Year: 2024
This project introduces a prototype perception system for feature-based Visual Simultaneous Localization and Mapping (Visual SLAM), specifically designed for a Formula Student autonomous race car. The study focuses on achieving real-time localization and enhanced situational awareness by determining the vehicle's position and mapping its surroundings within a cone-defined track. To detect the cones, a fine-tuned version of the YOLOv8 object detection algorithm is utilized. The system's performance is evaluated using both indoor and outdoor video datasets captured with an Intel RealSense D455 RGB-D camera, tested under diverse lighting conditions and environmental settings.
In the Formula Student Driverless competition, our project focuses on developing a perception system that enables an autonomous vehicle to understand its environment and localize itself within an unknown circuit. The circuit is defined by cones of various types placed at different distances, which the system must detect and classify. This task, commonly referred to as Simultaneous Localization and Mapping (SLAM), involves processing sensor data to construct a map of the circuit while simultaneously determining the vehicle's position. The system must accurately report the vehicle's real-time coordinates within a reference frame and identify the locations and classifications of cones encountered during the lap, in compliance with competition rules.
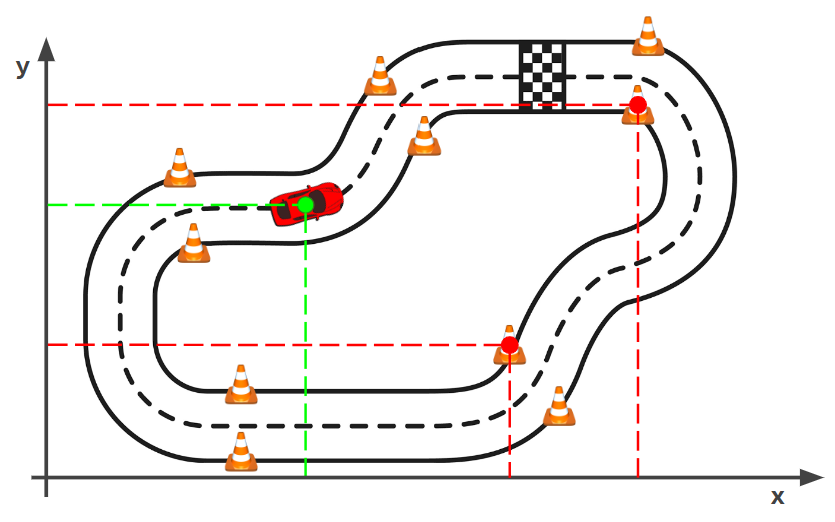
Figure 1
The report is structured as follows: we begin with a concise overview of relevant background concepts. Next, we describe the hardware and sensors utilized in our solution. We then outline our proposed methodology for developing the perception system, followed by a description of the experimental setup. Subsequently, we present and analyze the results. Finally, the "Conclusion and Future Work" section summarizes the key findings and explores potential research directions to improve our approach.
In the following, we briefly summarize the main theoretical aspects related to this work.
This project aims to address the SLAM (Simultaneous Localization and Mapping) problem by tracking the location of an autonomous agent over time while incrementally constructing a virtual representation of its environment. Leveraging the visual sensors at our disposal (see below), we utilize a Visual SLAM algorithm with an RGB-D camera setup.
Visual SLAM approaches are typically categorized by camera configurations—Monocular, Stereo, Multi-view, and RGB-D—and by methodology: feature-based or direct methods. Feature-based methods estimate camera motion by minimizing the projection error between image features and a local map, while direct methods operate on image pixel intensities and are better suited for 3D reconstruction.
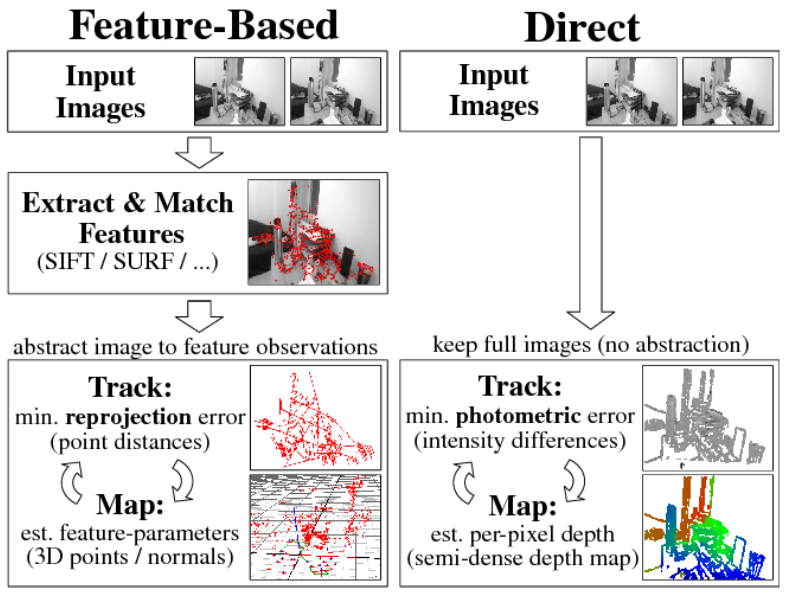
Figure 2
For this work, we adopted OrbSLAM [1], a feature-based Visual SLAM system renowned for its real-time performance in diverse environments. We began by studying OrbSLAM2 [2] to understand its code structure, then progressed to OrbSLAM3 [3] which is, to the best of our knowledge, recognized as one of the most robust and accurate system in the field.
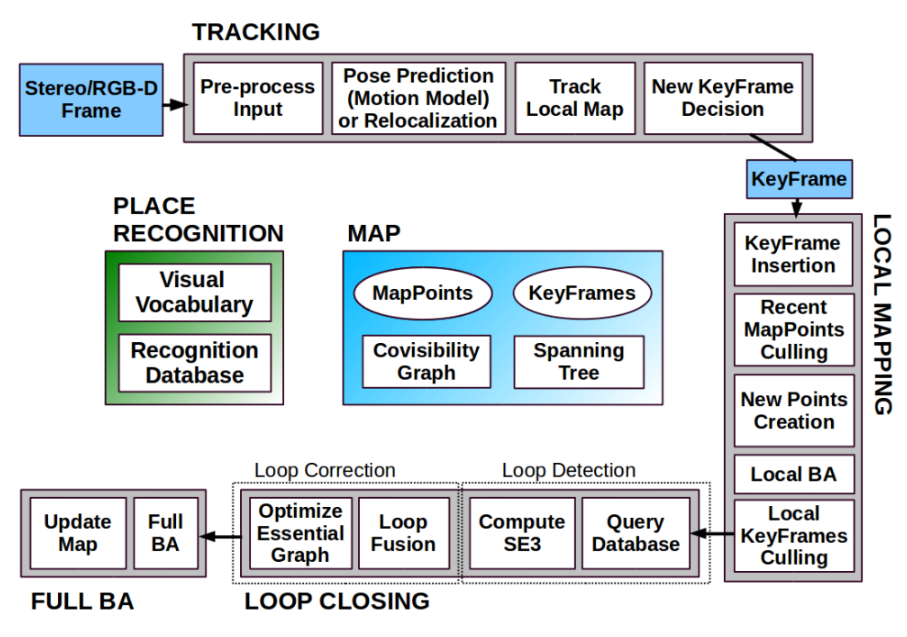
OrbSLAM2 [2] takes its name from the famous local feature detector ORB (Oriented Fast and rotated Brief) (Figure 3). These features are used for tracking, mapping and placing recognition tasks. The implementation of OrbSLAM2 is open source (ORB-SLAM2 GitHub repository). The system can work with monocular, stereo, and RGB-D camera setups. It also includes very useful tools like map reuse (i.e., it can load already mapped areas), loop closing (i.e., it can detect closed camera trajectories), camera relocalization (i.e., it can relocalize the camera inside the map when the system is no more able to track camera position) and localization (i.e., it can localize the camera inside a pre-existing map). Furthermore, according to the results presented in the original paper, the algorithm is suitable for real-time applications.

Figure 3
The OrbSLAM2 working principle can be divided into three parts which also correspond to the three main threads:
As described in the following figure, the computational pipeline of OrbSLAM3 is in line with the one of OrbSLAM2. However, OrbSLAM3 [3] stands out in our application due to its multiple map system and its capability to integrate IMU data. Furthermore, we have experimentally noticed that OrbSLAM3 sometimes excels where OrbSLAM2 fails in detecting loop closures.
