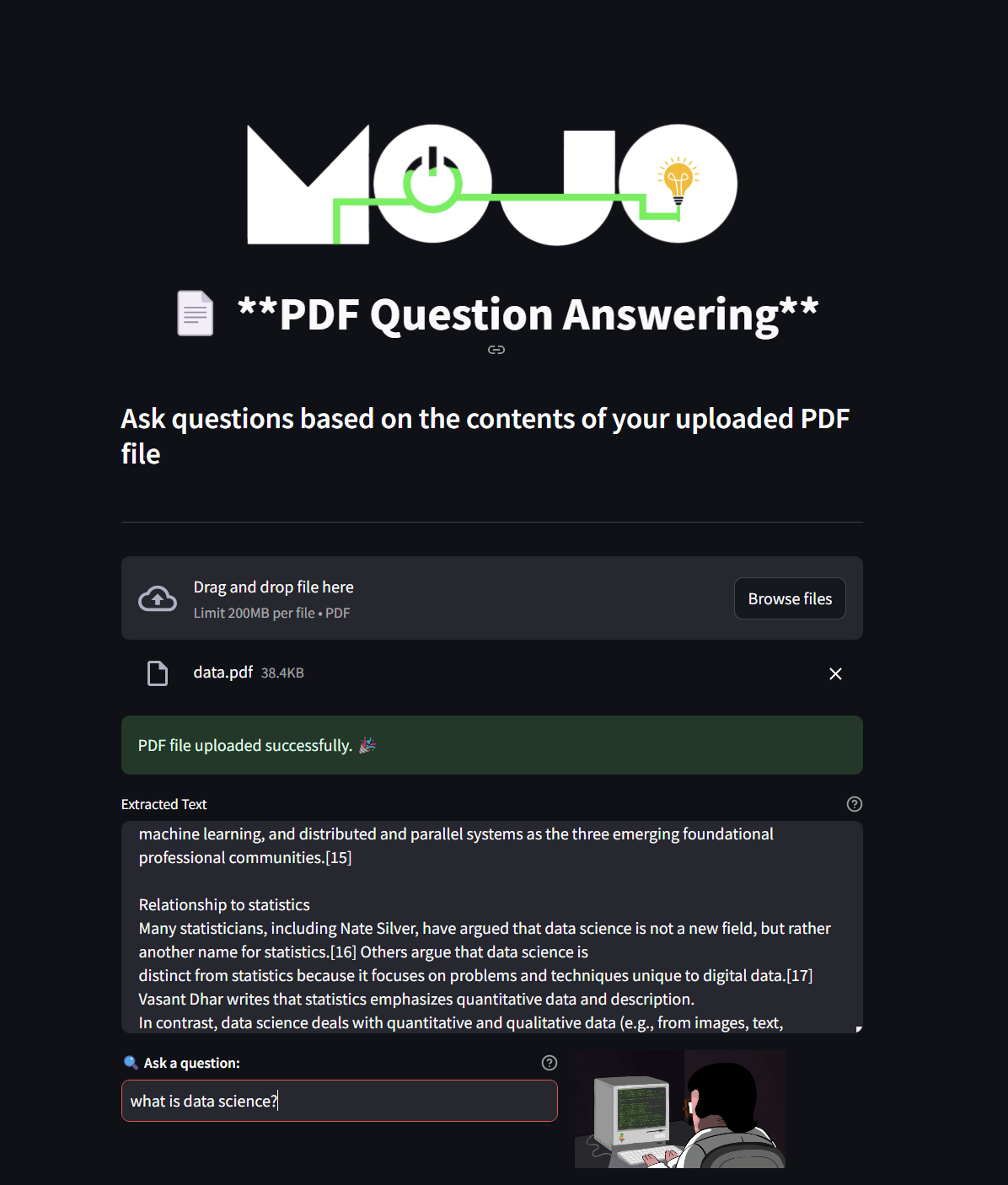
This repository contains a Streamlit application that allows users to upload a PDF file and ask questions based on its content. The app leverages LangChain for text splitting and vector store management, Cassandra as the vector store, and Google’s Generative AI for embeddings and language modeling.
Tip: This guide includes code snippets, images, and helpful links to enhance your experience with the application.
PDF Upload: Easily upload a PDF file to extract text.
Text Extraction: Extract and preview text from the PDF.
Vector Store Integration: Store text chunks in a Cassandra vector store.
Question Answering: Ask questions about the content, with relevant context provided.
Interactive UI: A clean and user-friendly interface built with Streamlit.
Before running the app, ensure you have the following installed:
Python 3.8+
Streamlit
LangChain
Cassandra Driver
PyPDF2
Google Generative AI Libraries
python-dotenv
Additionally, you must have access credentials for Astra DB and Google’s API.
Clone the Repository:
git clone https://github.com/MbeleckBerle/langchain_qa_app.git
cd pdf-qa-app
Install Dependencies:
pip install -r requirements.txt
Environment Variables:
Create a .env file in the root directory and add your API keys and Astra DB details:
ASTRA_DB_APPLICATION_TOKEN=your_astra_db_application_token
ASTRA_DB_ID=your_astra_db_id
GOOGLE_API_KEY=your_google_api_key
To launch the application, run:
streamlit run app.py
Then open your browser and navigate to the local URL (typically http://localhost:8501).
Streamlit: https://docs.streamlit.io/
LangChain: https://python.langchain.com/v0.1/docs/get_started/installation/
Cassandra documentation: https://docs.datastax.com/en/astra-db-serverless/cql/develop-with-cql.html
Google Generative AI: https://ai.google.dev/gemini-api/docs/models/gemini
This PDF Question Answering App is a great example of integrating document processing with state-of-the-art AI capabilities. Feel free to modify and extend the application to suit your needs. If you encounter any issues or have suggestions, please open an issue on the GitHub repository or submit a pull request.
from langchain.vectorstores.cassandra import Cassandra from langchain.indexes.vectorstore import VectorStoreIndexWrapper from langchain.llms import OpenAI from langchain.embeddings import OpenAIEmbeddings from datasets import load_dataset # support for dataset retrieval with Hugging Face import os import cassio # to integrate with Astra DB from PyPDF2 import PdfReader
ASTRA_DB_APPLICATION_TOKEN = os.environ["ASTRA_DB_APPLICATION_TOKEN"] ASTRA_DB_ID = os.environ["ASTRA_DB_ID"]
pdfreader = PdfReader("./data.pdf")
from typing_extensions import Concatenate # read text from pdf raw_text = "" for i, page in enumerate(pdfreader.pages): content = page.extract_text() if content: raw_text += content raw_text
cassio.init(token=ASTRA_DB_APPLICATION_TOKEN, database_id=ASTRA_DB_ID)
from langchain_google_genai import GoogleGenerativeAIEmbeddings import os GOOGLE_API_KEY = os.environ["GOOGLE_API_KEY"] embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001") vector = embeddings.embed_query("hello, world!") vector[:5]
from langchain_google_genai import GoogleGenerativeAIEmbeddings from langchain_google_genai import GoogleGenerativeAI import os llm = GoogleGenerativeAI(model="gemini-1.5-flash", google_api_key=GOOGLE_API_KEY) embedding = GoogleGenerativeAIEmbeddings(model="models/embedding-001") # print( # llm.invoke( # "What are some of the pros and cons of Python as a programming language?" # ) # ) len(embedding.embed_query("hello, world!")), embedding.embed_query("hello, world!")
astra_vector_store = Cassandra( embedding=embedding, table_name="qa_mini_demo", session=None, keyspace=None, )
from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter( separator="\n", chunk_size=800, chunk_overlap=10, length_function=len, ) texts = text_splitter.split_text(raw_text) texts[:5]
astra_vector_store.add_texts(texts) print("Inserted %i headlines." % len(texts)) astra_vector_index = VectorStoreIndexWrapper(vectorstore=astra_vector_store)
first_question = True while True: if first_question: query_text = input("\nEnter your question (or type 'quit' to exit): ").strip() else: query_text = input( "\nWhat is your next question? (or type 'quit' to exit): " ).strip() if query_text.lower() == "quit": break if query_text == "": continue first_question = False print('\nQUESTION: "%s"' % query_text) answer = astra_vector_index.query(query_text, llm=llm).strip() print('ANSWER: \%s ..."\n' % answer) print("FIRST DOCUMENT BY RELEVANCE: ") for doc, score in astra_vector_store.similarity_search_with_score(query_text, k=4): print(' [%0.4f] "%s .."' % (score, doc.page_content[:84]))