Abstract
This project presents an innovative Multimodal AI Assistant that integrates advanced vision-language models(VLMs) with speech recognition(ASR) to provide a comprehensive human-computer interaction(HCI) solution. The system is designed to process audio and visual inputs, delivering context-aware responses using cutting-edge natural language processing and computer vision techniques. By combining OpenAI's Whisper for speech recognition and the LLaVa-7B model for visual understanding, this assistant offers a seamless experience in processing and responding to multimodal queries.
Introduction
Human-computer interaction faces significant challenges, including the need for more intuitive and context-aware interfaces that can understand and respond to multiple input modalities. Current systems often focus on singular aspects of interaction, leaving gaps in holistic communication mechanisms. This project addresses these gaps by developing an integrated system that combines speech recognition, image analysis, and natural language processing.

The Multimodal AI Assistant leverages state-of-the-art models to accurately assess and respond to user inputs across different modalities, ensuring prompt and appropriate responses. Beyond immediate query processing, the system offers features such as text-to-speech conversion and video frame analysis, making it a valuable contribution to the field of AI-assisted communication and information retrieval.
Prerequisites
Ensure you have the following prerequisites installed on your machine before starting with the Multimodal AI Assistant:
Python 3.10or higherGradiolibraryPyTorchandTransformerslibrariesWhispermodel from OpenAIgTTSfor text-to-speech conversionOpenCVfor video frame processing
Installation
Follow these steps to install and set up the Multimodal AI Assistant:
-
Clone the repository to your local machine (use the actual repository link):
git clone https://github.com/TVR28/Multimodal-AI-Assistant.git cd Multimodal-AI-Assistant -
Install the required Python libraries:
pip install -r requirements.txt
Getting Started
To get started, run the application script after installation:
python multimodal_ai_assistant.py
or run the google colab Multimodal_AI_Assistant_Llava7B.ipynb notebook with a T4 GPU to test the working.
System Overview
Methodology
This project employs a multi-module approach integrating state-of-the-art technologies for multimodal input processing, analysis, and response generation. The methodology comprises the following key components:
- Speech Recognition using OpenAI's Whisper
The system utilizes Whisper, a robust speech recognition model, to transcribe user voice inputs accurately. This enables the assistant to understand and process spoken queries effectively.
import whisper import torch DEVICE = "cuda" if torch.cuda.is_available() else "cpu" model = whisper.load_model("medium", device=DEVICE) print(f"Model is {'multilingual' if model.is_multilingual else 'English-only'} " f"and has {sum(p.numel() for p in model.parameters()):,} parameters.")
- Image Analysis using LLaVa-7B
For visual input processing, the LLaVa-7B model is employed. This advanced vision-language model generates detailed descriptions of images, allowing the assistant to understand and respond to visual content.
from transformers import BitsAndBytesConfig, pipeline quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16) model_id = "llava-hf/llava-1.5-7b-hf" pipe = pipeline("image-to-text", model=model_id, model_kwargs={"quantization_config": quantization_config}) # Example usage from PIL import Image image_path = "example.jpg" image = Image.open(image_path) prompt = "Describe the image in detail." outputs = pipe(image, prompt=prompt, generate_kwargs={"max_new_tokens": 200}) print(outputs[0]["generated_text"])
- Natural Language Processing
The system integrates sophisticated NLP capabilities to interpret user queries and generate contextually relevant responses, combining information from both audio and visual inputs when necessary.
import nltk nltk.download('punkt') from nltk import sent_tokenize max_new_tokens = 200 prompt_instructions = """ Describe the image using as much detail as possible, is it a painting, a photograph, what colors are predominant, what's happening in the image what is the image about? """ prompt = "USER: <image>\n" + prompt_instructions + "\nASSISTANT:" outputs = pipe(image, prompt=prompt, generate_kwargs={"max_new_tokens": 200}) outputs for sent in sent_tokenize(outputs[0]["generated_text"]): print(sent) warnings.filterwarnings("ignore")
- Text-to-Speech Conversion
To provide a more interactive experience, the assistant includes a text-to-speech module using gTTS, converting AI-generated text responses into audible speech.
