
Stable Diffusion is a text-to-image deep learning model, based on diffusion models. It is a powerful AI tool that can create images from text descriptions. It was developed in 2022 by researchers at the CompViz Group at LMU Munich.
Image-to-Image is a feature that lets you modify an existing image. Suppose we have a picture, and we want to make some changes to it, like we want to change the background, add an object, or alter the style of the image. We provide a prompt of what we want, and the model generates a new image based on our instructions.
Inpainting is a technique that allows us to remove or replace specific parts of an image. Suppose we want to remove an unwanted object or a person in the background. With inpainting, we can describe what you want to replace it with, and the model will fill in that area seamlessly, making it look like the unwanted element was never there.
A generative model learns a probability distribution of the data set, then we can sample from the distribution to create a new imstances of data. For example, if we have a picture of cats and we train a generative model on it, we then sample from this distribution to create new images of cats.
Suppose we want to generate fake identities, each made up of variables, representing the characteristics of a person like Age, Height, etc. We can use data from the Statistics Department of the Government about how these characteristics are distributed in the population. So we have two Gaussian Distributions for age and for height. Then we sample (randomly pick values) from these distributions. Sampling means to throw a coin that has a very high chance of falling in the center area of the Gaussian Distribution and lower almost negligible chances of falling in the extreme areas of the curve.
For example, if age is 3 years and height is 130 cm, this combination is not realistic for humans. This happens because height may fall within its distribution, but not age. To generate fake identities that make sense, we need a joint distribution. Using a joint distribution, we can evaluate probabilities of one variable based on the other using conditional probability or by marginalizing a variable.
Similarly, in machine learning, we model data using a very large joint distribution. Since this distribution is complex, we use a neural network to learn its parameters. The goal is to use this learned distribution to sample from it and generate new data.
In a diffusion model, we have a forward process and a reverse process. The forward process starts with an initial image x0. We add noise to it to create a new image x1, which is similar to the original but has some noise added. This process is repeated multiple times, adding noise step by step, until we reach the last latent variable, x1000, where the image becomes completely noisy (pure noise).
The forward process is fixed, meaning we define a formula to add noise to an image given the previous one. However, we do not have an analytical formula to reverse this process and remove the noise. To achieve this, we train a Neural Network to perform the reverse process and gradually remove the noise to recover the original image.
I have explained the maths behind this in my previous articles:
Mastering Diffusion Probabilistic Models from Scratch
Once the model is trained to detect the amount of noise in an image, we start with pure noise and ask the model to detect and remove the noise. This process is repeated step by step until we obtain a denoised image.
Additionally, we need to control this denoising process to generate specific images based on our requirements. While the model can generate images starting from pure noise, we don’t know which image will be generated without further guidance. To address this, we introduce a conditioning signal (prompt) at each denoising step. This prompt influences the model, guiding it on how to remove the noise so that the output moves closer to the desired image.

The 𝜖 represents how much noise has been added to the image. This is predicted using a U-Net architecture, which takes the image as input and outputs the amount of noise present. To improve the model’s ability to remove noise, we also provide a conditional signal along with the image, giving the model more information about how to denoise it.
To condition the network, we could train a model to learn the joint distribution of the data and the conditional signal, and then sample from this distribution. However, this approach would require training a separate model for each specific conditional signal.
Instead of training two separate networks (one conditional and one unconditional), we train a single network. During training, we pass some images with prompts (conditioning signals) and others with no prompt (represented as a bunch of zeros). This allows the model to learn both how to pay attention to the prompt and how to work without it.
In step 1 we pass the noise will prompt that we want to generate a cat’s image, in step 2 we pass the same noise without the prompt. And using the output of both the steps we can decide how much we want the output to be closer to the prompt. This is called Classifier Free Guidance approach.
output = w (co — uo) + uo*
w is the weight that indicates how much we want the model to pay attention to the conditioning signal. co is conditional output and uo is unconditional output. Higher the value of w, more the output will resemble the prompt.
To use prompts effectively, we need to convert them into embeddings (vector representations) that capture their meaning. These embeddings are generated using the CLIP Text Encoder.
CLIP, developed by OpenAI, combines a Text Encoder and an Image Encoder to connect text with images. It was trained on a large dataset of images and their corresponding descriptions. The training process creates a matrix where each entry is the dot product of all the image embeddings and with all the text embeddings. The correct image-caption pairs appear along the diagonal of this matrix. The loss function is designed to maximize the diagonal values while making rest of the values 0.
In Stable Diffusion, we use the Text Encoder part of the CLIP model to encode the prompts into embeddings. These embeddings are then used as conditioning signals for the U-Net model to denoise the image.
Performing many steps in the reverse process for large images can be time-consuming. Every step involves passing the image through the U-Net to denoise it. For large image sizes like 512 x 512, 1024 x 1024, etc; this process can take a significant amount of time. To address this, we use a Variational Autoencoder (VAE).
