Abstract
The use of Artificial Intelligence (AI) in the medical field is essential for improving current methods and rapidity. This study analyses the performance of a U-Net neural network for detecting the liver in human CT scans. For the training and testing, the mean Pixel Accuracy (mPA) obtained is more than 0.99, and the mean Intersection over Union (mIoU) obtained is over 0.98. This findings suggest promising abilities of the model. U-Net also considerably outperforms a simple CNN baseline in every tested aspect. Overall, we believe it is capable to segment liver tissue with high precision and should be considered for the further evaluation.
Problem Description
The use of AI in the medical field is gaining ground. Nowadays, new challenges appear to improve AI efficiency, in terms of rapidity and accuracy. The purpose of this study is to evaluate the performance of a U-Net neural network, as defined by Ronneberger, in an image semantic segmentation task. More precisely, the task of the neural network here is to find the liver in axial human CT scans.
The data can be accessed via this URL. The data set contains both inputs and corresponding annotated expected outputs (called labels or masks). In the masks, white pixels represent the liver. All Python files and results can be found on GitHub.
Approach to Solution
Our research task was divided into many steps:
-
Exploratory Data Analysis (EDA) and data preprocessing
-
Building models
-
Training models and adjusting parameters
-
Evaluating models.
The Exploratory Data Analysis allowed us to gain knowledge about the data provided, and interpret more accurately the results we obtained. Data preprocessing was done at the same time, by splitting the data set into training, validation, and testing data sets.
Then, we built the models. The U-Net model was adapted from the article by Ronneberger. The CNN baseline model was custom made but inspired by the same article. The idea was to keep some blocks from the U-Net, but with fewer and simpler layers. Thus, the baseline model contains convolutional layers, pooling layers and upsampling layers. As in the U-Net, ReLU was used.
We trained the models and adjusted them to improve performance metrics and reduce loss values (for training and validation). Performance metrics used here are mean Pixel Accuracy (mPA) and mean Intersection over Union (mIoU). Since it is a binary task, Binary Cross Entropy (BCE) was used for the loss metric. We adjusted the number of epochs to obtain the best results possible.
The U-Net model was evaluated thanks to previous performance and loss metrics, and compared to the baseline model.
Exploratory Data Analysis
Analysis on the whole dataset
The data set contains 400 pairs of images and labels. The images and labels have size
The images contain many shades of gray, but the masks are in black and white. Figure below represents the number of masks depending on the proportion of white pixels in the masks (where white pixels represent the liver). The percentage of white pixels is between 2% and 17%, so a model predicting only "black" pixels (i.e., the liver is nowhere) would be expected to have at least 83% accuracy. The standard accuracy is then not really relevant here. Instead, mean Pixel Accuracy (mPA) and mean Intersection over Union (mIoU) are used as performance metrics.
![]()
Analysis on the training, validation, and testing datasets
The dataset has been split randomly to obtain training, validation, and testing data sets. The data sets used for training (training and validation data sets) contain 360 pairs of image and label i.e. 90% of the whole data set. The testing data set contains 40 pairs, i.e. 10% of the whole data set. The 360 pairs, were then split between actual training data set and validation data set, with 288 pairs of image and label in the training data set (80% of the 360 pairs) and 72 pairs in the validation data set (20% of the 360 pairs).
Figure below shows this repartition (number of masks depending on the proportion of white pixels in the masks) for the training dataset. The training data set fairly represents the whole data set, as the
labels repartition is similar to that shown before.
![]()
As for the validation and testing datasets (shown below), they are less representative in terms
of the number of images per category. However, in the validation
dataset, all categories are represented.
![]()
![]()
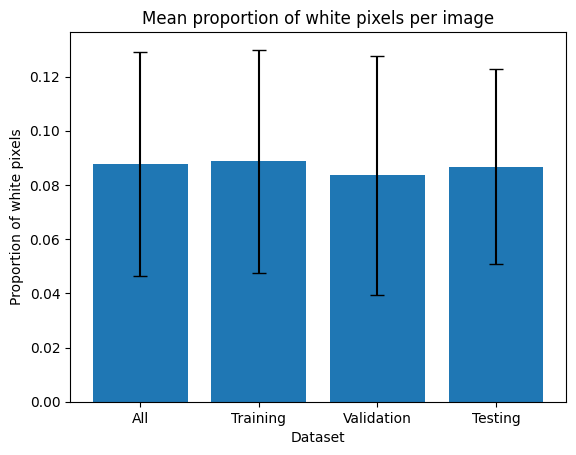
To conclude on this part, we reveal the average proportion of white pixels per image, in each data set. The mean is always in the same range, between 8% and 9%, and the standard deviation is very similar between the whole data set and the training data set. The standard deviation varies of 1% for validation and testing.
Implementation
The U-Net model can be found here, and the baseline model is available here, in our GitHub repository.
The (relevant excerpt of) configuration used for training both models is as follows:
{
"model" : "unet" or "baseline",
"in_dim" : 1,
"out_dim" : 1,
"out_activation" : "sigmoid",
"lr" : 1e-5,
"optim" : "adam",
"loss" : "bce",
"train_batch_size" : 1,
"valid_batch_size" : 1,
"epochs" : 10,
"val_metrics" : ["mPA", "mIoU"]
}
The number of epochs was set at 10, since it seemed that fewer epochs did not give optimal results on the U-Net, and with more epochs the model was not improving significantly in terms of accuracy metrics (mPA and mIoU). We trained the baseline model on the same number of epochs as determined to be optimal for the U-Net.
The optimizer used is Adam. Indeed, it combines properties of multiple optimizers, it adapts learning rate for each parameter, and proved to be very robust in most of the situations.
The learning rate was set to 1e-5. Bigger learning rates gave worst results.
The activation function chosen is Sigmoid for both models, since the case studied here is a binary classification task: white pixels (probability 1) stand for "the liver is here" and black pixels (probability 0) stand for "the liver is not here". During prediction, a threshold was set at 0.5 to transform probabilities into integers: 0 if the probability was above the threshold, or 1 if the probability was under the threshold.
Finally, batch sizes was set to 1 due to better performance compared to the higher values.
Discussion on Intelligence
Accuracy metrics and loss
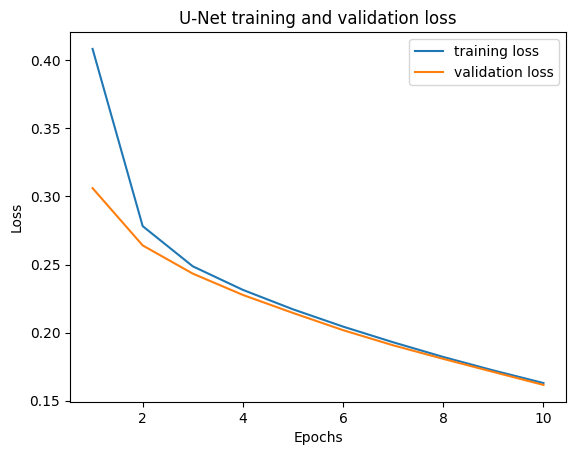
Plots below show the evolution of metrics during the training process.
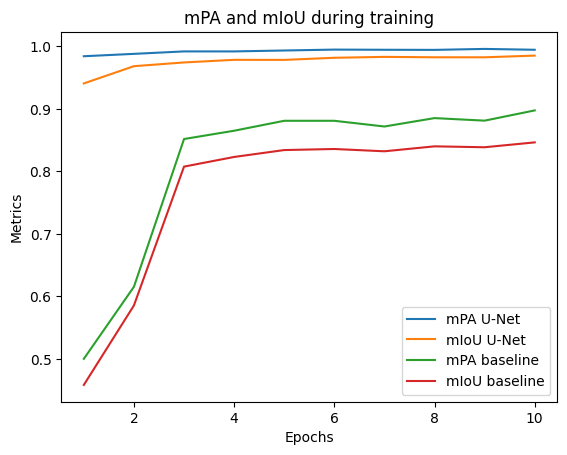
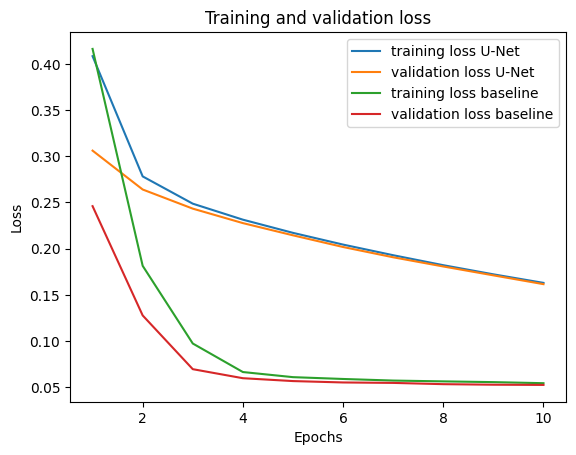
Even if loss is higher for U-Net than for the baseline model, the mPA and mIoU accuracy metrics are higher and closer to 1 for U-Net than for the baseline model. One can notice that the mPA and mIoU values are already very high at the beginning of U-Net training, which is not the case for the baseline model (mPA and mIoU around 0.5 at the beginning).
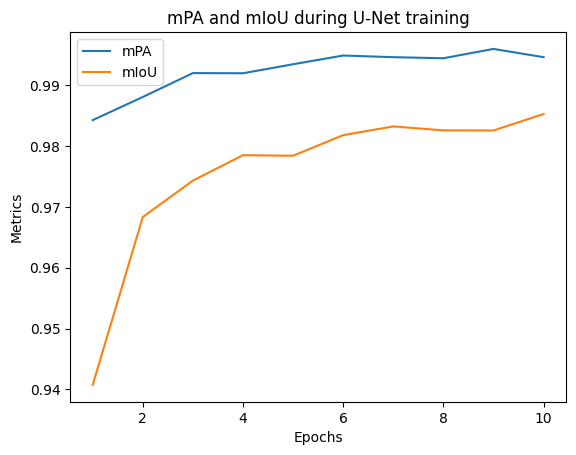
The learning curves for U-Net are displayed more precisely in figures below. As shown, the metrics are very high, and so since the beginning, with mIoU over 0.94 and mPA over 0.98. They both improve overall during training. It is noticeable that loss decreases at each epoch. The validation loss is always under the training loss, which is surprising. However, this phenomenon is also oberved with the baseline model, so it may be due to the data sets. Here, both curves tend to overlap at the end.
Evaluating models
Accuracy metrics during testing
The models are evaluated on the test data set. The mPA and mIoU results are displayed in Table below. U-Net has better results than the baseline model: +9% for mPA and +14% for mIoU.
| Baseline mPA | Baseline mIoU | U-Net mPA | U-Net mIoU |
|---|---|---|---|
| 0.9081 | 0.8471 | 0.9941 | 0.9854 |
Prediction visualization
Predictions of both models were observed more precisely on three images, No. 33, No. 158 and No. 209.
| 033 | 158 | 209 |
|---|---|---|
 |  |  |
The corresponding masks, as well as baseline and U-Net predictions, are shown in the following figures.
| 033 - mask | 033 - baseline | 033 - U-Net |
|---|---|---|
 |  |  |
| 158 - mask | 158 - baseline | 158 - U-Net |
|---|---|---|
 |  |  |
| 209 - mask | 209 - baseline | 209 - U-Net |
|---|---|---|
 |  |  |
The following figures color code model's output. Blue color corresponds to "false positive", i.e. the model predicted "liver" (white pixel) when there was "no liver" ; red color corresponds to "false negative", i.e. the model predicted "no liver" (black pixel) when there was "liver". This shows the high performance of the U-Net, especially compared to the baseline model. The baseline model predicts shapes that barely fit the ground-truth, while the U-Net has nearly no error.
| 033 - baseline | 033 - U-Net |
|---|---|
 |  |
| 158 - baseline | 158 - U-Net |
|---|---|
 |  |
| 209 - baseline | 209 - U-Net |
|---|---|
 |  |
Conclusion
The U-Net model performed particularly well on the data set provided, with the parameters set. It outperformed the simple CNN baseline model, ans highly proved its efficiency. However, one question is still pending, that is to know if the model would be able to generalize to other datasets as well. Therefore, further work is needed to evaluate U-Net model performance on new data. Nevertheless, the current results are promising and suggest that the model indeed learnt characteristics of liver tissue and could be used in future work on the topic.