Similar to OrbSLAM2, the code for OrbSLAM3 is open source and can be accessed via the original author's GitHub repository.
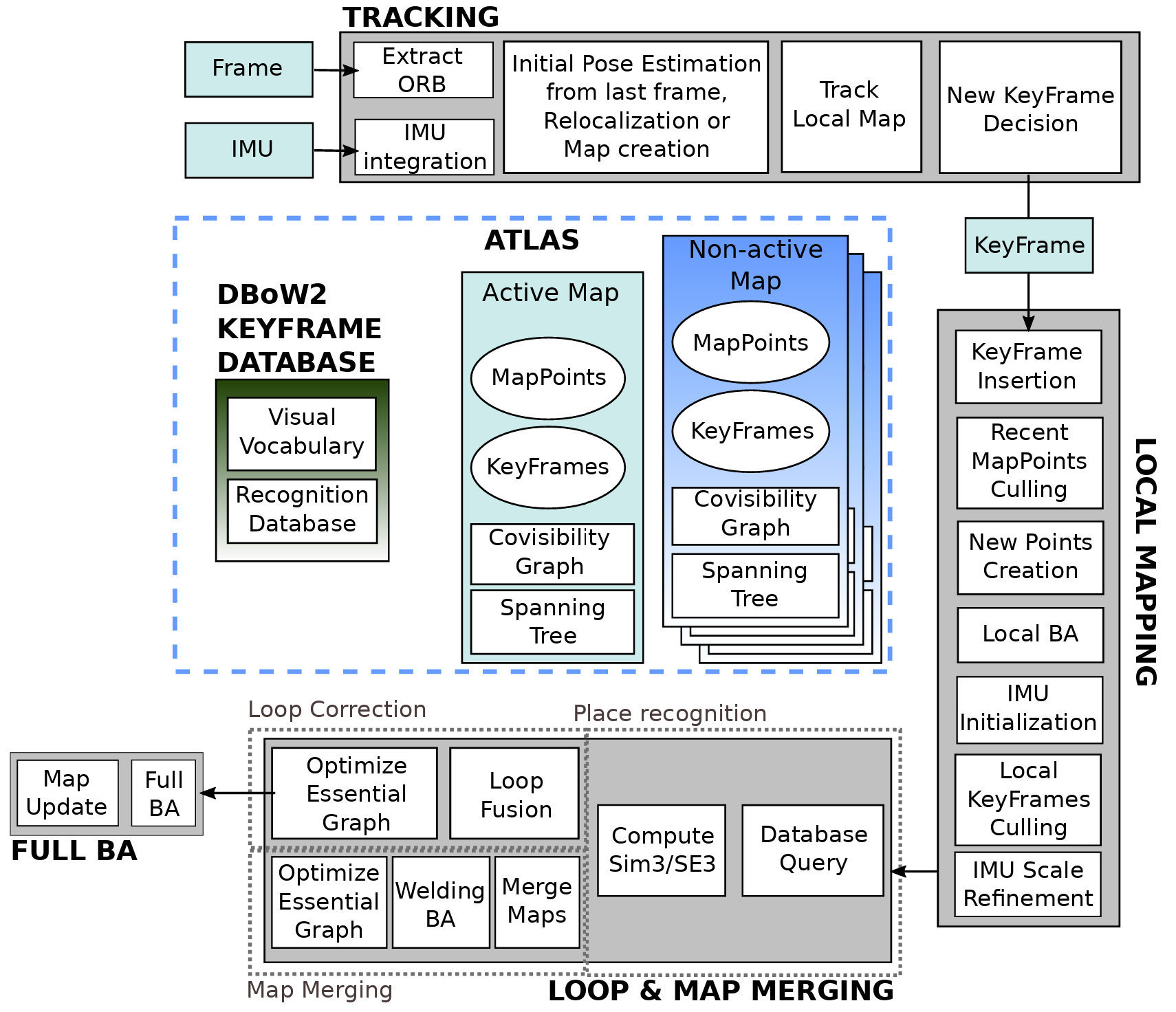
Figure 5
Solutions adopted by Formula Student teams often rely on expensive sensors such as professional cameras, multi-channel lidars, IMU, GPS, and ground speed sensors. The purpose of our research is to demonstrate that it is possible to develop a competitive driverless car without necessarily employing expensive equipment. In consonance with this, the sensor used for this project is an Intel RealSense D455 RGB-D camera. This hardware is reasonably cheap with respect to other commonly adopted solutions.

Figure 6
Using the camera calibration procedure provided by OpenCV we performed a camera calibration of our visual sensor to get the camera matrix and distortion coefficients. To do so we acquired several pictures of the widely used chess board calibration pattern placed at different locations and orientations. Then, we relied on the OpenCV calibration functions to identify the correspondences between the set of 3D real-world points and their 2D coordinates in the images. Finally, to assess the calibration parameters's accuracy, we evaluated the re-projection error, following OpenCV's guidelines, achieving a 0.01 projection error.
The code for the camera calibration is publicly available at this GitHub repository.

Figure 7

Figure 8
The overall idea of our methodology is reported in the following figure.
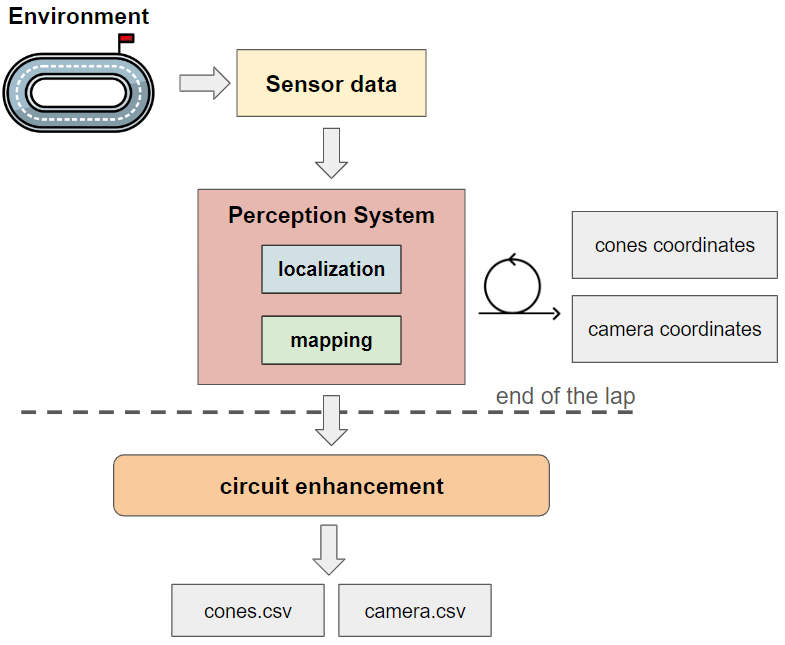
Figure 9
The RealSense D455 RGB-D camera captures sensor data to perceive the circuit in which the agent operates, acting as a bridge between the agent and its environment. The video stream produced by the camera is processed by the perception system that combines localization and mapping components. After undergoing a post-processing phase (in the figure referred to as circuit enhancement), the algorithmic pipeline produces two output files. The first, named cones.csv, reports the positions and classifications of cones identified in the recorded video stream. The second, camera.csv, contains the coordinates of the camera throughout the video stream, expressed relative to a fixed reference system.
As mentioned at the beginning of this chapter, initially we focused on OrbSLAM2 algorithm as our starting point. This strategy allowed us to thoroughly examine the OrbSLAM codebase, serving as a preliminary step in comprehending its structure. In our GitHub repository on branch orbslam2, we provide the C++ code together with the instructions to execute OrbSLAM2 on a video sequence recorded by the Intel RealSense D455 camera. Upon completion of the execution, we store the map generated by the algorithm along with the camera's trajectory in a human-readable format (camera.csv). Additionally, throughout the execution, real-time coordinates of the camera in the actual environment are accessible, enhancing the localization capability.

Figure 10
Once we became familiar with the structure of the OrbSLAM2 code, we shifted our focus to OrbSLAM3.
For mapping purposes, we aim to estimate the coordinates of the cones that outline the circuit. In this regard we fine-tuned a version of YOLOv8 using the annotated images from the FSOCO dataset [4], a collaborative dataset for vision-based cone detection systems in Formula Student Driverless competitions. The classes of cones of interest are conveniently illustrated in the following figure.

Figure 11
The obtained deep neural network model performs well across the training, validation, and test sets.
In the following figures, we report the outcome of the training and evaluation procedure.
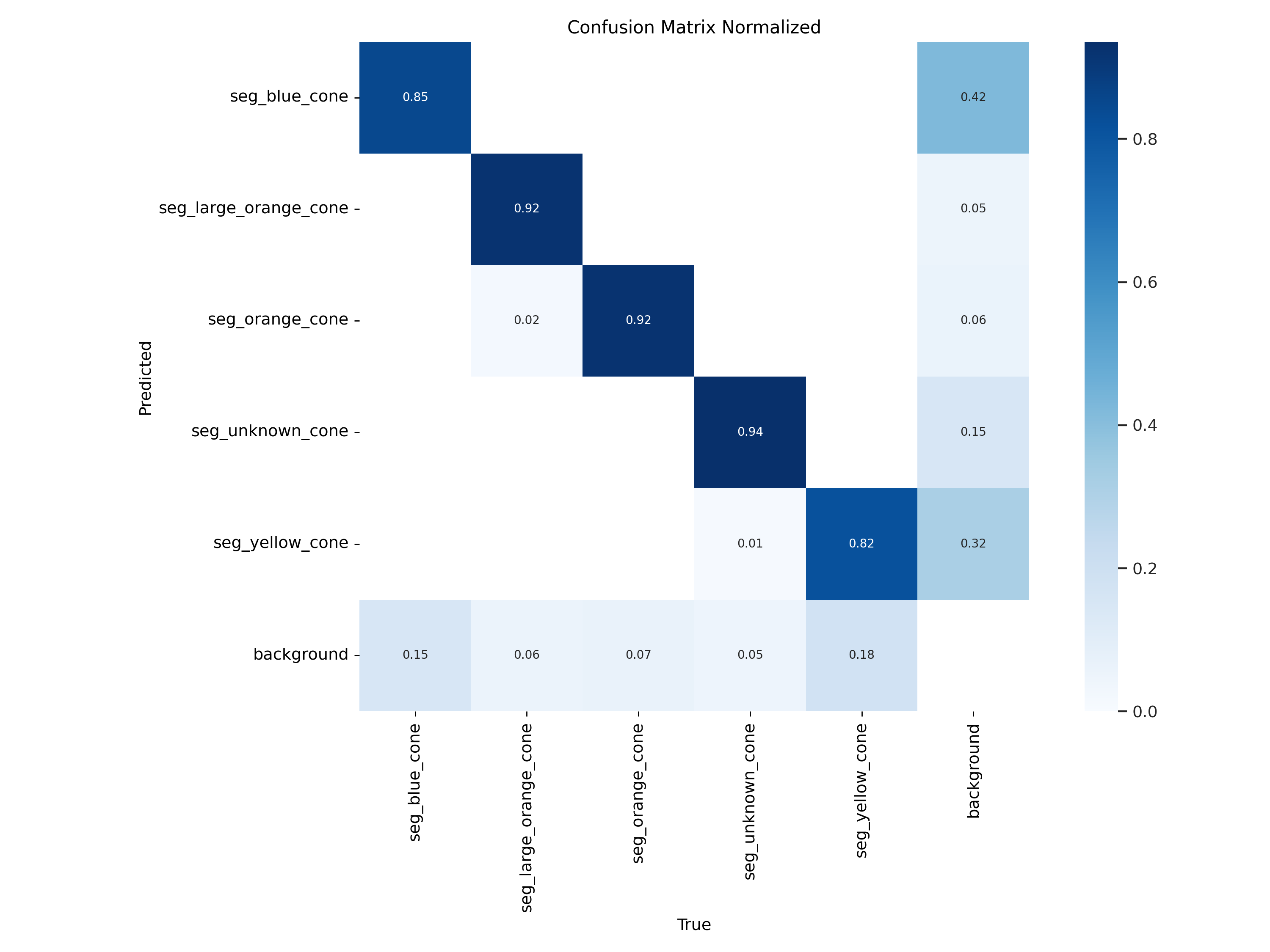
Figure 12: Confusion matrix.

Figure 13: FSOCO training set.

Figure 14: FSOCO validation set.
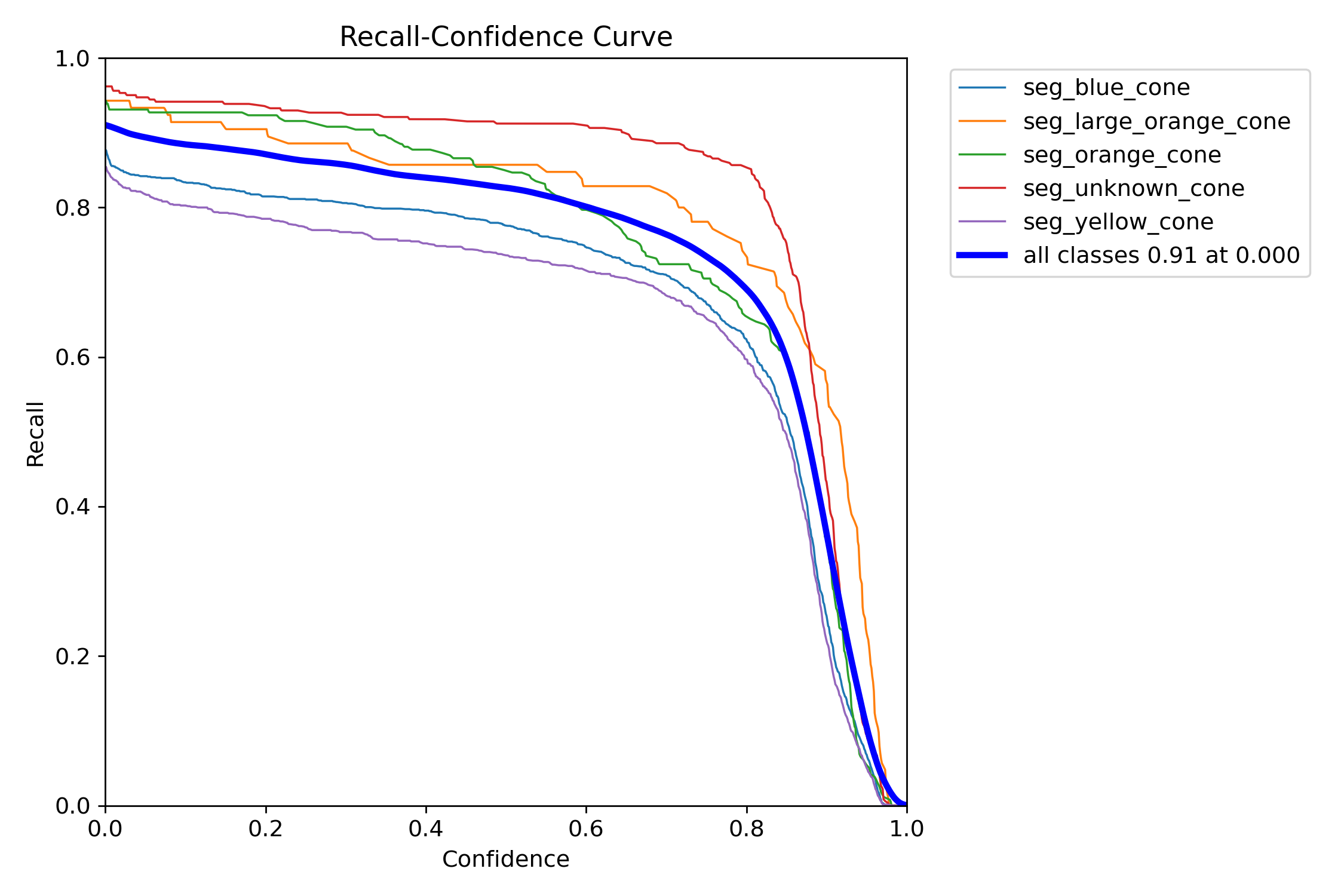
Figure 15: Recall-confidence curve.