Stable Diffusion is also called a Latent Diffusion Model because instead of learning the dataset of full-sized images, the model learns the distribution of a latent representation of the data using a VAE. This allows us to reduce the computation we need to perform the steps needed to generate a sample, because each data will not be represented by a 512 x 512 image, but its latent represenatation which is 64 x 64. This latent representation allows the model to perform denoising steps more efficiently while still being able to reconstruct high-quality images during the final decoding step.

An Autoencoder in a network that transforms the given image into a vector which has dimension that is much smaller than the original one. And if we use this vector and pass it through the decoder then we get the original image back. The problem with autoencoder is that the feature learned or the vector generated by this model doesn’t make any sense from a semantic point of view, so the feature associated with a cat image may be very similar to the code associated with a pizza image. To over come this limitation of the autoencoder we introduce the variational autoencoder. Instead of learning a vector or feature, it learns a latent space. The latent space represents the parameters of a (multivariate) distribution which most of the time is Gaussian.
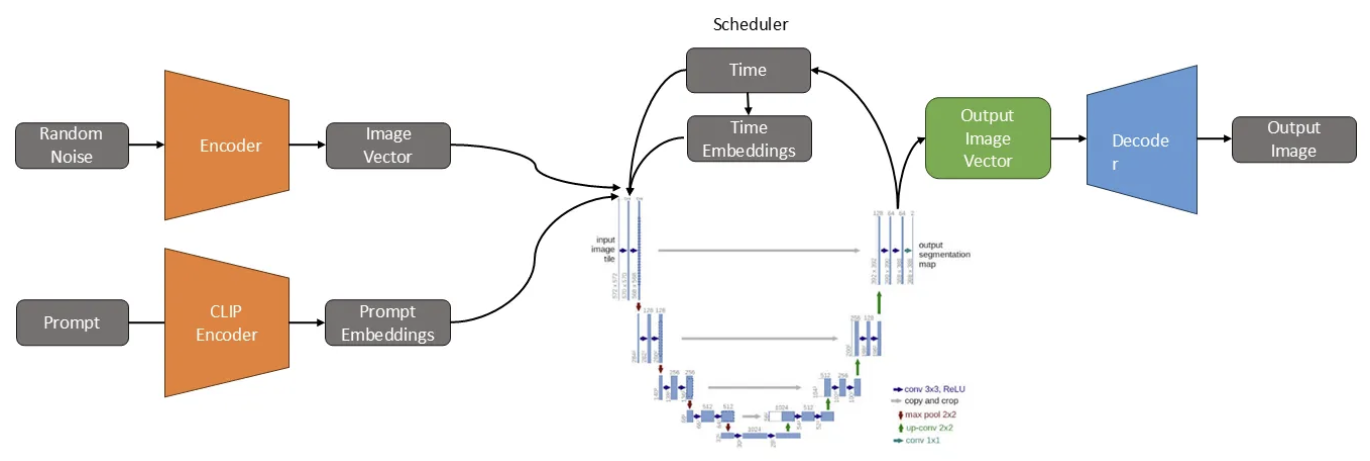
We pass the random noise into the Autoencoder to get the vector representation. We pass the prompt into the CLIP Encoder to get the embeddings. We then pass the image vector with the prompt embeddings into the U-Net model that passes its output into the decoder to get get the denoised image.
The Image Vector is the latent representation of the noisy image, compressed by the encoder. This latent representation, along with the prompt embeddings (used as a conditioning signal) and the time step, is sent into the U-Net. The goal of the U-Net is to estimate how much noise needs to be removed to transform the latent representation into an image that matches the prompt.
The Scheduler removes the noise as estimated by the U-Net and sends the updated output back into the U-Net as input for the next step. This process continues iteratively across all T steps. Once all T steps are completed, the output from the final step (which is still a latent representation) is passed into the decoder. The decoder reconstructs the final image from this latent representation.
For Image-to-Image tasks, instead of starting with random noise, we pass the input image and add some noise to the latent representation generated by the encoder. The amount of noise added controls how much attention the model should pay to the original image.
For In-Painting, the process is similar to Image-to-Image but with a mask. We mask the part of the input image that we want to modify and pass it, along with the current time step, into the U-Net. The U-Net’s output is then passed to the scheduler where the known (unmasked) parts of the image are preserved, while the part that we want to alter is masked. This ensures that the model works only on the masked area, leaving the rest of the image unchanged.
