Sentiment Analysis of Product Reviews (Fine-Tuned: bert-base-uncased and microsoft/MiniLM-L12-H384)
Data Collection : The dataset used for this project was an e-commerce dataset available on Hugging Face, containing reviews in Indonesian and English
Data Cleaning: I cleaned the dataset by removing Indonesian reviews and correcting spelling errors. The sentiment was represented by 1 for positive and 0 for negative. Since the dataset only contained training data, I created a test set using the train test split method.
Tokenization: imported the tokenizer from the transformers library of the particular model and applied it to the data
Model Training: I trained two models: bert-base-uncased and microsoft/MiniLM-L12-H384-uncased.
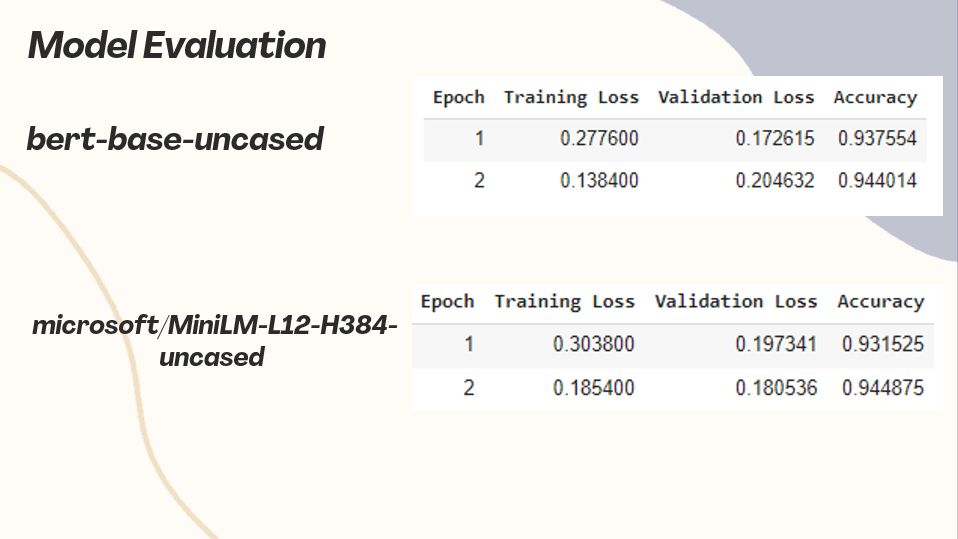
Both models performed similarly in terms of accuracy, but I chose the 𝗺𝗶𝗰𝗿𝗼𝘀𝗼𝗳𝘁/𝗠𝗶𝗻𝗶𝗟𝗠-𝗟𝟭𝟮-𝗛𝟯𝟴𝟰-𝘂𝗻𝗰𝗮𝘀𝗲𝗱 model 𝗪𝗛𝗬 ?
Model Evaluation: Both models performed similarly in terms of accuracy. However, the microsoft/MiniLM-L12-H384-uncased model was chosen due to its lower validation loss, indicating better generalization to unseen data.
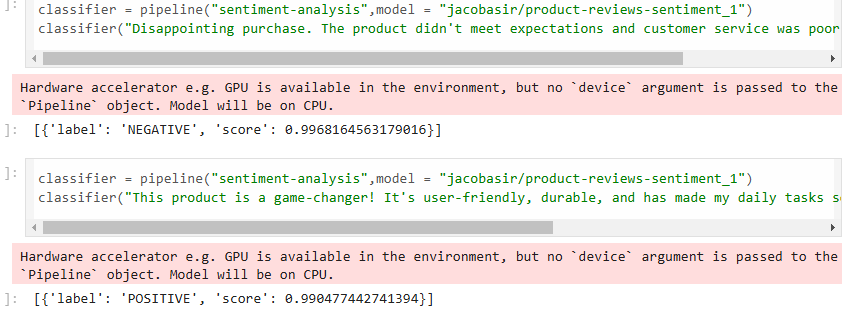
Sentiment Analysis: The trained model was then used to perform sentiment analysis on product reviews, outputting sentiment as either positive or negative.