Spam comments on GitHub repositories can be a significant nuisance, disrupting meaningful discussions and requiring constant moderation. To solve this problem, we built a GitHub Spam Comment Hider, an AI-powered tool that automatically detects and hides spam comments in issues, discussions, and pull requests. This blog documents our journey, challenges, and the final solution.
To train an effective spam detection model, we first needed a high-quality dataset. However, we quickly realized that there was no existing dataset for GitHub spam detection. So, we had to build our own.
We wrote a Python script that used GitHub's GraphQL API to fetch comments from some of the most active repositories, including:
These repositories have high engagement, making them ideal for collecting a diverse dataset. However, there was a problem—over 95% of the comments were ham (non-spam), and spam comments were hard to find.
import requests import pandas as pd import os import time def fetch_github_comments_with_status_graphql(owner, repo, token, max_count=2000, partition_size=10): url = "https://api.github.com/graphql" headers = {"Authorization": f"bearer {token}"} output_csv = 'comments.csv' def fetch_rate_limit(): rate_limit_query = """ query { rateLimit { limit cost remaining resetAt } } """ response = requests.post(url, json={"query": rate_limit_query}, headers=headers) if response.status_code == 200: return response.json()["data"]["rateLimit"] else: print(f"Failed to fetch rate limit. Status code: {response.status_code}, {response.text}") return None def fetch_issues_and_comments(): query = """ query($owner: String!, $repo: String!, $first: Int!, $after: String) { repository(owner: $owner, name: $repo) { issues(first: $first, orderBy: {field: CREATED_AT, direction: DESC}, after: $after) { pageInfo { hasNextPage endCursor } nodes { number comments(first: 100) { nodes { author { login } body isMinimized minimizedReason } } } } } } """ first = 100 # GitHub's maximum per request after = None all_data = [] fetched_count = 0 while fetched_count < max_count: variables = {"owner": owner, "repo": repo, "first": first, "after": after} response = requests.post(url, json={"query": query, "variables": variables}, headers=headers) if response.status_code == 200: data = response.json() repository = data.get("data", {}).get("repository") if not repository or not repository.get("issues"): print("Unexpected response structure:", data) break issues = repository["issues"]["nodes"] page_info = repository["issues"]["pageInfo"] all_data.extend(issues) fetched_count += len(issues) if not page_info["hasNextPage"]: break after = page_info["endCursor"] # Update the cursor for the next request else: print(f"Failed to fetch issues and comments. Status code: {response.status_code}, {response.text}") break return all_data issues_data = fetch_issues_and_comments() if not issues_data: print("Could not fetch issues and comments. Exiting...") return print(f"Total issues fetched: {len(issues_data)}") all_comments = [] for issue in issues_data: issue_number = issue["number"] comments = issue["comments"]["nodes"] for comment in comments: all_comments.append({ "Issue Number": issue_number, "Author": comment["author"]["login"] if comment["author"] else "Unknown", "Comment": comment["body"], "Is Minimized": comment["isMinimized"], "Minimized Reason": comment.get("minimizedReason", "None") }) # Save to CSV if os.path.exists(output_csv): existing_df = pd.read_csv(output_csv) new_df = pd.DataFrame(all_comments) combined_df = pd.concat([existing_df, new_df], ignore_index=True) combined_df.to_csv(output_csv, index=False) else: new_df = pd.DataFrame(all_comments) new_df.to_csv(output_csv, index=False) print(f"Total comments fetched: {len(all_comments)}") rate_limit = fetch_rate_limit() if rate_limit: print(f"Rate limit remaining: {rate_limit['remaining']}") else: print("Could not fetch rate limit.") # Example usage owner = input("Enter the owner of the repository: ") repo = input("Enter the name of the repository: ") token = input("Enter your GitHub token: ") fetch_github_comments_with_status_graphql(owner, repo, token)
PS C:\Users\sambh> python -u "c:\Users\sambh\OneDrive\Desktop\SPAM-GITHUB\scrap.py" Enter the owner of the repository: opencv Enter the name of the repository: opencv Enter your GitHub token: your token here Total issues fetched: 2000 Total comments fetched: 6592 Rate limit remaining: 4980
Even after scraping 70,000+ comments, we found only 500 spam comments. The primary reason was that spam comments are often moderated and deleted quickly by repo maintainers. We found spam only in hidden/minimized comments left by repo owners.
