
link on github
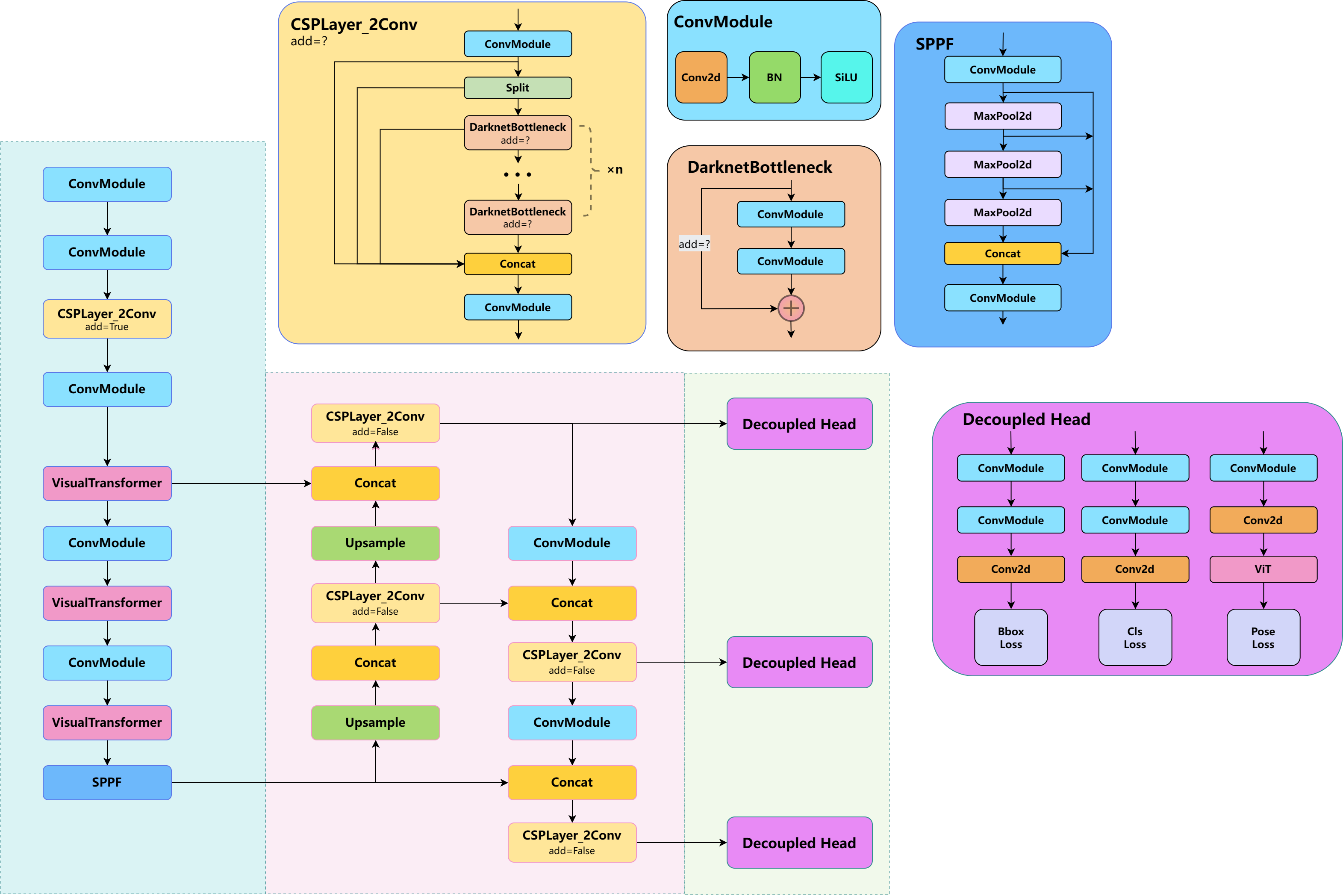
This project is based on YOLOv8
🔥Abstract
Inspired by traditional bird deterrent methods for power transmission lines and recent technologies related to bird damage recognition based on machine learning, this work proposes an object detection algorithm improved based on the YOLOv8 architecture, combined with the attention mechanism of Visual Transformer, to accomplish the task of bird pose recognition from a single frame image. Firstly, keypoint regression was used to design bird keypoints and skeletons, and a dataset containing bounding boxes and keypoints of bird targets was constructed, along with data augmentation work to optimize the distribution of the dataset and ensure the generalization performance of the model. Then, a convolutional output network was designed and trained to map keypoints to classification, and the corresponding dataset was trained with the YOLOv8 model for prediction, thereby verifying the feasibility and advantages of keypoint-based pose recognition from a single frame image with a simple architecture. At the same time, the original loss function was improved in conjunction with the characteristics of keypoint regression to assist the model in converging. The multi-head self-attention mechanism was also applied to the main trunk network and the decoupled head of the model, overcoming the receptive field issue of the convolutional structure and effectively improving the model's accuracy.
