This study is a deep learning-based system for Saudi Arabian license plate recognition, that uses a custom-trained Faster R-CNN model with ResNet50 backbone. The system detects and classifies multiple components of Saudi license plates, including Arabic numbers, Latin numbers, logos, and text across varied conditions.
License plate recognition systems are used in traffic management and security applications. Saudi Arabian license plates has unique challenges due to their dual-language format and distinctive design elements. In this research, we address these challenges through a specialized deep learning approach that recognizes both Arabic and Latin components.
Here, we create a custom licence plate recognition model using Pytorch. We’ll leverage a Deep Learning tool Torchvision to train our model using annotated images so it can recognize and annotate number plates. In this field of computer vision, we imagine a self-driving car, or real time car number plate recognition where we not only need to classify the objects but also identify where they are located. Hence, we’ll introduce the fundamental concepts of labeling the ground truth bounding-box of objects within an image using a tool named ybat, extracting region proposals using the selective search method, and defining the accuracy of bounding-box predictions by using the intersection over union (IoU) and mean average precision metrics. Consequently, we’ll use two neural networks – R-CNN and Fast R-CNN – and implement them on a custom dataset that contains images belonging to the number plates.
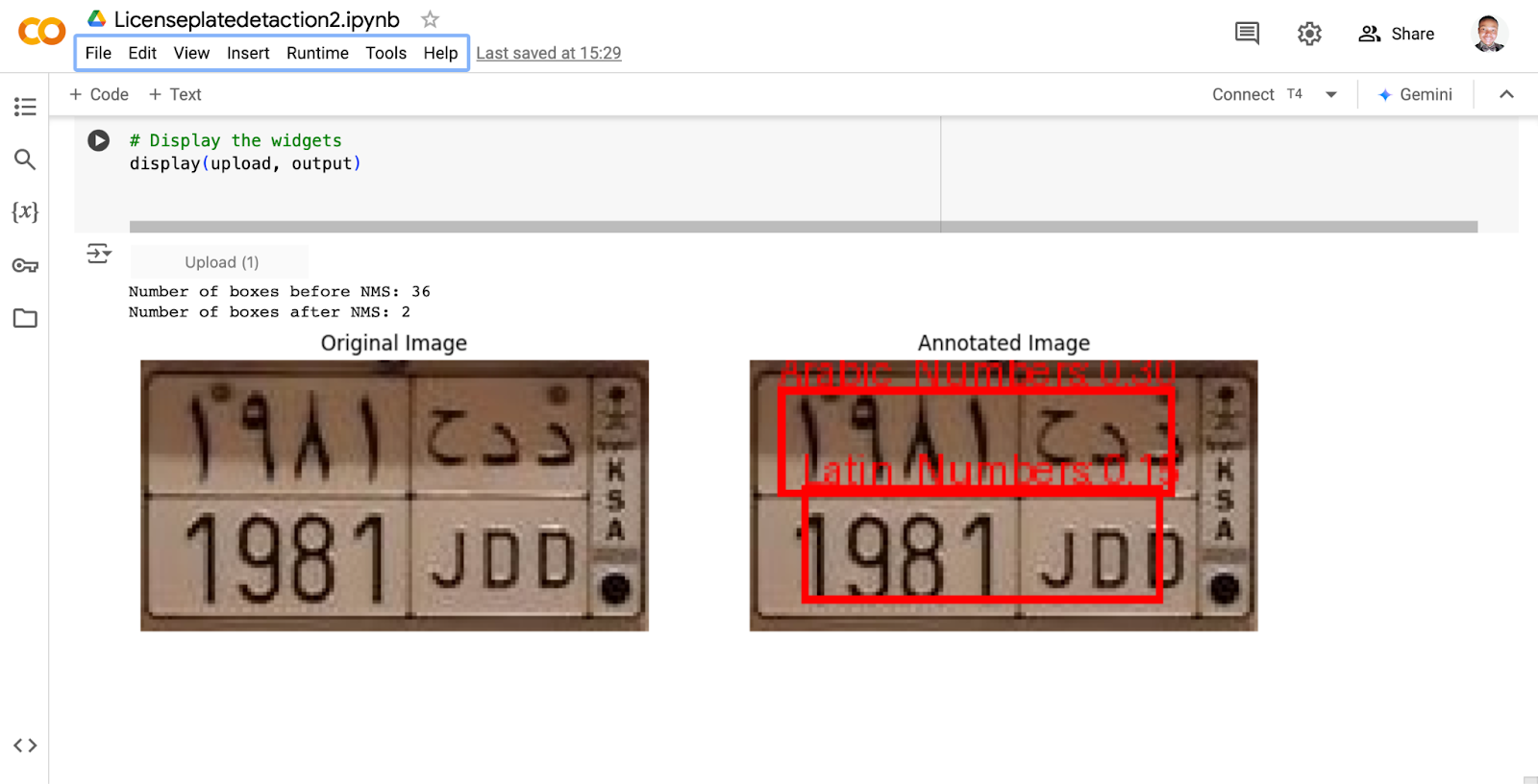
Figure 1. Licence plate recognition model in action
To achieve this, we will apply object localization techniques to draw bounding boxes around an image along with identifying the class of object within a bounding box across the multiple objects present in the image.