Initially, we tried training a binary classification model using standard spam detection datasets from Kaggle and other sources. However, the model performed poorly on GitHub comments because:
Since GitHub spam was scarce, we trained our model using:
This ensured that the model learned to accurately classify non-spam GitHub comments, minimizing false positives. The final dataset contained 109,662 comments.
With our dataset ready, we moved on to training.
We experimented with two different approaches:
Both models performed well, but we chose the first model for deployment because:
import numpy as np import pandas as pd from sklearn.feature_extraction.text import CountVectorizer from sklearn.naive_bayes import MultinomialNB from sklearn.pipeline import Pipeline from sklearn.metrics import classification_report import joblib # Load the dataset df = pd.read_csv(r"C:\Users\sambh\hamnew.csv") # Handle missing values in 'text' and 'label' columns df['text'] = df['text'].fillna('') # Replace NaN in 'text' with empty string df = df.dropna(subset=['label']) # Drop rows where 'label' is NaN # Convert 'label' to integers if needed df['label'] = df['label'].astype(int) # Shuffle the dataset df = df.sample(frac=1).reset_index(drop=True) # Split into training and testing sets train, test = np.split(df, [int(len(df) * 0.8)]) train_X = train["text"] train_y = train["label"] test_X = test["text"] test_y = test["label"] # Build the model pipeline cv = CountVectorizer() mb = MultinomialNB() model = Pipeline([ ('vectorizer', cv), ('nb', mb) ]) # Train the model model.fit(train_X, train_y) # Predict and evaluate pred_y = model.predict(test_X) print(classification_report(test_y, pred_y)) # Save the model joblib.dump(model, "spam_detector_model4.pkl")
Once trained, we deployed the model as an API, allowing easy integration.
API URL: https://spam-comment-detector-api.onrender.com/predict
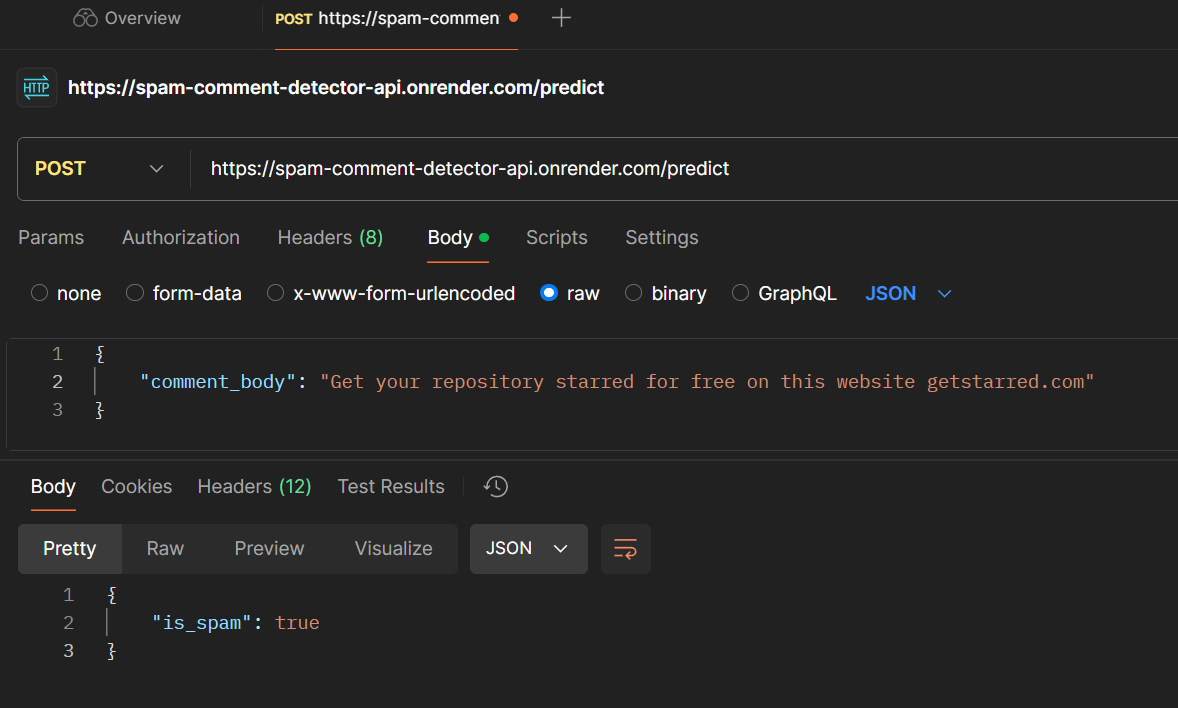
With our model API in place, we developed a GitHub Action to automatically detect and hide spam comments.
