
An open-source, async-first Python framework for building multi-agent AI systems with an innovative approach to parallelism, so you can focus on creating intelligent agents, not on managing the concurrency of your flows.
To install MiniAgents run the following command:
pip install -U miniagents
The source code of the project is hosted on GitHub.
Write procedural code, get parallel execution: Unlike graph-based frameworks that force you to think in nodes and edges, MiniAgents lets you write straightforward sequential code while the framework handles the complexities of parallel execution for agent interactions automatically. Your code stays clear and readable.
Nothing blocks until it's needed: With its innovative promise-based architecture, agents execute in parallel. Execution only blocks at points where specific agent messages are actively awaited. Agents communicate through replayable promises of message sequences, not just concrete messages or single-pass async generators. This replayability is a key distinction, allowing message streams to be consumed multiple times by different agents or for different purposes, fostering flexible data flows and enabling maximum concurrency without complex manual synchronization code.
Immutable message philosophy: MiniAgents uses immutable, Pydantic-based messages that eliminate race conditions and data corruption concerns. This design choice enables highly parallelized agent execution without many of the common headaches of state management. (While messages themselves are immutable, state can still be maintained across multiple invocations of agents by using forked agent instances, a pattern demonstrated later in this tutorial.)
Fundamental Agent Contract: Every miniagent adheres to a simple contract: it receives a promise of an input sequence of message promises, arbitrary keyword arguments passed to it (which are all automatically "frozen" unless passed via non_freezable_kwargs upon forking an agent, which will be explained later in this tutorial), and in return, it produces a promise of a reply sequence of message promises.
Sequential Appearance, Parallel Reality via Promises: MiniAgents achieves this seamless blend of procedural style and concurrent execution through one of its core mechanisms: "Message Sequence Flattening". Here is a very simple example (a more complex example will be shown later in this tutorial):
@miniagent async def aggregator_agent(ctx: InteractionContext) -> None: # This looks sequential but all agents start working in parallel ctx.reply([ # All nested sequences here will be asynchronously "flattened" in the # background for an outside agent (i.e., the one triggering the # `aggregator_agent`), so that when the outside agent consumes the # result, it appears as a single, flat sequence of messages. "Starting analysis...", research_agent.trigger(ctx.message_promises), calculation_agent.trigger(ctx.message_promises), "Analysis complete!", ])
In this tutorial we'll build a system that can:
The animation above demonstrates what the output of this system will look like.
NOTE: The complete source code is available here.
Let's start by exploring MiniAgents' central feature - "Message Sequence Flattening". We will explain what this means and how it simplifies building concurrent applications shortly. For this, we will build the first, dummy version of our Web Research System. We will not use the real LLM, we will not do the actual web searching and scraping and we will not create the "Final Answer" agent just yet. For now, we will put asyncio.sleep() with random delays to emulate activivity instead. Later in the tutorial, we will replace these delays with real web search, scraping and text generation operations.
First, let's look at how you might approach the problem of orchestrating multiple asynchronous operations (like our dummy agents performing research, web searching, and page scraping) and combining their results using standard Python async generators in a naive way. This will help understand the challenges that MiniAgents solves.
This approach uses standard Python async def with async for ... yield to simulate how one might try to build a similar system without MiniAgents. The key thing to note here is that this method leads to sequential execution of the "agents" (async generators in this case).
The full code for this naive example can be found in sequence_flattening_naive_alternative.py.
Let's look at the agent definitions and how they are run:
# examples/sequence_flattening_naive_alternative.py import asyncio import random from typing import AsyncGenerator async def research_agent_naive(question: str) -> AsyncGenerator[str, None]: """ The main research agent, implemented naively. Calls web_search_agent_naive sequentially. """ yield f"RESEARCHING: {question}" for i in range(3): query = f"query {i+1}" # The `async for ... yield` construct processes the generator # sequentially. The `web_search_agent_naive` for "query 2" will # only start after the one for "query 1" (including all its # pretend-scraping) is finished. async for item in web_search_agent_naive(search_query=query): yield item async def web_search_agent_naive(search_query: str) -> AsyncGenerator[str, None]: """ Pretends to perform a web search and trigger scraping. Calls page_scraper_agent_naive sequentially. """ yield f"{search_query} - SEARCHING" await asyncio.sleep(random.uniform(0.5, 1)) yield f"{search_query} - SEARCH DONE" for i in range(2): url = f"https://dummy.com/{search_query.replace(' ', '-')}/page-{i+1}" # This also leads to sequential execution async for item in page_scraper_agent_naive(url=url): yield item async def page_scraper_agent_naive(url: str) -> AsyncGenerator[str, None]: """ Pretends to scrape a web page. """ yield f"{url} - SCRAPING" await asyncio.sleep(random.uniform(0.5, 1)) yield f"{url} - DONE" async def stream_to_stdout_naive(generator: AsyncGenerator[str, None]): """ Consumes the async generator and prints yielded strings. """ i = 0 async for message in generator: i += 1 print(f"String {i}: {message}") async def main_naive(): """ Main function to trigger the naive research agent and print the results. """ question = "Tell me about MiniAgents sequence flattening (naive version)" # Get the async generator result_generator = research_agent_naive(question) print() print("=== Naive Async Generator Execution ===") print() # Consume and print results await stream_to_stdout_naive(result_generator) print() print("=== End of Naive Execution ===") print() print("Attempting to reiterate (WILL YIELD NOTHING):") # NOTE: Re-iterating a standard async generator like this is not possible. # Once consumed, it's exhausted. This contrasts with MiniAgents promises, # which are replayable. await stream_to_stdout_naive(result_generator) # This won't print anything print("=== End of Reiteration Attempt ===") print() if __name__ == "__main__": asyncio.run(main_naive())
In research_agent_naive, the loop that calls web_search_agent_naive processes each "search query" one after the other. Similarly, web_search_agent_naive waits for page_scraper_agent_naive to complete for one URL before processing the next.
