Abstract
In an era where precise and accurate communication is essential across various professional fields, the ability to generate long-form text that meets high standards of professionalism and contextual relevance is increasingly important. Traditional methods of text generation often struggle with maintaining coherence, context, and adherence to domain-specific norms, particularly when dealing with complex and lengthy content. In response, this study explores the potential of large language models (LLMs) to produce high-precision, accurate, and contextually appropriate long-form text across specialized domains.
This work investigates how well-designed AI Agent architecture could be applied produce high-precision and highly accurate AI-generated texts for use in compliance processes. These techniques enhance the ability of AI systems to generate text that not only meets specific stylistic and content requirements but also remains coherent and factually accurate over extended passages. The central research question guiding this study is: "How can large language models be optimized to improve precision and accuracy in generating long, professional texts?" By leveraging few-shot learning for domain adaptation, task decomposition for managing complexity, and RAG for integrating relevant knowledge, this work aims to advance the capabilities of LLMs in producing professional-grade content.
The results indicate that the proposed methodologies significantly enhance the accuracy, coherence, and reliability of AI-generated long-form text. This research contributes to the broader field of AI-driven text generation, offering practical in sights into optimizing LLMs for use in professional environments where precision and context are paramount.
Methodology
We used Streamlit to build the frontend interface, and FastAPI to build the backend API. For the backend, we utilized the LlamaIndex framework to construct the pipelines. We also deployed an Open-Source LLM using HuggingFace Text Generation Inference (TGI) on a Windows 11 computer equipped with an NVIDIA GeForce RTX 4070 Ti GPU (12GB VRAM), and queried GPT-4o using an OpenAI API Key.
Frontend Design
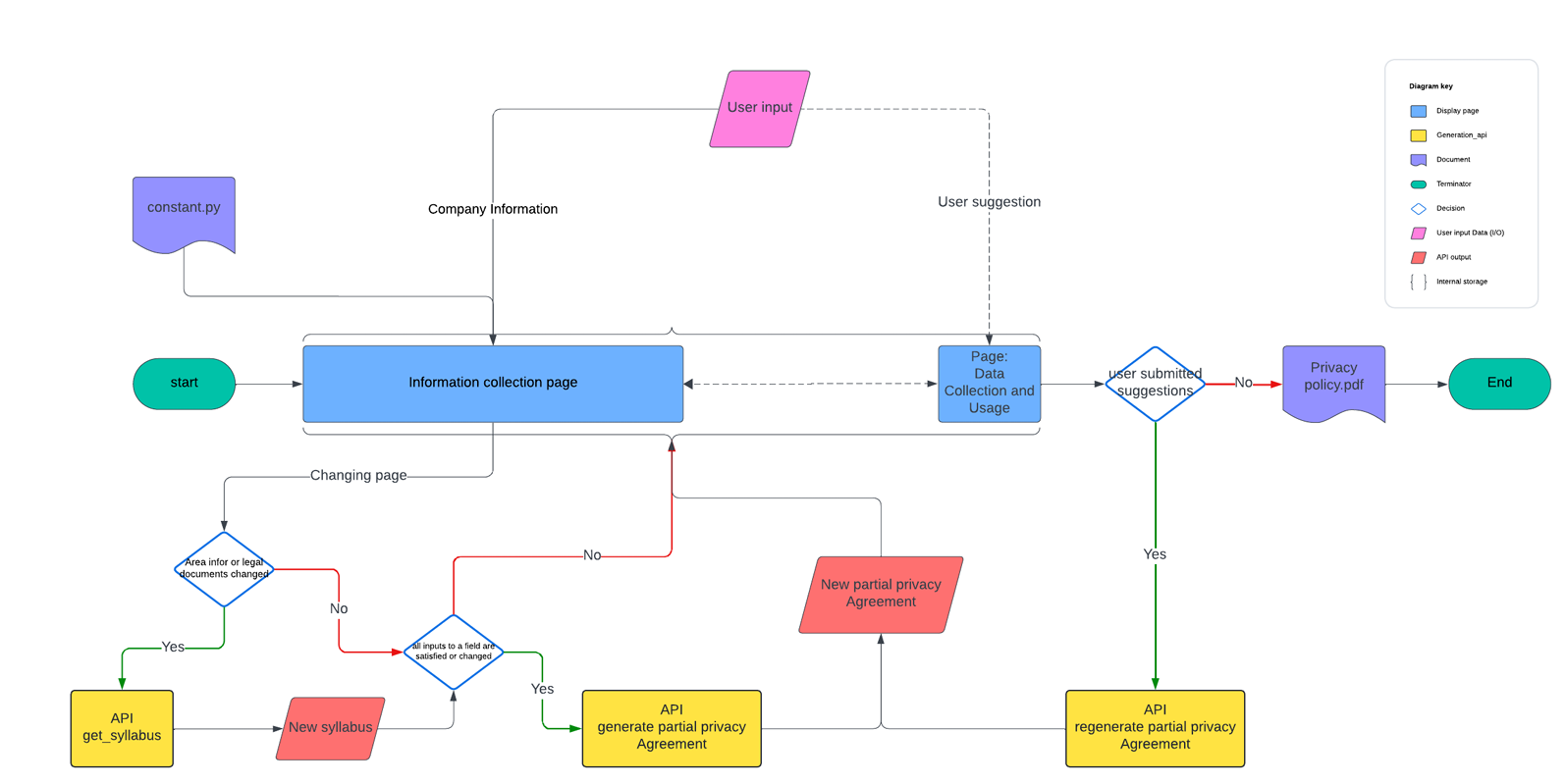
Structured workflow composed of six key steps. Each step represents a crucial part of the overall process, from initializing parameters to finalizing and downloading the privacy policy.