We leveraged GitHub's GraphQL API to retrieve comments from:
Our Python script:
import joblib import requests import os import json GITHUB_API_URL = "https://api.github.com/graphql" PREDICT_API_URL = "https://spam-comment-detector-api.onrender.com" CACHE_FILE = '.github/cursor_cache/cursor.json' def load_cursor(): if os.path.exists(CACHE_FILE): with open(CACHE_FILE, 'r') as f: return json.load(f) return {} def save_cursor(cursor_data): os.makedirs(os.path.dirname(CACHE_FILE), exist_ok=True) with open(CACHE_FILE, 'w') as f: json.dump(cursor_data, f) def fetch_comments(owner, repo, headers, after_cursor=None, comment_type="discussion"): if comment_type == "discussion": query_field = "discussions" query_comments_field = "comments" elif comment_type == "issue": query_field = "issues" query_comments_field = "comments" elif comment_type == "pullRequest": query_field = "pullRequests" query_comments_field = "comments" query = f""" query($owner: String!, $repo: String!, $first: Int, $after: String) {{ repository(owner: $owner, name: $repo) {{ {query_field}(first: 10) {{ edges {{ node {{ id title {query_comments_field}(first: $first, after: $after) {{ edges {{ node {{ id body isMinimized }} cursor }} pageInfo {{ endCursor hasNextPage }} }} }} }} pageInfo {{ hasNextPage endCursor }} }} }} }} """ variables = { "owner": owner, "repo": repo, "first": 10, "after": after_cursor, } response = requests.post(GITHUB_API_URL, headers=headers, json={"query": query, "variables": variables}) print("Fetch Comments Response:", response.json()) # Debugging line if response.status_code == 200: return response.json() else: raise Exception(f"Query failed with code {response.status_code}. Response: {response.json()}") def minimize_comment(comment_id, headers): mutation = """ mutation($commentId: ID!) { minimizeComment(input: {subjectId: $commentId, classifier: SPAM}) { minimizedComment { isMinimized minimizedReason } } } """ variables = {"commentId": comment_id} response = requests.post(GITHUB_API_URL, headers=headers, json={"query": mutation, "variables": variables}) if response.status_code == 200: data = response.json() return data["data"]["minimizeComment"]["minimizedComment"]["isMinimized"] else: print(f"Failed to minimize comment with ID {comment_id}. Status code: {response.status_code}") return False def detect_spam(comment_body): response = requests.post(f"{PREDICT_API_URL}/predict", json={"comment_body": comment_body}) if response.status_code == 200: return response.json().get("is_spam", False) else: print("API Error:", response.json()) return False def moderate_comments(owner, repo, token): headers = { 'Authorization': f'Bearer {token}', 'Content-Type': 'application/json' } spam_results = [] comment_types = ["discussion", "issue", "pullRequest"] cursor_data = load_cursor() for comment_type in comment_types: latest_cursor = cursor_data.get(comment_type) try: while True: data = fetch_comments(owner, repo, headers, latest_cursor, comment_type=comment_type) for entity in data['data']['repository'][comment_type + "s"]['edges']: for comment_edge in entity['node']['comments']['edges']: comment_id = comment_edge['node']['id'] comment_body = comment_edge['node']['body'] is_minimized = comment_edge['node']['isMinimized'] print(f"Processing {comment_type} comment:", comment_body) print("Is Minimized:", is_minimized) print("Is Spam:", detect_spam(comment_body)) if not is_minimized and detect_spam(comment_body): hidden = minimize_comment(comment_id, headers) spam_results.append({"id": comment_id, "hidden": hidden}) latest_cursor = comment_edge['cursor'] page_info = entity['node']['comments']['pageInfo'] if not page_info['hasNextPage']: break if not data['data']['repository'][comment_type + "s"]['pageInfo']['hasNextPage']: break latest_cursor = data['data']['repository'][comment_type + "s"]['pageInfo']["endCursor"] except Exception as e: print(f"Error processing {comment_type}s: " + str(e)) cursor_data[comment_type] = latest_cursor save_cursor(cursor_data) print("Moderation Results:") print(spam_results) if __name__ == "__main__": OWNER = os.environ.get("GITHUB_REPOSITORY_OWNER") REPO = os.environ.get("GITHUB_REPOSITORY") TOKEN = os.getenv('GITHUB_TOKEN') try: repo_parts = os.environ.get("GITHUB_REPOSITORY").split("/") if len(repo_parts) == 2: OWNER = repo_parts[0] REPO = repo_parts[1] else: raise ValueError("GITHUB_REPOSITORY environment variable is not in the expected 'owner/repo' format.") except (AttributeError, ValueError) as e: print(f"Error getting repository information: {e}") exit(1) moderate_comments(OWNER, REPO, TOKEN)
GraphQL allowed us to efficiently query only the latest comments, reducing API call overhead. Unlike REST APIs, GraphQL fetches only the data we need, making it highly efficient for our use case.