Here is what this process looks like as a result:
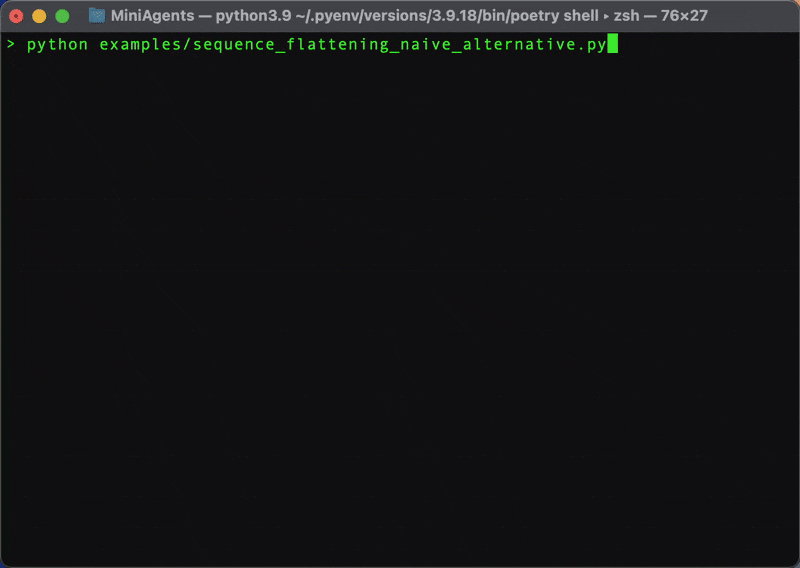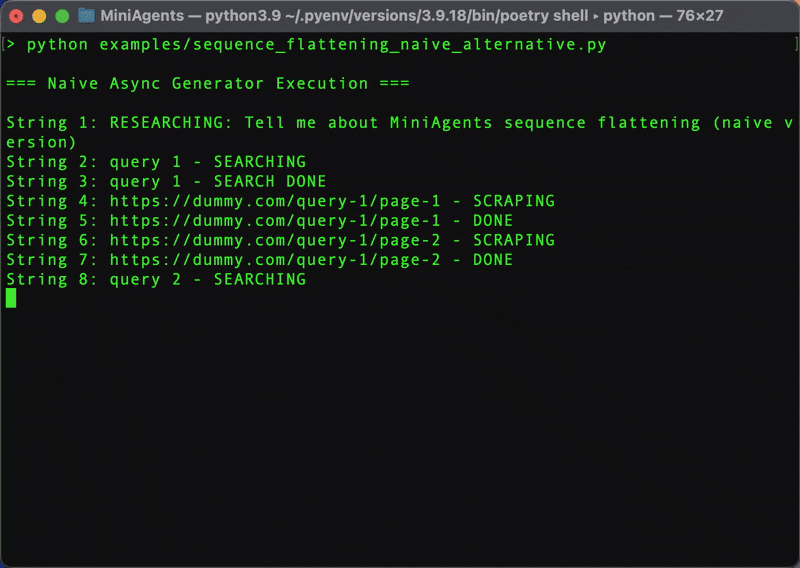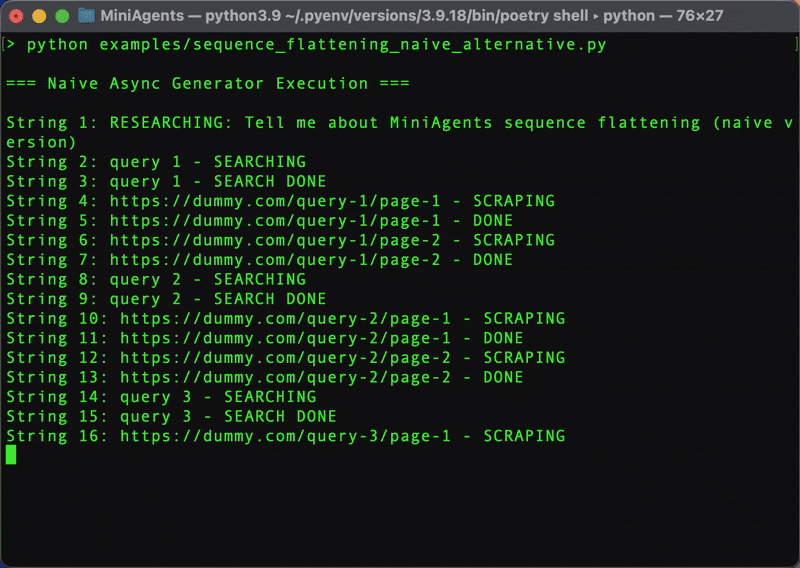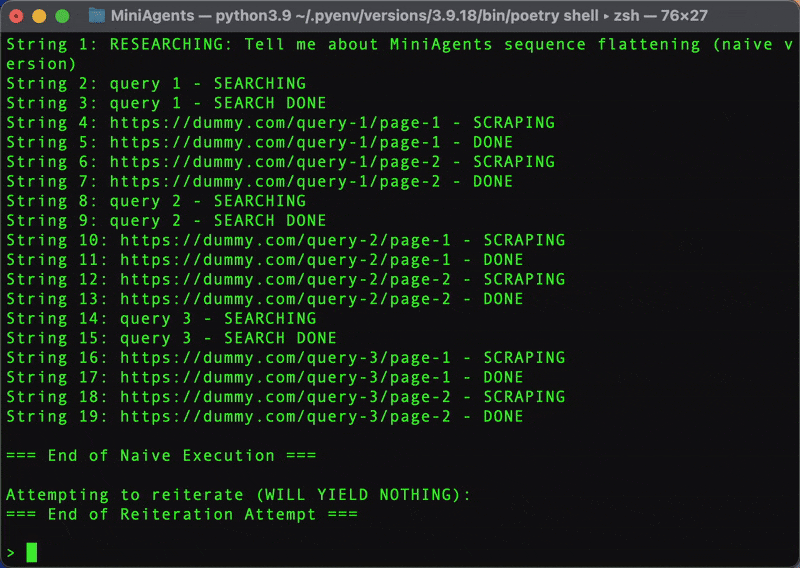
To achieve true concurrency with this naive approach, you would need to manually manage asyncio.create_task for each sub-operation and potentially use queues or other synchronization primitives to collect and yield results as they become available. This would significantly increase code complexity.
Furthermore, standard async generators, once consumed, are exhausted. If you try to iterate over the result_generator in main_naive a second time, it will yield nothing. This contrasts with MiniAgents' replayable promises.