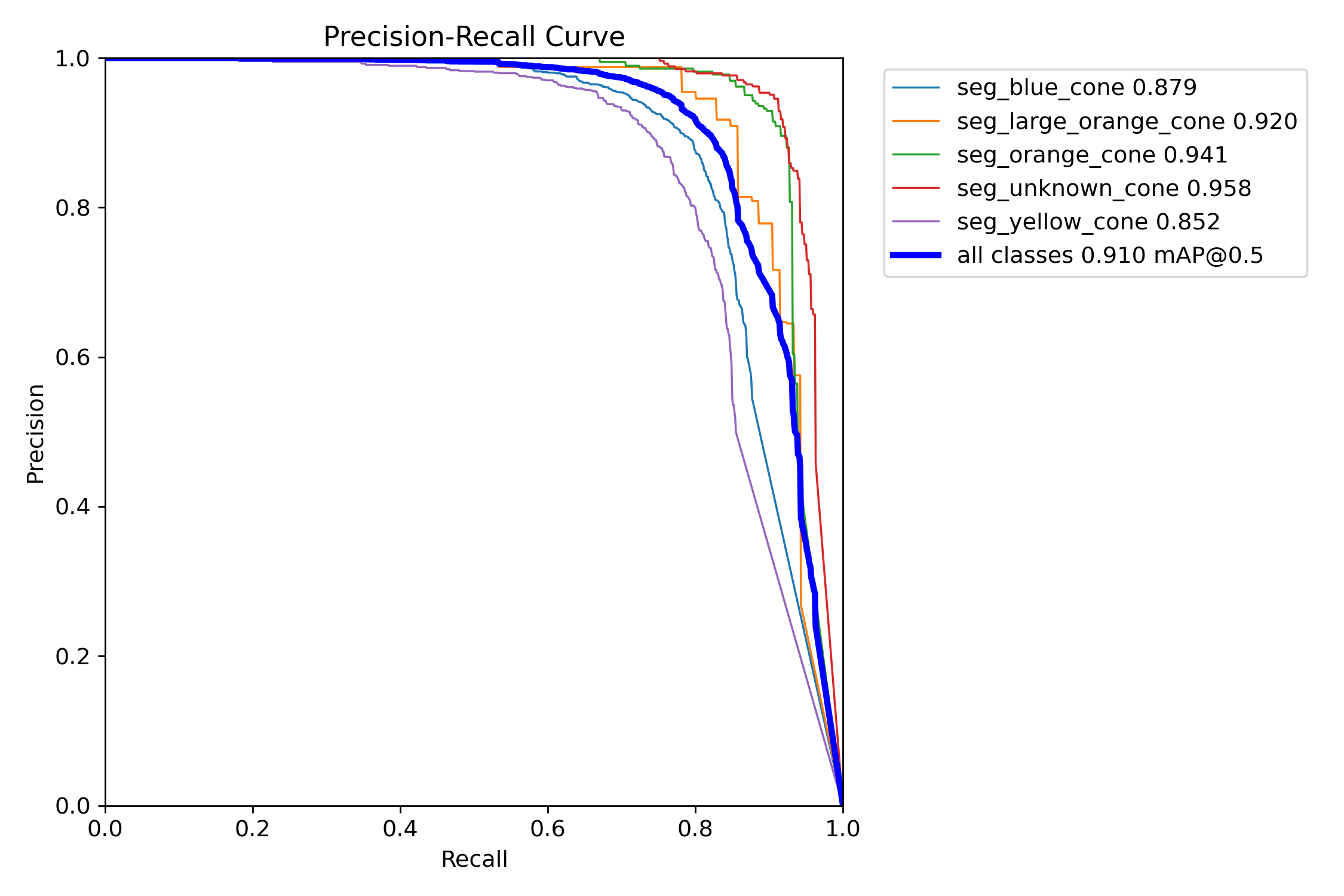
Figure 16: Precision-recall curve.
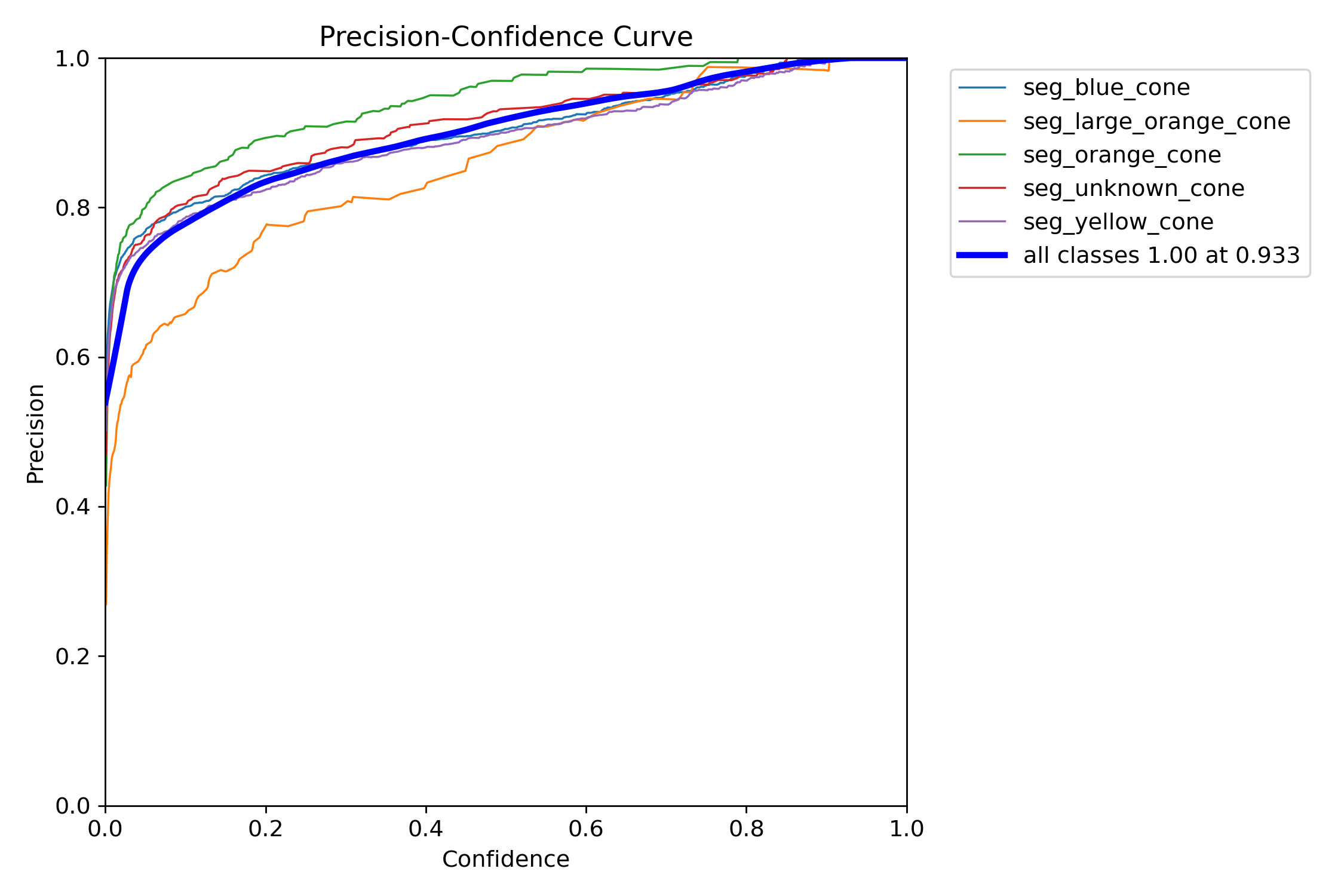
Figure 17: Precision-confidence curve.
