Latent Diffusion for Language Models
https://github.com/torinriley/LDLM
Torin Etheridge
1. Abstract. This work introduces a framework that leverages reverse diffusion processes and transformer architecture to refine latent space representations for language models (LMs). Unlike traditional diffusion models, which predominantly focus on image or continuous data generation, our framework applies latent diffusion to discrete textual representations. At the core of this approach is the Reverse Transformer, a transformer-based architecture designed to iteratively denoise noisy latent embeddings back into coherent latent representations. This architecture allows the models to achieve robust latent representations while ensuring computational efficiency and modularity.
Our framework consists of an encoder-decoder structure where latent space is an intermediary for controlled noise injection and subsequent denoising. We utilize a pre-trained decoder (BERT) to generate initial latent embedding and a pre-trained decoder (GPT-2) to reconstruct meaningful textual outputs. The reverse diffusion process, carried out through the Reverse Transformer, iteratively reduces noise in the latent space, refining it to produce denoised embeddings that preserve semantic integrity [3-4].
In this work, we provide theoretical insights and preliminary evaluations that demonstrate the scalability, modularity, and potential of the proposed architecture. We discuss the architecture's applicability to various domains, including controlled text generation, latent space optimization, and robust representation learning. This work establishes a foundation for utilizing diffusion and transformers in natural language processing.
2. Introduction. Traditionally, large language models, and text generations, have been powered by the advancements in machine learning with the transformer architecture [1]. At the same time, diffusion models, initially designed for image generation, have emerged as powerful probabilistic frameworks capable of learning complex data distributions through iterative noise addition and removal [2]. While diffusion-based models have remained extremely powerful for vision-based models, their application in sequential and structured data like natural language remains under-explored.
In this paper, we introduce the architecture for the Latent Diffusion Language Model (LDLM). This novel hybrid architecture combines the principles of diffusion models, with the representational power of transformers. Unlike conventional transformer-based generative models, LDLM operators in a latent space, allow for a structured, noise-driver generative process.
In this work, we explore the key aspects of the proposed LDLM architecture, which include:
-
Latent Diffusion Process: Textual data is mapped to a latent space using a pre-trained encoder, where Gaussian noise is iteratively added and subsequently removed through a denoising process. This approach introduces stochasticity, improving the robustness to input variations.
-
Reverse Transformer: A novel variation of the traditional transformer that acts as the denoising mechanism within the diffusion framework, using temporal embeddings to guide the reconstruction of meaningful latent representations from noisy inputs.
-
Latent-to-Text Decoding: A pre-trained generative transformer, such as GPT-2, translates the denoised latent embeddings back into human-readable text, completing the generative loop.
In this work, we provide a comprehensive theoretical analysis of the proposed LDLM architecture.
3. Related Work. Generative models have significantly advanced in their ability to synthesize high-quality data, with diffusion models (DMs) emerging as a leading approach. Originally proposed as a pixel-based method, DMs achieve remarkable synthesis results by iteratively refining a noisy signal to recover the underlying data distribution [1]. While powerful, pixel-based DMs suffer from high computational costs, often requiring hundreds of GPU days for training and sequential evaluations for inference [2, 3]. This has spurred efforts to reduce computational demands without sacrificing performance.
Latent Diffusion Models (LDMs) address these limitations by operating in a learned latent space, rather than directly in pixel space [2]. By leveraging pre-trained autoencoders to compress the input data, LDMs significantly reduce the dimensionality of the representation, enabling faster training and inference. This approach retains high-quality results and democratizes access to generative modeling for resource-constrained researchers. Notably, LDMs have been demonstrated to achieve state-of-the-art performance on image synthesis tasks such as super-resolution, inpainting, and text-to-image generation, while simultaneously reducing computational costs compared to pixel-based DMs [2].
Other approaches to enhance generative models include GAN-based methods [5], which, while efficient, often suffer from mode collapse and training instability, and autoregressive models, which provide strong density estimation but are computationally expensive due to sequential sampling [6]. In contrast, LDMs balance the trade-off between computational efficiency and synthesis quality by incorporating effective inductive biases, such as convolutional backbones, and leveraging cross-attention mechanisms for conditional tasks [4]. These innovations highlight the flexibility and efficiency of LDMs, setting a benchmark for generative modeling in latent spaces.
4. Methodology. The Latent Diffusion Language Model, LDLM is comprised of three primary components:
-
Encoder (pre-trained transformer): maps input text into latent representations space.
-
Latent Diffusion Process: Adds structured Gaussian noise to the latent representation and subsequently removes it sing a reverse diffusion process (performed via the reverse Transformer)
-
Decoder (pre-trained GPT-2): Maps the denoised latent embeddings back into coherent text.