To make the tool easily accessible, we published it on the GitHub Marketplace.
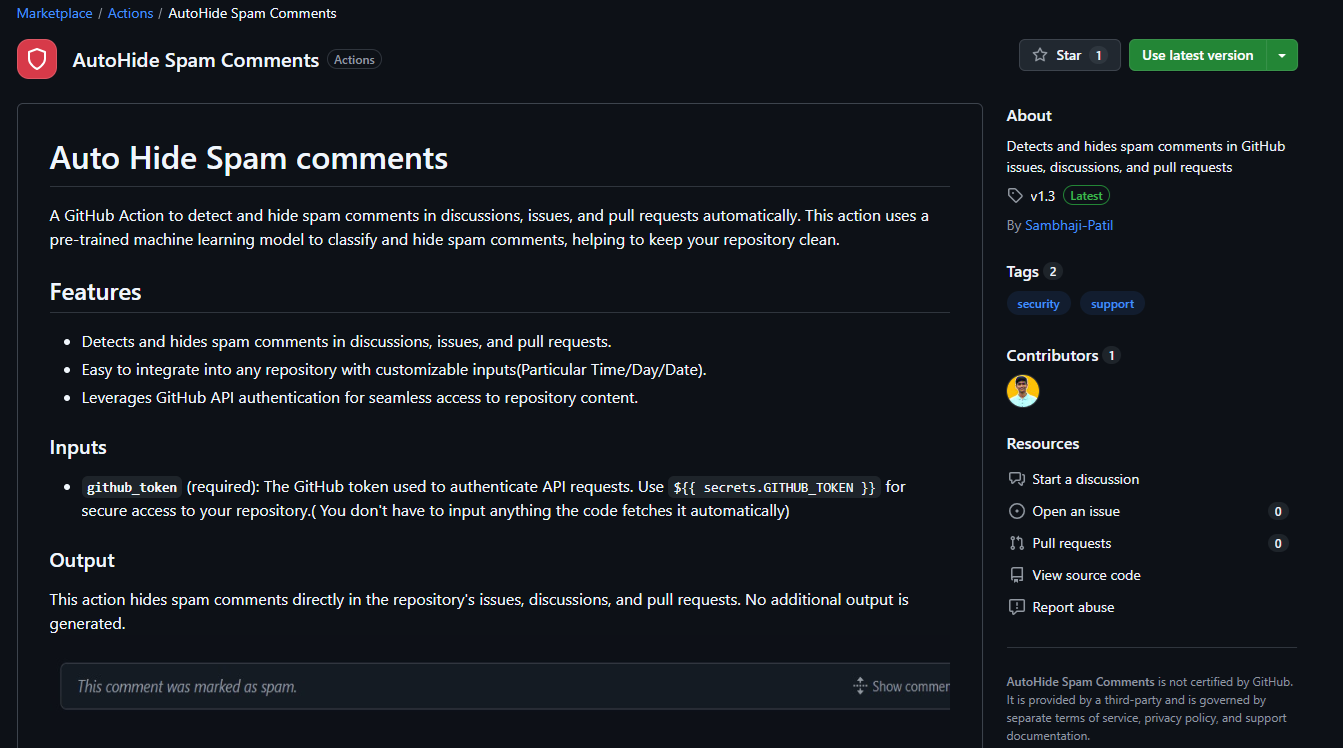
To use the action, users simply needed to copy the following YAML workflow and add it to their repository under .github/workflows/spam-detection.yml.
