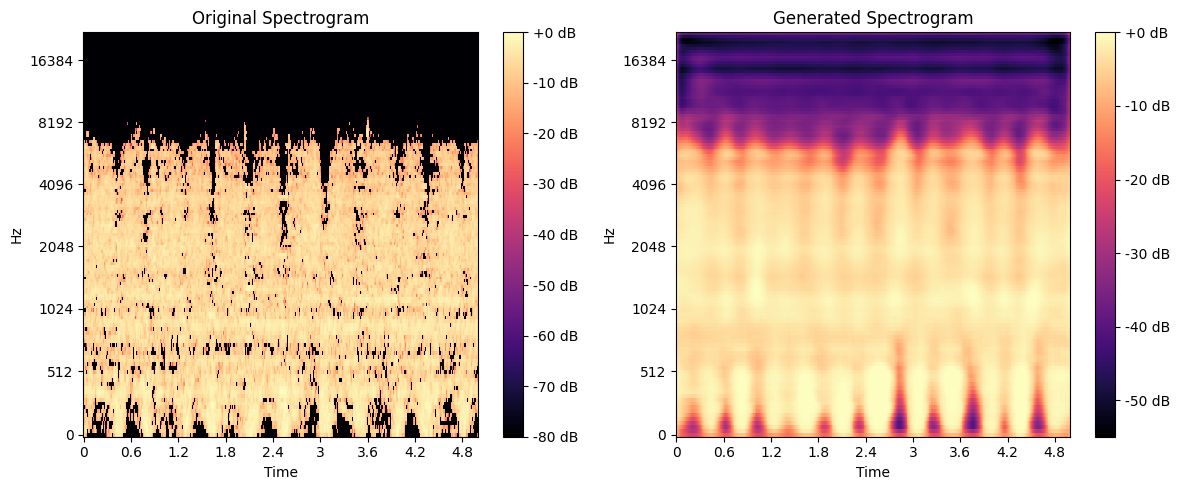
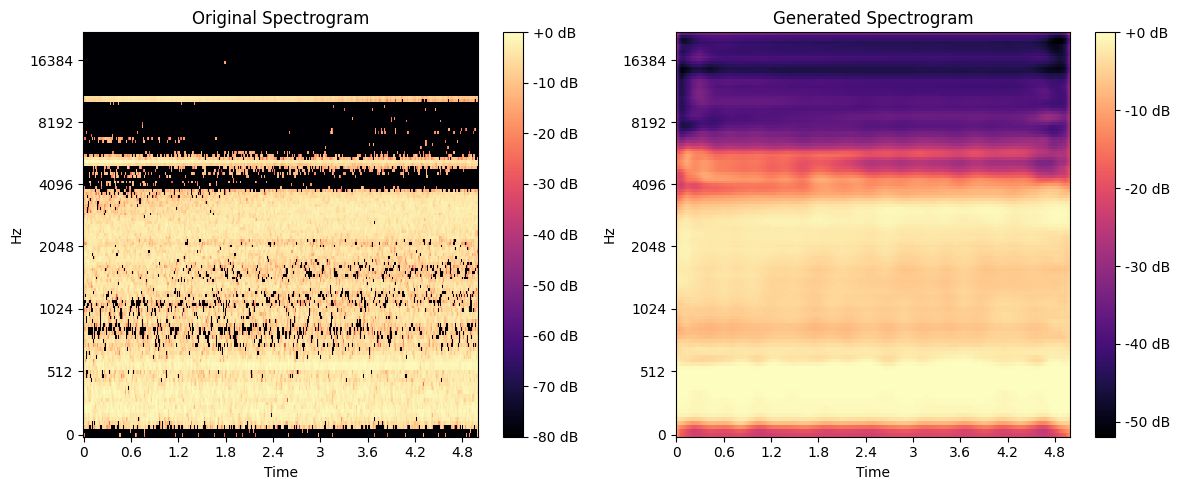
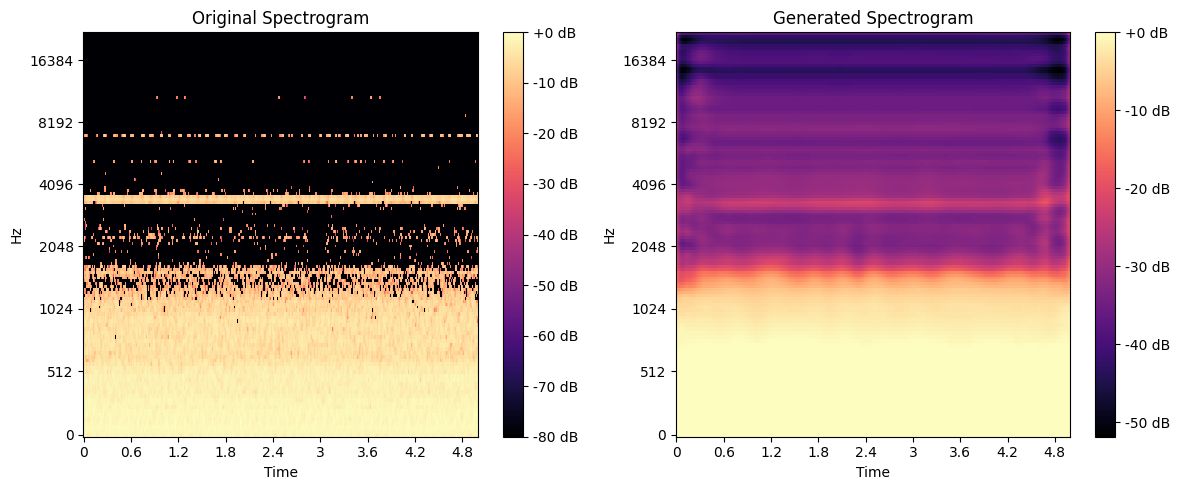
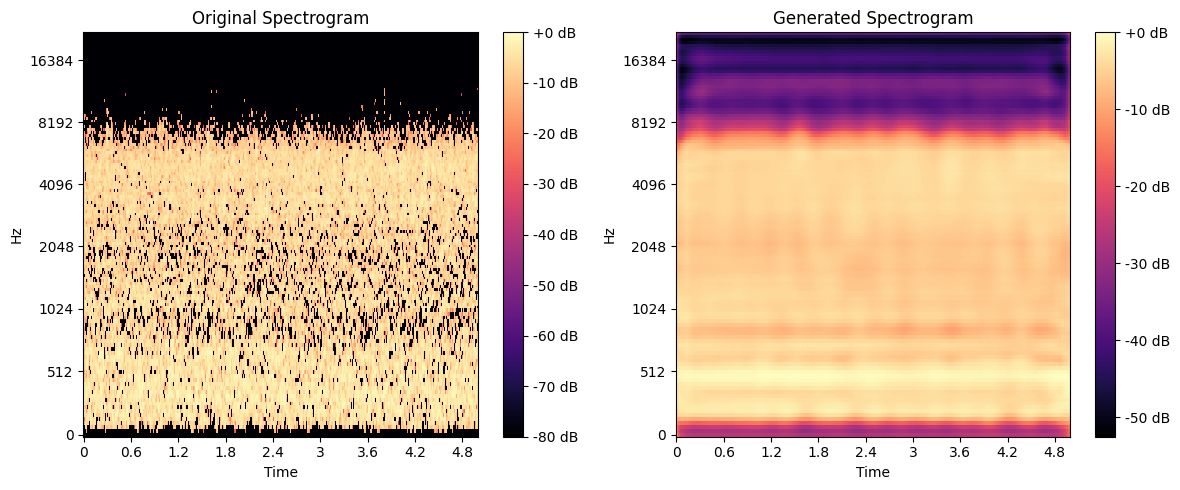
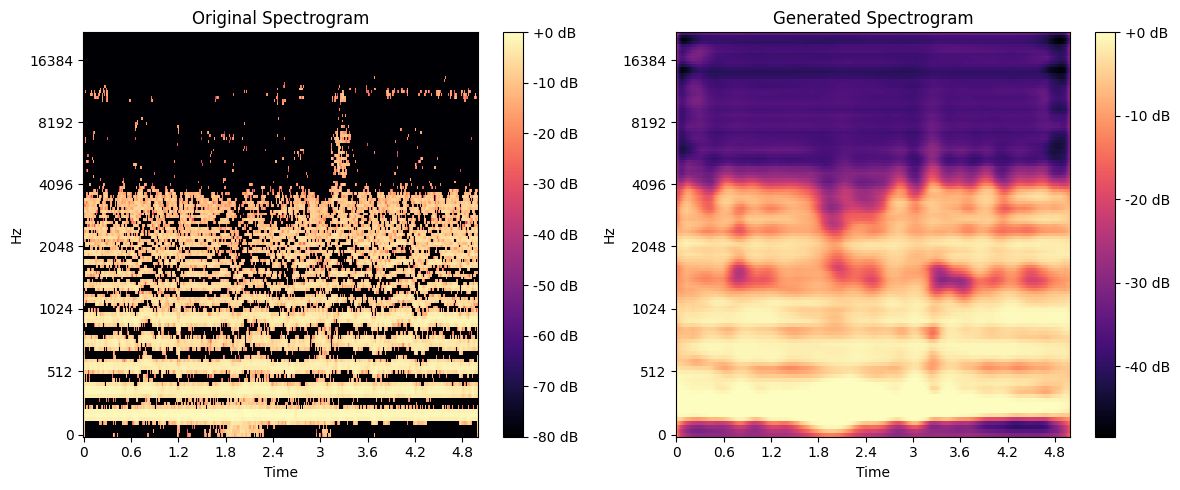
This project explores the potential of Deep Learning in enhancing audio spectrograms through a Deep Convolutional Autoencoder (DCAE). The goal is to accurately reconstruct sound spectrograms while preserving their time-frequency structure, improving denoising and spectral information restoration. The model is named OMNIA, inspired by its ability to process and enhance diverse soundscapes.
As a sound engineer and AI researcher, I aimed to synthesize realistic sound representations using a CNN-based autoencoder. While reproducing a full-spectrum sound remains complex, the use of Computer Vision techniques on spectrograms helps analyze and generate structured representations of sound.
