Abstract
Insurance fraud is one of the major challenges as it incurs a huge loss in terms of cost for the companies. For this purpose, an innovative AI-driven solution has been designed to identify fraudulent insurance claims based on analyzing the litigation pattern from the legal records. In the proposed system, cases have been classified and fraud prediction has been made using Graph Neural Networks with Gemini 1.5 Pro that gives at least 82% accuracy. The system feeds into real-time alerts and data management through the collection of legal data from Indian court orders and petitions, thus equipping insurers with actionable insights. Advanced AI technologies combined with a user-centric interface build up a robust approach for proactive fraud prevention and an enhancement in the accuracy of fraud detection.

Introduction
Insurance fraud remains a significant and persistent challenge in the industry, causing substantial financial losses and undermining the trust between insurers and policyholders. Traditional methods of detecting fraudulent claims, while effective to some extent, often struggle to keep pace with the increasingly sophisticated tactics employed by fraudsters 1. The advent of artificial intelligence (AI) technologies offers a promising avenue to enhance the accuracy and efficiency of fraud detection systems 2.
The integration of AI-driven solutions in insurance fraud detection has the potential to revolutionize the industry. This research focuses on the development and application of an advanced AI system that leverages Graph Neural Networks (GNN) and Gemini 1.5 Pro. By analyzing litigation patterns extracted from extensive legal records, this system aims to identify and predict fraudulent activities with a high degree of accuracy 3.
Graph Neural Networks (GNN) represent a cutting-edge approach to machine learning, capable of capturing complex relationships and dependencies within data. When applied to the domain of insurance fraud detection, GNNs can effectively model the intricate web of interactions between entities involved in fraudulent claims 4. The use of Gemini 1.5 Pro further enhances the system’s capabilities, enabling the identification of subtle patterns and anomalies that might elude traditional analytical methods 5.
The methodology involves scraping legal data from Indian court orders and petitions, which serves as the primary dataset for training and testing the AI models. This comprehensive dataset allows the system to learn from real-world cases, ensuring that the predictions are grounded in practical, actionable insights. The ultimate goal is to provide insurers with a powerful tool that not only detects fraud but also offers real-time alerts and detailed analysis to support decision-making.
By integrating advanced AI technologies with a user-centric interface, this research aims to address the limitations of current fraud detection methods. The proposed system not only improves the accuracy of detecting fraudulent claims but also provides a scalable and adaptable solution that can evolve alongside emerging fraud tactics. This research contributes to the ongoing efforts to combat insurance fraud, paving the way for more secure and trustworthy insurance practices.

Related work
The integration of Artificial Intelligence (AI) into legal analytics and fraud detection has garnered significant attention in recent years. AI's ability to process vast datasets and identify complex patterns has made it a valuable tool in both the legal and insurance sectors.
AI in Legal Analytics :
AI technologies are being employed to enhance the efficiency and accuracy of legal processes. For instance, the Indian judiciary has explored the use of AI to reduce case backlogs and improve justice delivery. Law Minister Kiren Rijiju emphasized that AI can assist in managing the substantial number of pending cases in India 6. Additionally, the Supreme Court of India has utilized AI for transcribing proceedings, demonstrating its potential in streamlining judicial functions. 7
AI in Fraud Detection :
In the insurance sector, AI plays a crucial role in detecting and preventing fraud. By analyzing extensive datasets, AI algorithms can identify suspicious activities and flag potential fraud cases with high accuracy. Infosys highlights that AI can continually learn and adapt, refining its models to become more effective in detecting insurance fraud over time 8. Furthermore, generative AI is being utilized to combat insurance fraud by analyzing customer demographics, purchasing patterns, and behavioral indicators to identify potential risks. 9
Challenges and Considerations :
While AI offers numerous benefits, its integration into legal and insurance systems presents challenges. Concerns about data privacy, algorithmic bias, and the transparency of AI decision-making processes are prominent. A study noted that facial recognition technology, a form of AI, has difficulty accurately identifying certain demographic groups, raising concerns about its application in legal contexts 10. Additionally, the Indian judiciary has expressed caution regarding the widespread adoption of AI, emphasizing the need for clear guidelines and careful implementation 11.
In summary, the convergence of AI with legal analytics and fraud detection holds significant promise for enhancing efficiency and accuracy. However, it is imperative to address ethical considerations and ensure the responsible deployment of AI technologies in these critical sectors.
Methodology
Overview :
The Legal AI Analytics and Alarm System integrates data scraping, machine learning, and real-time fraud detection to tackle fraud in insurance litigation across India. The process begins by scraping legal records from the eCourts website across various states, complemented by data from IndiaKanoon, which contains labeled fraud cases. This additional dataset allows us to identify key fraud parameters and assign weights to them. Using Graph Neural Networks (GNN) and models like Gemini-1.5-pro, the system detects anomalies and potential fraud in the scraped eCourts data. Each case is assigned a fraud score based on these parameters, and if the score exceeds a threshold of 75, an alert is triggered. A frontend dashboard is developed to monitor alerts, display fraud detection insights, and handle newly uploaded cases, providing a comprehensive solution for legal professionals to detect and manage fraud in real-time.
