
Abstract
EmbedAnything is an open-source Rust/Python framework that lets you generate vector embeddings for any data (text, images, audio) with minimal code. It's blazing fast, memory-efficient, and can handle massive datasets through vector streaming - meaning you can process 10GB+ files without running out of RAM. Whether you're building a search engine or recommendation system, you can start with pip install embed-anything and a few lines of Python.
Introduction
Embedding models are essential today. They have become extremely important due to their use in Retrieval-Augmented Generation (RAG), Image Search, Recommendation Systems, and many other applications. EmbedAnything provides a way to embed data from different modalities ranging from audio, images and text in an fast and efficient way. The library is completely written in Rust and leverages the Huggingface Candle library to serve highly performant embedding models like Jina, ColPali, and others. The best part is that there is no dependence on PyTorch or libtorch, making deploying your applications very easy. In this article, we will look at more features EmbedAnything offers. But first, let's see what motivated us to make this library.
Motivation
The AI landscape today is fantastic. New cutting-edge models pop up almost every month. They are more efficient than ever and have excellent capabilities. However, deploying these large models is quite a pain, and there are several frameworks like VLLM, LitServe, and more to make serving LLMS easy. However, most of these solutions do not provide a way to efficiently serve embedding models. Embedding models are challenging because they require a lot of pre-processing even to start the embedding process. For example, embedding a PDF requires extracting the text, chunking it, embedding it, adding the required metadata, and then pushing these embeddings to a vector database. Solutions like Ollama and FastEmbed exist, which provide embedding features but have drawbacks. Other solutions require PyTorch or Libtorch, which makes the application footprint quite heavy, and thus, deployment is more complicated. Moreover, currently, there are no existing solutions to extract embeddings and custom metadata from various file formats. LangChain offers some solutions, but it is a bulky package, and extracting only the embedding data is difficult. Moreover, LangChain is not very suitable for vision-related tasks.
This is where EmbedAnything comes in. It is a lightweight library that allows you to generate embeddings from different file formats and modalities. Currently, EmbedAnything supports text documents, images and audio, with many more formats like video in the pipeline. The idea is to provide an end-to-end solution where you can give the file and get the embeddings with the appropriate metadata.
Development of EmbedAnything started with these goals in mind:
- Compatibility with Local and Cloud Models: Seamless integration with local and cloud-based embedding models.
- High-Speed Performance: Fast processing to meet demanding application requirements.
- Multimodal Capability: Flexibility to handle various modalities.
- CPU and GPU Compatibility: Performance optimization for both CPU and GPU environments.
- Lightweight Design: Minimized footprint for efficient resource utilization.
Our Solution
Now, let us look at the different ways we are tackling the problems associated with embedding data.
Keeping it Local
While cloud-based embedding services like OpenAI, Jina, and Mistral offer convenience, many users require the flexibility and control of local embedding models. Here's why local models are crucial for some use cases:
- Cost-Effectiveness: Cloud services often charge per API call or model usage. Running embeddings locally on your own hardware can significantly reduce costs, especially for projects with frequent or high-volume embedding needs.
- Data Privacy: Certain data, like medical records or financial documents, might be too sensitive to upload to the cloud. Local embedding keeps your data confidential and under your control.
- Offline Functionality: An internet connection isn't always guaranteed. Local models ensure your embedding tasks can run uninterrupted even without an internet connection.
Performance
EmbedAnything is built with Rust. This makes it faster and provides type safety and a much better development experience. But why is speed so crucial in this process?
The need for speed:
Creating embeddings from files involves two steps that demand significant computational power:
- Extracting Text from Files, Especially PDFs: Text can exist in different formats such as markdown, PDFs, and Word documents. However, extracting text from PDFs can be challenging and often causes slowdowns. It is especially difficult to extract text in manageable batches as embedding models have a context limit. Breaking the text into paragraphs containing focused information can help. This task is even more compute intensive which using OCR models like Tesseract to extract text.