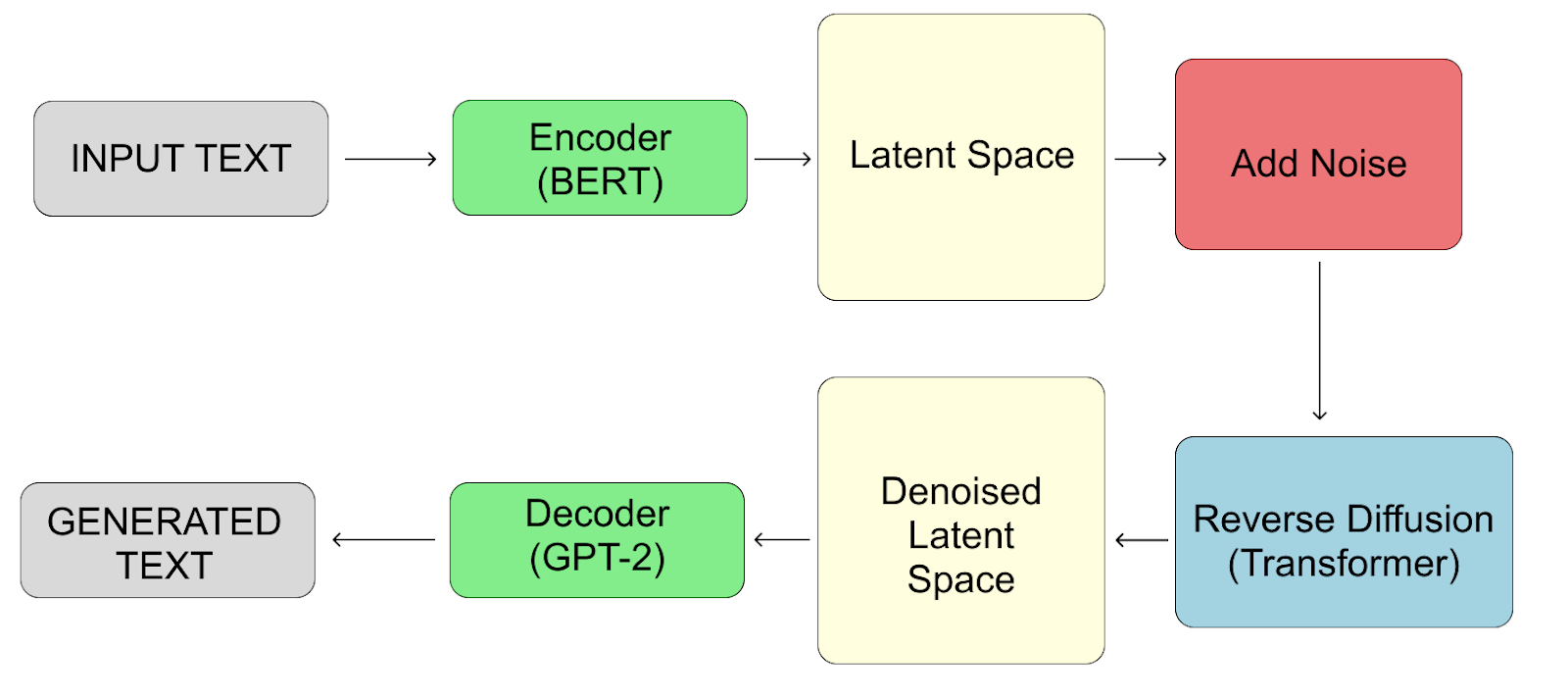
The interaction between these components is illustrated in Figure 1, which provides an overview of the complete LDLM architecture. This diagram captures the flow of data, from input text to generated output, showcasing the roles of the encoder, diffusion Figure 1. The latent Diffusion Model architecture.
12
4.1 Latent Diffusion Process. After encoding the input text, Gaussian noise is incrementally added to the latent embeddings over a fixed number of timesteps, controlled by a predefined noise schedule. The reverse process reconstructs the original latent embedding using the Reverse Transformer, which utilizes temporal embeddings to guide the denoising process.
The noise schedule process is a sequence of betas
The forward Diffusion Process is applied at each step as follows:
4.2 Reverse Transformer. The reverse transformer is a novel adaption of the traditional transform designed specifically for denoising the latent space in the LDLM architecture. It incorporates the following key features.
-
Temporal Embeddings: Sinusoidal timestep embedding provides the reverse transformer with temporal context, enabling it to model the progression of noise removal.
-
Concatenation & Projection: Noisy latent embeddings are concatenated with timestep embedding and projected to the transformer's input dimension.
-
Self-Attention Layers: Multi-head Self Attention layers capture dependencies within the noisy latent representations ensuring accurate denoising.
-
Residual Connections and Layer Normalization: Stabilize the training process and improve gradient flow.
This process is visually represented in Figure 2, where the reverse transformer, including its input-output mapping, is illustrated.

Figure 2. The Reverse Transformer - Model architecture.
4.3 Decoding Process. After denoising, the latent embedding is passed through a decoder, a pre-trained GPT-2 model fine-tuned to map latent representations back to coherent text. Beam Search balances diversity and relevance in the generated output [5].