The model consists of two main components:
✔️ Uses Convolutional Neural Networks (CNNs) to extract spatial features.
✔️ MaxPooling layers reduce spectrogram dimensionality while retaining essential information.
✔️ Encodes a compressed representation of the spectrogram.
✔️ Uses UpSampling layers to restore the spectrogram resolution.
✔️ Convolutional layers refine and reconstruct details.
✔️ Applies Cropping to fix minor output mismatches.
Dataset Preparation
Model Training
Performance Evaluation
✔️ The model successfully denoised and enhanced spectrograms.
✔️ It showed promising results in restoring lost spectral details.
✔️ Challenges emerged in generating fully realistic audio outputs, where low sampling frequency affected quality, leading to slightly robotic reconstructions.
✔️ Further optimizations with higher resolution datasets and GAN-based approaches could improve results.
🚀 Explore GANs for spectrogram generation.
🚀 Improve sampling fidelity for clearer reconstructed sounds.
🚀 Implement latent space audio synthesis for game and film sound design.
This research demonstrates the potential of AI in audio processing through spectrogram-based deep learning models. OMNIA serves as a stepping stone toward AI-driven sound design, merging the power of machine learning and digital signal processing to create richer, more immersive audio environments.
🔗 GitHub Repository: github.com/Mike014
📢 Feedback & Collaboration Welcome!