name: Spam Detection on: workflow_dispatch: jobs: detect-spam: runs-on: ubuntu-latest permissions: issues: write pull-requests: write discussions: write contents: read steps: - uses: actions/checkout@v3 - name: Cache cursor uses: actions/cache@v3 with: path: .github/cursor_cache key: ${{ runner.os }}-cursor-${{ github.run_id }} restore-keys: | ${{ runner.os }}-cursor- - name: Spam Detection uses: Sambhaji-Patil/Auto-Hide-Spam-Comments@v1.3 env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
⚙️ Default Behavior & Custom Scheduling
By default, the workflow only activates when run manually. However, users can also customize the schedule using our cron expression workflow script from the GitHub Action README file (as shown in the image below). This allows users to set specific times and dates for execution.
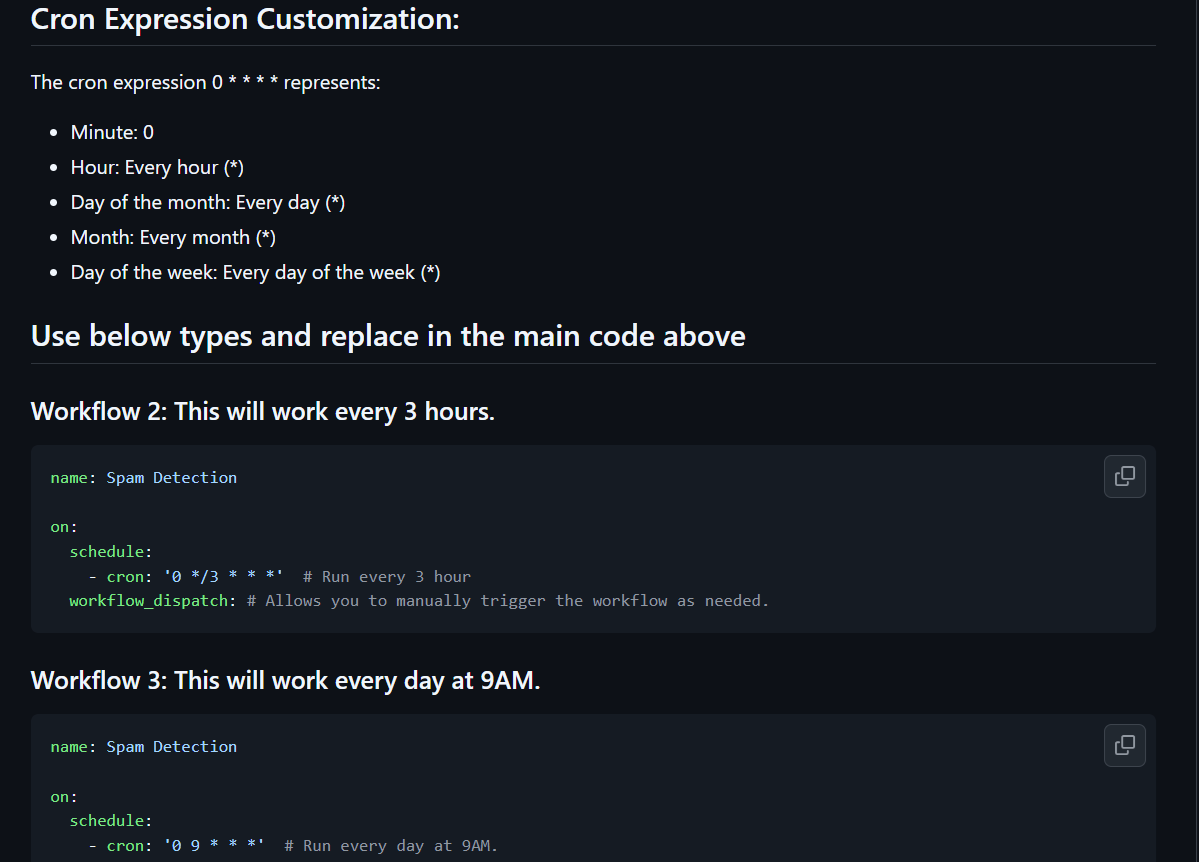
There are more customized templates in the actions README
Once deployed, our GitHub Spam Comment Hider successfully identified and auto-hid spam comments in real-time.