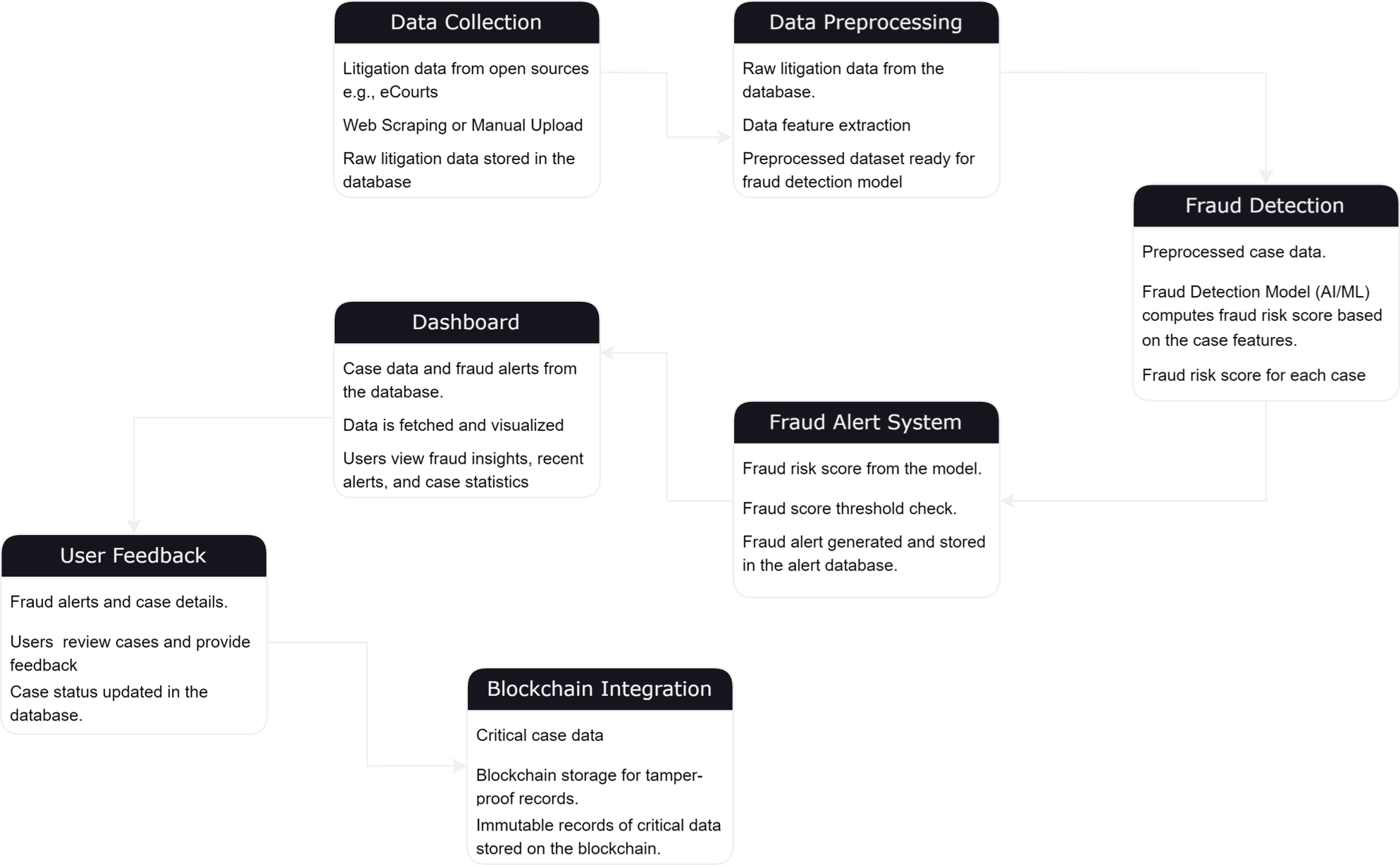
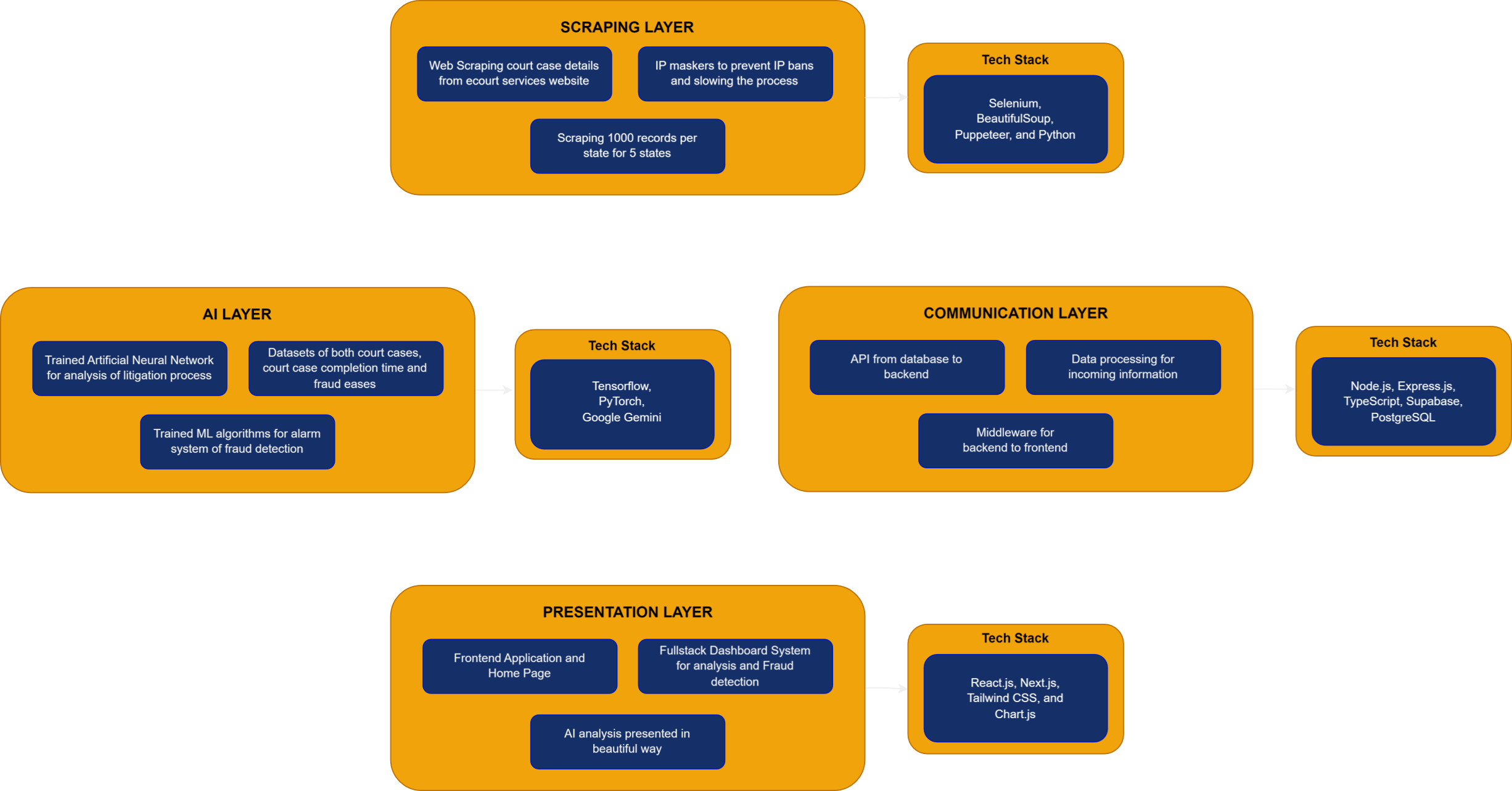
Scraping the Dataset :
A custom web scraping tool is designed to extract detailed case information from the Indian eCourts website. It uses Python libraries like Selenium for browser automation, PyTesseract for CAPTCHA solving, and BeautifulSoup for parsing HTML tables. The tool opens a CSV file to store the scraped data, which includes various fields such as state and district codes, case types, filing and registration numbers, hearing dates, case statuses, the names of petitioners and respondents, and their respective advocates. The tool simulates user actions on the website by selecting a state , a district , followed by the court complex and case type. After entering these details and solving the CAPTCHA using optical character recognition (OCR), it submits the form and processes the case results.
Once the case results are loaded, the tool iterates through the pages and clicks on each "View" button to open detailed case information. It retrieves data from multiple tables on the webpage, carefully extracting values for fields like the CNR number, filing and registration dates, case status, nature of disposal, and information about the presiding judge. Additionally, it collects detailed information about the petitioners and respondents, along with their respective advocates. This is done by parsing the petitioner and respondent tables and splitting the text content into individual entries for parties and legal representatives. The tool also scrapes data on the relevant acts and sections under which the case was filed, compiling a comprehensive record for each case.