The six steps are interlinked, each building upon the previous one to create a seamless user experience that integrates effectively with backend APIs. Through this design process, the front end can more easily collect user input and transmit it to the back end, and then more effectively support AI agents to generate customized privacy policies to meet user needs.
Backend Design
The concern about whether the generated privacy policies were truly compliant with the specified regulations was directly tied to our core research question: how can LLMs generate long and professional text? In the previous stage, GPT-4o judged its own outputs within the ReAct framework through a process known as self-reflection. While GPT-4o’s broad pre-training on a wide range of text from various domains gave it strong generalization capabilities, it lacked the specialized expertise required to ensure compliance with legal regulations.
In real-world scenarios, when someone without a legal background needs to draft a privacy policy and ensure it complies with relevant regulations, the most reliable approach is to consult a lawyer who can review the draft and provide expert advice. This real-life practice inspired us to incorporate a similar approach into our system by finding another LLM that had been supervised fine-tuned (SFT) using data from the legal domain. Fine-tuning a model on domain-specific data enhances its performance and professionalism within that particular area, allowing it to provide more accurate and relevant outputs.
After evaluating available options, we selected Saul-7B-Instruct-v1, a LLM specifically tailored for the legal domain. Saul-7B-Instruct-v1 is an instruction-tuned model specifically tailored for the legal domain. Built on the Mistral 7B architecture, SaulLM-7B was trained on an extensive English legal corpus of over 30 billion tokens, giving it state-of-the-art proficiency in understanding and processing legal documents. Additionally, a novel instructional fine-tuning method with specialized legal datasets further enhances its performance in legal tasks.
Here are the SOP of generating a privacy policy based on user input:
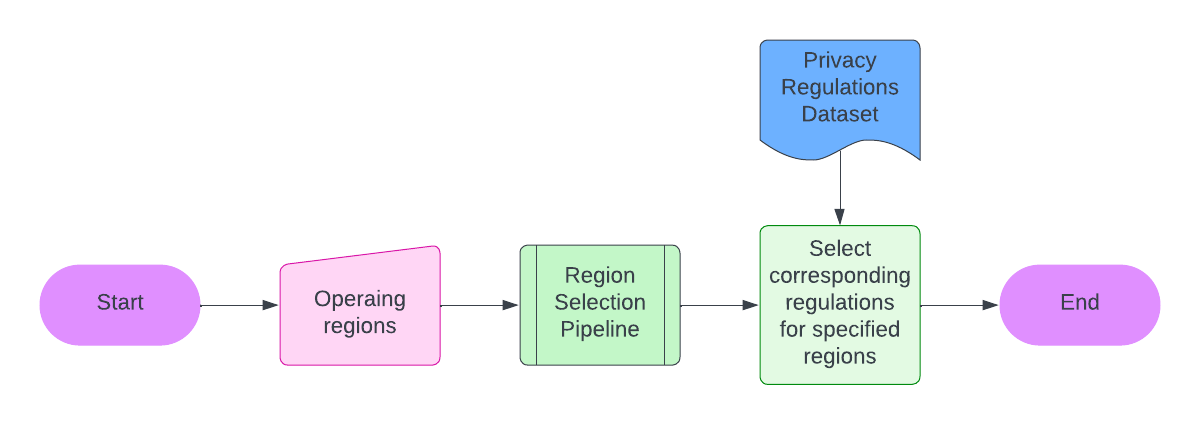
- Regulation Selection: Based on the user's specified operation regions, select the corresponding pre-defined regulation regions. Identify the regulations that the privacy policy needs to comply with, including any user-uploaded regulations.
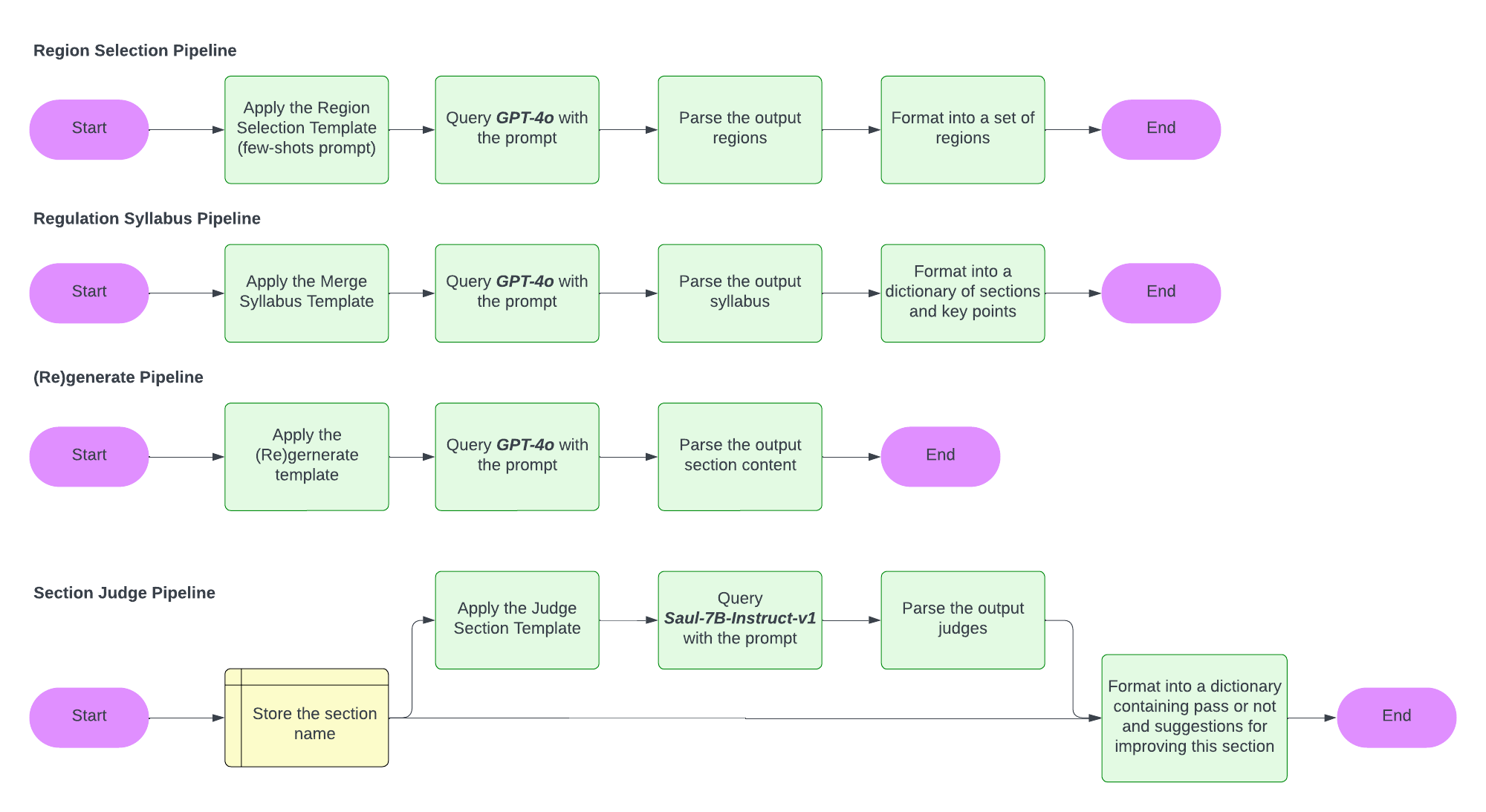
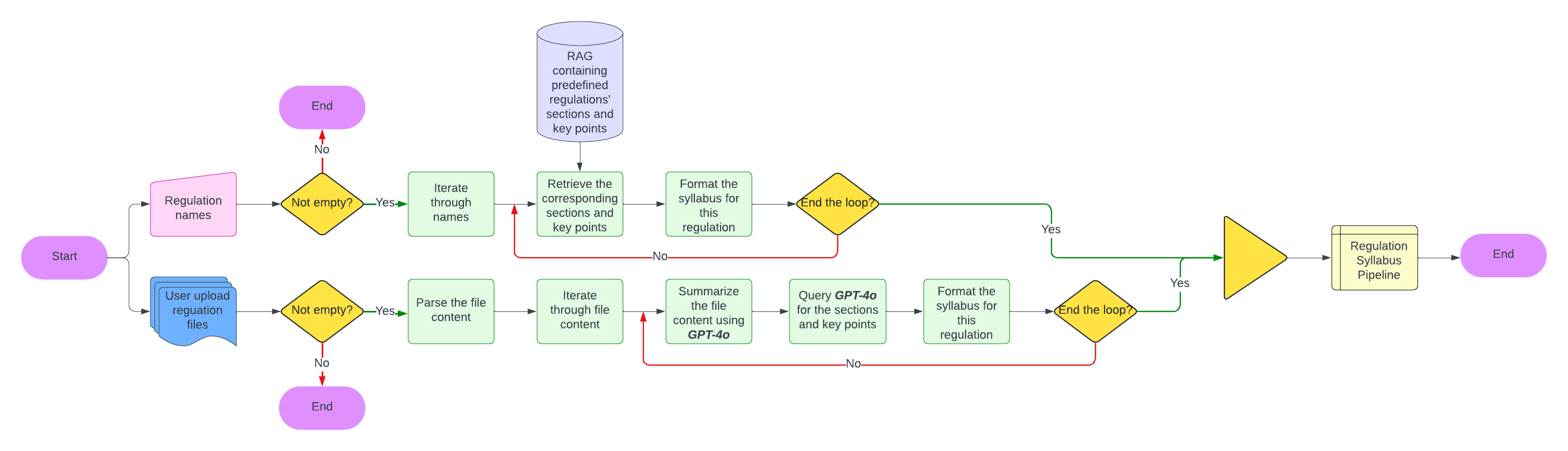
- Syllabus Generation: Using the selected regulations, generate a syllabus containing 12 key sections that must be addressed for regulatory compliance. If the regulations are pre-defined, retrieve the syllabus from the RAG system to save time and reduce token usage. GPT-4o then merges the syllabi from each selected regulation into a single comprehensive syllabus.
- Section-by-Section Generation and Evaluation: With the syllabus and user input, GPT-4o generates the privacy policy section by section. After each section