
Abstract
This publication introduces a sentiment analysis system leveraging Natural Language Processing (NLP) to classify sentiments from a Twitter dataset. The system preprocesses text data using tokenization, stemming, and stop-word removal, followed by feature extraction through Count Vectorizer. Several machine learning algorithms, including Random Forest, K-Fold Cross Validation, Logistic Regression, Support Vector Machines ,and Decision Tree classifiers, were implemented to predict sentiment categories (positive, negative, or neutral). Model performance was evaluated using metrics such as accuracy and confusion matrix. Furthermore, the system was extended to predict sentiments on new tweets, demonstrating real-world applicability. The results highlight the comparative effectiveness of various models, with ensemble techniques like Random Forest and XGBoost achieving higher accuracy in sentiment classification.
Introduction
Social media platforms like Twitter offer an abundance of unstructured data, making them valuable sources for sentiment analysis. Analyzing sentiments expressed in tweets can provide key insights into public opinion on a wide array of topics. While this system primarily focuses on Twitter data, the overarching goal is to extend its capability to all major social media platforms.
The sentiment analysis system is designed to classify text into three sentiment categories: positive, negative, and neutral. Using Natural Language Processing (NLP) techniques, the system processes raw tweet data by removing unnecessary elements like hashtags and mentions, followed by tokenization, stemming, and stop-word removal to prepare the text for analysis. The processed data is then classified using machine learning models, allowing the system to determine the overall sentiment of a tweet.
Though this version is tailored to analyze tweets, the system's architecture is built with scalability in mind. It is capable of integrating data from other social media platforms like Facebook or Instagram, enabling the analysis of more diverse text inputs. By capturing real-time sentiments, this system helps businesses, researchers, and policymakers track public opinion and identify trends across social media. The expansion potential to other platforms enhances its utility as a comprehensive tool for understanding sentiment across a broad spectrum of online interactions.
Problem Statement
Social media platforms, particularly Twitter, have become essential channels for individuals to express their opinions and share information on a wide range of topics. Analyzing sentiments expressed in tweets can provide valuable insights into public opinion, trends, and consumer behavior. However, the vast amount of data generated on Twitter presents challenges for accurate sentiment analysis. The informal language, slang, and context-specific expressions often found in tweets can lead to difficulties in effectively classifying sentiments.
This system aims to develop a sentiment analysis tool that classifies tweets into three categories: positive, negative, and neutral. By utilizing Natural Language Processing (NLP) techniques and various machine learning algorithms, this system will preprocess Twitter data, extract relevant features, and accurately predict sentiment. The goal is to create a solution that not only offers insights into Twitter sentiment but also lays the groundwork for future applications across other social media platforms. This research addresses the need for an effective sentiment analysis system that can help stakeholders understand public sentiment in real-time.
Objectives
-
Classify Sentiments: Develop a system to classify tweets into three distinct sentiment categories: positive, negative, and neutral.
-
Utilize NLP Techniques: Employ Natural Language Processing (NLP) methods to preprocess and analyze tweet data, ensuring effective extraction of relevant features.
-
Implement Machine Learning Algorithms: Utilize various machine learning algorithms, such as Random Forest, Decision Tree, and XGBoost, to enhance the accuracy of sentiment classification.
-
Real-Time Sentiment Tracking: Provide real-time insights into public sentiment on Twitter, enabling stakeholders to understand user opinions and trends.
-
Scalability to Other Platforms: Establish a framework that allows for the adaptation of the sentiment analysis system to other social media platforms, broadening its applicability.
Data Collection
The dataset utilized for this sentiment analysis project was sourced from Kaggle and contains a total of 1 million reviews organized in an Excel sheet. This extensive collection includes a diverse range of sentiments, specifically categorized into positive and negative classes for a binary classification task.
The reviews capture a variety of expressions and opinions, making it a valuable resource for training sentiment analysis models. This dataset enables the system to learn from different linguistic styles and nuances, enhancing its capability to accurately classify sentiments. By leveraging this comprehensive dataset, the project aims to develop a reliable sentiment analysis tool that can effectively predict sentiments from tweets and ultimately be adapted for other social media platforms.
Data Preprocessing
-
Loading the Dataset:
The sentiment analysis dataset was imported into a Jupyter Notebook, allowing for a structured and interactive environment to explore and manipulate the data effectively. This facilitated the application of various data analysis techniques essential for preparing the dataset for modeling. -
Null Value Check:
An initial assessment was conducted to identify any null values within the dataset. This involved utilizing methods to evaluate missing data across all columns. Upon inspection, it was determined that certain entries contained null values that could hinder accurate sentiment analysis.