This manual management is typical when using raw asyncio or even foundational async libraries like trio or anyio. While these libraries provide powerful concurrency tools, MiniAgents aims to provide a higher-level, agent-centric abstraction for these patterns, particularly around how agents stream and combine their results.
Now, let's see how MiniAgents addresses these challenges, enabling concurrent execution while keeping the same level of code simplicity. You'll see what the changed version of the same code looks like in a moment, but first, let's jump ahead and take a look at how different its output is going to be:
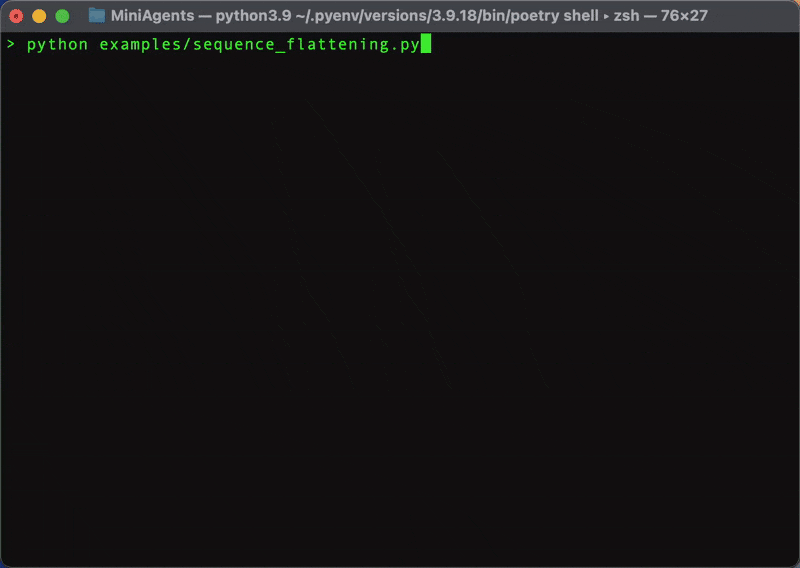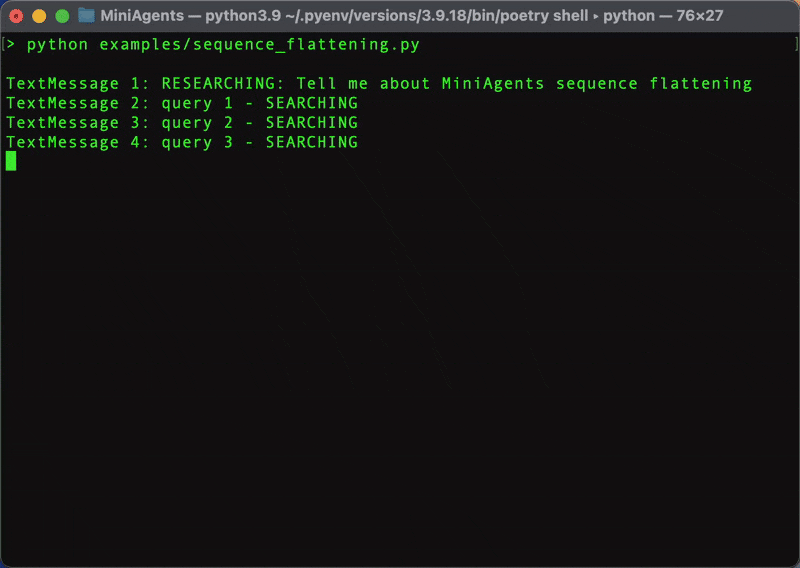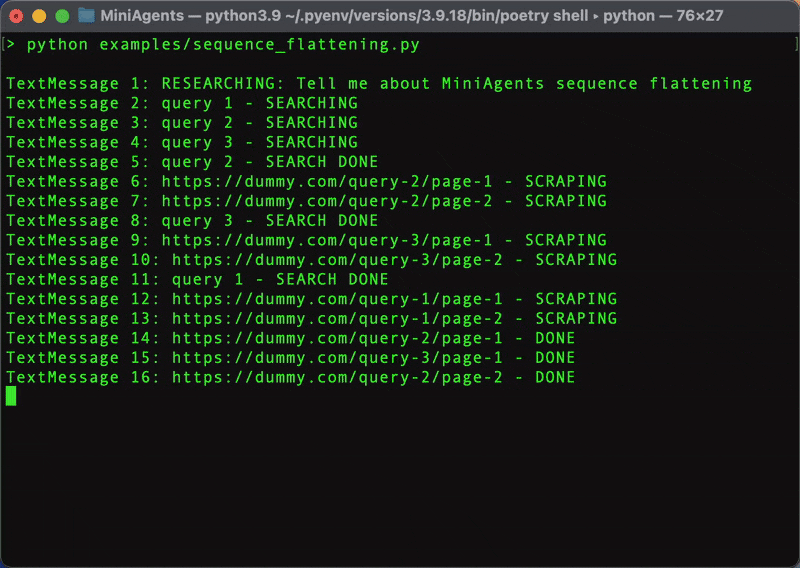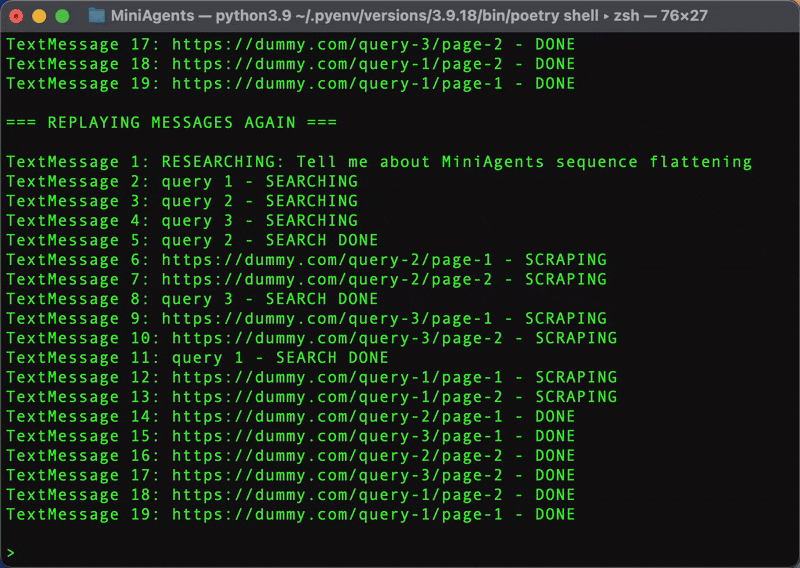
Looks much faster, doesn't it? Now, back to the code. The full example that uses MiniAgents can be found in sequence_flattening.py.