is generated, SaulLM-7B evaluates it for compliance with the relevant regulations and suggests any necessary improvements. This process combines GPT-4o’s generalization abilities for drafting with SaulLM-7B’s legal expertise to ensure that the final policy is both professional and compliant.
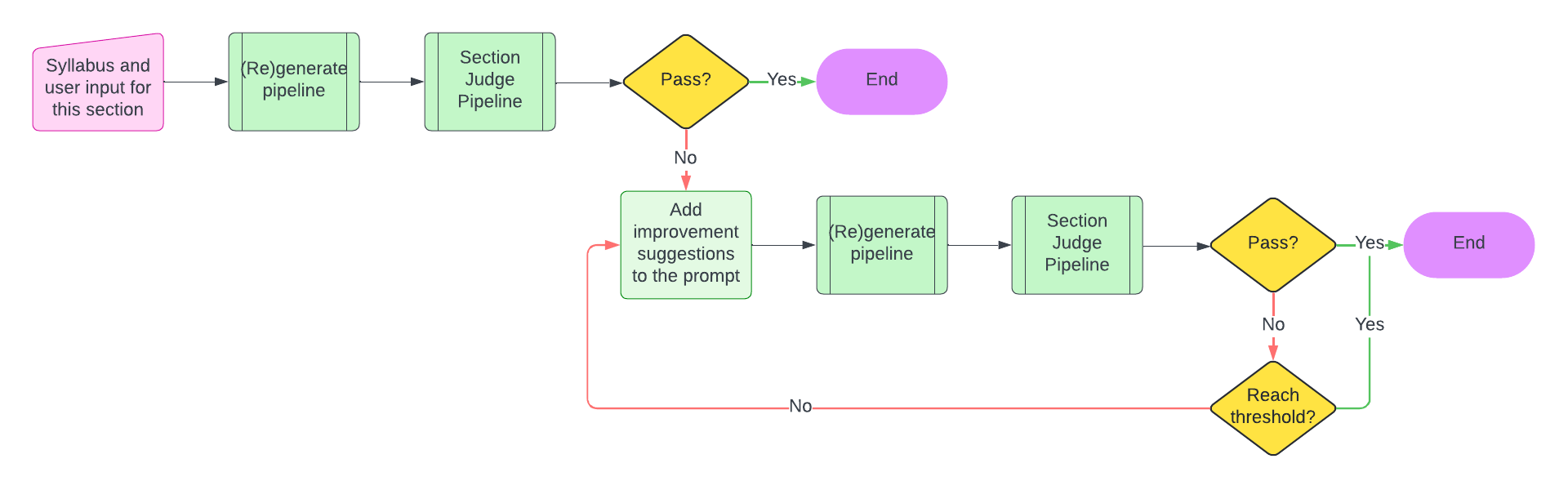
By combining the strengths of these two models, we significantly improved the reliability and accuracy of the generated privacy policies, addressing the key challenge that had driven us to this final stage of development.
Results
Law LLM Review

Section Generated