We'll use the ybat tool - YOLO BBox Annotation Tool, a Fast and efficient BBox annotation for images in YOLO, and VOC/COCO formats. This tool contains features such as:
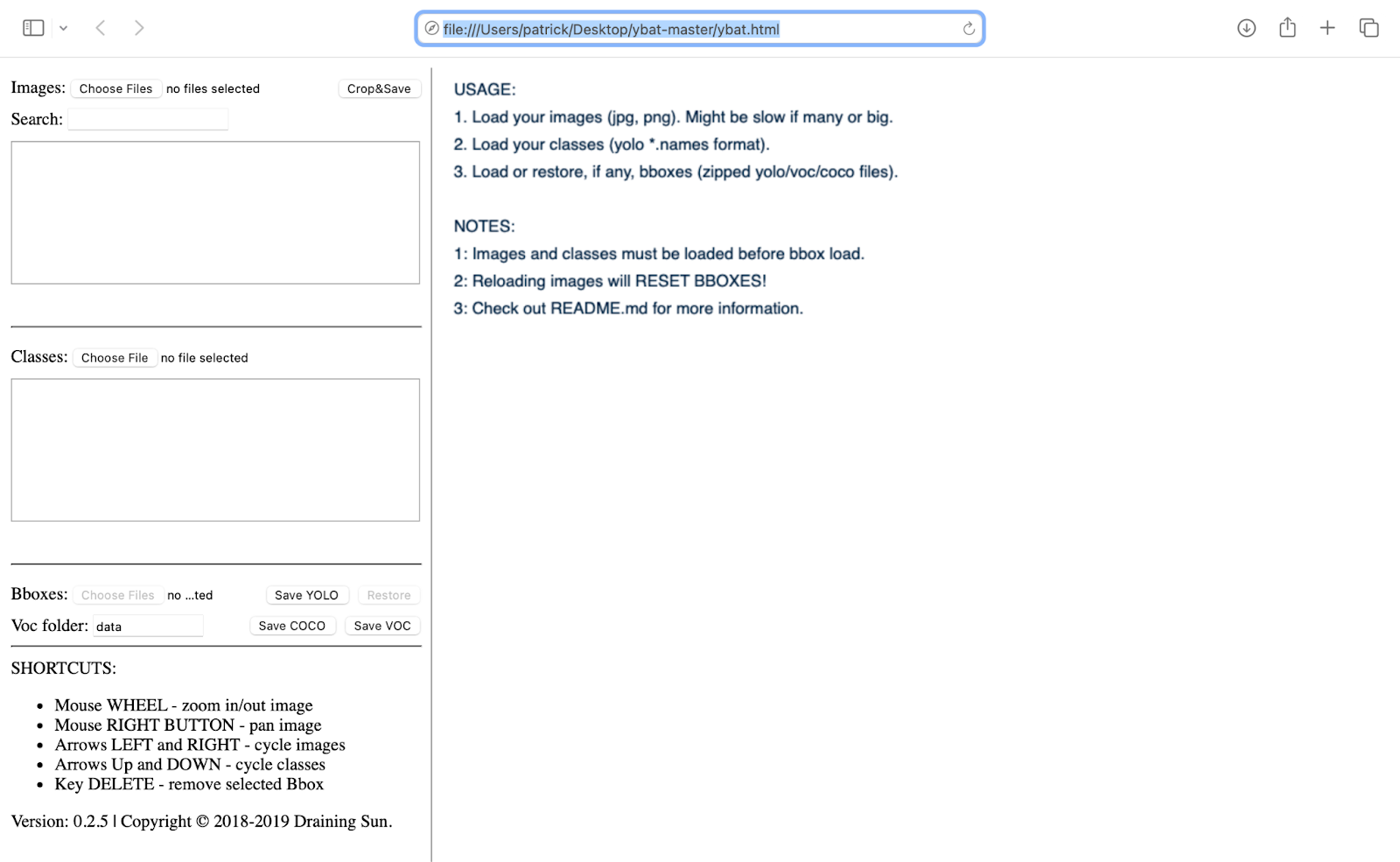
Figure 2. ybat tool open on a safari browser
The first step is localization which entails drawing a tight bounding box around the object in the image. After training, the Deep learning model will detect the class corresponding to multiple objects in the picture, along with a bounding box around each object, which is an object detection functionality. Therefore, to train a model that provides the bounding box, we need the image and the corresponding bounding-box coordinates of all the objects in the image. A simple way to create the training dataset is to use the image as the input and store the corresponding bounding boxes and classes of objects as an XML file output.
We begin by installing the ybat to create (annotate) bounding boxes around objects in the image. Let’s first specify the possible classes that we want to label across images and store in the classes.txt file, as follows:

Figure 3. classes.txt showing the class names of objects in our images
Now, let’s prepare the ground truth corresponding to an image. Here, we will draw a bounding box around our defined objects, i.e, Latin numbers, Arabic numbers, Logo, Latin text, Arabic text and assigning labels/classes to the objects present in the image, as seen in the following steps:
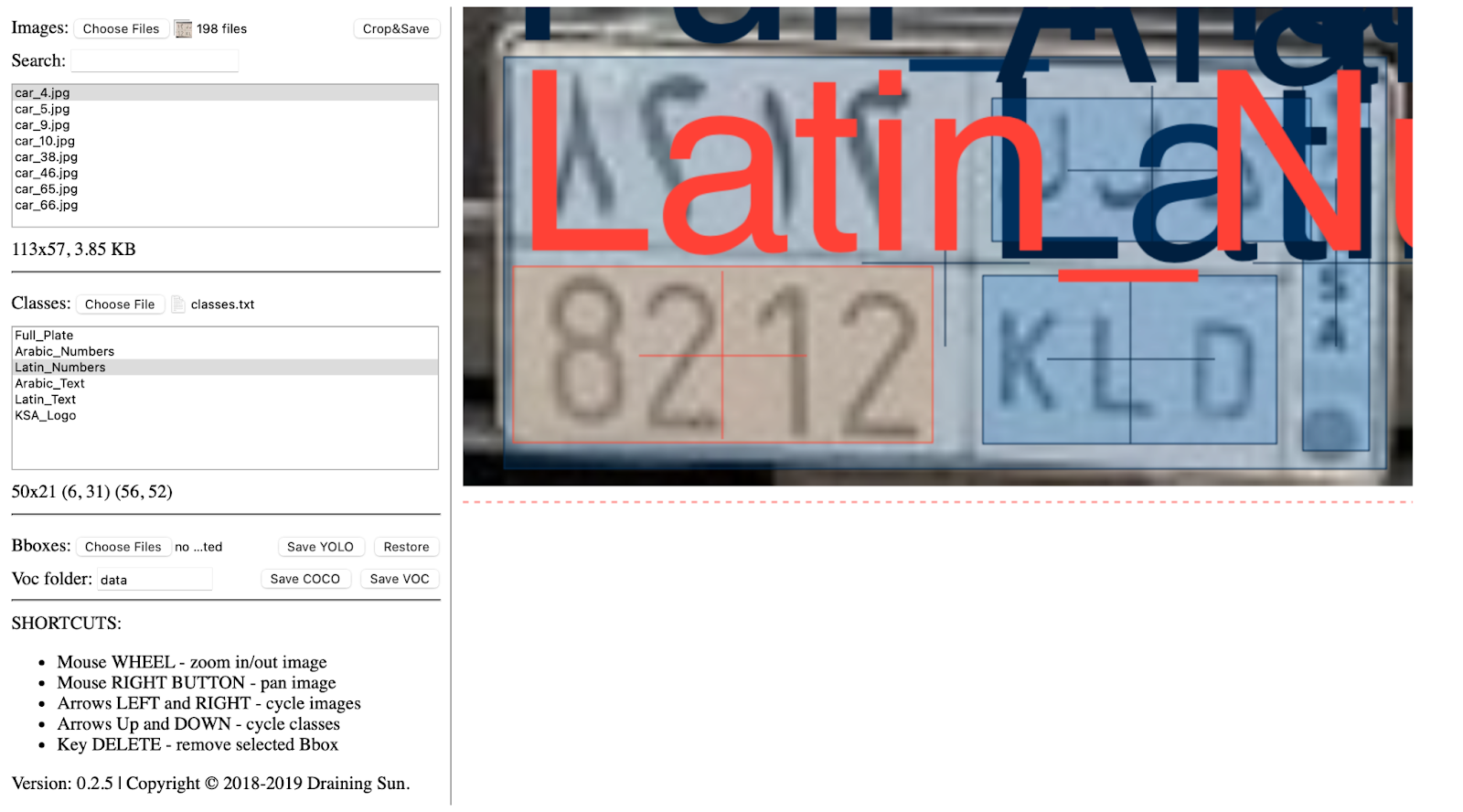
Figure 4: ybat tool annotations with the Latin_Numbers class selected
Save the data dump in the desired format - we will use the PascalVOC format, as it downloads a zip of XML files.
Figure 5: Annotated images data in xml format after we download the annotations in VOC format
Next, we will train a R-CNN-based custom object detector model. R-CNN stands for region-based convolutional neural network. Region-based within R-CNN refers to the region proposals used to identify objects within an image. Note that R-CNN assists in identifying both the objects present in the image and their location within it.
Defining and training the model
The model was trained for 20 epochs using SGD optimizer with learning rate 0.0001 and momentum 0.9. The experimental validation included:
Predicting on new images

Test prediction on an uploaded image:

The system has a great performance in identifying plate components:
After fine tuning the model, it has a considerably good accuracy in identifying plate components even
with the limited dataset as seen from the files attached.