- Inferencing on the Transformer Embedding Model: The transformer model is usually at the core of the embedding process, but it is known for being computationally expensive. To address this, EmbedAnything utilizes the Candle Framework by Hugging Face, a machine-learning framework built entirely in Rust for optimized performance.
The Benefit of Rust for Speed
By leveraging Rust for its core functionalities, EmbedAnything offers significant speed advantages:
- Rust is Compiled: Unlike Python, Rust compiles directly to machine code, resulting in faster execution.
- Efficient Memory Management: Working with embedding models requires careful memory usage when handling models and embeddings. Rust's efficient data structures make this possible.
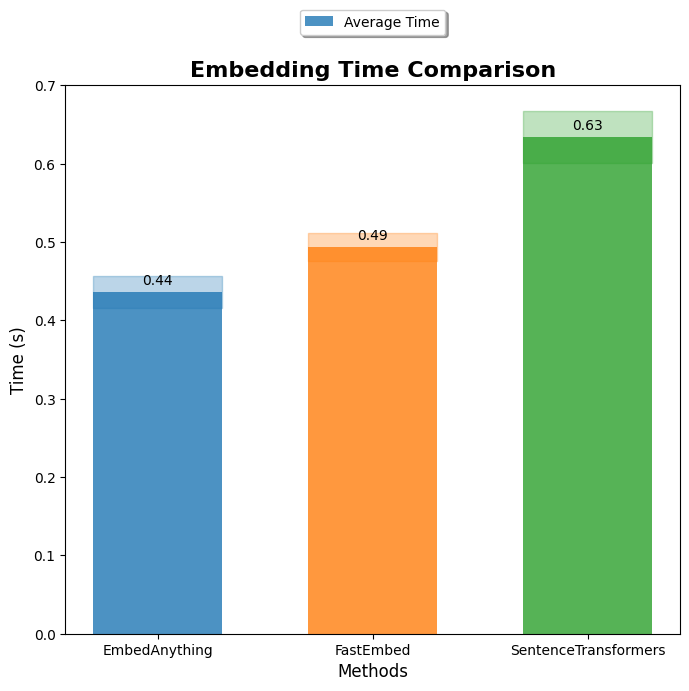
- True Concurrency: Rust enables genuine multi-threading and asynchronous programming. As illustrated in the image below, we can simultaneously extract text, split content, generate embeddings, and push data to the database like in the Vector Streaming feature discussed below.
The image shows the speed of embedding documents with EmbedAnything compared to other libraries. You can find the source for the benchmark here.
What does Candle bring to the table?
Running language models or embedding models locally can be difficult, especially when you want to deploy a product that utilizes these models. If you use the transformers library from Hugging Face in Python, you will depend on PyTorch for tensor operations. This, in turn, depends on Libtorch, meaning you must include the entire Libtorch library with your product. Also, Candle allows inferences on CUDA-enabled GPUs right out of the box.
Multiple Modalities
EmbedAnything supports different modalities. You can embed text documents like HTML Pages, PDFs, and Markdowns using text embedding models like Jina, AllMiniLM, and others. You can also embed images using CLIP.
Audio files can also be embedded using Whisper. The best part about EmbedAnything for audio embedding is that you can connect a text embedding model with Whisper. Using this, you can embed the text that Whisper decodes in parallel. The metadata includes the time stamps of the texts. You can see this in action in this Huggingface Space.
Moreover, with EmbedAnything, you can use late-interaction models like ColPali, which remove the need to do OCR or chunking by embedding the PDF pages as a whole and retrieving the relevant PDF and pages against a query. This has enormous potential. For example, you can reduce the number of tokens that a Vision Language Model uses for document reading by retrieving only the valid pages and then showing them to large VLMs like GPT-4o and Gemini Flash. This can save a lot of cost and time.