Here are the agent definitions, along with the main execution logic:
# examples/sequence_flattening.py import asyncio import random from miniagents import ( InteractionContext, Message, MessageSequencePromise, MiniAgents, miniagent, ) @miniagent async def research_agent(ctx: InteractionContext) -> None: ctx.reply(f"RESEARCHING: {await ctx.message_promises.as_single_text_promise()}") for i in range(3): # `trigger` returns immediately with a `MessageSequencePromise`. # The actual execution of `web_search_agent` starts in the background. # `reply_out_of_order` delivers messages as they become available, # not strictly in the order they are added to the reply. ctx.reply_out_of_order( web_search_agent.trigger( ctx.message_promises, # Original question search_query=f"query {i+1}", ) ) @miniagent async def web_search_agent(ctx: InteractionContext, search_query: str) -> None: ctx.reply(f"{search_query} - SEARCHING") await asyncio.sleep(random.uniform(0.5, 1)) # Simulate work ctx.reply(f"{search_query} - SEARCH DONE") for i in range(2): # Again, no `await` here when triggering the next agent. # The page_scraper_agent will run in parallel. ctx.reply_out_of_order( page_scraper_agent.trigger( ctx.message_promises, # Original question url=f"https://dummy.com/{search_query.replace(' ', '-')}/page-{i+1}", ) ) @miniagent async def page_scraper_agent(ctx: InteractionContext, url: str) -> None: ctx.reply(f"{url} - SCRAPING") await asyncio.sleep(random.uniform(0.5, 1)) # Simulate work ctx.reply(f"{url} - DONE") async def stream_to_stdout(promises: MessageSequencePromise): """ As we iterate through the `response_promises` sequence, asyncio switches tasks, allowing the agents (`research_agent`, `web_search_agent`, `page_scraper_agent`) to run concurrently in the background and resolve their promises. The `async for` loop seamlessly receives messages from the flattened sequence, regardless of how deeply nested their origins were (research_agent -> web_search_agent -> page_scraper_agent). """ i = 0 async for message_promise in promises: i += 1 print(f"{message_promise.message_class.__name__} {i}: ", end="") async for token in message_promise: print(token, end="") print() async def main(): """ Main function to trigger the research agent and print the results. Demonstrates how the flattened sequence of messages is consumed. """ # Trigger the top-level agent. This returns a MessageSequencePromise. # No processing has started yet. response_promises = research_agent.trigger( "Tell me about MiniAgents sequence flattening" ) print() await stream_to_stdout(response_promises) print() print("=== REPLAYING MESSAGES ===") print() # If we iterate through the sequence again, we will see that exactly the # same messages are yielded again (and in exactly the same order). This # demonstrates the replayability of all types of promises in MiniAgents. # # Replayability is useful because it allows you to feed the same sequences # (be it responses from agents, or input to the current agent) to multiple # other agents without even thinking that those sequences might already be # "exhausted" in a traditional, async generator sense. await stream_to_stdout(response_promises) print() print("=== REPLAYING MESSAGES AGAIN ===") print() # We can even await for the whole MessageSequencePromise to get the # complete tuple of resolved messages (demonstrating the replayability of # the promises once again). messages: tuple[Message, ...] = await response_promises for i, message in enumerate(messages): # When you run this example, you will see that for agents replying with # simple strings, they are automatically wrapped into TextMessage # objects (a subclass of Message). print(f"{type(message).__name__} {i+1}: {message}") print() if __name__ == "__main__": # The MiniAgents context manager orchestrates the async execution. MiniAgents().run(main())
In the MiniAgents version:
research_agent calls web_search_agent.trigger(...), this call is non-blocking. It immediately returns a MessageSequencePromise. The actual execution of web_search_agent starts in the background when the asyncio event loop gets a chance to switch tasks.ctx.reply(...) method (and its variant ctx.reply_out_of_order(...)) is versatile. It can accept:
Message (or its subclasses), or other concrete Python objects (like strings, dictionaries, or arbitrary Pydantic models). If not already Message objects, these are automatically wrapped into appropriate framework-specific Message types (e.g., TextMessage).MessagePromise).MessageSequencePromise), such as those returned by agent.trigger().main function (or another agent) consumes the response_promises from research_agent, it receives a single, flat sequence of all messages. This sequence includes messages produced directly by research_agent, all messages from all the triggered web_search_agent instances, and consequently, all messages from all the page_scraper_agent instances called by them.
MessageSequencePromise).async for message_promise in promises: loop in the stream_to_stdout function in our example (which consumes the results in main) leads to asyncio switching tasks. This gives the agents (research_agent, web_search_agent, page_scraper_agent) a chance to run in the background. The use of reply_out_of_order in some of the agents ensures that certain messages are yielded to the output stream as soon as they are ready from these parallel operations, rather than in the order in which they were registered as part of the agent's response. This enhances the sense of parallelism from the consumer's perspective, though it doesn't change the parallelism of the actual agent execution (which is already parallel due to trigger being non-blocking).main function of sequence_flattening.py is the replayability of MessageSequencePromise objects. You can iterate over response_promises multiple times and get the exact same sequence of messages. This is invaluable for scenarios where you might want to feed the same set of results to multiple different subsequent processing agents without worrying about "exhausting" the input stream.As you saw from the animation at the beginning of this section, the processing happens much faster, even though we didn't do anything special to achieve that, all thanks to parallelism introduced by the framework.
This automatic concurrency and sequence flattening greatly simplify the development of complex, multi-step AI systems. You can focus on the logic of each individual agent, writing code that appears sequential within the agent, while the MiniAgents framework handles the parallel execution and complex data flow management behind the scenes.
Now that we've explored the core concept of "Message Sequence Flattening" with a dummy example, let's dive into the fully functional Web Research System. This system uses real AI models for understanding and generation, performs actual web searches, and scrapes web pages to gather information.
Again, as mentioned earlier, the complete source code for this example can be found here.