from gtts import gTTS def text_to_speech(text, file_path): audio_obj = gTTS(text=text, lang="en", slow=False) audio_obj.save(file_path) return file_path # Example usage text_to_speech("This is a test response.", "response.mp3")
- Video & Frame Analysis through CV
An additional feature allows the system to capture and analyze frames from live video, extending its capabilities to real-time visual processing.
import cv2 video_path = "video.mp4" cap = cv2.VideoCapture(video_path) while cap.isOpened(): ret, frame = cap.read() if not ret: break # Process each frame (e.g., pass it through an image analysis pipeline) # Example: outputs = pipe(frame) cv2.imshow("Video Frame", frame) if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows()
- Interactive Interface
import gradio as gr def process_inputs(audio_path, image_path): speech_to_text_output = transcribe(audio_path) chatgpt_output = img2txt(speech_to_text_output, image_path) processed_audio_path = text_to_speech(chatgpt_output, "response.mp3") return speech_to_text_output, chatgpt_output, processed_audio_path iface = gr.Interface( fn=process_inputs, inputs=[gr.Audio(source="microphone"), gr.Image(type="filepath")], outputs=[gr.Textbox(), gr.Textbox(), gr.Audio()], title="Multimodal AI Assistant", description="Interact using voice and images." ) iface.launch()
Experimental Results
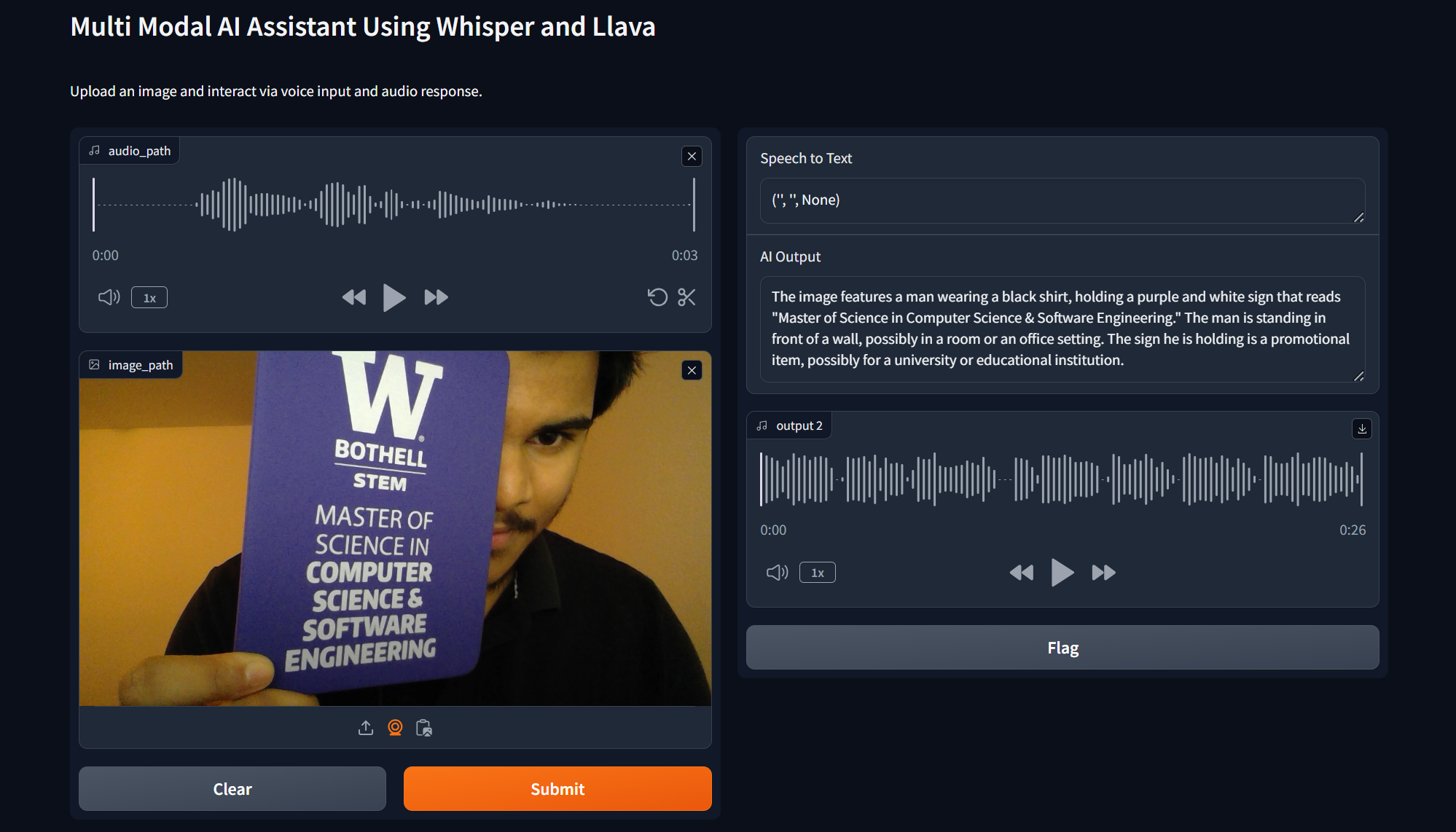
The Multimodal AI Assistant demonstrates impressive capabilities in processing and responding to diverse input types. Experimental results show high accuracy in speech transcription and image description tasks, with the system effectively combining information from multiple modalities to provide comprehensive responses.
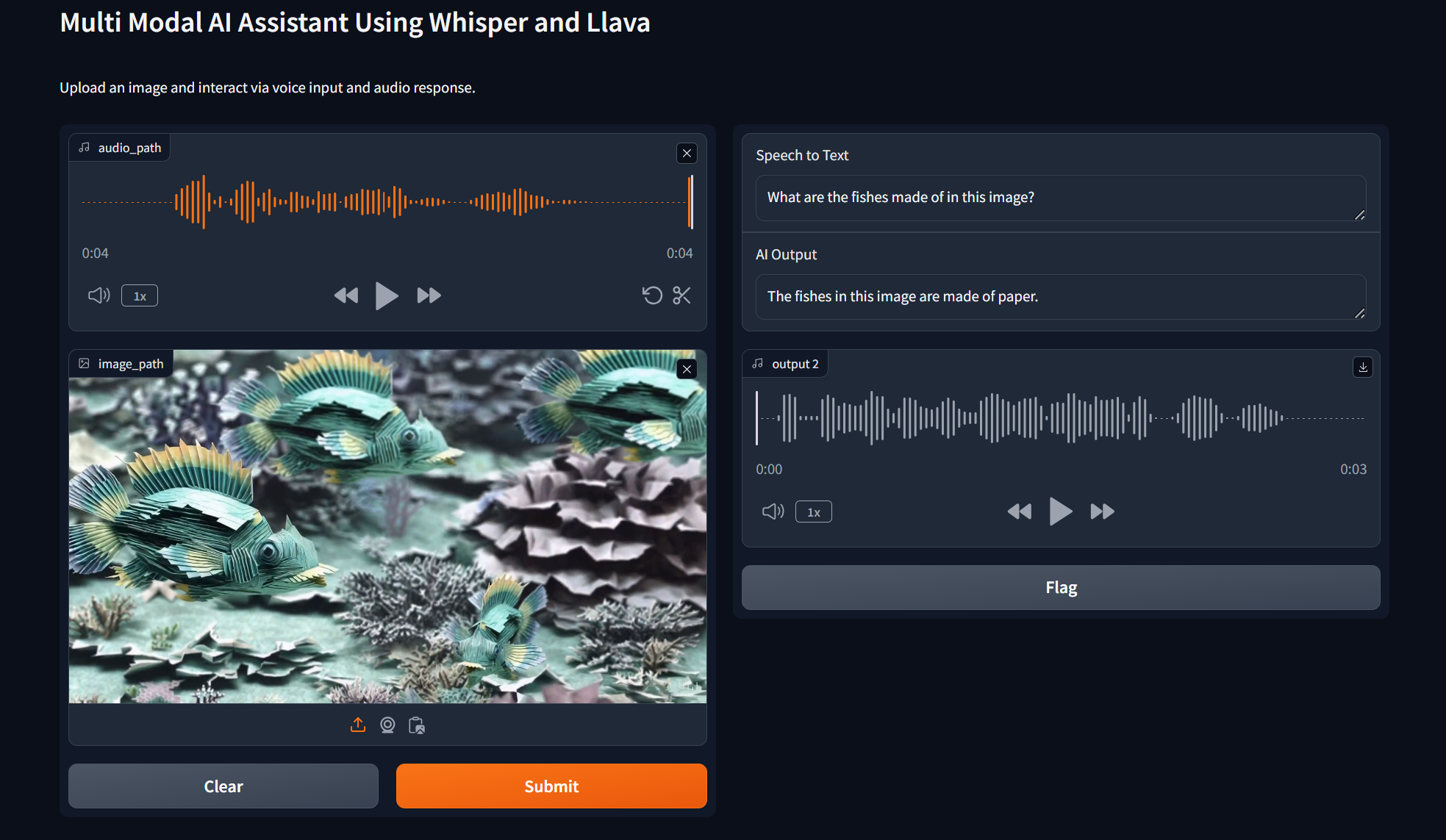
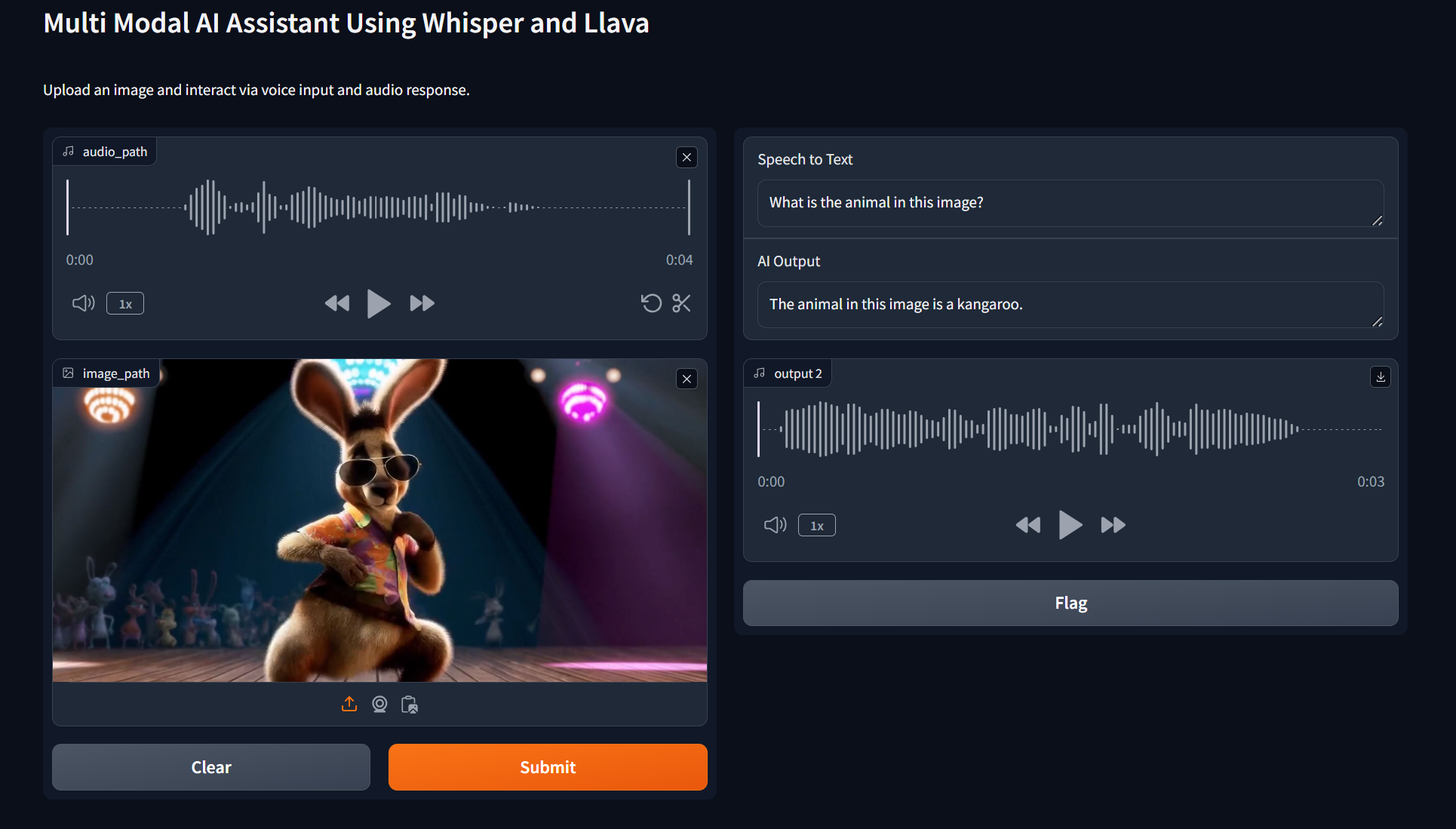
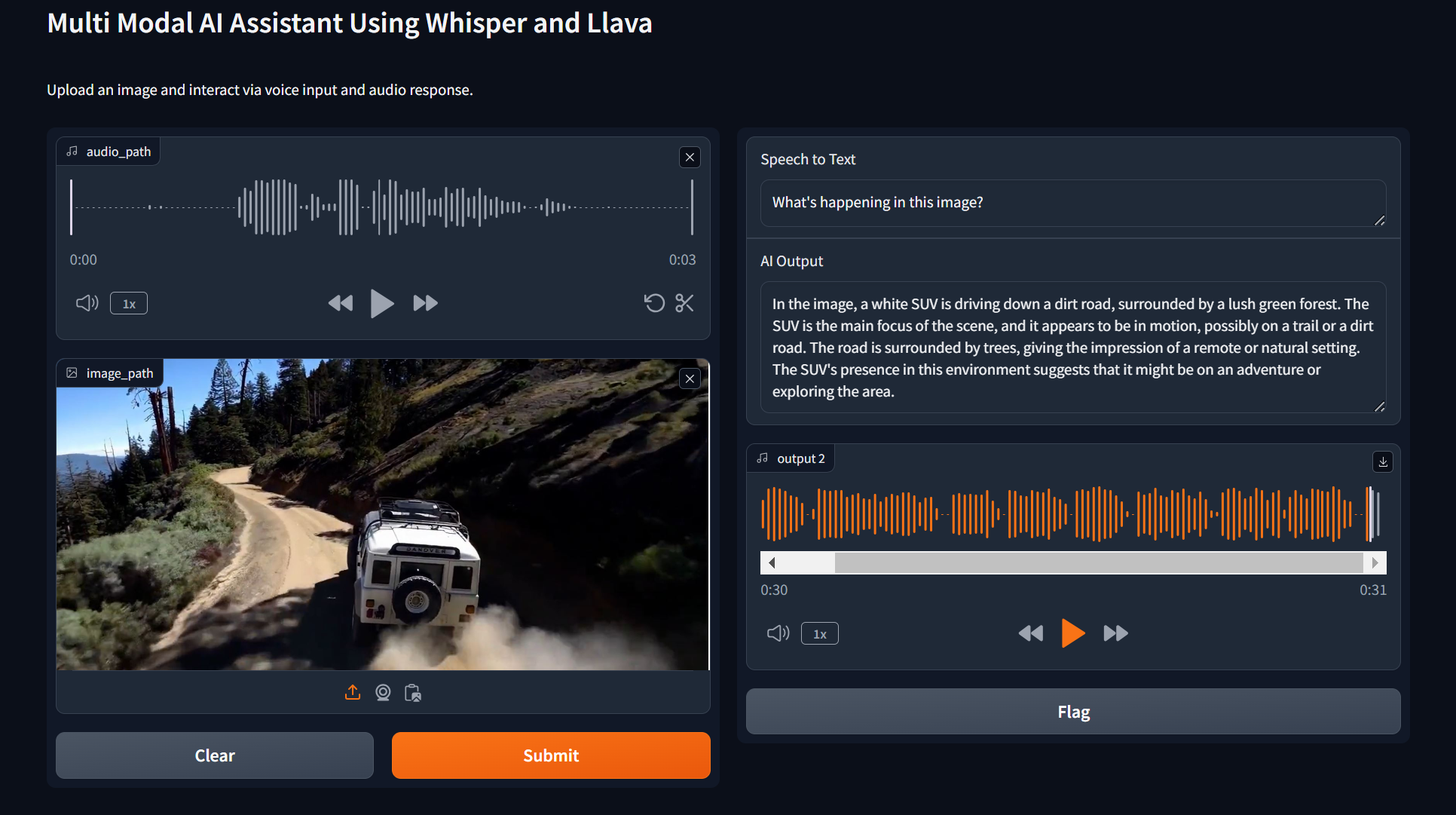
Why This Application is Useful in Industry?
The Multimodal AI Assistant has significant potential across various industries due to its ability to process and analyze multimodal data (audio, visual, and text) efficiently. Below are the key reasons why this application is valuable:
- Enhanced Customer Interaction: Provides businesses with an intuitive interface for customer service by enabling voice and image-based queries, improving user engagement and satisfaction.
- Accessibility Solutions: Assists individuals with disabilities by offering voice-to-text and text-to-speech functionalities, making technology more inclusive.
- Real-Time Decision-Making: Processes multimodal inputs in real-time, which is critical in industries like emergency response, healthcare, and logistics for quick and informed decisions.
- Automation of Complex Tasks: Automates tasks such as transcription, image analysis, and document retrieval, reducing human effort and increasing productivity.
- Educational Tools: Offers interactive learning experiences by analyzing visual content and providing detailed explanations, aiding in education and training.
- Media Analysis: Facilitates content creators and media professionals by analyzing images or videos to extract meaningful insights or generate descriptions.
- Document Management: Supports businesses in retrieving information from diverse document formats (e.g., PDFs, CSVs), streamlining workflows.
- Scalability Across Domains: Adaptable to various domains such as healthcare (medical imaging), retail (product recommendations), and public safety (incident analysis).
This versatility makes the Multimodal AI Assistant a transformative tool for enhancing efficiency, accessibility, and decision-making across industries.
Conclusion
The Multimodal AI Assistant represents a significant advancement in AI-assisted communication applications. By seamlessly integrating speech recognition and realtime image/video analysis it offers a versatile and intuitive interface for human-computer interaction. The project not only demonstrates the potential of combining cutting-edge AI models but also opens avenues for future research in multimodal AI systems.
Future work may focus on expanding the system's capabilities to include more diverse input types, improving real-time processing efficiency, and enhancing the contextual understanding across longer conversations.
References
OpenAI. (2022). Whisper: Robust Speech Recognition via Large-Scale Weak Supervision. https://arxiv.org/abs/2212.04356
Liu, H., et al. (2023). Visual Instruction Tuning. https://arxiv.org/abs/2304.08485
Gradio. (2023). Gradio: Build Machine Learning Web Apps in Python. https://www.gradio.app/
GitHub: https://github.com/TVR28/Computer-Vision/tree/main/Multimodal-AI-Assistant
Colab Notebook: https://colab.research.google.com/drive/1EObkOG0Cpzm_6i0v1ryctEEfNlpX60cN?usp=sharing
Acknowledgments
We thank the developers of OpenAI's Whisper and the LLaVa model for their groundbreaking work, which made this project possible. We also acknowledge the contributions of the open-source community in developing the libraries and tools used in this project.