Telegram bots are well known and very popular technology in past years. Furthermore, current state of the development of the AI allows people to create very beatiful projects combining a lot of things together. This fact brings me the idea to build a telegram bot that will generate images. To implement such project I develop a telegram bot and stable diffusion model. Telegram bot was developed and stable diffusion was implemented from scratch using PyTorch. During the implementing the following technologies were investigated: U-Net, CLIP Encoder, diffusion, attention mechanism, telegram bot development. As a result, generated images looks not as real one, but follow the prompt that was given to model to produce. Example: image generated via prompt: "Man is sitting on the bed." 
The following project helps me to understand the stable diffusion model and review the telegram bot development
Image generation is a modern technology that was widely investigated in previous years. Current state of the development allows to generate images that may be unrecognizable by the humans: we can not understand is it a real image or fake. Diffusion models do this job. These models are complex, required a lot of computational resoursec to train, and, what is the most important, a lot of efforts and knowledge of programming, statistics and AI/ML techniques to implement it. My decision is to provide in this work contribution to the people who wants to try implement this technology for their purposes. This publication provide a detailed implementation of Stable Diffusion, including the U-Net, Variational Autoencoder, and text encoder. The remainder of this paper is structured as follows: Section 3 describes the methodology, Section 4 presents the experiments, Section 5 discusses the results, and Section 6 concludes the paper.
U-Net: The core of the diffusion model, responsible for predicting noise in the reverse diffusion process. We use a U-Net with skip connections to capture both low-level and high-level features.
Variational Autoencoder (VAE): Used to encode images into a latent space and decode them back to the original domain. 
Text Encoder: A transformer-based model (CLIP) is used to encode textual descriptions into embeddings, which are then concatenated with the latent representations for conditioning. 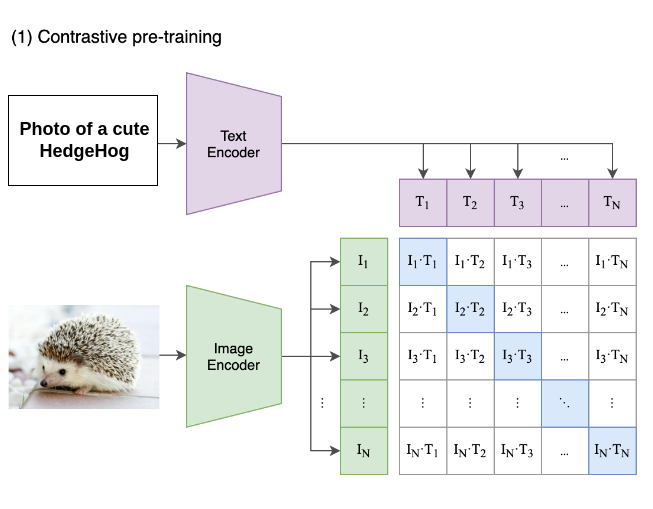
Now, let me briefly introduce the main processes. Before starting a training we need to prepare the image for that. This procedure is called forward process and is a process follows Markov chain approach, means, that every next state of the object depends only on its previous step. We gradually add the noise from normal distribution accrding to the variance schedule:
Here is the absolutely expected question: what is variance schedule? Variance schedule is a measure how many noise we should add at each step. Usually,
When the forward process is done we should train the model. Despite the fact that I do not have code for it, I want to provide explanation of that process. The main purpose is learn model to predict noise which was added to the image. The algorithm is following:
When the training is done we should test our model and make inference. This process is called sampling and produce the output image starting from pure noise:
As a result, we obtain an image that satisfies our prompt.
This is a basic and not so deep introduction to the principles how this approach works
The experimets were simple: generating images based on different text promts. In this section I would share the outputs in following format: prompt -> image.
On my setup of the computer, image takes approximately 7 minutes to be created.




Results are not clear, due to the lack of metrics which do not allow to compare this implementation with others. However, it is worth to say that the model denoising the image and provide adequate results, not just another noise. This shows that the model works properly and may be used as a starting point for future improvements, for example, finetuning. The output image shape is 512 by 512. At the same time, when one looks at the picture, it is not the hard task to see that image is artificial, not natural. Furthermore, my laptop setup does not allow to integrate this application into other system, because it takes long time to create an image and the quality is not the best.
This project is a brief and not deep introduction to stable diffusion model which is suitable for beginners in this field to understand the basic concepts under this technology. I highly recommend you to go through the original paper "Denoising Diffusion Probabilistic Models" and watch the videos on different platfroms that explain this approach better and deeper. As a future work I want to obtain the metrics to evaluate my model in comparison with other existing solutions. This will allow to adequately evaluate the project and have objective results. Additionally, I want to implement the training loop and train model by myself using appropriate dataset for personal purposes. Furthermore, it is necessary to deploy the model on a server with appropriate resources so that generating image will not take huge amount of time as it is now. And, as a final remark, I want to improve the quality of the image. Now, it is easy to distinguish the image from real because it looks as artificial. It is necessary to find the way to improve the quality of the image. My final purpose is to generate images that looks like real one.