Before running the web_research.py script, you'll need to set up a few things:
Installation: First, install MiniAgents and the required dependencies:
pip install -U miniagents openai httpx pydantic markdownify python-dotenv selenium
Environment Variables: For the LLM we will use OpenAI and for the google searches as well as web scraping we will use Bright Data, a pay as you go scraping service. The two Bright Data products that we are interested in are: SERP API and Scraping Browser. Create a .env file in the same directory as web_research.py with the following credentials:
# .env BRIGHTDATA_SERP_API_CREDS="your_serp_api_username:your_serp_api_password" BRIGHTDATA_SCRAPING_BROWSER_CREDS="your_scraping_browser_username:your_scraping_browser_password" OPENAI_API_KEY="your_openai_api_key"
ATTENTION: The credentials above are NOT for your whole Bright Data account. They are for the SERP API and Scraping Browser respectively (their website will guide you how to set up both products).
Helper Utilities (utils.py): The project uses a utils.py file (available here) which contains helper functions for:
fetch_google_search(): Interacts with the Bright Data SERP API.scrape_web_page(): Uses Selenium with Bright Data's Scraping Browser to fetch and parse web page content. It runs Selenium in a separate thread pool as Selenium is blocking.You don't need to dive deep into utils.py to understand the MiniAgents framework, but it's essential for the example to run.
main functionThe entry point of our application is the main() function. It orchestrates the entire process:
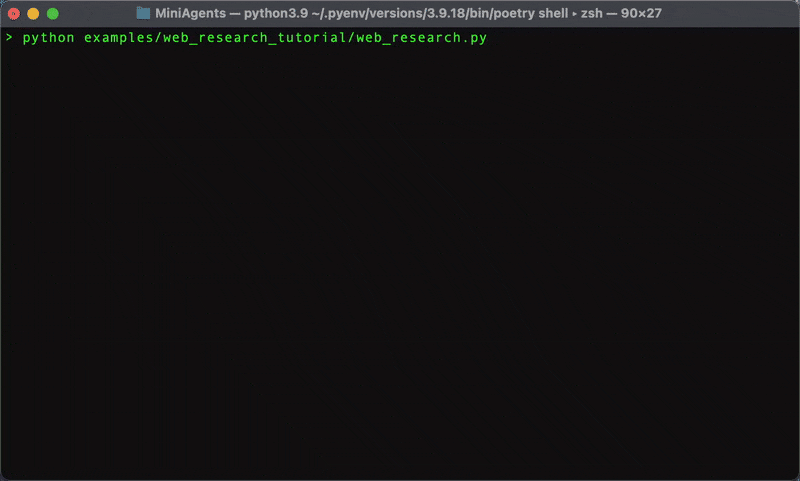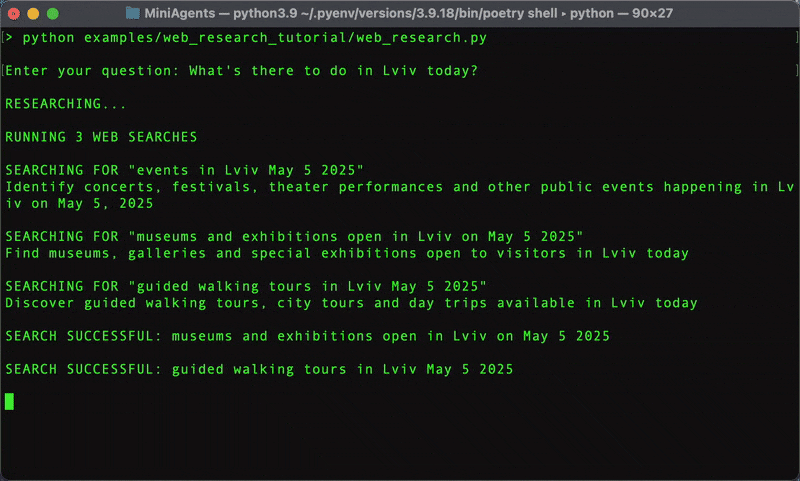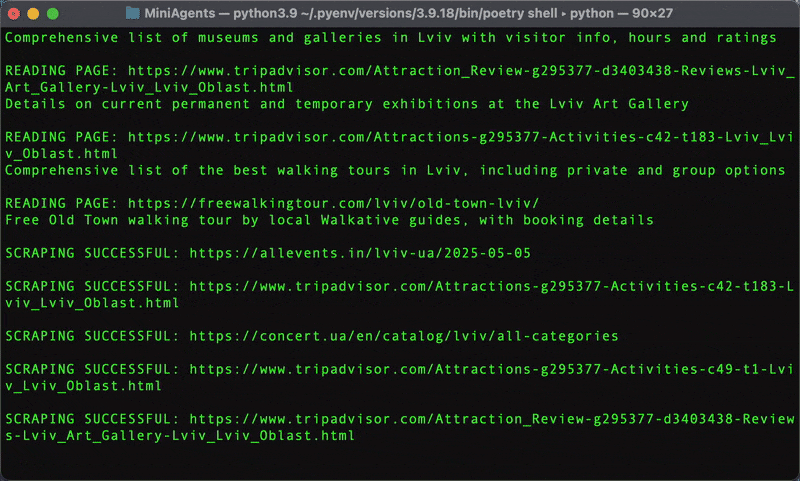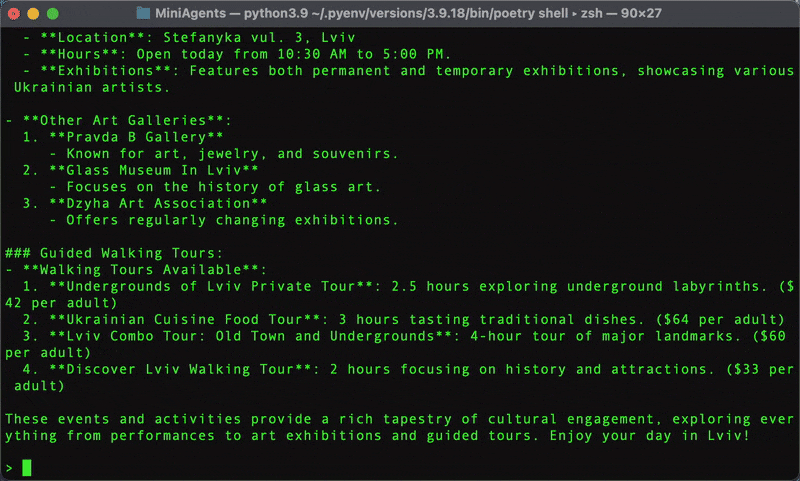
# examples/web_research_tutorial/web_research.py import asyncio from datetime import datetime from typing import Union from dotenv import load_dotenv from openai import AsyncOpenAI from pydantic import BaseModel from miniagents import ( AgentCall, InteractionContext, Message, MessageSequencePromise, MiniAgents, miniagent, ) from miniagents.ext.llms import OpenAIAgent, aprepare_dicts_for_openai from utils import fetch_google_search, scrape_web_page load_dotenv() # Load environment variables from .env file MODEL = "gpt-4o-mini" # "gpt-4o" SMARTER_MODEL = "o4-mini" # "o3" MAX_WEB_PAGES_PER_SEARCH = 2 SLEEP_BEFORE_RETRY_SEC = 5 openai_client = AsyncOpenAI() async def main(): question = input("\nEnter your question: ") # Invoke the main agent (no `await` is placed in front of the call, hence # this is a non-blocking operation, no processing starts just yet) response_promises: MessageSequencePromise = research_agent.trigger(question) print() # Iterate over the individual message promises in the response sequence # promise. The async loops below lead to task switching, so the agent above # as well as its "sub-agents" will now start their work in the background # to serve all the promises. async for message_promise in response_promises: # Skip messages that are not intended for the user (you'll see where # the `not_for_user` attribute is set later) if message_promise.known_beforehand.get("not_for_user"): continue # Iterate over the individual tokens in the message promise (messages # that aren't broken down into tokens will be delivered in a single # token) async for token in message_promise: print(token, end="", flush=True) print("\n") # ... (rest of the file)
Key takeaways from main():
not_for_user) and use it to filter what's shown to the end-user. The known_beforehand attribute of a MessagePromise allows access to metadata that is available before the message content itself is resolved. This can be useful for early filtering or routing of messages. In our main function, we use this to check the "not_for_user" flag (set in page_scraper_agent) to prevent internal page summaries from being directly displayed.print. They communicate results back, which main then decides how to present. This separation makes it easier to change the UI or even integrate this entire agentic system as a component within a larger AI system, where its output would be consumed programmatically rather than printed to a console.NOTE: Background execution is optional. MiniAgents, by default, starts processing triggered agents as soon as possible, and this is generally the desired behavior for maximum parallelism. You can, however, disable this behavior by passing start_soon=False to individual trigger calls, or by setting start_everything_soon_by_default=False in the MiniAgents constructor for a global effect. The latter is generally not recommended, though. Disabling "early start" globally can often lead to deadlocks if agent interdependencies are complex, and in the majority of scenarios, there is hardly any benefit in setting start_soon to False.
research_agent: Orchestrating the SearchThe research_agent is the primary coordinator. It takes the user's question and breaks it down into actionable steps.
