Behind every Google search, LinkedIn connection, or Amazon recommendation lies a powerful concept: the knowledge graph. At its core, a knowledge graph represents information as interconnected entities and relationships, mirroring how humans naturally think about and connect information. While traditional databases store data in rigid tables and rows, knowledge graphs create a rich network of relationships that can capture complex real-world connections.
Neo4j, as the leading graph database platform, has revolutionized how organizations implement and utilize knowledge graphs. From fraud detection in financial services to recommendation engines in retail, and even enhancing AI systems through integration with Large Language Models, Neo4j provides the foundation for building sophisticated graph-based solutions.
Think of a knowledge graph as a digital mirror of relationships in the real world. In a movie database, for instance, rather than having separate tables for films, actors, and directors, a knowledge graph directly connects these entities: Christopher Nolan is connected to "Inception," which is connected to Leonardo DiCaprio, which in turn connects to other films, directors, and co-stars. This web of connections enables powerful queries that would be complex or impossible with traditional databases.
The applications of knowledge graphs span across industries and use cases. Social networks use them to understand user connections and suggest new relationships. E-commerce platforms leverage them to provide personalized product recommendations. Healthcare organizations employ them to understand drug interactions and patient relationships. More recently, they've emerged as valuable tools for grounding Large Language Models in factual knowledge, reducing hallucinations and improving response accuracy.
This article provides a comprehensive introduction to knowledge graphs using Neo4j. We'll explore the fundamental concepts, learn how to model and query graph data, and examine practical applications across different domains. Whether you're a developer, data scientist, or business analyst, understanding knowledge graphs is becoming increasingly crucial in today's interconnected data landscape.
The main objective of this article is to provide a comprehensive introduction to knowledge graphs and demonstrate their practical application using Neo4j through a citation network analysis.
Specific objectives include:
To follow along with this article, you'll need:
Technical Requirements
Dataset
We'll be using the Citations dataset available in Neo4j, which can be loaded directly through Neo4j Desktop. No additional data preparation is required.
Note: All examples use Cypher, Neo4j's query language. While SQL experience is helpful, we'll explain all concepts from the ground up.
knowledge graph is a structured representation of data that emphasizes relationships between entities, much like how we naturally connect information in our minds. Unlike traditional relational databases that store data in tables, knowledge graphs use a more flexible and intuitive structure built on two fundamental concepts: nodes (entities) and relationships (edges).
Consider how we might represent information about movies. In a knowledge graph:
Nodes represent entities like movies, actors, directors, and genres
Relationships show how these entities connect: actors "ACTED_IN" movies, directors "DIRECTED" films, movies are "IN_GENRE" categories
Properties on both nodes and relationships enrich the information: movies have release dates and ratings, actors have birthdates, and acting relationships might have role names
For example:
Tom Hanks (node) →[ACTED_IN]→ Forrest Gump (node)
Forrest Gump (node) →[IN_GENRE]→ Drama (node)
Robert Zemeckis (node) →[DIRECTED]→ Forrest Gump (node)
This example knowledge graph illustrates several key concepts:
%%{init: {'theme':'default', 'themeVariables': { 'fontSize': '16px'}, "flowchart" : { "nodeSpacing" : 50, "rankSpacing" : 400 }} }%% %% CSS styling for arrows %%{init: { 'theme': 'default', 'themeVariables': { 'edgeLabelBackground':'#ffffff', 'lineColor': '#148011' } }}%% graph LR linkStyle default stroke:#148011,stroke-width:2px %% Movies Matrix[("The Matrix (Movie) 1999")] Speed[("Speed (Movie) 1994")] Point[("Point Break (Movie) 1991")] %% Actors Keanu[("Keanu Reeves (Person) born: 1964")] Sandra[("Sandra Bullock (Person) born: 1964")] Patrick[("Patrick Swayze (Person) 1952-2009")] %% Directors Wachowski[("Lana Wachowski (Person) born: 1965")] Bigelow[("Kathryn Bigelow (Person) born: 1951")] %% Genres Action[("Action (Genre)")] SciFi[("Sci-Fi (Genre)")] %% Relationships - Movies to Actors Keanu -->|ACTED_IN| Matrix Keanu -->|ACTED_IN| Speed Keanu -->|ACTED_IN| Point Sandra -->|ACTED_IN| Speed Patrick -->|ACTED_IN| Point %% Relationships - Directors to Movies Wachowski -->|DIRECTED| Matrix Bigelow -->|DIRECTED| Point %% Relationships - Movies to Genres Matrix -->|IN_GENRE| Action Matrix -->|IN_GENRE| SciFi Speed -->|IN_GENRE| Action Point -->|IN_GENRE| Action
Traditional databases excel at handling structured, tabular data, but they often struggle when dealing with highly connected information. Graph databases, particularly Neo4j, provide a more natural way to work with interconnected data. Let's explore why organizations are increasingly turning to graph databases for their data needs.
Limitations of Traditional Databases
Advantages of Graph Databases
Financial Services:
Healthcare:
Technology:
Neo4j is the world's leading graph database platform, designed specifically for storing and querying connected data. While traditional relational databases excel at handling structured, tabular data, Neo4j shines when dealing with complex relationships and interconnected information. At its core, Neo4j uses a property graph model where data is stored as nodes (entities) connected by relationships.
The most basic type of query in cypher is to retrieve all nodes in the database.
You can do this by running the following query:
MATCH (n) RETURN n
This means we want to match any node (we called it n) and return all these nodes.
You can also specify a specific type of node. For example, you might want to retrieve all nodes of type Movie.
You can achieve this by running:
MATCH (n:Movie) RETURN n
This time we are matching against all node of type movie.
You can also include relationships in the query. Let's say we want to retrieve all movies that Tom Hanks acted in. We can do this by running:
MATCH (actor:Actor) -[:ACTED_IN]-> (movie:Movie) WHERE actor.name = "Tom Hanks" RETURN movie.title AS movie_title
In this query we are specifying a relationship between an actor and a movie where the type of the relationship is ACTED_IN.
Note that the relationship has a direction. It is syntactically correct to write (actor:Actor) <-[:ACTED_IN]- (movie:Movie) but this is not going to return anything since it makes no to have a relation of type ACTED_IN coming out of a movie
Let's compare some common operations in SQL and Cypher:
SQL
-- Creating a new movie INSERT INTO Movies (title, released) VALUES ('The Matrix', 1999); -- Creating an actor and linking to movie INSERT INTO Actors (name, born) VALUES ('Keanu Reeves', 1964); INSERT INTO ActedIn (actor_id, movie_id, role) VALUES (1, 1, 'Neo');
Cypher
// Creating a movie and actor with relationship in one query CREATE (m:Movie {title: 'The Matrix', released: 1999}) CREATE (a:Person {name: 'Keanu Reeves', born: 1964}) CREATE (a)-[:ACTED_IN {role: 'Neo'}]->(m)
SQL
SELECT a.name, m.title, m.released FROM Actors a JOIN ActedIn ai ON a.id = ai.actor_id JOIN Movies m ON m.id = ai.movie_id WHERE m.released > 1990 ORDER BY m.released DESC LIMIT 5;
Cypher
MATCH (a:Person)-[:ACTED_IN]->(m:Movie) WHERE m.released > 1990 RETURN a.name, m.title, m.released ORDER BY m.released DESC LIMIT 5;
Key points about Cypher syntax:
Key Differences:
For more information on Cypher, refer to Neo4j documentation
In this section, we will be using the citations dataset provided by Neo4j. The dataset represents an academic citation network containing three main entities:
The relationships between these entities tell us:
%%{init: { 'theme': 'default', 'themeVariables': { 'fontSize': '16px'}, 'flowchart': { 'nodeSpacing': 50, } }}%% graph LR %% Node definitions with properties Article[("(Article) title year")] Author[("(Author) id name")] Venue[("(Venue) id name")] %% Self-referential CITED relationship Article -->|CITED| Article %% Article to Venue relationship Article -->|VENUE| Venue %% Article to Author relationship Author -->|AUTHOR| Article %% Styling classDef default fill:#f9f9f9,stroke:#333,stroke-width:2px; classDef articleClass fill:#f9f9f9,stroke:#333,stroke-width:2px,color:#ff0000; classDef authorClass fill:#f9f9f9,stroke:#333,stroke-width:2px,color:#0000ff; classDef venueClass fill:#f9f9f9,stroke:#333,stroke-width:2px,color:#008000; %% Apply classes to nodes class Article articleClass; class Author authorClass; class Venue venueClass; linkStyle default stroke-width:2px; %% Style specific relationships linkStyle 0 stroke:#ff6b6b,stroke-width:2px; linkStyle 1 stroke:#4834d4,stroke-width:2px; linkStyle 2 stroke:#22a6b3,stroke-width:2px;
In academic research, understanding the flow of knowledge and identifying influential papers is crucial. Traditional metrics like simple citation counts don't tell the whole story. We'll demonstrate how graph databases can reveal deeper insights about research impact and knowledge propagation through citation networks.
