Abstract
This document outlines a computer vision-based system to identify food products in supermarket settings from shelf images. The system employs object detection techniques to assist tasks such as aiding visually impaired customers and automating inventory management. The project involves developing a method to identify product instances, their dimensions, and positions in the image from corrupted images. The task is addressed for both single instance and multiple instance detection.
Methodology
The development of the system combines two interconnected tracks to tackle the challenges of product detection in shelf images. Initially, a baseline object detection model is developed to identify single instances of products by leveraging SIFT (Scale-Invariant Feature Transform) for feature extraction and FLANN (Fast Library for Approximate Nearest Neighbors) for feature matching. These techniques enable accurate matching of reference images to scene images, laying the groundwork for reliable product identification.
Starting from this foundation, the system extends its capabilities to detect multiple instances of the same product. This involves incorporating advanced filtering techniques that analyze geometric constraints and color information to refine matches, eliminate false positives, and accurately identify overlapping or repeated instances. Together, these tracks ensure robust detection of both single and multiple product instances, addressing the diverse scenarios encountered in supermarket shelf environments.
The overall methodology encompasses several key steps:
-
Dataset Preprocessing: Prepare the data for processing, reference images and scene images are first preprocessed. This involves applying different filters to clean the corrupted image, guaranteeing to enhance the feature extraction process.
-
Feature Matching: Once the images are preprocessed, SIFT is employed to extract distinctive features from both reference and scene images. These features are then matched using FLANN, which efficiently identifies correspondences between the two sets of features. This step is critical for establishing initial matches that serve as the foundation for further analysis.
-
Post-Matching Filtering: The raw matches obtained from FLANN are further refined using a combination of geometric and color-based filters. By analyzing the spatial distribution of features and comparing color histograms, the system identifies and discards false positives. This filtering process ensures that only the most reliable matches are retained for subsequent stages.
-
Instance Detection: After filtering, the system computes bounding boxes for each detected instance. This involves determining the dimensions (width and height) of the bounding box and calculating its center position in the image reference system. These metrics provide a comprehensive description of each detected instance and facilitate their visualization.
-
Visualization: To present the results in an intuitive and accessible format, the system overlays bounding boxes on the original shelf images. These visualizations highlight the detected products and their locations, making it easy to verify the accuracy of the detections.
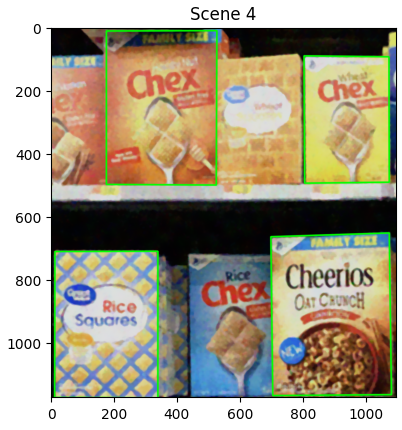
This structured methodology ensures that the system is both robust and scalable, capable of handling the diverse challenges associated with product detection in supermarket settings. Further details on the implementation are in the attached notebook, where each step is accurately described.
Results
The algorithm almost achieves 100% of accuracy in both single and multiple instance detection, managing to success in it sometimes in the multiple one. It is possible to reach the perfection by designing a specific approach for each case and setting specific thresholds. However, it has been taken the decision to keep a unique set of thresholds to guarantee better generalisation capabilities and solidity for an algorithm that ensures good performances in any possible application.