🔥Method
Bird Keypoint Design
The label structure of the dataset is based on the following image:
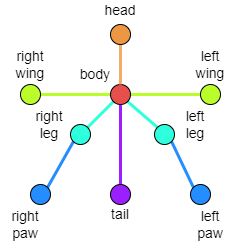
YOLOv8 Bird Keypoint Dataset
The overall format of the COCO dataset labels for YOLO keypoints is as follows:
<class-index> <x> <y> <width> <height> <px1> <py1> <p1-visibility> <px2> <py2> <p2-visibility> …<pxn> <pyn> <p2-visibility>
- The number of rows in the annotated data corresponds to the number of targets in a single image, with each row representing one target, including the classification label, a bounding box (1), and a keypoint array (9) for annotations. The bounding box is located based on its center, and since not all 9 keypoints may appear for each target, a status value must be annotated for the keypoints. When a keypoint does not exist, the loss for that keypoint regression will be excluded.
Data Augmentation
YOLOv8 comes with several data augmentation techniques. I implemented a similar one. If you need to use it additionally, the project also provides this script. The process is as follows: provide a background folder containing various background images without birds, slightly enlarge the bounding boxes of the annotated bird dataset, and paste them onto the background images. You can choose to paste multiple targets and set the scaling factor.
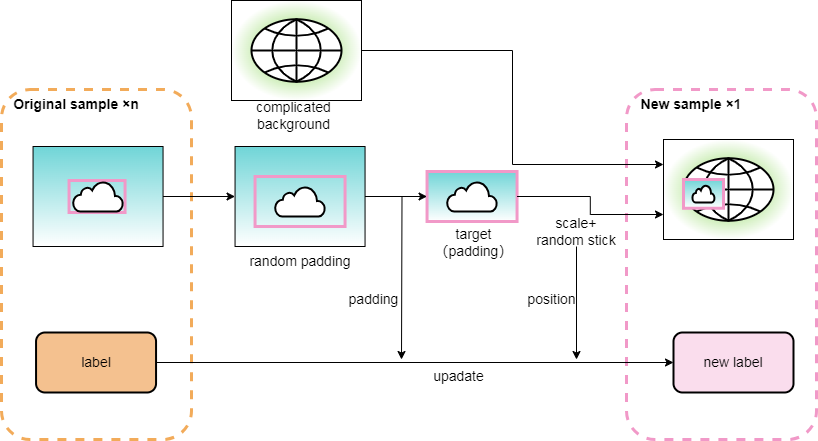
The results are shown in the following image:

Keypoints -> Pose Classification
By connecting an external convolutional output network to the YOLOv8 keypoint output, pose classification can be obtained. The network structure is very simple, which reflects the efficiency of keypoint detection for pose estimation. This output network can be trained separately from YOLOv8, allowing for different output networks to be designed for various tasks.
