gap between AI research and real-world usability. Future work will focus on improving video quality, optimizing inference time, and exploring alternative deployment strategies to ensure scalability.
backend/
|── .env
|── main.py
|── models.py
|── requirnments.py
|── s3_utils.py
└── tasks.py
frontend/
|── app.py
Notebooks/
|── Hosting_model_on_Google_Colaboratory.ipynb
The backend is implemented using FastAPI and provides endpoints for generating videos from text, images, or both. It also includes utilities for uploading files to S3.
The frontend is implemented using Streamlit and provides a user interface for interacting with the backend.
Clone the repository:
git clone https://github.com/Dineth9D/text-to-video.git cd text-to-video
Set up the backend:
cd backend python -m venv .venv venv\Scripts\activate pip install -r requirements.txt
Set up the frontend:
cd ../frontend python -m venv .venv .venv\Scripts\activate pip install -r requirements.txt
Upload the Notebook to Google Colab:
- Open your Google Drive and create a folder for the project (e.g., 'Text_to_Video_Generation').
- Upload 'Hosting_model_on_Google_Colaboratory.ipynb' to this folder.
- Open the notebook in Google Colab by right-clicking and selecting Open with > Google Colaboratory.
Start the server in Google Colab:
- Run the notebook to start the FastAPI server.
- Note the `ngrok` URL provided in the notebook output.
- Update the backend server URL in `backend/main.py` with the `ngrok` URL.

Start the backend server:
cd backend uvicorn main:app --reload
Start the frontend application:
cd ../frontend streamlit run app.py
Open your browser and go to http://localhost:8501 to use the application.