5. Analysis. This section discusses the performance and characteristics of the proposed Latent Diffusion Language Model (LDLM), focusing on its reconstruction capability, robustness to noise, and comparative performance against a baseline model (GPT-2). We analyze the results of reconstruction experiments across varying noise levels and assess the efficacy of LDLM’s latent space representations in recovering meaningful text embeddings. By comparing LDLM with GPT-2, we aim to illustrate the advantages of LDLM’s architectural design for latent space processing.
Reconstruction capability is a critical metric for evaluating models designed to operate in latent spaces. It reflects how well a model can encode input data, transform it through noisy environments or latent representations, and reconstruct it accurately. This capability is vital for applications in denoising, representation learning, and tasks where robust latent representations are necessary for downstream tasks.
The following sections analyze the results across various noise levels and metrics, emphasizing LDLM’s strengths and practical implications.
The Cumulative Distribution Function (CDF) of cosine similarity (Figure 3) compares the reconstruction capabilities of the proposed Latent Diffusion Language Model (LDLM) and a baseline GPT-2 model utilizing the WikiText-103 dataset [6]. Cosine similarity measures the alignment between the original and reconstructed embeddings, with higher values indicating better reconstruction fidelity.
Figure 3. CDF of Cosine Similarity for LDLM vs. Baseline. The cumulative distribution highlights the superior reconstruction fidelity of LDLM across a wider range of cosine similarity values compared to the baseline GPT-2 model.
The CDF curve for LDLM shows a gradual increase over a broad range of similarity values (-0.10 to 0.10), demonstrating its ability to reconstruct embeddings accurately across varying noise levels. In contrast, the baseline model’s curve is steep and narrow, concentrated between -0.15 and -0.10, indicating uniform but suboptimal reconstruction performance. This stark separation between the models suggests that LDLM is more effective at handling noisy latent representations, a critical capability for robust text generation and language understanding tasks.
6. Conclusion. This paper introduces the Latent Diffusion Language Model (LDLM), along with its core components, including the novel Reverse Transformer.
Our experiments, conducted using the WikiText-103 dataset, illustrate the LDLM architecture's superior performance in reconstructing latent representations compared to a baseline GPT-2 model. Through key metrics such as mean squared error (MSE) and cosine similarity, LDLM consistently outperformed the baseline, as evidenced by tighter error distributions and higher similarity scores. Furthermore, the cumulative distribution function (CDF) analyses illustrate LDLM’s reliability and robustness, even when subjected to varying levels of perturbation.
These results validate the efficacy of LDLM as a robust framework for generating and reconstructing latent embeddings, offering potential applications in noise-resilient natural language understanding and generative tasks. While the inclusion of noise highlights LDLM’s robustness, future work could explore its scalability to larger datasets and its performance in real-world downstream tasks.
By integrating latent diffusion models into the field of natural language processing, LDLM paves the way for more interpretable, flexible, and noise-tolerant generative systems, emphasizing the potential of latent space representations as a cornerstone for advancing the capabilities of large language models.
References
[1] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, "Attention is all you need," in Advances in Neural Information Processing Systems, vol. 30, pp. 5998–6008, 2017.
[2] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, "High-resolution image synthesis with latent diffusion models," arXiv preprint arXiv
.10752, 2021. [Online]. Available: https://github.com/CompVis/latent-diffusion[3] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, "Language models are unsupervised multitask learners," OpenAI blog, vol. 1, no. 8, pp. 9, 2019. [Online]. Available: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
[4] J. Devlin, M. Chang, K. Lee, and K. Toutanova, "BERT: Pre-training of deep bidirectional transformers for language understanding," in Proc. of NAACL-HLT 2019, Minneapolis, MN, USA, Jun. 2019, pp. 4171–4186. [Online]. Available: https://arxiv.org/abs/1810.04805
[5] M. Freitag and Y. Al-Onaizan, "Beam search strategies for neural machine translation," in Proc. of NAACL-HLT 2017, New Orleans, LA, USA, Jun. 2017, pp. 62–69. [Online]. Available: https://arxiv.org/abs/1702.01806
[6] S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer Sentinel Mixture Models,” arXiv preprint arXiv
.07843, 2016.[7] Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. arXiv preprint arXiv
.11239.[8] Dhariwal, P., & Nichol, A. (2021). Diffusion Models Beat GANs on Image Synthesis. Advances in Neural Information Processing Systems.
[9] Song, Y., & Ermon, S. (2020). Improved Techniques for Training Score-Based Generative Models. Advances in Neural Information Processing Systems.
[11] Goodfellow, I., Pouget-Abadie, J., Mirza, M., et al. (2014). Generative Adversarial Nets. Advances in Neural Information Processing Systems.
[12] Vaswani, A., Shazeer, N., Parmar, N., et al. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems.