This is a handmade machine and deep learning framework library, made in python, using numpy as its only external dependency.
I made it to challenge myself and to learn more about deep neural networks, how they work in depth.
The big part of this project, meaning the Multilayer Perceptron (MLP) part, was made in a week.
I then decided to push it even further by adding Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), Autoencoders, Variational Autoencoders (VAE), GANs and Transformers.
Regarding the Transformers, I just basically reimplement the Attention is All You Need paper, but I had some issues with the gradients and the normalization of the attention weights. So, I decided to leave it as it is for now. It theorically works but needs a huge amount of data that can't be trained on a CPU. You can however see what each layers produce and how the attention weights are calculated here.
This project will be maintained as long as I have ideas to improve it, and as long as I have time to work on it.
You can install the library using pip:
pip install neuralnetlib
See this file for a simple example of how to use the library.
For a more advanced example, see this file for using CNN.
You can also check this file for text classification using RNN.
See this file for an example of how to use VAE to generate new images.
And this file for an example of how to generate new dinosaur names.
More examples in this folder.
You are free to tweak the hyperparameters and the network architecture to see how it affects the results.
from neuralnetlib.models import Sequential from neuralnetlib.layers import Input, Dense from neuralnetlib.activations import Sigmoid from neuralnetlib.losses import BinaryCrossentropy from neuralnetlib.optimizers import SGD from neuralnetlib.metrics import accuracy_score # ... Preprocess x_train, y_train, x_test, y_test if necessary (you can use neuralnetlib.preprocess and neuralnetlib.utils) # Create a model model = Sequential() model.add(Input(10)) # 10 features model.add(Dense(8)) model.add(Dense(1)) model.add(Activation(Sigmoid())) # many ways to tell the model which Activation Function you'd like, see the next example # Compile the model model.compile(loss_function='bce', optimizer='sgd') # Train the model model.fit(X_train, y_train, epochs=10, batch_size=32, metrics=['accuracy'])
from neuralnetlib.activations import Softmax from neuralnetlib.losses import CategoricalCrossentropy from neuralnetlib.optimizers import Adam from neuralnetlib.metrics import accuracy_score # ... Preprocess x_train, y_train, x_test, y_test if necessary (you can use neuralnetlib.preprocess and neuralnetlib.utils) # Create and compile a model model = Sequential() model.add(Input(28, 28, 1)) # For example, MNIST images model.add(Conv2D(32, kernel_size=3, padding='same'), activation='relu') # activation supports both str... model.add(BatchNormalization()) model.add(MaxPooling2D(pool_size=2)) model.add(Dense(64, activation='relu')) model.add(Dense(10, activation=Softmax())) # ... and ActivationFunction objects model.compile(loss_function='categorical_crossentropy', optimizer=Adam()) model.compile(loss_function='categorical_crossentropy', optimizer=Adam()) # same for loss_function and optimizer # Train the model model.fit(X_train, y_train_ohe, epochs=5, metrics=['accuracy'])
from neuralnetlib.losses import MeanSquaredError from neuralnetlib.metrics import accuracy_score # ... Preprocess x_train, y_train, x_test, y_test if necessary (you can use neuralnetlib.preprocess and neuralnetlib.utils) # Create and compile a model model = Sequential() model.add(Input(13)) model.add(Dense(64, activation='leakyrelu')) model.add(Dense(1), activation="linear") model.compile(loss_function="mse", optimizer='adam') # you can either put acronyms or full name # Train the model model.fit(X_train, y_train, epochs=100, batch_size=128, metrics=['accuracy'])
X, y = fetch_openml('Fashion-MNIST', version=1, return_X_y=True, as_frame=False) X = X.astype('float32') / 255. X = X.reshape(-1, 28, 28, 1) X_train, X_test = train_test_split(X, test_size=0.2, random_state=42) autoencoder = Autoencoder(random_state=42, skip_connections=True) autoencoder.add_encoder_layer(Input((28, 28, 1))) autoencoder.add_encoder_layer(Conv2D(16, kernel_size=(3, 3), strides=(2, 2), activation='relu', padding='same')) autoencoder.add_encoder_layer(Conv2D(32, kernel_size=(3, 3), strides=(2, 2), activation='relu', padding='same')) autoencoder.add_encoder_layer(Flatten()) autoencoder.add_encoder_layer(Dense(64, activation='relu')) # Bottleneck autoencoder.add_decoder_layer(Dense(7 * 7 * 32, activation='relu')) autoencoder.add_decoder_layer(Reshape((7, 7, 32))) autoencoder.add_decoder_layer(UpSampling2D(size=(2, 2))) # Output: 14x14x32 autoencoder.add_decoder_layer(Conv2D(16, kernel_size=(3, 3), activation='relu', padding='same')) autoencoder.add_decoder_layer(UpSampling2D(size=(2, 2))) # Output: 28x28x16 autoencoder.add_decoder_layer(Conv2D(1, kernel_size=(3, 3), activation='sigmoid', padding='same')) # Output: 28x28x1 autoencoder.compile(encoder_loss='mse', decoder_loss='mse', encoder_optimizer='adam', decoder_optimizer='adam', verbose=True) history = autoencoder.fit(X_train, epochs=5, batch_size=256, validation_data=(X_test,), verbose=True,)
# Load the MNIST dataset (x_train, y_train), (x_test, y_test) = mnist.load_data() n_classes = np.unique(y_train).shape[0] # Flatten images x_train = x_train.reshape(x_train.shape[0], -1) x_test = x_test.reshape(x_test.shape[0], -1) # Normalize pixel values x_train = x_train.astype('float32') / 255 x_test = x_test.astype('float32') / 255 # Labels to categorical y_train = one_hot_encode(y_train, n_classes) y_test = one_hot_encode(y_test, n_classes) noise_dim = 32 generator = Sequential() generator.add(Input(noise_dim)) generator.add(Dense(128, input_dim = noise_dim, activation='relu')) generator.add(Dense(784, activation = 'sigmoid')) discriminator = Sequential() discriminator.add(Input(784)) discriminator.add(Dense(128, input_dim=784, activation='relu')) discriminator.add(Dense(1, activation='sigmoid')) gan = GAN(latent_dim=noise_dim) gan.compile(generator, discriminator, generator_optimizer='adam', discriminator_optimizer='adam', loss_function='bce', verbose=True) history = gan.fit(x_train, epochs=40, batch_size=128, plot_generated=True)
df = pd.read_csv("dataset.tsv", sep="\t") df.iloc[:, 1] = df.iloc[:, 1].apply(lambda x: re.sub(r'\\x[a-fA-F0-9]{2}|\\u[a-fA-F0-9]{4}|\xa0|\u202f', ' ', x)) # remove unicode characters LIMIT = 1000 fr_sentences = df.iloc[:, 1].values.tolist()[0:LIMIT] en_sentences = df.iloc[:, 3].values.tolist()[0:LIMIT] fr_tokenizer = Tokenizer(filters="", mode="word") # else the tokenizer would remove the special characters including ponctuation en_tokenizer = Tokenizer(filters="", mode="word") # else the tokenizer would remove the special characters including ponctuation fr_tokenizer.fit_on_texts(fr_sentences, preprocess_ponctuation=True) en_tokenizer.fit_on_texts(en_sentences, preprocess_ponctuation=True) X = fr_tokenizer.texts_to_sequences(fr_sentences, preprocess_ponctuation=True, add_special_tokens=True) y = en_tokenizer.texts_to_sequences(en_sentences, preprocess_ponctuation=True, add_special_tokens=True) max_len_x = max(len(seq) for seq in X) max_len_y = max(len(seq) for seq in y) max_seq_len = max(max_len_x, max_len_y) vocab_size_fr = len(fr_tokenizer.word_index) vocab_size_en = len(en_tokenizer.word_index) max_vocab_size = max(vocab_size_fr, vocab_size_en) X = pad_sequences(X, max_length=max_seq_len, padding='post', pad_value=fr_tokenizer.PAD_IDX) y = pad_sequences(y, max_length=max_seq_len, padding='post', pad_value=en_tokenizer.PAD_IDX) x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False) model = Transformer(src_vocab_size=vocab_size_fr, tgt_vocab_size=vocab_size_en, d_model=512, n_heads=8, n_encoder_layers=8, n_decoder_layers=10, d_ff=2048, dropout_rate=0.1, max_sequence_length=max_seq_len, random_state=42) model.compile(loss_function="cels", optimizer=Adam(learning_rate=5e-5, beta_1=0.9, beta_2=0.98, epsilon=1e-9, clip_norm=1.0, ), verbose=True) history = model.fit(x_train, y_train, epochs=50, batch_size=32, verbose=True, callbacks=[EarlyStopping(monitor='loss', patience=20), LearningRateScheduler(schedule="warmup_cosine", initial_learning_rate=5e-5, verbose=True)],validation_data=(x_test, y_test), metrics=['bleu_score'])
[!NOTE]
You can also save and load models using thesaveandloadmethods.
# Save a model model.save('my_model.json') # Load a model model = Model.load('my_model.json')
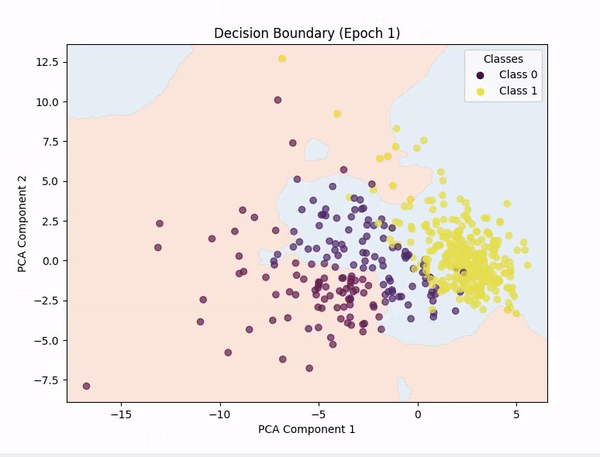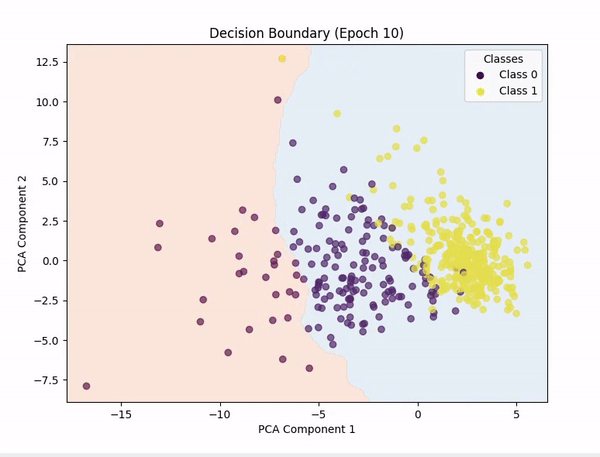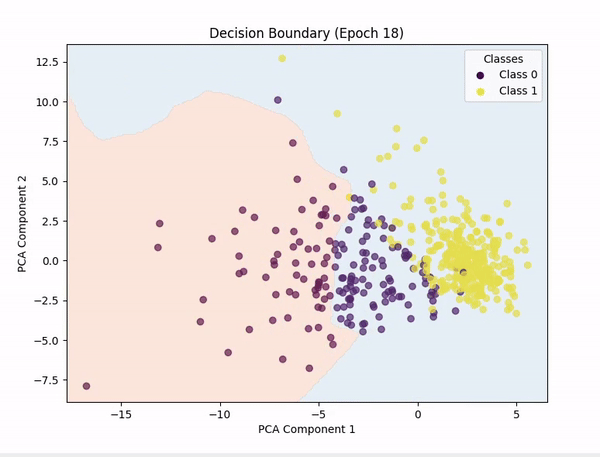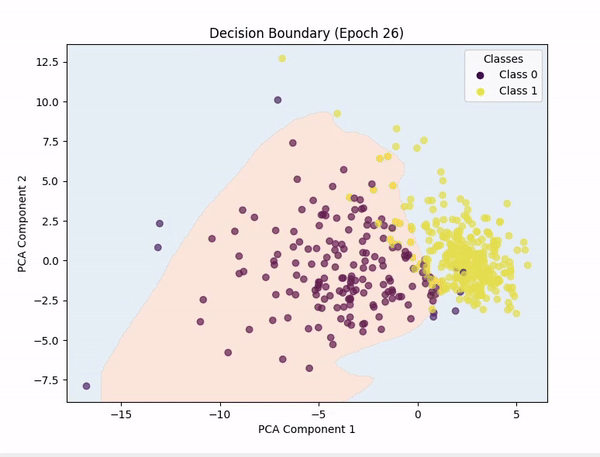
[!NOTE]
PCA (Principal Component Analysis) was used to reduce the number of features to 2, so we could plot the decision boundary.
Representing n-dimensional data in 2D is not easy, so the decision boundary may not be always accurate.
I also tried with t-SNE, but the results were not good.