Rows containing null values were systematically removed to maintain data integrity. This step is crucial, as the presence of null values can significantly impact the performance of machine learning models. -
Data Cleaning:
Comprehensive data cleaning operations were performed to prepare the dataset for analysis. This included:
Removal of Irrelevant Characters: Extraneous characters, such as punctuation, special symbols, and excessive whitespace, were eliminated from the tweet texts to standardize the content.
Text Normalization: All text was converted to lowercase to ensure uniformity, which is essential for accurate sentiment classification, as it reduces the complexity of the data by eliminating variations in case. -
Character Length Column:
A new column was created to track the character length of each tweet, providing insights into the relationship between tweet length and sentiment classification. This feature allows for the analysis of how the length of a tweet may influence sentiment perception and classification accuracy. -
Data Visualization:
The dataset was visually analyzed to derive insights into sentiment distribution and text characteristics using a variety of graphical representations:
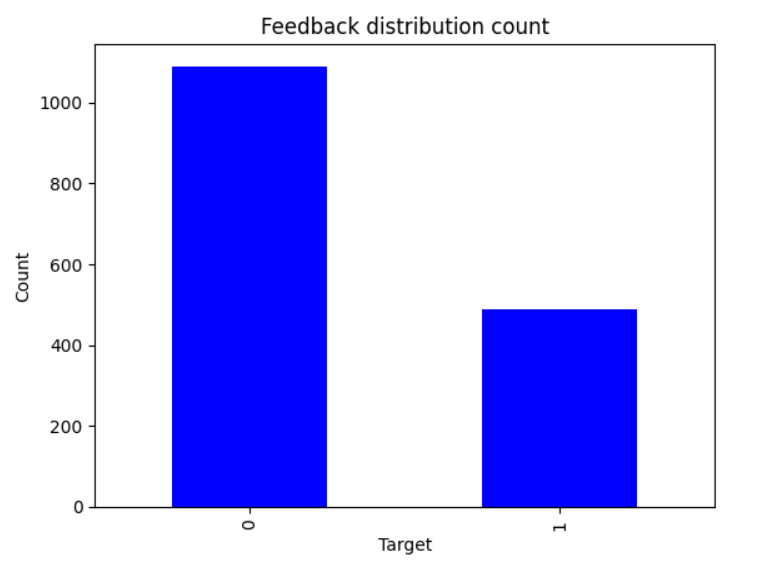
a. Bar Graphs: Used to depict the number of tweets categorized into positive, negative, and neutral
sentiments. This visualization provided a clear overview of the sentiment landscape within
the dataset.
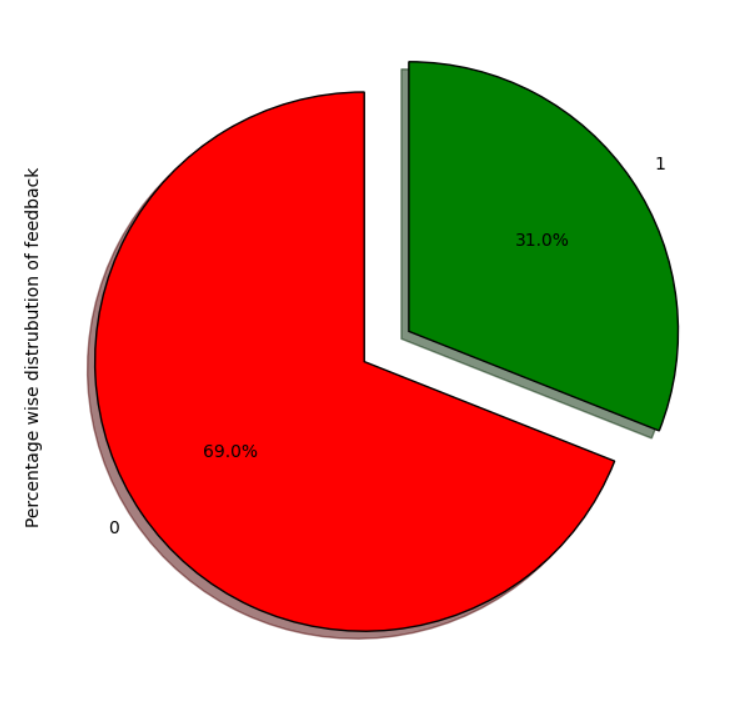
b. Pie Charts: Illustrated the proportion of each sentiment category, allowing for an immediate
understanding of the overall distribution of sentiments.
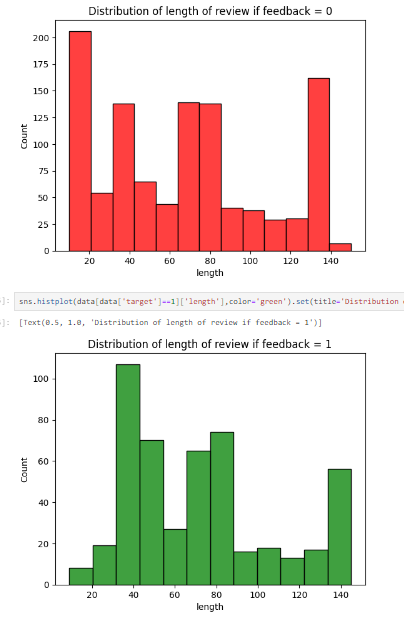
c. Graphs: Analyzed the distribution of tweet lengths across different sentiment categories, revealing trends
and patterns that may impact the analysis.
d. Word Cloud Generation: A word cloud was created to visually represent the most frequently used words
within the dataset. This tool highlighted key terms and phrases associated with
different sentiments, offering valuable insights into user expressions and the
language used on Twitter.

- Feature Extraction:
To prepare the textual data for modeling, CountVectorizer was applied to convert the tweet texts into a numerical representation. This process transformed the text into a matrix of token counts, enabling machine learning algorithms to interpret the data.
The PorterStemmer algorithm was utilized to reduce words to their root forms, enhancing the model's ability to recognize variations of the same word. This normalization process is vital for improving the efficiency and accuracy of sentiment classification.
Data Splitting:
The processed dataset was divided into training and testing sets to facilitate model evaluation. A test size of 0.3 was chosen, meaning 30% of the dataset was allocated for testing while 70% was used for training the sentiment analysis models. This stratified approach ensures that the model is trained on a sufficient amount of data while retaining a representative sample for testing.
7.Scaling:
To ensure consistent numerical representation, Min-Max Scaler was employed to normalize the features, scaling all numerical values to a range between 0 and 1. This scaling is particularly important for algorithms sensitive to input feature scales, improving the convergence of gradient descent and overall model performance.
The scaler model was saved for future use, facilitating consistent scaling of data in subsequent analyses or model deployments, ensuring that the model can be applied reliably to new data.
Methodology
Model Selection
The model selection process for this sentiment analysis project involved identifying suitable machine learning algorithms capable of effectively classifying sentiments based on textual data. Given the nature of the dataset and the binary classification task of distinguishing between positive and negative sentiments, various models were considered for evaluation. The goal was to identify the most accurate and robust model to achieve optimal performance in sentiment classification.
Evaluated Machine Learning Models :
1. Random Forest
The Random Forest classifier is an ensemble learning method that constructs multiple decision trees during training and outputs the mode of the classes for classification tasks. This model was selected for its robustness against overfitting and ability to handle large datasets with higher dimensionality. It also provides feature importance, which aids in understanding the contributions of individual features in sentiment prediction.2. Decision Tree
The Decision Tree classifier is a non-parametric supervised learning method used for classification and regression tasks. Its intuitive tree-like structure makes it easy to visualize and interpret. This model was evaluated for its simplicity and effectiveness in capturing complex relationships in the data, despite its susceptibility to overfitting, which was managed through pruning techniques.3. Logistic Regression
Logistic Regression is a widely used classification algorithm known for its simplicity and effectiveness, especially in binary classification tasks. Selected for its interpretability and efficiency, Logistic Regression is capable of handling large datasets and providing insights into feature significance through coefficients. This model's probabilistic approach aids in understanding the likelihood of each sentiment class, enhancing interpretability in sentiment prediction.4. SVM
Machine is a supervised learning model that performs classification by finding the hyperplane that best separates the classes. SVM was included in the evaluation due to its effectiveness in high-dimensional spaces and its capability to model complex relationships between features. Kernel functions were employed to enhance performance on the non-linear data present in the tweets.Model Evaluation
K-Fold cross-validation is a method used to assess the performance of machine learning models more reliably. The dataset is divided into 10 subsets or folds. The models are trained on 9 folds and tested on the remaining fold, with this process repeated 10 times so that each fold serves as a testing set once. This approach mitigates the impact of data variability and reduces the likelihood of overfitting, ensuring a robust evaluation of model performance.