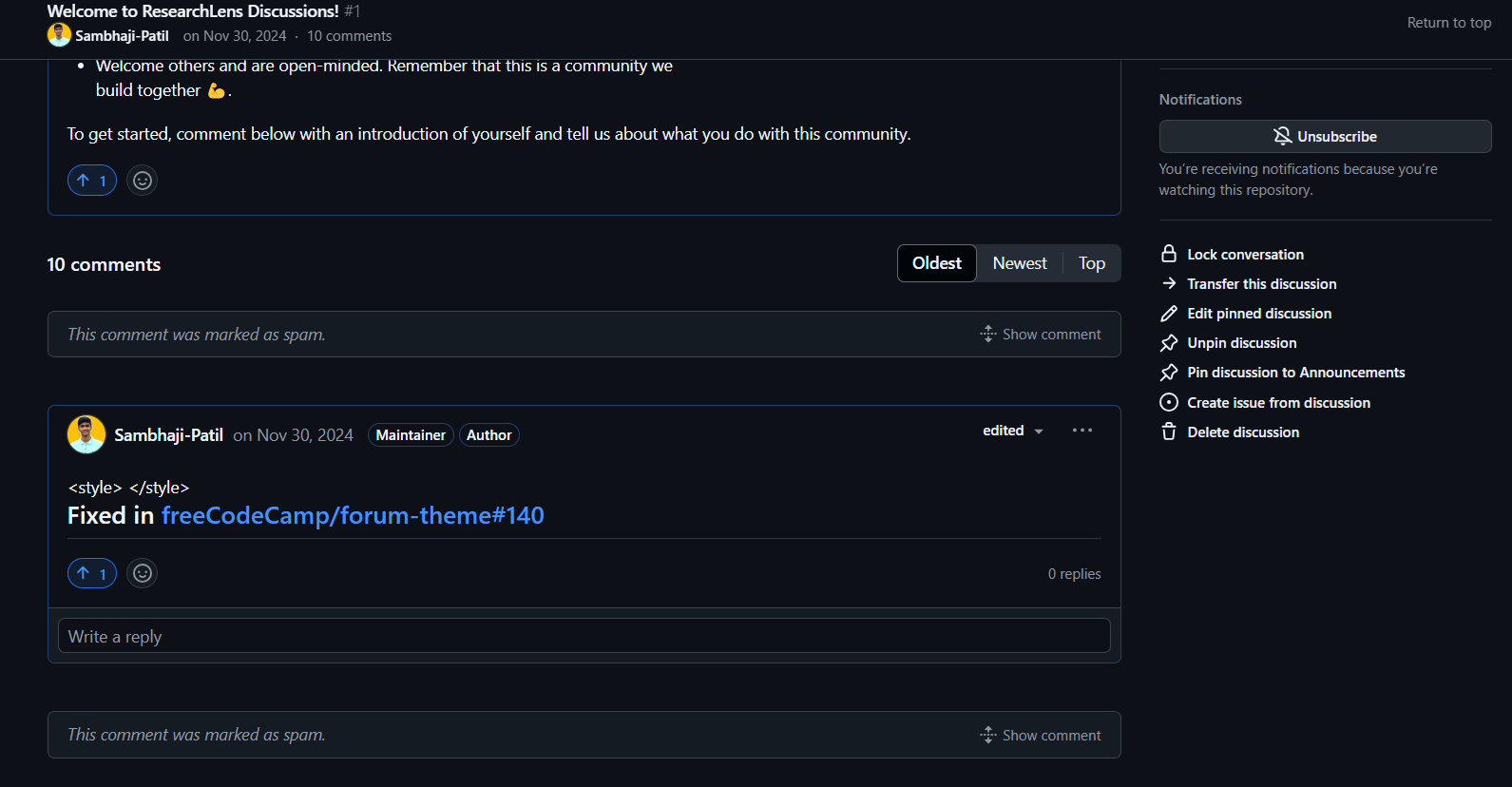
This project was a fascinating journey, from scraping GitHub comments and handling data scarcity to building a custom AI model and publishing it as a GitHub Action.
With this tool, open-source maintainers no longer have to manually moderate spam comments, making discussions more productive and spam-free!
🚀 Try it out today on GitHub Marketplace!