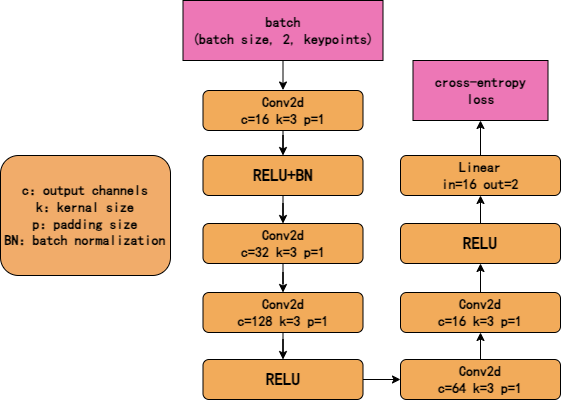
Annotated datasets to train this network:
I wrote an annotation script using Python's Tkinter library, which displays the annotated images sequentially and allows the corresponding targets to be selected one by one. The classification is achieved by typing 0 or 1 on the keyboard, generating the corresponding label file in the format:
<class-index> <px1> <py1> <px2> <py2> …<pxn> <pyn>

New Loss Function
You can choose to use the newly designed loss function for training:
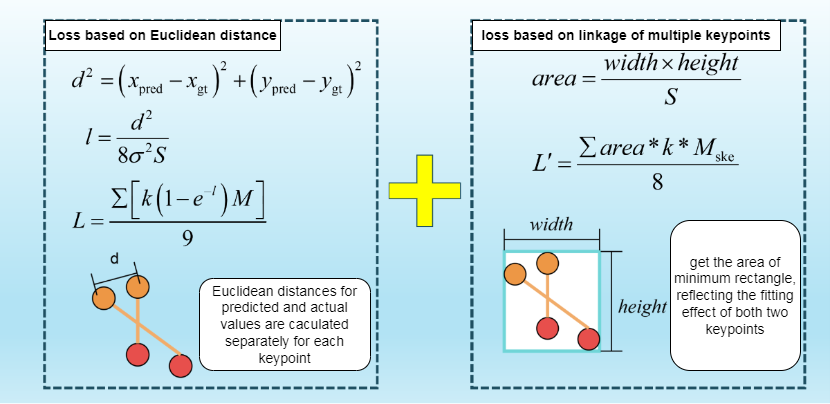
The following figure illustrates the predictive effects of the loss function before and after improvement, with the left side of each group of images representing the loss function before improvement and the right side representing the improved one. It can be seen that using the new loss function can make the model's prediction of details such as the wings and legs of birds more accurate, indicating that the new loss function can enhance the model's learning ability for overall posture and structure.

New Network with ViT
The Vision Transformer (ViT) is a type of neural network architecture that applies the principles of Transformer models, originally designed for natural language processing, to computer vision tasks by treating images as a sequence of patches or pixels, enabling the model to learn contextual relationships across the entire image. It is an excellent work which bring the attention mechanisms from NLP to CV.
I transplanted the ViT module to YOLOv8 and you can choose whether to use the ViT module to change the network structure (it will be slower):
🔥Experiments
Ablation Experiments
To verify the effects of various improvements, this work also conducted ablation experiments (on NVIDIA Geforce GTX 1650 Ti), and the results are shown in the table below (due to computational power limitations, the models may not have achieved optimal performance, and the data is for reference only). It can be seen that the use of the improved loss function indeed provides a significant boost to the mAP of pose, with noticeable improvements in both mAP50 and mAP50-95, indicating that the added loss for keypoint interaction aids in the model's overall pose regression. In a sense, the avian skeleton is used as prior knowledge to provide direction for model convergence, assisting the original fitting to the Euclidean distance of keypoints. At the same time, due to the increase in pose loss, the model pays more attention to the regression of keypoint detection, which slightly decreases the effect on bounding box regression.
The introduction of the ViT module significantly improves the precision of keypoint regression, indicating that the pixel-level patch design helps the model focus on the details of the entire image. The attention mechanism, unlike the convolutional structure, is not limited by a fixed receptive field, and even when dealing with feature sequences up to 80×80 in length, it can easily achieve global information interaction.