Evaluation Metrics:
To assess the performance of the machine learning models, several evaluation metrics were employed:
- Training Accuracy: This metric indicates the proportion of correctly classified instances on the training dataset, providing insights into how well the model learns from the training data.
2.Testing Accuracy: This metric measures the proportion of correctly classified instances on the testing dataset, reflecting the model's generalization capability to unseen data.
3.Confusion Matrix: A confusion matrix was utilized to visualize the performance of each model by displaying the true positive, true negative, false positive, and false negative counts. This matrix helps identify the model's strengths and weaknesses in predicting each sentiment class.
4.Predicted Output: The predicted outputs for the test set were generated and analyzed to evaluate the model's effectiveness in classifying sentiments.
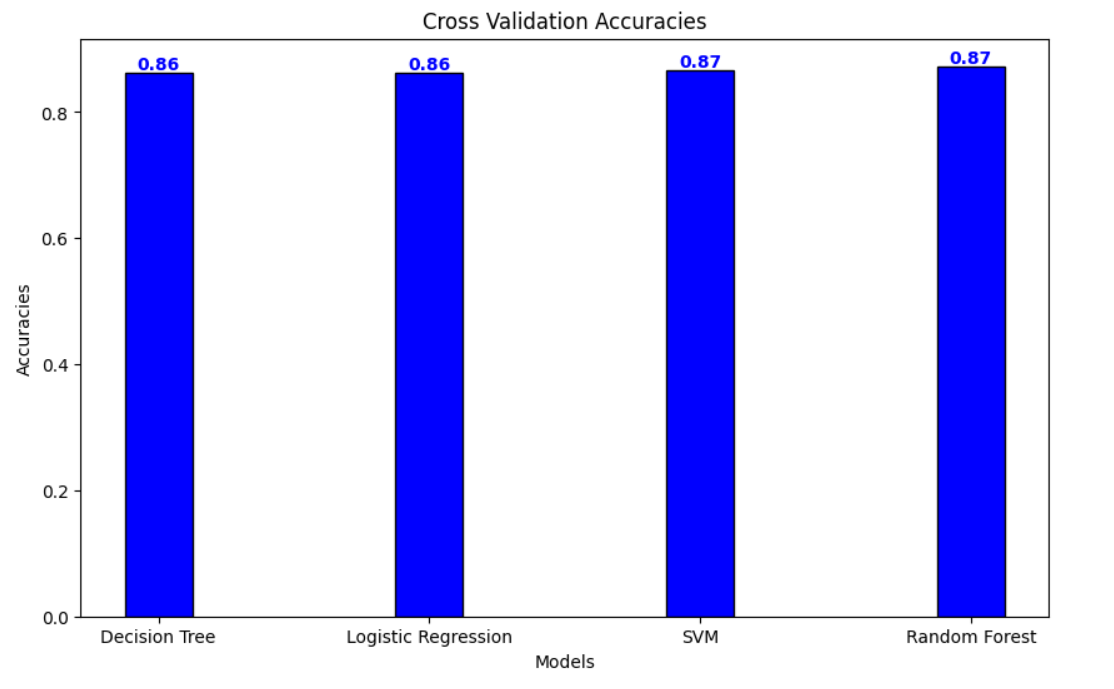
Here is a graph comparing all the accuracies across different models :
Challenges
The following are some challenges faced during the implementation of the System:
-
Ambiguity of Reviews:
Tweets often contain slang, sarcasm, and contextual nuances, making it difficult to accurately classify sentiments. This ambiguity required careful preprocessing and feature extraction to improve the model's understanding of the textual data. -
Imbalanced Data:
The dataset exhibited an imbalance in sentiment distribution, with significantly more positive reviews than negative and neutral ones. This imbalance risked biased predictions, necessitating techniques like oversampling and under sampling to ensure fair assessment across all sentiment categories. -
Data Preprocessing Complexity:
Cleaning the data involved removing noise such as links and mentions while retaining sentiment-bearing words. Balancing thorough cleaning with the retention of meaningful context was crucial for effective preprocessing. -
Feature Selection:
Identifying relevant features for sentiment classification proved challenging. While CountVectorizer helped convert text to numerical form, selecting the right features was essential to avoid noise and ensure meaningful model input. -
Model Overfitting:
Some models, particularly Decision Trees, were at risk of overfitting, performing well on training data but poorly on unseen data. This required careful parameter tuning and the use of techniques like cross-validation to enhance model generalization.
Results
Among all models evaluated, the Random Forest and Support Vector Machine (SVM) classifiers demonstrated the highest performance, closely tying in accuracy for sentiment classification. Both models effectively managed the complexities within the sentiment dataset, achieving a cross-validation accuracy near 0.8728, which reflects their proficiency in distinguishing between positive, negative, and neutral sentiments with a high degree of precision.
The robustness of the Random Forest model, due to its ensemble approach of combining multiple decision trees, provided resilience against overfitting while capturing nuanced patterns within the data. Similarly, SVM’s hyperplane-based classification method proved effective in handling high-dimensional feature space, which is essential for the intricate relationships in sentiment analysis. Evaluation metrics, including confusion matrices, further underscored the models’ consistent performance across diverse sentiment categories.
These results confirm the suitability of Random Forest and SVM as robust options for sentiment classification tasks, offering strong accuracy and reliability that can be scaled across various social media platforms. Their demonstrated stability and high predictive power make them ideal for real-world applications requiring effective sentiment analysis in high-dimensional data contexts.
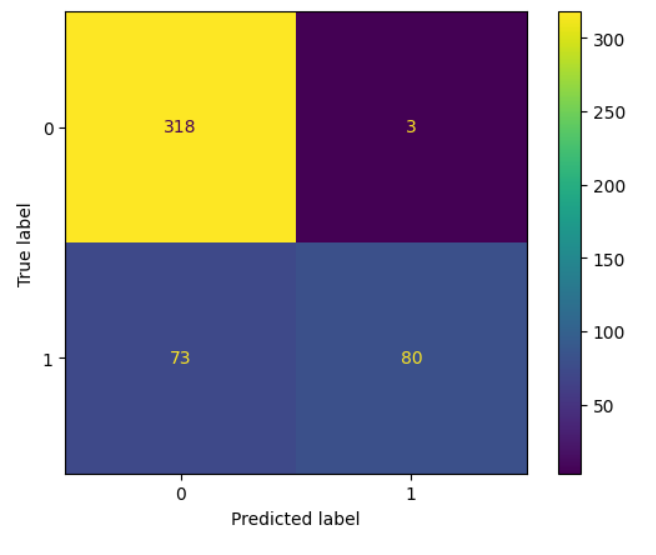
The Confusion Matrix of the Model :
Practical Applications
The sentiment analysis system developed in this project has several practical applications across various domains:
1.Market Research: Companies can monitor public opinion on their products by analyzing tweets, helping gauge customer satisfaction and identify improvement areas.
2.Social Media Monitoring: Organizations can track sentiment regarding events, campaigns, or public figures, allowing for timely responses to public sentiment and enhanced engagement.
3.Customer Service: The system can identify negative sentiments directed at a company, enabling proactive customer service and improving overall service quality.
4.Political Analysis: The system can analyze public sentiment toward candidates or policies, assisting political campaigns in tailoring strategies based on voter perceptions.
5.Brand Reputation Management: Continuous monitoring of sentiment allows companies to manage their reputation, identify potential PR crises, and communicate effectively with their audience.
6.Financial Market Predictions: Investors can analyze sentiments related to stocks or financial news, aiding in informed investment decisions based on public perception.
7.Content Creation and Marketing: Marketers can use sentiment insights to craft targeted campaigns that resonate with audiences, optimizing messaging and enhancing engagement.
8.Public Health: The system can gauge reactions to health campaigns or policies, guiding health organizations in adjusting communication strategies to promote initiatives effectively.
Conclusion
This project successfully developed a sentiment analysis system aimed at classifying sentiments in Twitter data into positive, negative, and neutral categories. Among the various machine learning models evaluated, the Random Forest classifier demonstrated superior performance, achieving a cross-validation accuracy of 87.28%. The corresponding confusion matrix indicated high precision and recall, with a low rate of misclassification, underscoring the model’s robustness in accurately capturing sentiment distinctions.
Throughout the implementation, challenges such as review ambiguity and imbalanced data distribution were addressed through comprehensive preprocessing steps and evaluation techniques, including K-Fold cross-validation. These strategies enhanced the model's reliability and generalizability, ensuring effective performance in real-world sentiment classification tasks.
The outcomes of this project underscore the efficacy of machine learning approaches, particularly ensemble methods like Random Forest, in sentiment analysis. This work not only offers valuable insights into public sentiment but also provides a scalable framework for expanding sentiment analysis capabilities across various social media platforms and diverse applications.