# examples/web_research_tutorial/web_research.py # ... (imports and setup shown above) ... @miniagent async def research_agent(ctx: InteractionContext) -> None: ctx.reply("RESEARCHING...") # First, analyze the user's question and break it down into search queries message_dicts = await aprepare_dicts_for_openai( ctx.message_promises, # The user's question system=( "Your job is to breakdown the user's question into a list of web " "searches that need to be done to answer the question. Please try " "to optimize your search queries so there aren't too many of " "them. Current date is " + datetime.now().strftime("%Y-%m-%d") ), ) # Using OpenAI's client library directly for structured output response = await openai_client.beta.chat.completions.parse( model=SMARTER_MODEL, messages=message_dicts, response_format=WebSearchesToBeDone, # Pydantic model for structured output ) parsed: WebSearchesToBeDone = response.choices[0].message.parsed ctx.reply(f"RUNNING {len(parsed.web_searches)} WEB SEARCHES") already_picked_urls = set[str]() # Fork the `web_search_agent` to create an isolated, configurable instance # for this task. `non_freezable_kwargs` allows passing mutable objects like # our `already_picked_urls` set, which will then be specific to this forked # agent instance and shared across its invocations within this research # task. _web_search_agent = web_search_agent.fork( non_freezable_kwargs={ "already_picked_urls": already_picked_urls, }, ) # Initiate a call to the final_answer_agent. We'll send it data as we # gather it. final_answer_call: AgentCall = final_answer_agent.initiate_call( user_question=await ctx.message_promises, ) # For each identified search query, trigger a web search agent for web_search in parsed.web_searches: search_and_scraping_results = _web_search_agent.trigger( ctx.message_promises, # Forwarding the original user question search_query=web_search.web_search_query, rationale=web_search.rationale, ) # `reply_out_of_order` sends messages to the research_agent's output # as they become available, maintaining responsiveness. ctx.reply_out_of_order(search_and_scraping_results) # Send the same results to the final_answer_agent final_answer_call.send_message(search_and_scraping_results) # Reply with the sequence from final_answer_agent, effectively chaining # its output to research_agent's output. This also closes the call to # final_answer_agent. ctx.reply(final_answer_call.reply_sequence()) # ... (other agents)
Key aspects of research_agent:
openai_client.beta.chat.completions.parse) to break the user's question into a list of specific search queries. WebSearchesToBeDone is a Pydantic model that ensures the LLM returns data in the expected structure (using OpenAI's "structured output" feature). While this example uses the OpenAI client library directly for structured output, MiniAgents plans to support this natively as another built-in LLM miniagent, along with already existing OpenAIAgent, AnthropicAgent etc. which simply generate text.web_search_agent needs to keep track of URLs it has already decided to scrape to avoid redundant work. agent.fork() creates a new, independent version (an "instance") of the agent. This is useful for creating agents with specific configurations or, as in this case, for endowing an agent instance with mutable state (like already_picked_urls) that is shared across its invocations by this particular forked instance. The non_freezable_kwargs argument is the mechanism for passing such mutable resources that cannot (or should not) be "frozen" by the fork.initiate_call): The final_answer_agent will eventually synthesize an answer using all gathered information. We don't have all this information upfront. final_answer_agent.initiate_call() creates an AgentCall object. This allows research_agent to send messages (or message promises) to final_answer_agent incrementally using final_answer_call.send_message().trigger without await): For each generated search query, _web_search_agent.trigger() is called. Again, no await means these sub-agents start working in parallel.ctx.reply_out_of_order): As results from _web_search_agent (which include search and scraping steps) become available, ctx.reply_out_of_order() sends them to the output stream of research_agent. As mentioned earlier, we use reply_out_of_order() to avoid enforcing message delivery in the order they were added to the reply. Delivering these messages as soon as they are available allows research_agent to show progress from different search branches in real time.ctx.reply(final_answer_call.reply_sequence()) takes the response that final_answer_agent will produce (in this example, a sequence consisting of a single message containing the synthesized answer) and appends it to research_agent's own output. reply_sequence() also signals to final_answer_agent that no more input messages will be sent via final_answer_call.send_message(), effectively closing the call (such behavior can be prevented with reply_sequence(finish_call=False) if needed, though).web_search_agent: Searching and Selecting PagesThis agent takes a single search query, performs the search, and then uses an LLM to decide which of the resulting pages are most relevant for scraping.