Specific Questions We'll Answer:
Let's start with basic impact analysis and progressively build more complex queries:
Which papers are the most cited?
MATCH (a:Article)<-[c:CITED]- () RETURN DISTINCT a.title AS Title, a.n_citation AS citation_count ORDER BY citation_count DESC LIMIT 3
| Title | citation_count |
|---|---|
| A method for obtaining digital signatures and public-key cryptosystems | 18861 |
| Pastry: Scalable, Decentralized Object Location, and Routing for Large-Scale Peer-to-Peer Systems | 10467 |
| Time, clocks, and the ordering of events in a distributed system | 9521 |
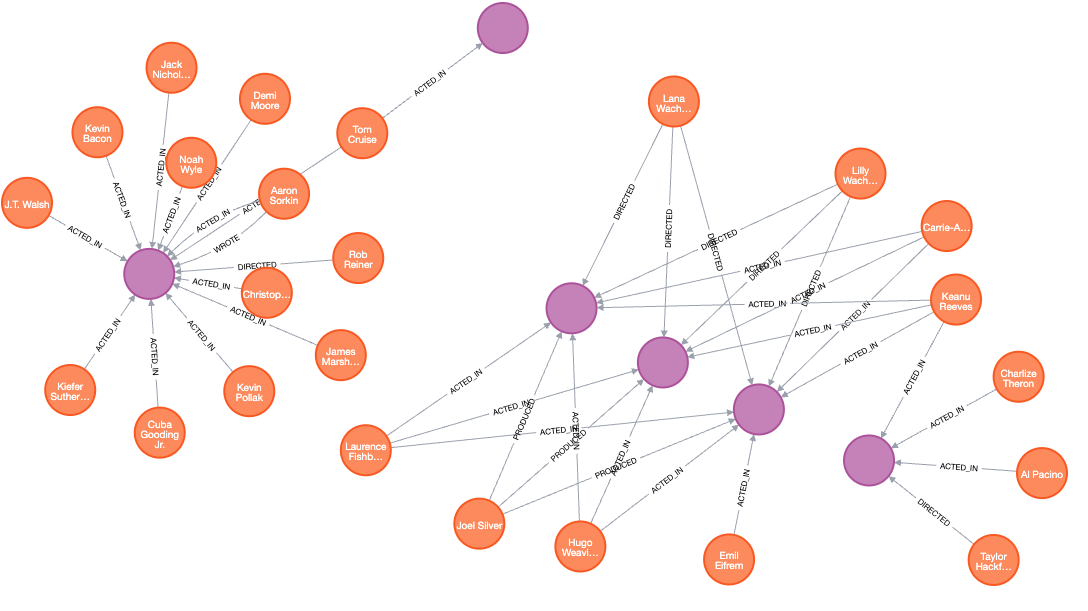
One of the most powerful capabilities of graph databases is their ability to traverse relationships efficiently and find complex patterns. Consider this query:
MATCH path = (a1:Article)-[:CITED*2..3]->(a2:Article) WHERE a1.year > 2015 RETURN path LIMIT 10;
This query traces how knowledge flows through the citation network by:
While this seems simple in Cypher, implementing the same analysis in a relational database would be extremely challenging:
Let's see the results of running this query in Neo4j browser:
While knowledge graphs and Neo4j offer powerful capabilities for handling connected data, several key limitations should be considered:
These limitations should be evaluated against specific use case requirements when considering a knowledge graph implementation.
Throughout this article, we explored the power of graph databases through the lens of academic citation networks. Using Neo4j and its query language Cypher, we demonstrated how naturally graph databases handle interconnected data that would be complex to model and query in traditional relational databases.
Our exploration of citation networks showcased key advantages of graph databases:
The ability to easily traverse citation patterns through multiple levels demonstrates the elegant simplicity of graph databases compared to the complex joins required in relational databases. While we focused on academic citations, these same principles apply to many domains where relationship analysis is crucial, from social networks to fraud detection.
As data becomes increasingly connected, graph databases offer not just a different way to store data, but a more suitable approach for understanding and analyzing relationships within our data. Their ability to efficiently handle complex relationships while maintaining performance makes them an invaluable tool for modern data analysis.