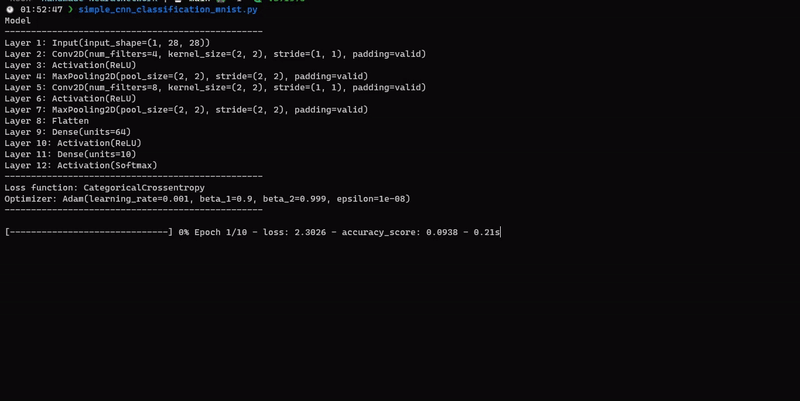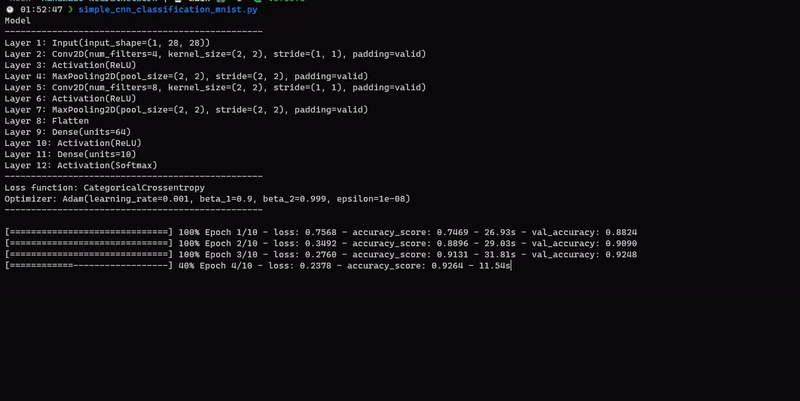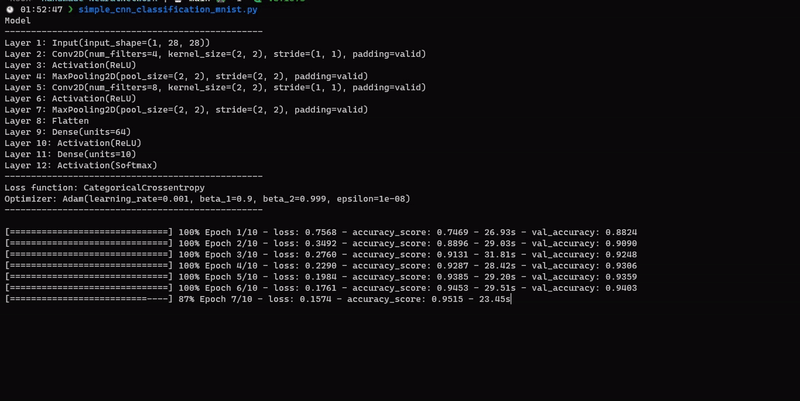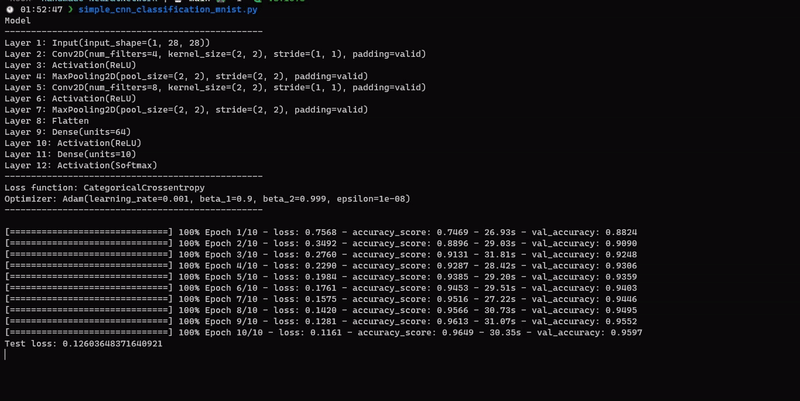



You can of course use the library for any dataset you want.
You can pull the repository and run:
pip install -e .
And test your changes on the examples.
Nothing yet! Feel free to open an issue if you find one.