# examples/web_research_tutorial/web_research.py # ... (research_agent) ... @miniagent async def web_search_agent( ctx: InteractionContext, search_query: str, rationale: str, already_picked_urls: set[str], # Received from the forked instance ) -> None: ctx.reply(f'SEARCHING FOR "{search_query}"\n{rationale}') try: search_results = await fetch_google_search(search_query) # from utils.py except Exception: await asyncio.sleep(SLEEP_BEFORE_RETRY_SEC) ctx.reply(f"RETRYING SEARCH: {search_query}") search_results = await fetch_google_search(search_query) ctx.reply(f"SEARCH SUCCESSFUL: {search_query}") message_dicts = await aprepare_dicts_for_openai( [ ctx.message_promises, # Original user question f"RATIONALE: {rationale}\n\nSEARCH QUERY: {search_query}\n\n" f"SEARCH RESULTS:\n\n{search_results}", ], system=( "This is a user question that another AI agent (not you) will " "have to answer. Your job, however, is to list all the web page " "urls that need to be inspected to collect information related to " "the RATIONALE and SEARCH QUERY. SEARCH RESULTS where to take the " "page urls from are be provided to you as well. Current date is " + datetime.now().strftime("%Y-%m-%d") ), ) response = await openai_client.beta.chat.completions.parse( model=SMARTER_MODEL, messages=message_dicts, response_format=WebPagesToBeRead, # Pydantic model for structured output ) parsed: WebPagesToBeRead = response.choices[0].message.parsed web_pages_to_scrape: list[WebPage] = [] for web_page in parsed.web_pages: if web_page.url not in already_picked_urls: web_pages_to_scrape.append(web_page) already_picked_urls.add(web_page.url) if len(web_pages_to_scrape) >= MAX_WEB_PAGES_PER_SEARCH: break for web_page in web_pages_to_scrape: ctx.reply_out_of_order( page_scraper_agent.trigger( ctx.message_promises, # Original user question url=web_page.url, rationale=web_page.rationale, ) ) # ... (page_scraper_agent and final_answer_agent)
Highlights of web_search_agent:
fetch_google_search() (from utils.py) to get search results. Includes basic retry logic.WebPagesToBeRead Pydantic model.already_picked_urls set (provided by the fork in research_agent) to avoid re-processing URLs that have already been selected from other search queries in the same overall research task. It also limits the number of pages scraped per search query (MAX_WEB_PAGES_PER_SEARCH).page_scraper_agent.trigger() is called without await, initiating parallel scraping operations. Results are again channeled using ctx.reply_out_of_order().page_scraper_agent: Fetching and Summarizing ContentThis agent is responsible for fetching the content of a single web page and then using an LLM to extract relevant information.
# examples/web_research_tutorial/web_research.py # ... (web_search_agent) ... @miniagent async def page_scraper_agent( ctx: InteractionContext, url: str, rationale: str, ) -> None: ctx.reply(f"READING PAGE: {url}\n{rationale}") try: page_content = await scrape_web_page(url) # from utils.py except Exception: await asyncio.sleep(SLEEP_BEFORE_RETRY_SEC) ctx.reply(f"RETRYING: {url}") page_content = await scrape_web_page(url) # We await the full summary here because we want to ensure summarization # is complete before reporting success for this page. page_summary = await OpenAIAgent.trigger( [ ctx.message_promises, # Original user question f"URL: {url}\nRATIONALE: {rationale}\n\n" f"WEB PAGE CONTENT:\n\n{page_content}", ], system=( "This is a user question that another AI agent (not you) will " "have to answer. Your job, however, is to extract from WEB PAGE " "CONTENT facts that are relevant to the users original question. " "The other AI agent will use the information you extract along " "with information extracted by other agents to answer the user's " "original question later. Current date is " + datetime.now().strftime("%Y-%m-%d") ), model=MODEL, # Streaming isn't important for this internal summary stream=False, # If summarization fails, let this agent fail rather than sending an # error message. This is a choice; for robustness, True might be # preferred if partial results are acceptable. errors_as_messages=False, response_metadata={ # This summary is for the final_answer_agent, not directly for the # user. "not_for_user": True, }, ) ctx.reply(f"SCRAPING SUCCESSFUL: {url}") ctx.reply(page_summary) # Send the extracted summary # ... (final_answer_agent)
Key points for page_scraper_agent:
scrape_web_page() (from utils.py), which uses Selenium to get page content. Includes retry logic.OpenAIAgent is used here. It's triggered to process the scraped content and extract information relevant to the original user question and the rationale for visiting this specific page.trigger calls, page_summary = await OpenAIAgent.trigger(...) awaits the result. This is a design choice: we want to ensure the summarization is complete and successful before this agent reports SCRAPING SUCCESSFUL and sends the summary onward.errors_as_messages=False): For this particular call to OpenAIAgent, errors_as_messages is set to False. This means if the LLM call fails, the page_scraper_agent itself will raise an exception. The overall system is configured with errors_as_messages=True (see the if __name__ == "__main__": block later in the tutorial), so this local override demonstrates fine-grained control. If it were True (or defaulted to the global setting), an LLM error would result in an error message being sent as page_summary instead of crashing this agent.response_metadata): The OpenAIAgent.trigger call includes response_metadata. This dictionary is attached to the message(s) produced by OpenAIAgent. Here, "not_for_user": True signals that this summary is an intermediate result, primarily for the final_answer_agent, and shouldn't be directly displayed to the user by the main function's loop. It's worth noting that metadata keys like "not_for_user" are arbitrary choices specific to this application's design; you can use any key names that suit your system's logic for routing or annotating messages.final_answer_agent: Synthesizing the ResultThis agent receives all the summaries and extracted pieces of information from the various page_scraper_agent instances and synthesizes a final answer to the user's original question.
