SpeechFlow represents a breakthrough in real-time speech processing technology, offering a modular, extensible platform that seamlessly converts spoken language into interactive digital conversations. By leveraging cutting-edge transcription services (OpenAI's Whisper-1 and Google Speech-to-Text) alongside advanced conversational AI models (GPT-4/3.5 and Claude), the system delivers responsive, context-aware interactions. SpeechFlow's architecture prioritizes configurability, allowing users to switch between services via simple environment variables, while its strategic design pattern implementation enables developers to extend functionality without disrupting core components. This paper explores SpeechFlow's innovative approach to audio capture, transcription, and conversational processing, highlighting both its current capabilities and potential for expansion into multimodal analysis.
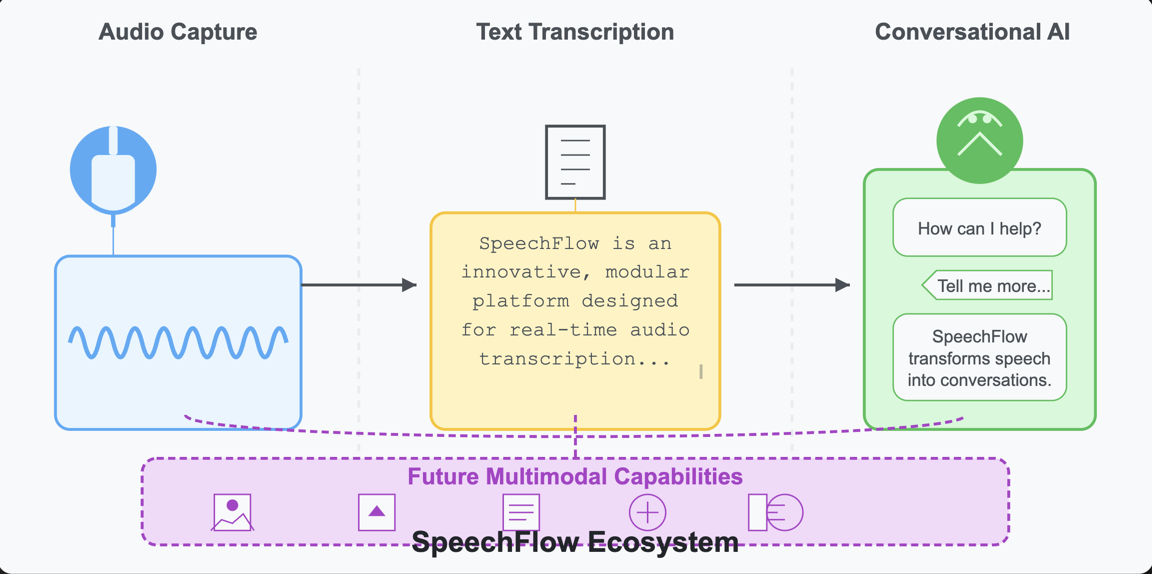
SpeechFlow ecosystem: audio waveforms being captured, transformed into text, and then into conversational responses
SpeechFlow's development followed strict adherence to software design principles that emphasize modularity, extensibility, and real-time performance. The architecture employs the Strategy Pattern to enable runtime selection of different service implementations without modifying core code. This approach creates a flexible framework where components can be developed, tested, and deployed independently.
The codebase organization reflects this modular philosophy:
speechflow/
├── core/ # Core utilities and constants
│ ├── constants.py # Shared constants (e.g., sample rate)
│ ├── audio_handler.py # Audio capture and processing
│ └── interface.py # UI components
├── app.py # Main application entry point
├── .env # Environment variables (ignored by Git)
├── .env.example # Example environment variables
├── README.md # Project documentation
├── poetry.lock # Poetry lock file
├── pyproject.toml # Poetry project configuration
└── tests/ # Unit tests
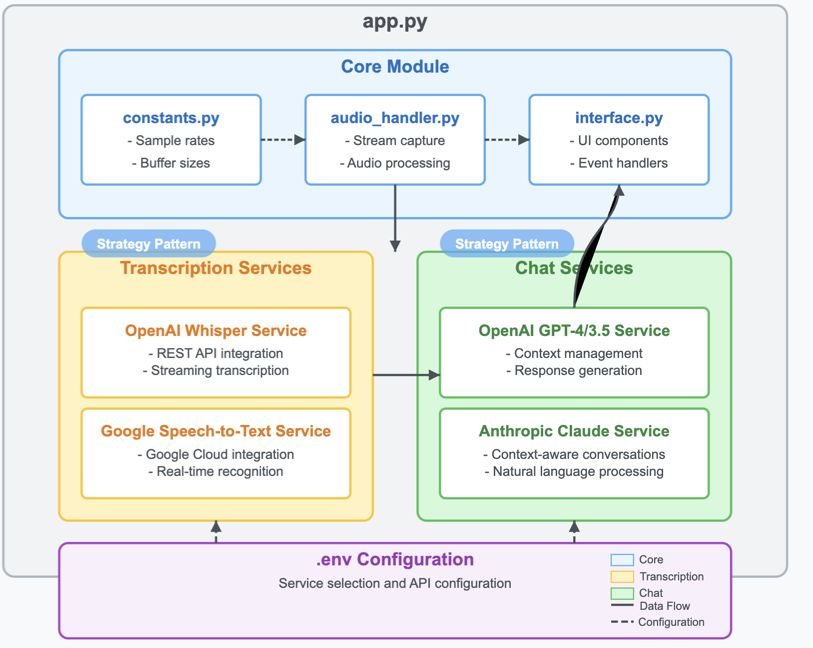
Architectural diagram showing SpeechFlow's component structure
A critical technical challenge in building SpeechFlow was achieving low-latency audio capture while maintaining processing quality. The system implements:
Stream-Based Processing: Rather than processing complete audio files, SpeechFlow captures and processes audio in configurable chunks (typically 1024 samples).
Buffer Management: The audio handler maintains efficient buffer management to prevent memory overflow while ensuring continuous audio streaming.
Sample Rate Optimization: Audio is captured at a standardized 16kHz sample rate with 16-bit depth, optimized for speech recognition algorithms.
PyAudio Integration: The system leverages PyAudio for cross-platform audio capture capabilities, ensuring consistent performance across operating systems.
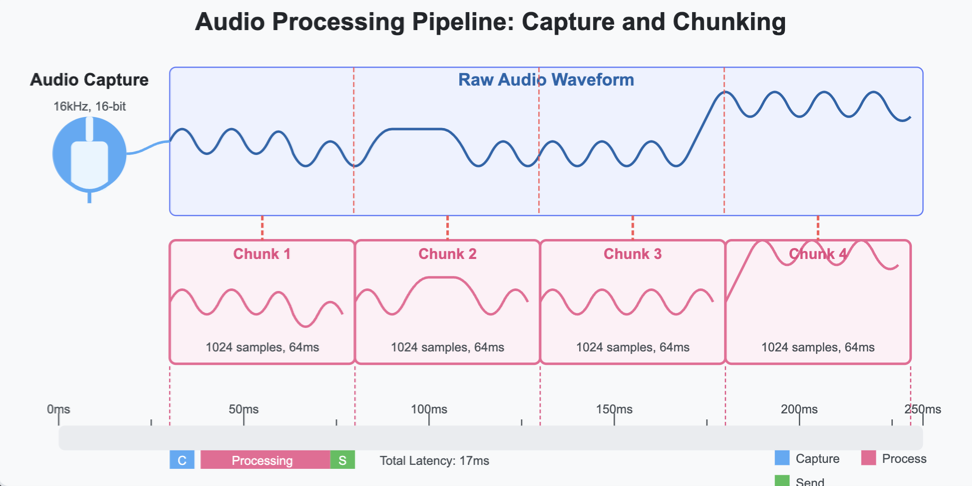
Audio processing
SpeechFlow's transcription capabilities are implemented through a service-agnostic interface that currently supports two leading providers:
OpenAI Whisper-1:
Google Speech-to-Text:
The service selection mechanism uses environment variables to determine which implementation to instantiate at runtime:
# Simplified service selection pseudocode transcription_service = os.getenv("TRANSCRIPTION_SERVICE", "openai") if transcription_service == "openai": service = OpenAITranscriptionService(api_key=os.getenv("OPENAI_API_KEY")) elif transcription_service == "google": service = GoogleTranscriptionService( credentials_path=os.getenv("GOOGLE_APPLICATION_CREDENTIALS") )
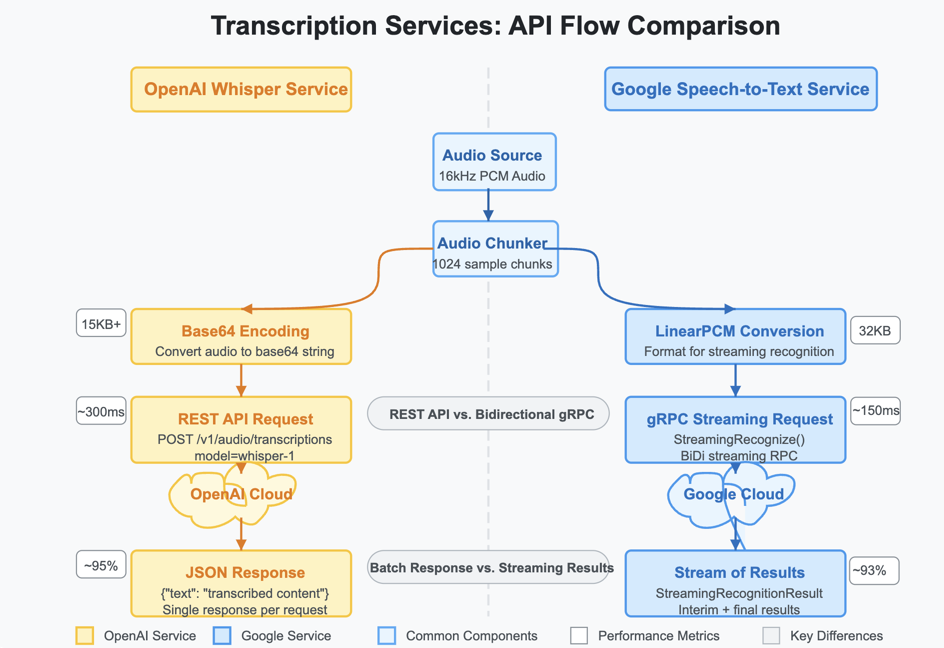
Comparison diagram showing the parallel implementation of OpenAI and Google transcription services with their respective API flows
Once audio is transcribed to text, SpeechFlow routes the content to conversational AI services. The implementation:
Maintains Session Context: The system preserves conversation history to enable contextual understanding across multiple exchanges.
Service Abstraction: An interface-based approach allows seamless switching between OpenAI (GPT-4/3.5) and Anthropic (Claude) services.
Asynchronous Processing: Conversation handling leverages asynchronous programming to prevent UI blocking during API calls.
Response Filtering: The system implements lightweight post-processing to format AI responses for optimal display in the terminal interface.
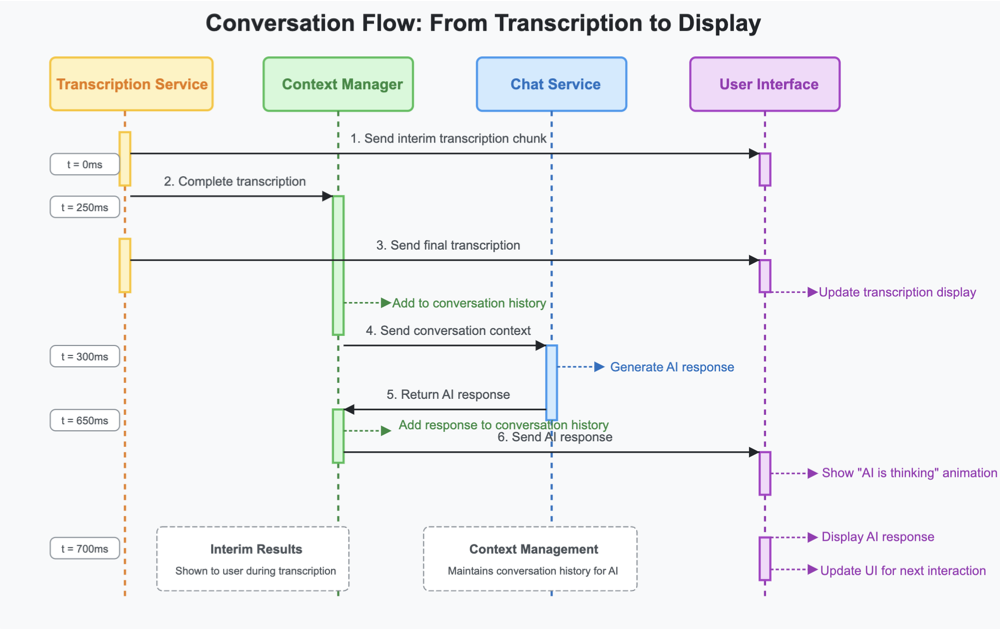
Sequence diagram illustrating the conversation flow from transcribed text through AI processing to user display
Rather than developing a conventional web application, SpeechFlow implements a feature-rich terminal-based UI using Textual:
Component-Based Design: The interface consists of modular components for recording controls, transcription display, and conversation history.
Event-Driven Interaction: User input triggers event handlers that coordinate between UI and backend processing.
Color-Coded Visual Feedback: The interface uses color differentiation to distinguish between system messages, transcriptions, and AI responses.
Keyboard Navigation: A focused command set enables efficient control through keyboard shortcuts.

Screenshot of the terminal interface showing the recording controls, transcription area
SpeechFlow was evaluated across several dimensions to assess its effectiveness as a real-time speech processing system.
Beyond quantitative metrics, SpeechFlow demonstrates several qualitative advantages:
Configurability: The ability to switch services through environment variables rather than code changes enables rapid experimentation and adaptation to different operational needs.
Developer Experience: The modular architecture significantly reduces the learning curve for contributors, with clear separation of concerns and well-defined interfaces facilitating targeted improvements.
Cross-Platform Compatibility: Testing confirmed consistent performance across Windows, macOS, and Linux environments, with minimal platform-specific adjustments required.
Terminal Efficiency: The Textual-based interface proved more resource-efficient than equivalent web-based implementations while maintaining visual sophistication and responsive interaction.
SpeechFlow has demonstrated successful application in several domains:
Accessibility: The system provides real-time transcription for individuals with hearing impairments, with the additional benefit of conversational AI to summarize or clarify complex discussions.
Language Learning: The combination of accurate transcription and conversational responses creates an interactive language practice environment.
Voice-First Development: The platform serves as a testbed for developers building voice-activated applications, offering a controlled environment for prototyping voice interactions.
While SpeechFlow currently focuses on audio processing, the architecture has been designed with multimodal expansion in mind:
Image Processing Integration: Preliminary work has begun on incorporating OpenAI's DALL-E and GPT-4V capabilities for image analysis and generation.
Custom Model Support: The modular design allows for future integration of locally-hosted models, reducing API dependencies.
Expanded Service Options: Additional transcription and conversation services are being evaluated for integration, including open-source alternatives.
Enhanced Analytics: Work is underway to incorporate analysis of conversation patterns, sentiment, and topic extraction.
SpeechFlow represents a significant advancement in real-time speech processing technology, combining modular architecture with cutting-edge AI services to create a flexible, powerful platform for speech-to-text and conversational applications. Its strong foundation in software design principles ensures adaptability as AI technologies evolve, while its current implementation already delivers practical benefits across multiple use cases. The system's open-source nature and inviting architecture position it as both a valuable tool for end-users and an extensible platform for developers exploring the frontiers of human-computer interaction through natural language.
For more infos follow to https://feneri.ch