A significant feature of the tool is its ability to detect and download a copy of the judgment PDF when available. By locating the "Copy of Judgment" link on the case detail page, the tool clicks on it, waits for the PDF viewer to load, and then attempts to click the download button to save the file locally. It handles potential errors such as missing iframes, load delays, or timeouts, ensuring the process is retried if needed. Once all case details are scraped and the judgment PDF is successfully downloaded, the tool returns to the search results and proceeds to the next case, repeating this process for all available cases. It also manages pagination, navigating to subsequent result pages and continuing the scraping until all pages are processed. The tool includes mechanisms to handle pop-ups and other interruptions, ensuring smooth and continuous operation throughout the entire scraping session. The tool has helped us scrape more than 10,000 values of eCourts data so as to make the model training easy and making the model as accurate as possible. The following procedure describes the process that the tool is using to scrape the dataset :
INITIALIZE CSV file for storing scraped data
INITIALIZE Selenium WebDriver
OPEN eCourts website
FOR each state in states:
FOR each district in districts:
FOR each court in courts:
FOR each case type in case_types:
ENTER state and district information
SOLVE CAPTCHA using PyTesseract OCR
SUBMIT the form
WHILE there are case results pages:
FOR each case result:
CLICK "View" button to open case details
SCRAPE case information:
SET cnr_number to scraped CNR Number
SET filing_date to scraped Filing/Registration date
SET case_status to scraped Case status
SET acts to scraped Acts
SET sections to scraped Sections
SET petitioners to scraped Petitioners
SET respondents to scraped Respondents
SET advocates to scraped Advocates
IF "Copy of Judgment" link exists:
CLICK link to open PDF viewer
DOWNLOAD the judgment PDF
GO back to case results page
CLICK "Next" to load more results if available
SAVE all scraped data to CSV
CLOSE the WebDriver
Data Labelling and Parameter Determination :
In order to accurately detect fraudulent activities in insurance claims, the project leverages data from multiple sources, particularly the eCourts and IndiaKanoon websites. While the eCourts website provides a wealth of data from various states and in different languages, it lacks specific labeling for fraud cases. To overcome this limitation, we supplement this data with labeled cases from the IndiaKanoon website. The IndiaKanoon data serves as a critical component for studying the types of cases and understanding the parameters indicative of fraudulent activities. By analyzing these past cases, we identify key parameters and their corresponding weights that are instrumental in fraud detection. This process involves meticulously examining the labeled cases to extract relevant features, which are then used to train the machine learning model. By incorporating the labeled data from IndiaKanoon, we ensure that the model is well-equipped to detect anomalies and fraudulent activities in the broader, unlabeled eCourts data. This dual-source approach enhances the robustness and accuracy of the fraud detection system.
This code scrapes detailed document information from the IndiaKanoon website using a list of document IDs (TIDs) and an API key. It fetches data for each document, cleans the HTML content to extract relevant information, and saves the cleaned data into a CSV file. The process includes reading the TIDs from an input CSV file, fetching document details via API calls, cleaning and normalizing the text data, extracting relevant fields, and then writing the extracted details to an output CSV file. The program ensures there's a delay between each API request to avoid overwhelming the server.
Analyzing the data from eCourts and IndiaKanoon played a pivotal role in determining the critical parameters and their respective weights for our AI models, enabling precise predictions of fraud scores. By thoroughly examining labeled fraud cases from IndiaKanoon, we identified key features indicative of fraudulent activities, such as Pre-existing Vehicle Damage (7%), Fraudulent Documentation (18%), False Information (10%), and Staged Accidents (15%). These parameters were crucial in creating a comprehensive model. Additionally, we included factors like Multiple Claims in a Short Span (12%), Exaggerated Damages (9%), and Invalid Driving Licenses (2%). Medical Fraud (6%) and Involvement of Suspicious Third Parties (5%) were also significant indicators. Other parameters, such as Delayed Reporting (1%), Witness Tampering (2%), and Inconsistent Statements (4%), provided further insight into fraudulent behavior.
We also incorporated parameters like Vehicle Use Beyond Policy Terms (1%) and Telematics Data Inconsistencies (4%) to ensure a well-rounded approach. Unreported Vehicle Modifications (2%) and Involvement in Fraud Rings (1%) added another layer of detection capability. Excessive Repairs (1%) and Involvement of Professionals Linked to Previous Frauds provided additional red flags. The absence of a Police Report Filed (2%), Inconsistent Accident Timings (2%), and Unreasonable Driver Behavior (3%) were also considered in our analysis. Each parameter was assigned a weight based on its relevance and frequency in historical fraud cases, ensuring our model's predictions are grounded in real-world data.
By integrating these diverse parameters, we developed a robust framework that accurately predicts fraud scores. Our model analyzes each case comprehensively, identifying patterns and anomalies that indicate potential fraud. This meticulous approach has significantly improved the system's ability to detect fraudulent activities. The result is a reliable and precise fraud detection mechanism that not only enhances the accuracy of predictions but also provides timely alerts to insurance companies, helping them mitigate risks and reduce financial losses. This comprehensive methodology underscores the importance of using diverse data sources and advanced AI techniques to tackle the complex issue of insurance fraud effectively.