By integrating the two improvements to train the model, it can be seen that the integrated group model has achieved an overall improvement in indicators, demonstrating that the new model can combine the advantages of both modifications. However, this also significantly increases the training time (which is obviously a huge strain on my graphics card).
| POSE | POSE | POSE | POSE | BOX | BOX | BOX | BOX | |
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | mAP50 | mAP50-95 | Precision | Recall | mAP50 | mAP50-95 | |
| Control Group | 0.917 | 0.871 | 0.883 | 0.511 | 0.985 | 0.965 | 0.992 | 0.801 |
| Loss | 0.912 | 0.872 | 0.897 | 0.541 | 0.975 | 0.967 | 0.988 | 0.804 |
| ViT | 0.92 | 0.893 | 0.893 | 0.507 | 0.985 | 0.974 | 0.989 | 0.795 |
| Integrated Group | 0.92 | 0.878 | 0.893 | 0.521 | 0.986 | 0.979 | 0.993 | 0.799 |
Prediction
This work also evaluates and analyzes the predictive performance of the model using images and videos.
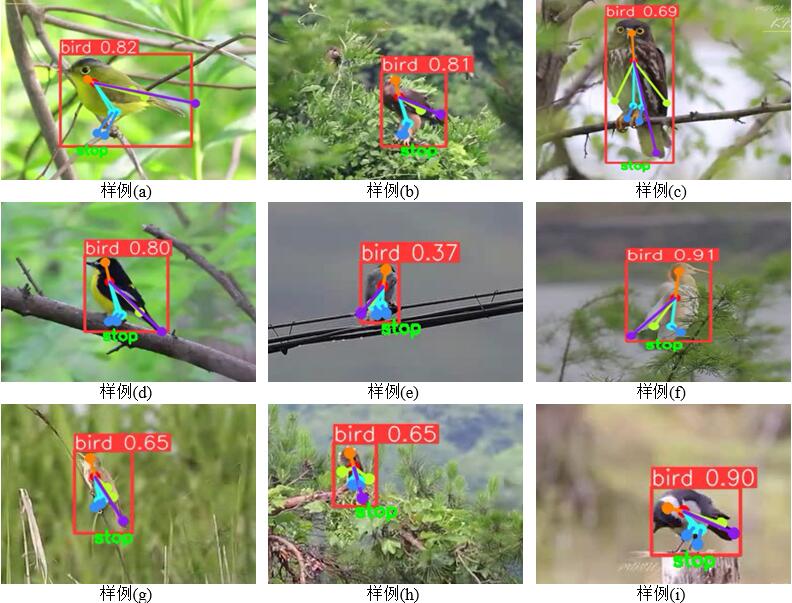
For the Integrated Group, the above figure shows the target recognition of birds perched under various environmental conditions, including scenarios such as perched on tree branches, canopies, power lines, reeds, and wooden stakes, all of which can effectively detect birds. It is capable of recognizing both large and small targets, sufficiently meeting the common scenarios encountered in practical use. When the lighting is dim (e), the color difference between the bird and the background is weak, resulting in lower recognition confidence. The recognition effect is also good in cases of slight occlusion (f) or when the background blends with the target (h). The keypoint recognition is relatively reasonable under various circumstances, and even for the downweighted bird legs, the model can make decent predictions.

The above figure demonstrates the target recognition of birds in flight under various conditions. The recognition effect is good for both close-up and distant views of birds. Even when the birds are in motion at high speeds, causing blur (b, g, h, i), it does not affect the judgment of the key points of the wings. Although there may be errors in the judgment of the legs (h), it verifies that less important keypoint features such as legs and claws do not affect the recognition of posture. It can also correctly identify the bounding box and key points of birds under special conditions like snowy weather (i), confirming the effectiveness of a series of data augmentation operations and overcoming the issue of insufficient diversity in the dataset. It can also normally recognize a small number of multiple targets (a).
Comparing the predictions of flying and perching states horizontally, whether it is keypoint or bounding box prediction, the recognition of birds in flight is more stable and has better generalization performance, capable of dealing with poor image quality and complex environments. This may be due to a larger number of samples of birds in flight in the dataset's annotation, and the features of birds in flight are quite distinct. Moreover, the background tends to be empty during flight, and the different focusing effects brought by depth of field may also contribute to the recognition of birds.
It is worth noting that when recognizing flying postures, the model often does not judge the presence of legs and claws, while in perching states, it can stably determine the presence of legs. This may indicate that the model has learned some regular knowledge about the posture of birds, but it will not make mistakes due to a high dependence on this rule. At the same time, the experiment further verifies the effectiveness of key points in a single frame image for judging the state of birds. In most cases, even if the key point prediction is not very accurate, the model can make a relatively accurate judgment of the bird's posture, confirming that a simple output network can handle keypoint-based posture discrimination tasks through simple training.

As shown in the figure above, there are also many situations where the model struggles to recognize birds. For instance, when birds are preening their feathers (a, b), the model has difficulty identifying them due to a lack of similar images in the dataset and the significant difference between this state and other states. There are also birds with particularly unique appearances (c, f) that the model cannot recognize. The model may also have trouble distinguishing birds when the background is misleading (i), when the background heavily obscures the bird (d, e), or when the bird is highly integrated with the background (g). When there is an excessive number of targets (h), the model might fail to identify all targets due to the influence of the bounding box IoU threshold. Overall, the main reason is likely the insufficient size and complexity of the dataset, even though data augmentation can address some issues such as those caused by adverse weather conditions.
🔥Conclusion
This work centers around the YOLOv8 algorithm, designing a bird keypoint skeleton and annotating a dataset that includes bounding boxes and keypoints. Basic data augmentation was completed, and data augmentation for multiple targets was achieved through stitching, resulting in a dataset with multi-target and small-target capabilities. Additionally, an external convolutional output network was constructed to map keypoints to bird pose judgment, verifying the feasibility of keypoint prediction. Following this, on the existing technology of YOLOv8, a new keypoint regression loss function was designed, and the visual domain attention mechanism of ViT (Vision Transformer), a hot topic in the field, was applied to improve the original YOLOv8 architecture. Ultimately, a model was developed that can stably recognize most common scenarios involving birds and their poses. I draw the following conclusion:
- This work initially designed a custom bird keypoint skeleton, focusing on the head, tail, and wings as primary features, and annotated the corresponding dataset. By implementing the proposed data augmentation scheme, the complexity of the background, the number of multi-target and small-target samples were effectively increased, which in turn significantly enhanced the quality of the dataset and provided a safeguard for the model's generalization capabilities.
- The externally designed convolutional output network in this work has consistently and stably judged the pose of targets in subsequent experiments. Even when there is a slight instability in keypoint regression, it can still make correct judgments in most cases. The simple external network structure has proven the efficiency of keypoint regression for pose recognition, demonstrating that keypoints can provide sufficient and concise semantic information for pose recognition, enabling pose detection based solely on a single frame image as input.
- The loss function designed in this work is centered around the area of the minimum rectangle that encompasses both the predicted and true line segments, which can coordinate the regression between keypoints and provide effective guidance for the model's overall learning of the skeleton.
- This work has adapted the attention module from the ViT (Vision Transformer) to the main trunk network and the decoupled head's POSE part of YOLOv8. This adaptation allows the model to overcome the limitations of the receptive field of a pure convolutional network during feature extraction and analysis, offering considerable assistance to the model's learning capabilities.
- The final model is capable of providing robust predictive performance across a variety of common scenarios, with high accuracy in keypoint regression and pose classification. However, it struggles with a few complex situations, which is inferred to be due to the dataset's lack of richness, unable to cover a greater variety of bird species, more complex backgrounds, and a broader range of bird sub-poses.