# examples/web_research_tutorial/web_research.py # ... (page_scraper_agent) ... @miniagent async def final_answer_agent( ctx: InteractionContext, user_question: Union[Message, tuple[Message, ...]], ) -> None: # Await all incoming messages (summaries from page_scraper_agents) to # ensure they are "materialized" before we proceed to show the "ANSWER" # heading. If not for this heading, `await` would not have been important # here - OpenAIAgent will internally await for all the incoming messages to # make them part of its prompt anyway. await ctx.message_promises ctx.reply("==========\nANSWER:\n==========") ctx.reply( OpenAIAgent.trigger( [ "USER QUESTION:", user_question, # Passed as a kwarg during initiate_call "INFORMATION FOUND ON THE INTERNET:", # Concatenate all received messages (page summaries) into a # single text block. `as_single_text_promise()` returns a # promise; actual concatenation happens in the background. ctx.message_promises.as_single_text_promise(), ], system=( "Please answer the USER QUESTION based on the INFORMATION " "FOUND ON THE INTERNET. Current date is " + datetime.now().strftime("%Y-%m-%d") ), model=MODEL, # stream=True, # In LLM miniagents streaming is enabled by default. # Explicitly setting stream=False would turn it off. ) ) # ... (Pydantic models and main block)
Key features of final_answer_agent:
await ctx.message_promises): Before generating the answer, this agent explicitly await ctx.message_promises. This ensures that all the page summaries sent by research_agent (via final_answer_call.send_message()) have arrived and are resolved. This is important because we want the "ANSWER:" heading to appear after all the processing logs (like "SEARCHING...", "READING PAGE...").ctx.message_promises.as_single_text_promise() is a handy method. It takes the sequence of incoming messages (which are progress logs and page summaries) and concatenates them into a single text message promise, with original messages separated by double newlines. This consolidated text, along with the original user question, forms the prompt for the final LLM call. (Although it's worth noting that you could have passed all these messages into the prompt without such concatenation - they would all have appeared to the LLM as separate dialog turns in that case.)OpenAIAgent is triggered one last time to produce the comprehensive answer. OpenAIAgent streams by default, so the final answer will appear token by token to the user, providing a responsive experience.Our example uses Pydantic models with OpenAI's "Structured Output" feature (via response_format in client.beta.chat.completions.parse) to guide the LLM in generating responses in a specific format:
# examples/web_research_tutorial/web_research.py # ... (final_answer_agent) ... class WebSearch(BaseModel): rationale: str web_search_query: str class WebSearchesToBeDone(BaseModel): web_searches: tuple[WebSearch, ...] class WebPage(BaseModel): rationale: str url: str class WebPagesToBeRead(BaseModel): web_pages: tuple[WebPage, ...] # ... (if __name__ == "__main__":)
These models (WebSearchesToBeDone, WebPagesToBeRead) help ensure that the LLM provides its output in a way that can be reliably parsed and used by the subsequent logic in the agents.
The if __name__ == "__main__": block initializes and runs the MiniAgents system:
# examples/web_research_tutorial/web_research.py # ... (Pydantic models) ... if __name__ == "__main__": MiniAgents( # Log LLM requests/responses to markdown files in `llm_logs` llm_logger_agent=True, # Convert agent errors into messages rather than crashing the agents errors_as_messages=True, # # Optionally include full tracebacks in error messages for debugging # error_tracebacks_in_messages=True, ).run(main())
Key MiniAgents configurations used here:
llm_logger_agent=True: This is incredibly useful for debugging. It logs all requests to and responses from LLM miniagents (like OpenAIAgent) into markdown files in an llm_logs directory. You can inspect these logs to see the exact prompts, model parameters, and outputs.errors_as_messages=True: This global setting makes the system more robust. If an agent encounters an unhandled exception, instead of the agent (and potentially the whole flow) crashing, the error is packaged into an ErrorMessage object and continues through the system. As we saw, page_scraper_agent locally overrides this for its LLM calls by setting errors_as_messages=False in the trigger call.error_tracebacks_in_messages=True (commented out): If you enable this, the error messages produced when errors_as_messages=True will also include the full Python traceback, which can be helpful during development (only useful when errors_as_messages=True, because when errors_as_messages=False, errors are raised as exceptions and are logged to the console with the tracebacks regardless of the error_tracebacks_in_messages setting).This Web Research System demonstrates several powerful features of MiniAgents:
trigger calls without await lead to parallel execution.MessageSequencePromise objects, allowing computation to proceed while data is still being gathered.ctx.reply_out_of_order for responsive streaming and agent.initiate_call for incremental data feeding provide fine-grained control over message flow.agent.fork() offers a clean way to create isolated, configurable instances of agents, which can be used for managing state specific to a task or for creating differently parameterized versions of an agent.OpenAIAgent, AntropicAgent etc. provide a convenient, MiniAgents-native way to incorporate LLM capabilities from popular providers like OpenAI and Anthropic into your agents. (More such built-in LLM miniagents will be added in the future and there will also be a tutorial showing how easy it is to create such an LLM miniagent on your own.)llm_logger_agent aid in development by providing visibility into LLM interactions.errors_as_messages help create more resilient systems.By focusing on the logic of individual agents, MiniAgents lets you build sophisticated, concurrent AI systems without getting bogged down in the complexities of manual parallelism management. The system naturally parallelizes IO-bound tasks (like calls to LLMs or external APIs) without requiring explicit concurrency code from the developer, as AI agents are typically IO-bound.
Join our Discord community to get help with your projects. We welcome questions, feature suggestions, and contributions!