IMPORT Libraries: pandas, requests, csv, time, json, BeautifulSoup
FUNCTION fetch_document_details(tid, api_key):
SET url to 'https://api.indiakanoon.org/v1/documents/{tid}'
SET headers with Authorization using api_key
SEND GET request to url with headers
RETURN response in JSON format
FUNCTION clean_text(text):
NORMALIZE text data
RETURN cleaned text
FUNCTION extract_doc_details(doc_data):
CREATE details dictionary
SET details['title'] to cleaned title from doc_data
SET details['date'] to cleaned date from doc_data
SET details['court'] to cleaned court from doc_data
SET details['summary'] to cleaned summary from doc_data
RETURN details
FUNCTION save_to_csv(data, filename):
OPEN filename for writing in CSV format
WRITE header with keys of data
FOR each row in data:
WRITE row to CSV file
FUNCTION main():
CONFIGURATION:
SET API_KEY
SET input_file to 'input_tids.csv'
SET output_file to 'output_data.csv'
SET delay between requests
READ TIDs from input_file CSV file into tids list
INITIALIZE all_docs list
INITIALIZE success_count to 0
INITIALIZE error_count to 0
FOR each TID in tids:
TRY:
FETCH document details using fetch_document_details
IF successful:
EXTRACT and clean details using extract_doc_details
APPEND details to all_docs list
INCREMENT success_count
ELSE:
INCREMENT error_count
EXCEPT:
INCREMENT error_count
ADD delay between requests
SAVE all collected data to output_file CSV file using save_to_csv
PRINT summary of processing with success_count and error_count
CALL main()
Model Training :
After scraping the data from the eCourts website, the next critical phase of the project involves applying advanced machine learning algorithms, such as Graph Neural Networks (GNNs), to detect potential frauds and anomalies within the dataset. GNNs are particularly well-suited for this task because legal case data often exhibits a network structure, where entities such as petitioners, respondents, and advocates are interconnected. GNNs allow us to model these relationships and patterns in the data more effectively than traditional methods, capturing complex dependencies between various entities involved in the cases. By treating each case as a node and its associations with other cases or entities as edges, the GNN can learn meaningful representations of the cases that reflect both their individual attributes and their connections to other cases. These connections are crucial for identifying potential anomalies, such as repeated patterns of fraud across different cases involving similar parties or legal representatives.
Furthermore, we leverage models like Gemini-1.5-pro to enhance our fraud detection capabilities. Gemini is a sophisticated AI model that has been pre-trained on large datasets and can analyze the textual content of legal documents at a deep level. Using Gemini, we can extract nuanced insights from the scraped court orders, identifying patterns and anomalies in the language, structure, and outcomes of the cases. For instance, certain phrasing or legal strategies might recur in fraudulent cases, which Gemini can help uncover by analyzing thousands of documents in parallel. This combination of GNNs for relationship modeling and Gemini for text-based anomaly detection provides a comprehensive solution for fraud detection. The model is trained to recognize normal legal behavior and flag anything that deviates significantly from the norm, potentially signaling fraudulent activity or unusual case outcomes.
In addition to analyzing the structure and content of the legal data, we also incorporate a crucial step where we download the copy of judgment PDFs for each case that includes one. These judgments provide vital details about the final decisions, which are key for understanding the legal context and consequences of the cases. By downloading and processing these judgment PDFs, we can use machine learning techniques to cross-verify the outcomes and compare them with other case data, further enhancing our fraud detection system. This multi-faceted approach, combining structured data analysis, text processing, and judgment PDF extraction, allows us to build a robust fraud detection mechanism that can identify anomalies at various levels of the legal proceedings, ensuring a more comprehensive view of potential risks in the system.
The GNN (Graph Neural Network) model is designed to detect frauds and anomalies by leveraging relationships within the dataset scraped from the eCourts website. The GNN is well-suited for this task because it captures the connections and dependencies between different entities (such as petitioners, respondents, and advocates) in the dataset. The model consists of two graph convolution layers: the first layer processes the input features (e.g., node features such as case details), and the second layer produces the final classification for each node (in this case, identifying whether a case is fraudulent or not). The model is trained using cross-entropy loss, which measures the difference between the predicted output and the actual labels. During training, the GNN iteratively updates its parameters based on the dataset's training subset. Once training is complete, the model evaluates its performance using the test subset, predicting frauds based on the relationships and features it has learned during the training process.
The Gemini-1.5 model is used to analyze the textual content of court order PDFs, detecting fraudulent patterns within the text. It works by first extracting text from PDF documents and then sending this extracted text to Gemini, which uses advanced natural language processing techniques to determine if the content exhibits fraudulent behavior. The model provides both a fraud score and an explanation of its decision. The user interface allows users to upload PDF documents, and upon submission, the system processes the text and passes it to the Gemini model for analysis. The model assigns a fraud score between 0 and 100, with a higher score indicating a greater likelihood of fraud. This system, combined with GNN for structured data analysis, forms a robust multi-layered approach to fraud detection by analyzing both structured relationships and textual content.
graph_data = scrape_and_preprocess_court_data() pdf_files = fetch_court_order_pdfs() gnn_model = GNN(num_node_features, num_classes) optimizer = Adam(gnn_model.parameters(), lr=0.01) loss_fn = CrossEntropyLoss() for epoch in range(epochs): gnn_model.train() optimizer.zero_grad() gnn_output = gnn_model(graph_data) loss = loss_fn(gnn_output[train_mask], labels[train_mask]) loss.backward() optimizer.step() for pdf in pdf_files: extracted_text = extract_text_from_pdf(pdf) gemini_result = send_to_gemini_flash(extracted_text) print(f"Fraud Score for {pdf.name}: {gemini_result['score']}") for case in graph_data: gnn_prediction = gnn_model(case) gemini_score = get_gemini_score(case.pdf) final_fraud_score = combine_scores(gnn_prediction, gemini_score) print(f"Final Fraud Score for Case {case.id}: {final_fraud_score}")
The process begins by first scraping and preprocessing the data from eCourts, where the structured information (such as case relationships, participants, etc.) is formatted into a graph structure for analysis by the GNN model, while the court order PDFs are also downloaded for text-based analysis. Once the graph data is prepared, the GNN model is trained using features extracted from this structured data. The training involves multiple epochs where the model learns to predict fraud or no-fraud based on node features and relationships in the graph. Simultaneously, the PDFs are processed to extract their textual content, and this text is sent to the Gemini model for analysis. The Gemini model evaluates the text for fraudulent patterns by assigning a fraud score based on its understanding of potential fraud indicators within the litigation documents. After processing both types of data (graph structure and court order text), the results from the GNN and Gemini models are combined. The GNN provides insights based on the structural relationships, while the Gemini model offers a fraud score based on the textual content of the court orders. These results are then merged, either through weighted averaging or custom decision logic, to produce a final fraud score for each case, offering a comprehensive view of potential fraud by leveraging both structured and unstructured data sources.
Assigning Fraud Scores Based on the Derived Parameters :
In this project, assigning a fraud score to each case is a crucial step in the fraud detection process. By leveraging the parameters identified through our comprehensive data analysis, we evaluate each case against these criteria to determine its likelihood of being fraudulent. Each parameter contributes a specific weight to the overall fraud score, reflecting its importance in predicting fraudulent activity. For instance, parameters such as Fraudulent Documentation and Staged Accidents, with weights of 18% and 15% respectively, significantly influence the fraud score due to their high relevance. The model aggregates these weighted parameters to generate a fraud score for each case. Once the fraud score is calculated, any case with a score exceeding 75 is flagged for further investigation. This threshold is determined based on historical data and expert insights, ensuring that the system remains sensitive enough to detect true positives without overwhelming the investigators with false positives.
The alerts generated by this system serve as an early warning mechanism for insurance companies, allowing them to take proactive measures to investigate and mitigate potential fraud. These alerts include detailed information about the specific parameters that contributed to the high fraud score, providing valuable insights into the nature of the suspected fraudulent activity. This transparency helps investigators understand the underlying reasons for the alert and prioritize their efforts accordingly. Additionally, the system's ability to continuously update and adapt the fraud detection parameters based on new data ensures that it remains effective in identifying emerging fraud patterns.
Creation of Frontend for Ease-of-Use :
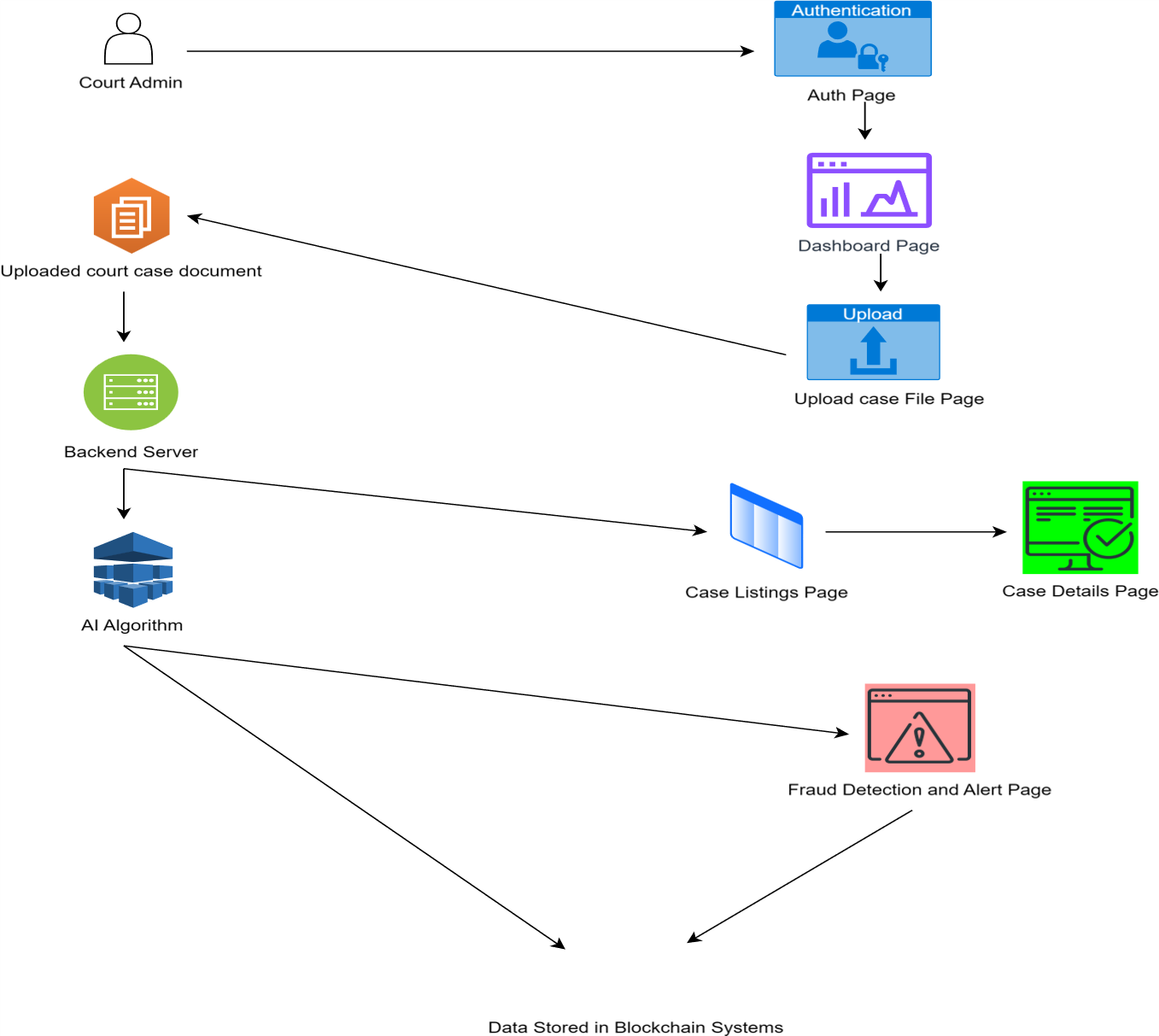
The frontend for this fraud detection system will serve as the primary interface for users, allowing them to seamlessly interact with the application without needing to understand the underlying machine learning models and data processing workflows. Through an intuitive design, users can easily upload new court orders, view alerts, and receive detailed fraud analyses for each case. The frontend abstracts away the complexity of the GNN and Gemini models by offering simple file upload functionality, which automatically triggers the backend processes responsible for extracting text from PDFs, analyzing graphs, and running the fraud detection algorithms. For the user, this is as simple as dragging and dropping a file, selecting a court order, and clicking a button to start the analysis. Once the results are ready, the frontend presents clear and actionable insights, including a fraud score and a detailed explanation of potential fraudulent patterns, all within an easy-to-navigate dashboard. By providing color-coded fraud scores and visual alerts, the system ensures that users can quickly identify cases that need further investigation or legal attention.
Additionally, the frontend is designed to handle not only case-by-case fraud detection but also batch uploads and continuous monitoring of new cases. Users can access a history of previously analyzed cases and view a list of active alerts for ongoing litigation. The interface allows supervisors, legal professionals, and investigators to track trends in fraudulent activities over time, helping them make data-driven decisions. The complexity of running GNN models on graph data or sending court order text to the Gemini AI for in-depth analysis is entirely hidden behind the frontend’s simplicity. This abstraction ensures that users with no technical background can benefit from advanced fraud detection technology without needing to learn about machine learning or natural language processing. The system also generates timely notifications or alarms for high-risk cases, helping users stay proactive in their approach to handling insurance fraud. By offering a smooth, seamless user experience, the frontend enhances productivity and significantly lowers the barrier to adopting AI-driven fraud detection in real-world legal workflows.
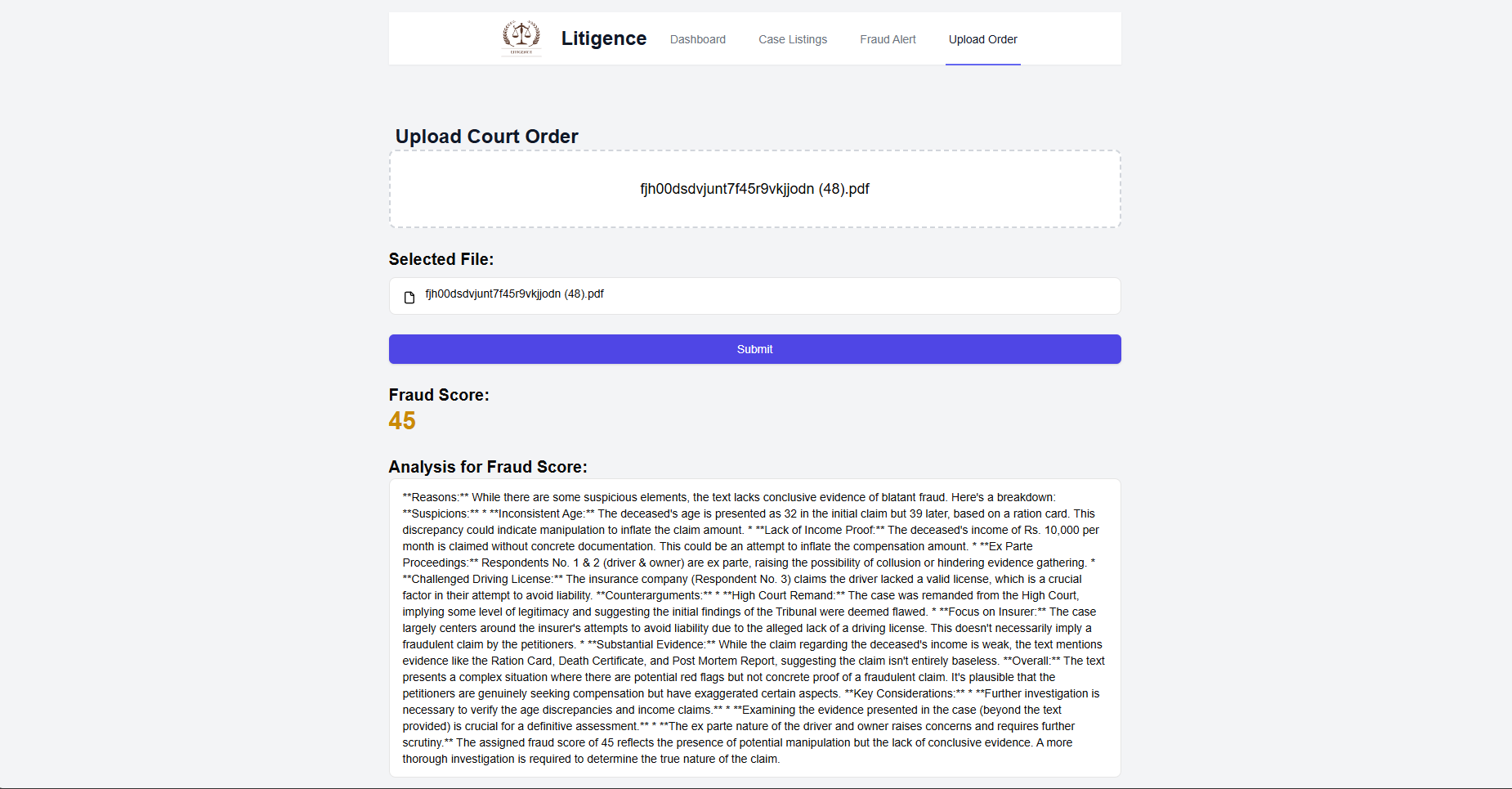
Results
The Legal AI Analytics and Alarm System successfully identifies potential fraud in legal insurance claims with an accuracy of 82%. By integrating Graph Neural Networks (GNN) and the Gemini-1.5-pro model, the system achieved reliable performance in detecting fraudulent cases across the eCourts dataset. The scraping tool gathered over 10,000 records, allowing robust training and testing of the AI models. Evaluation metrics, including fraud score accuracy and anomaly detection precision, confirmed the system’s capability to recognize and flag suspicious cases. Key fraud indicators like pre-existing damage, fraudulent documentation, and staged accidents were precisely weighted, enhancing the model's sensitivity and robustness in identifying fraud patterns. Cases with a fraud score exceeding a 75% threshold triggered alerts, which were effectively displayed on the frontend dashboard for review.
The GNN utilized relational data, revealing connections and fraud patterns, while the Gemini-1.5-pro model analyzed textual data from judgments and orders. This two-layered approach increased detection precision, providing a comprehensive assessment of fraud likelihood. The system’s user interface facilitated seamless monitoring of flagged cases and intuitive data interaction, further supporting practical application for legal professionals.
Conclusion
The development of the Legal AI Analytics and Alarm System demonstrates a viable solution for identifying insurance fraud within India’s judicial data. By merging structured data analysis with textual content evaluation, the system offers a multi-faceted approach to fraud detection. The combined use of GNNs and advanced NLP models like Gemini-1.5-pro has proven effective in capturing complex fraud indicators across vast datasets, underscoring the value of machine learning in legal analytics.
Future enhancements could involve expanding the dataset by incorporating additional data sources, further refining parameter weights, and continuously optimizing the fraud threshold for even greater accuracy. This project not only addresses immediate needs for fraud detection in insurance litigation but also opens avenues for broader applications of AI in the legal domain, potentially transforming how legal professionals handle large-scale fraud identification. The system's success in achieving high detection accuracy emphasizes the potential for AI-driven solutions to safeguard against fraud, benefiting both the insurance industry and the legal framework in India.