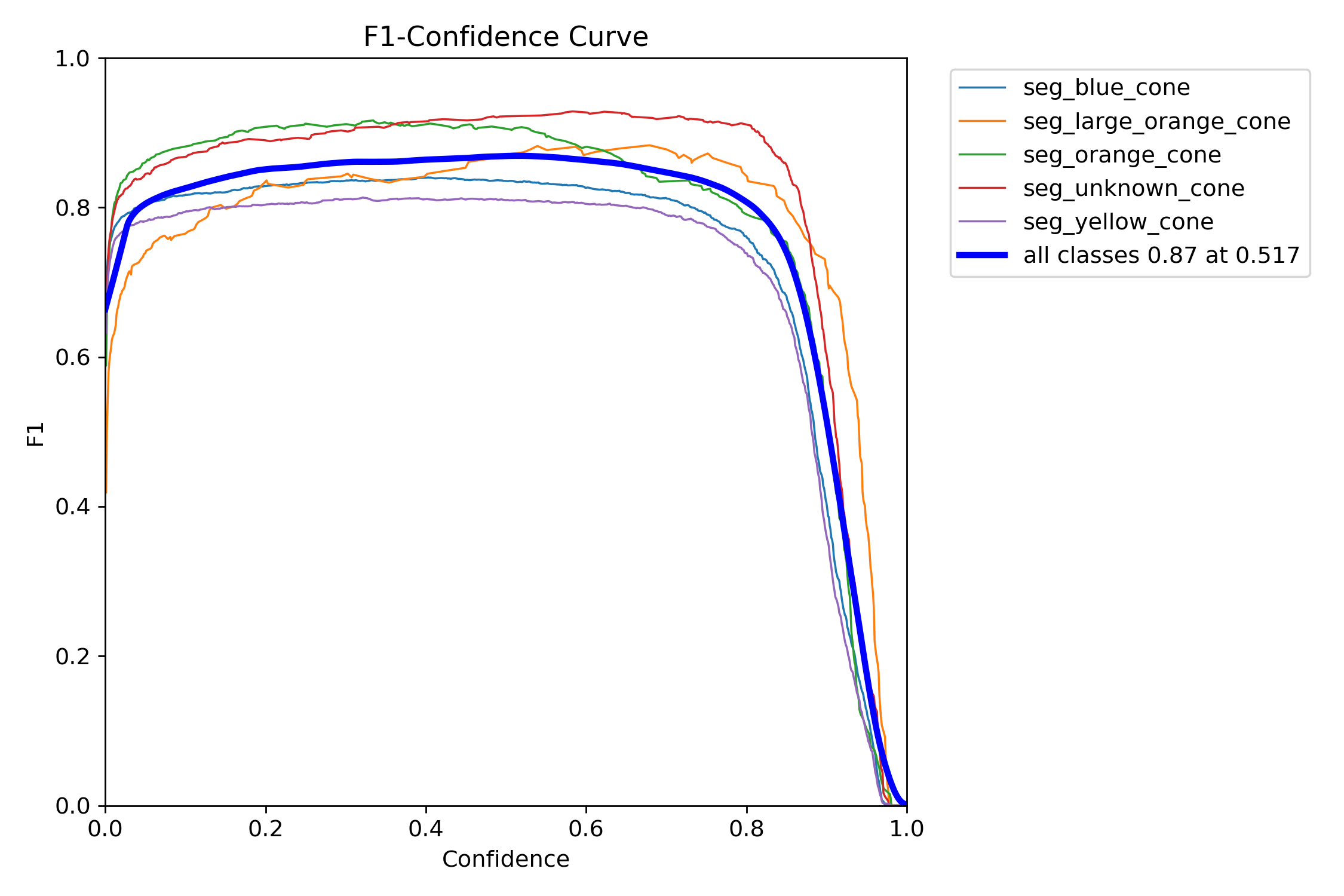
Figure 18: F1-confidence curve.
To integrate the cone detection module into the rest of the system, a custom C++ interface has been developed starting from the one provided in the YOLOv8 repository. The proposed interface uses the OpenCV DNN module to load the network in ONNX format with the capabilities to run it either with or without CUDA for GPU acceleration if available.
The original code has been modified as the originally provided example only works on bounding boxes and does not account for the segmentation output. With such modification, the interface produces a vector of bounding boxes and their respective masks.
Our custom interface implementation in C++, along with the ONNX YOLO models, can be accessed publicly on our GitHub repository.
The heart of the overall perception system is the integration of YOLOv8 in the OrbSLAM3 algorithm pipeline. The following figure illustrates the main software components of the perception system.
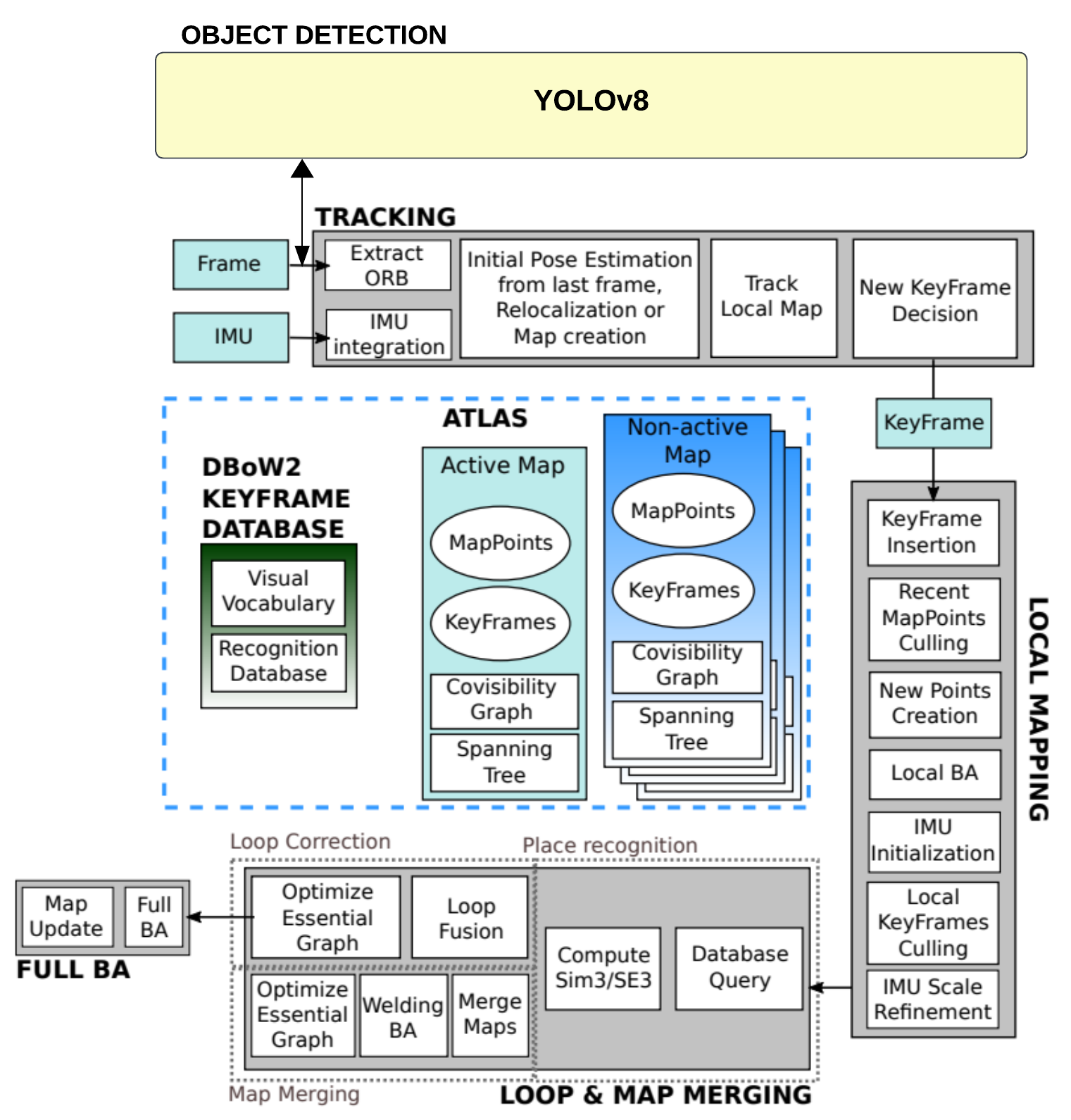
Figure 19
Each frame acquired by the camera is processed with our fine-tuned deep learning model, before the ORB extraction step of OrbSLAM3. By doing so, in the subsequent steps of the algorithm, we can filter only the visual features that belong to the bounding boxes of the cones within the current frame. For each ORB feature on the image, OrbSLAM3 keeps track of its corresponding map point in the three-dimensional real-world reference system. Leveraging this information, we gather a set of
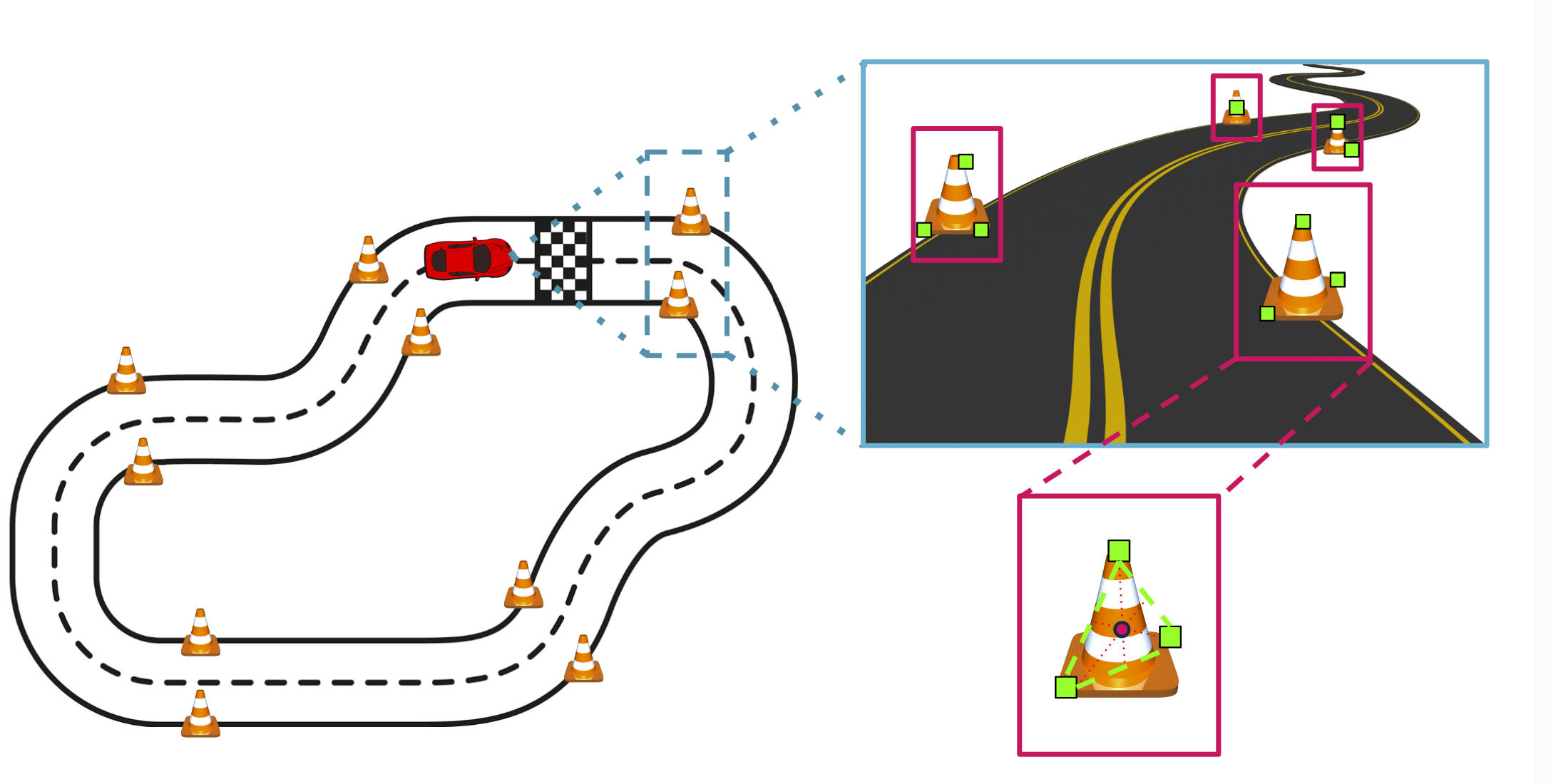
Figure 20
The perception system updates at each frame the list of detected cones that populate the track throughout which the autonomous agent is traveling. Each cone is described by the following attributes:
Whenever YOLO detects a cone, we need to determine whether the cone has been previously identified in another frame or if it is a new detection. In the case of new detection, the cone needs to be added to the collection of detected cones. However, if the cone has been detected previously (which could happen for instance in consecutive frames), the corresponding hit counter attribute is incremented, and its position is refined based on the new localization estimation.
A cone
Upon receiving a new frame from the input video stream, YOLO performs cone detection and classification, resulting in a set of detected cones within the image. Utilizing the methodology outlined above, OrbSLAM3 is employed to derive a triplet of 3D coordinates for each detected cone.
Handling cone equality as defined earlier, we iterate the list of detected cones to determine whether each newly detected cone should be inserted for the first time or if it already exists in the vector.
When processing a newly detected cone
Only cones with a hit counter value exceeding a predefined threshold are treated as valid cones and are subsequently visualized in the output. Cones failing to meet this criterion are deemed as noise and thus are neither visualized nor logged.
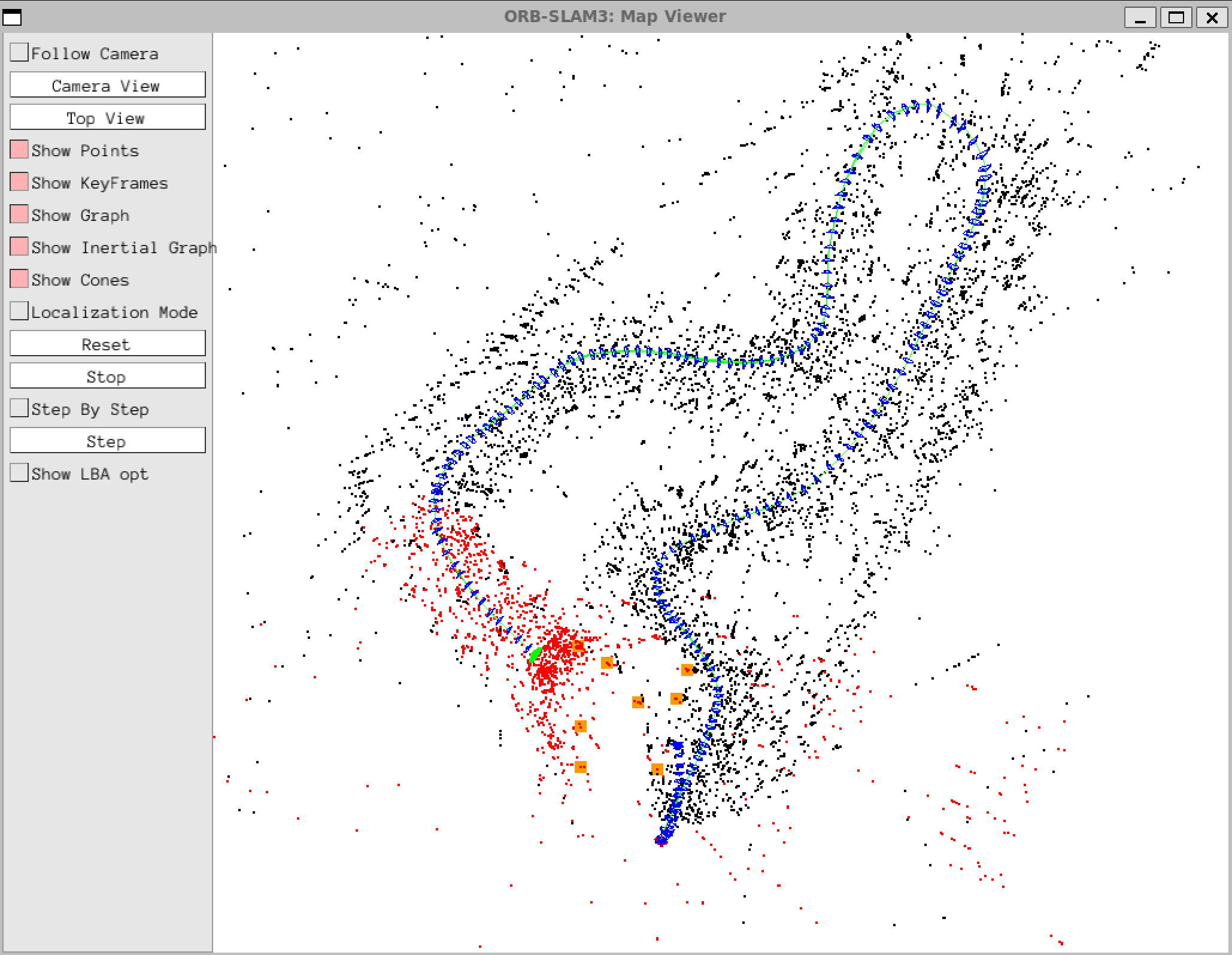
Figure 21

Figure 22
A central aspect for acquiring a comprehensive representation of the circuit involves distinguishing between cones located on the left and right sides of the vehicle. To address this, we have evaluated two potential solutions:
According to competition regulations, track lanes are delineated by yellow and blue cones for the left and right lane boundaries, respectively. Therefore, we can easily determine whether a cone is positioned on the right or left boundary of the track by relying on the classifications provided by YOLO. This represents the simplest solution.
Another method to determine whether a cone is positioned on the left or right involves a geometric approach. Utilizing the reference systems illustrated in the following figure, we convert the 3D world coordinates
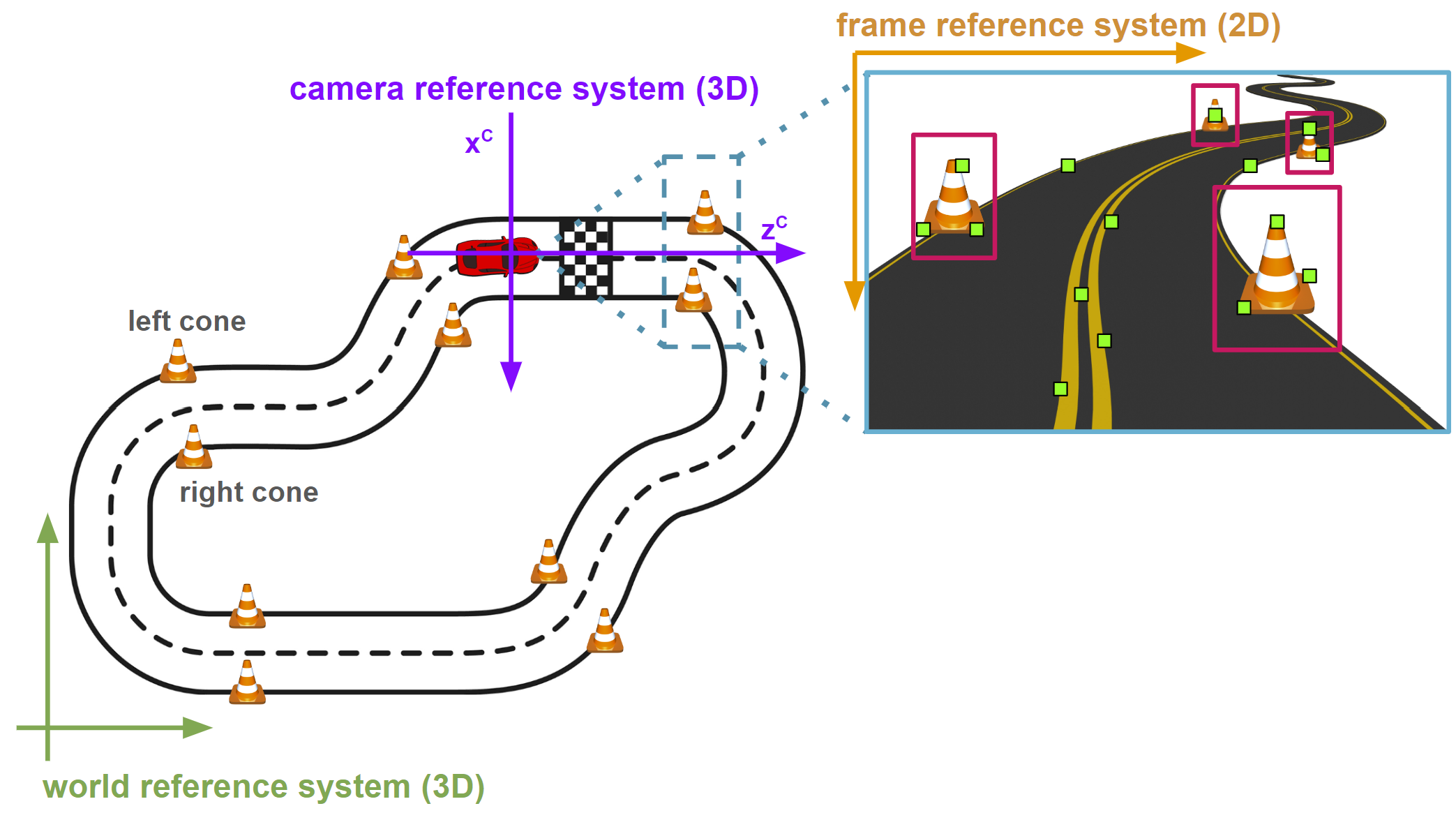
Figure 23
In this section, we provide an overview of the experimental design employed to evaluate the proposed framework.
To ensure the solution could be implemented without requiring specialized hardware, thereby minimizing implementation costs, the experiments described in this report were conducted on a standard Windows 11 laptop. The system was equipped with a 14-core Intel i7-12700H @ 2.30 GHz and 32GB of RAM.
To evaluate the performance of the implemented perception system, we captured multiple datasets using the RealSense D455 camera through the RealSense Viewer software made available by Intel. All the datasets are made available at this link.
This section aims to present representative experiments showcasing the results achieved with our implemented perception system. First, we report and discuss a comparison of the performance of OrbSLAM2 and OrbSLAM3. Finally, we offer a demonstrative video showcasing the execution of our perception system on one of our indoor datasets.
To evaluate OrbSLAM2 and OrbSLAM3 performance, we compared the estimated camera trajectories obtained by the two algorithms executed on the four datasets we collected. In the following figure, the plots of the obtained trajectories are reported. The code that has been implemented to obtain these representations has been published on eagle-driverless-orbSLAM GitHub repository on branch evaluation.
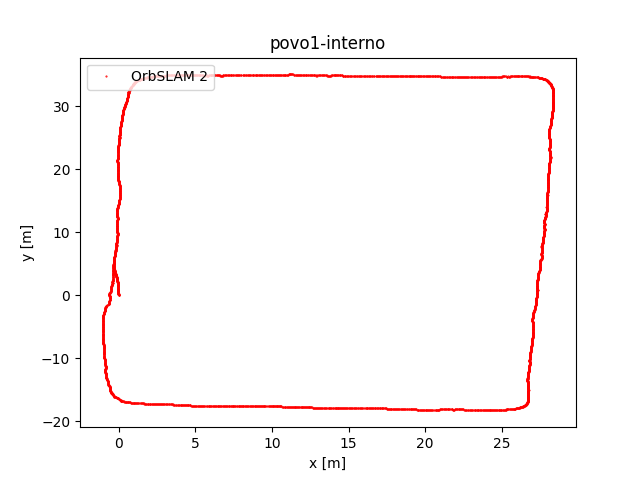
Figure 25
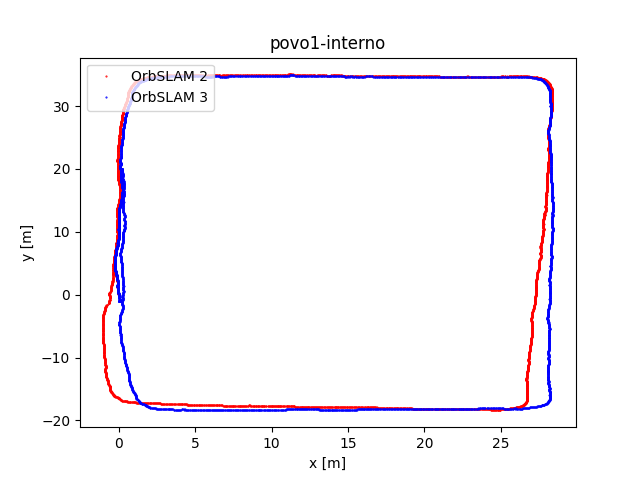
Figure 26
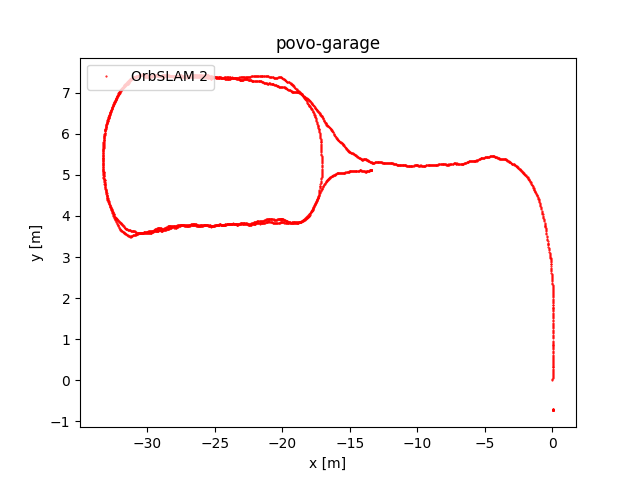
Figure 27
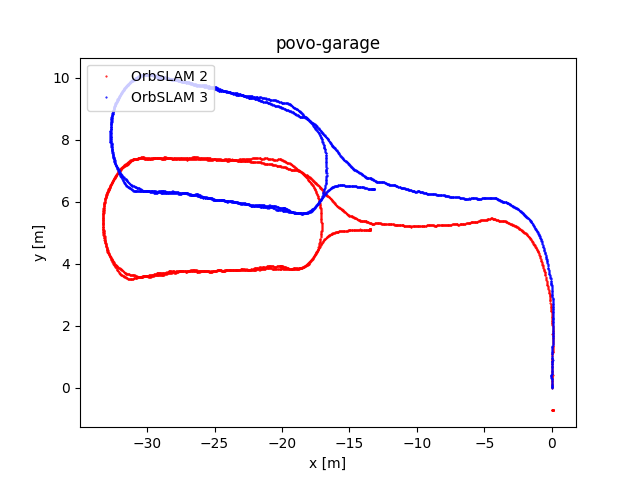
Figure 28
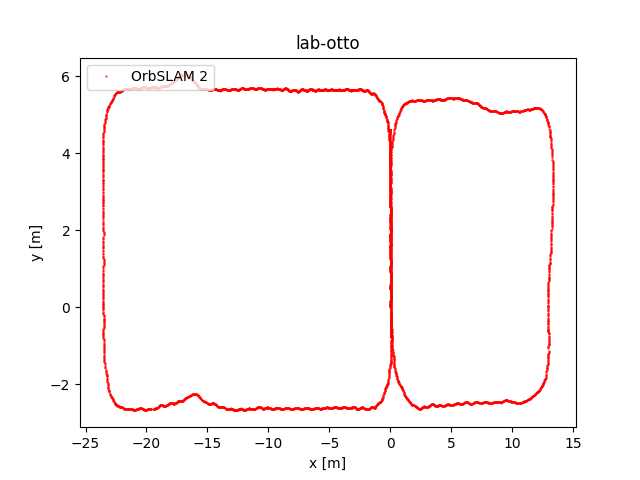
Figure 29
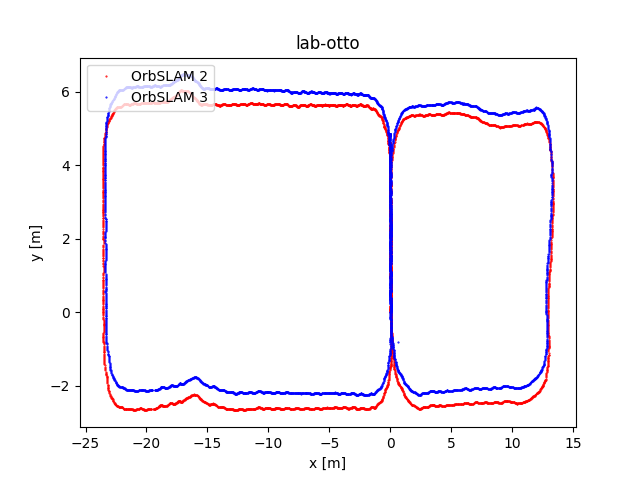
Figure 30
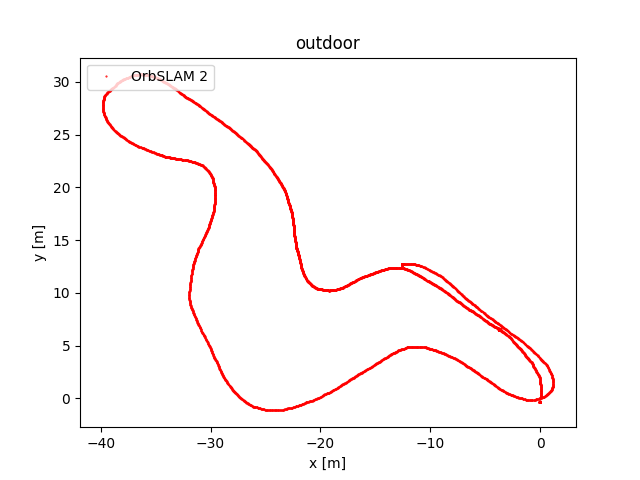
Figure 31
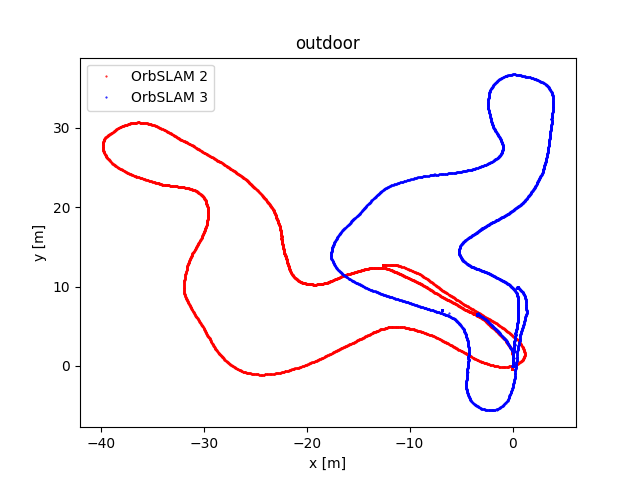
Figure 32
Upon observing the trajectory curves we derive the following observations. While some datasets show nearly overlapping trajectories, others exhibit differences due to specific rotations and translations. This discrepancy is not concerning as both algorithms calculate accurate trajectories, albeit within slightly different reference systems.
To present the achieved results, we offer two videos demonstrating the behavior of the perception system using the povo-garage dataset. The videos illustrate that the system produces reasonably high-quality output with satisfactory stability.
The first video demonstrates that YOLO appropriately recognizes and classifies cones within the captured frame. Additionally, different colors distinguish between ORB features within the bounding boxes of the cones and key points that do not belong to a cone.
The second video showcases the progressive mapping of the track and the simultaneous localization of the vehicle within it. Particularly, the orange squares represent the projection of the centroid coordinates of the cones within the world reference system. These squares are updated in every frame. The larger blue and yellow squares represent cone clusters. Blue is used to represent cones on the right side, while yellow represents cones on the left side.
In this work, we achieved a functioning initial version of a perception system aimed at solving an instance of the Simultaneous Localization and Mapping (SLAM) problem for a Formula Student racing car to drive an autonomous vehicle.
Through camera calibration, we were able to obtain intrinsic and extrinsic parameters of the Intel RealSense D455 camera.
Starting the work with OrbSLAM2 allowed us to become familiar with the code structure proposed by the authors. This facilitated a smoother migration towards the Visual SLAM algorithm OrbSLAM3. Having a working solution of both OrbSLAM2 and OrbSLAM3 also allowed us to compare the performance achievable with the two algorithms.
Regarding the mapping, the YOLOv8 model, on which we performed fine-tuning using the FSOCO dataset, proved to be efficient for properly detecting and classifying conses within the acquired frames. Integrating YOLOv8 into the algorithmic pipeline of OrbSLAM3 is at the core of the proposed solution and enabled us to effectively address the SLAM problem. By combining the two algorithms, we can select only the Oriented FAST and rotated BRIEF (ORB) visual features belonging to the bounding box of the cone, derive their corresponding coordinates relative to the world reference system, and thus obtain the coordinates of a single representative centroid of the recognized cone. Notably, we further refined the results by proposing a prototypical solution for cone clustering and distinguishing between right and left cones. The proposed solution was tested and achieved good performance on five datasets acquired by us.
Upon analyzing the plot of cone centroids, we observe considerable noise in the estimation of their location. We attribute this noise to inferring cone coordinates from the ORBs within the bounding boxes encasing each other. Within these bounding boxes, there might exist visual features unrelated to the detected cones. To address this limitation, our proposed solution involves taking into account the segmentation mask of the cones rather than the bounding box and subsequently filtering the ORBs within this defined shape.
At present, the goodness of processing every acquired frame with YOLO remains uncertain. Although YOLO provides good real-time performance, being able to avoid running the object detection model on each frame of the video stream would reduce the computational cost of the algorithm. Moreover, it is reasonable to assume that the cones in two consecutive frames remain unchanged. Thus, it might be a prominent idea to utilize the model solely on OrbSLAM3 KeyFrames rather than on every frame.
Currently, YOLOv8 is executed sequentially, in series, with respect to OrbSLAM3. A possible enhancement of this work would be to separate YOLOv8 and OrbSLAM3 into two distinct threads running in parallel. At that point, through appropriate process synchronization policies, it might be possible to optimize the interaction between YOLO and SLAM.
ORB-SLAM: A Versatile and Accurate Monocular SLAM System
DOI: 10.1109/TRO.2015.2463671
ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras
DOI: 10.1109/TRO.2017.2705103
ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM
DOI: 10.1109/TRO.2021.3075644
FSOCO: The Formula Student Objects in Context Dataset
DOI: 10.4271/12-05-01-0003