Llama2 Fine Tuning with PEFT QLoRA
Table of contents
Optimizing LLaMA 2 using QLoRA adapters to minimize memory usage.
Abstract
The growing computing needs of contemporary transformer systems have made the efficient fine-tuning of large language models (LLMs) an important research topic. This work investigates the use of Parameter-Efficient Fine-Tuning (PEFT) methods, particularly Low-Rank Adaptation (LoRA), to maximize LLaMA 2 model performance while reducing memory overhead. To make fine-tuning on the OpenAssistant-Guanaco dataset easier, the pipeline incorporates the transformers, peft, and trl libraries from Hugging Face. To improve response creation, we use structured conversational training, LoRA settings, and dataset preprocessing. The suggested strategy strikes a balance between resource efficiency and model adaptation, showing promise for practical implementation in resource-constrained settings.
Introduction
Natural language processing (NLP) has been transformed by large language models (LLMs), which allow for the synthesis of text that is human-like in a variety of applications, such as chatbots, content production, and automated assistants. Nevertheless, optimizing these models poses substantial memory and computational difficulties, especially in situations with limited resources. For many real-world applications, traditional full-model fine-tuning is impracticable due to its high computational and GPU memory requirements.
In order to overcome these obstacles, Parameter-Efficient Fine-Tuning (PEFT) techniques, like Low-Rank Adaptation (LoRA), have become promising substitutes. Low-rank matrices are introduced into pre-trained model layers via LoRA, which drastically decreases the number of trainable parameters while preserving fine-tuning efficiency. In this work, LLaMA 2, a high-performance causal language model, is fine-tuned using LoRA-based techniques to maximize its response generating capabilities.
To effectively fine-tune LLaMA 2, we leverage the OpenAssistant-Guanaco dataset, which comprises structured human-assistant conversations. To make dataset processing, model modification, and effective training easier, our approach makes use of the Hugging Face transformers, peft, and trl libraries. By using LoRA-based fine-tuning, we want to achieve a compromise between computational economy and model performance, making LLM fine-tuning more affordable and available for practical uses.
This project implements QLoRA (Quantized Low-Rank Adaptation) with PEFT (Parameter-Efficient Fine-Tuning) to efficiently fine-tune LLaMA 2 while reducing memory usage. The project leverages 4-bit quantization and LoRA adapters to achieve high performance with minimal computational cost.Here is the sample output of the training result:
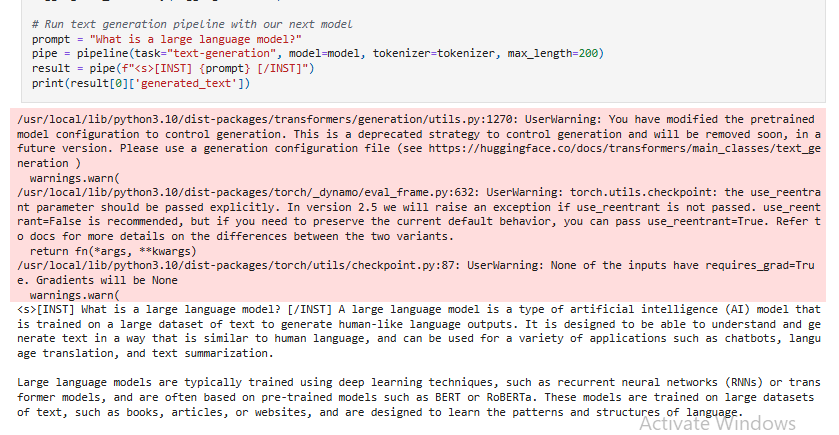 . Additionally, Entire code is available in this attached repository:https://github.com/shehab0911/Llama2-Fine-Tuning-with-PEFT-QLoRA.
. Additionally, Entire code is available in this attached repository:https://github.com/shehab0911/Llama2-Fine-Tuning-with-PEFT-QLoRA.