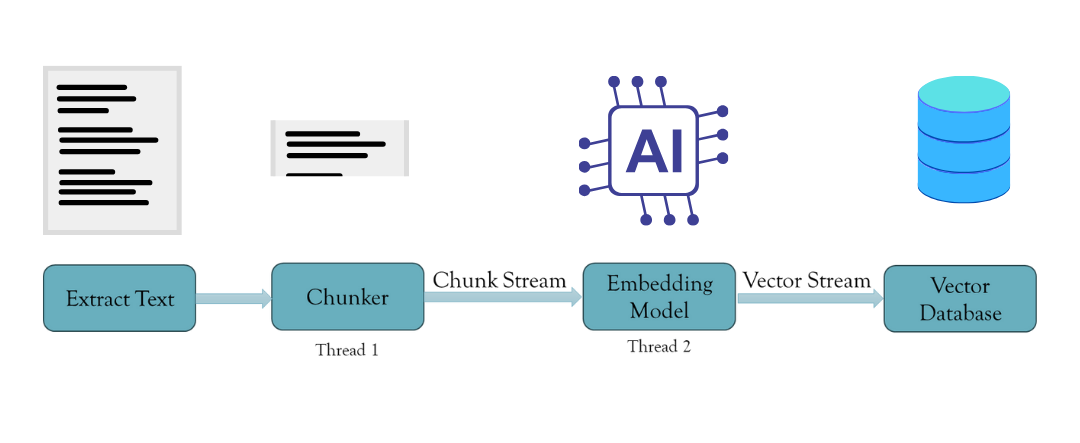
Vector Streaming
Vector streaming allows you to create an asynchronous chunking and embedding task. We can effectively spawn threads to handle this task using Rust's concurrency patterns and thread safety. This is done using Rust's MPSC (Multi-producer Single Consumer) module, which passes messages between threads. Thus, this creates a stream of chunks passed into the embedding thread with a buffer. Once the buffer is complete, it embeds the chunks and sends the embeddings back to the main thread, where they are sent to the vector database. This ensures time is well spent on a single operation and no bottlenecks. Moreover, only the chunks and embeddings in the buffer are stored in the system memory. They are erased from the memory once moved to the vector database.
Thus, it effectively solves the problem by making many tasks done asynchronously and thus improving efficiency.
Real-world Use Cases
- Vector Streaming: This involves streaming live information from videos by breaking them into frames and generating embeddings of the images using multimodal embedding models like CLIP. This technique is particularly useful for live camera feeds, such as CCTV, to detect malicious activities or traffic violations.
- Search Applications: We generate embeddings from PDFs and enable direct searches for page numbers based on user queries, utilizing ColPali. All of this is integrated into our pipeline.
- Classification Problems: Embeddings can be employed for classification tasks and can scale through metric learning, allowing for the easy addition of new classes.
- RAG Applications: We view EmbedAnything as an ingestion pipeline for vector databases, which can be extensively utilized for Retrieval-Augmented Generation (RAG) in chatbots.
How to get started?
To install our library, all you have to do is
pip install embed-anythin
To improve the speed further and to use large models like ColPali, use the GPU version of embed anything by running.
pip install embed-anything-gpu
Then, with just a few lines of code, you can embed any files and directories.
model = EmbeddingModel.from_pretrained_hf( WhichModel.Bert, model_id="model link from huggingface" ) config = TextEmbedConfig(chunk_size=200, batch_size=32) data = embed_anything.embed_file("file_address", embeder=model, config=config)
You can check out the documentation at https://starlight-search.com/references/
What’s Next
Future work includes expanding our modalities and vector streaming adapters. We currently support unstructured sources like images, audio, and texts from different sources like PDFs, markdown, and jpegs, but we would also like to expand to graph embeddings and video embeddings. We currently support Weaviate and Elastic Cloud to stream the vectors, which we will expand to other vector databases.
Moreover, we will also release methods to fine-tune embedding models easily using Candle, similar to how Sentence Transformers does, but with the speed and memory efficiency of Rust.
With this, I would like to conclude this article on this amazing new library that I am building, and I hope to receive some great feedback from the readers. Try it out now and check out the GitHub Repo.