First, we build the Encoder, which consists of a sequence of submodels. Each submodel reduces the dimensionality of the data while increasing the number of features which means the number of pixels are reducing but every time the information stored by each pixel is increasing.
import torch from torch import nn from torch.nn import functional as F from decoder import VAE_AttentionBlock, VAE_ResidualBlock class VAE_Encoder(nn.Sequential): def __init__(self): super().__init__( # (Batch_Size, Channel, Height, Width) -> (Batch_Size, 128, Height, Width) nn.Conv2d(3, 128, kernel_size=3, padding=1), # (Batch_Size, 128, Height, Width) -> (Batch_Size, 128, Height, Width) VAE_ResidualBlock(128, 128), VAE_ResidualBlock(128, 128), # (Batch_Size, 128, Height, Width) -> (Batch_Size, 128, Height/2, Width/2) nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=0), # (Batch_Size, 128, Height/2, Width/2) -> (Batch_Size, 256, Height/2, Width/2) VAE_ResidualBlock(128, 256), # (Batch_Size, 256, Height/2, Width/2) -> (Batch_Size, 256, Height/2, Width/2) VAE_ResidualBlock(256, 256), # (Batch_Size, 256, Height/2, Width/2) -> (Batch_Size, 256, Height/4, Width/4) nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=0), # (Batch_Size, 256, Height/4, Width/4) -> (Batch_Size, 512, Height/4, Width/4) VAE_ResidualBlock(256, 512), # (Batch_Size, 512, Height/4, Width/4) -> (Batch_Size, 512, Height/4, Width/4) VAE_ResidualBlock(512, 512), # (Batch_Size, 512, Height/4, Width/4) -> (Batch_Size, 512, Height/8, Width/8) nn.Conv2d(512, 512, kernel_size=3, stride=2, padding=0), # (Batch_Size, 512, Height/8, Width/8) -> (Batch_Size, 512, Height/8, Width/8) VAE_ResidualBlock(512, 512), VAE_ResidualBlock(512, 512), VAE_ResidualBlock(512, 512), VAE_AttentionBlock(512), VAE_ResidualBlock(512, 512), nn.GroupNorm(32, 512), nn.SiLU(), # (Batch_Size, 512, Height/8, Width/8) -> (Batch_Size, 8, Height/8, Width/8) nn.Conv2d(512, 8, kernel_size=3, padding=1), # (Batch_Size, 8, Height/8, Width/8) -> (Batch_Size, 8, Height/8, Width/8) nn.Conv2d(8, 8, kernel_size=1, padding=0) ) def forward(self, x:torch.Tensor, noise:torch.Tensor) -> torch.Tensor: # x: (Batch_Size, Channel, Height, Width); noise: (Batch_Size, Output_Channel, Height/8, Width/8) for module in self: if getattr(module, 'stride', None) == (2,2): # (Padding_Left, Padding_Right, Padding_Top, Padding_Bottom) x = F.pad(x, (0,1,0,1)) # Asymetric Padding x = module() # # (Batch_Size, 8, Height, Height/8, Width/8) -> two tensors of shape (Batch_Size, 4, Height/8, Width/8) mean, log_variance = torch.chunk(x, 2, dim=1) log_variance = torch.clamp(log_variance, -30, 20) variance = log_variance.exp() stdev = variance.sqrt() # Z = N(0,1) -> X = N(mean, variance) # X = mean + stdev * Z x = mean + stdev * noise # Scale the output by a constant x *= 0.18215 return x
The architecture follows this pattern:
The activation function we are using is SiLU (Sigmoid Linear Unit), there is no special reason for choosing this function over other, just the authors saw that this one works better for this kind of applications.
The forward method in the encoder class is responsible for processing the input tensor x through the encoder network. When a convolutional layer with a stride of 2 is encountered, the input tensor x is padded asymmetrically (padding only right side and bottom side) using F.pad(x, (0,1,0,1)). This padding ensures that the spatial dimensions are correctly reduced by half.
The autoencoder does not learn to compress the data directly. Instead, it learns a latent space that represents the parameters of a multivariate Gaussian distribution. The encoder is trained to learn the mean and variance of this distribution, and its output consists of the mean and the log variance.
The chunk function splits a tensor into two tensors along a given dimension (dim=1).
The clamp function ensures that values stay within a specified range to prevent instability.
To transform log variance into variance, we use the exp function.
Once we obtain the mean and variance of the multivariate Gaussian distribution, we sample from it using the transformation: X = mean + std_deviation * Z, where Z is random noise. Finally, we scale the output by a constant (0.18215), which is a scaling factor used by the authors.
import torch from torch import nn from torch.nn import functional as F from attention import SelfAttention class VAE_AttentionBlock(nn.Module): def __init__(self, channels): super().__init__() self.groupnorm = nn.GroupNorm(32, channels) self.attention = SelfAttention(1, channels) def forward(self, x): # x: (Batch_Size, Features, Height, Width) residue = x # (Batch_Size, Features, Height, Width) -> (Batch_Size, Features, Height, Width) x = self.groupnorm(x) n, c, h, w = x.shape # (Batch_Size, Features, Height, Width) -> (Batch_Size, Features, Height * Width) x = x.view((n, c, h * w)) # (Batch_Size, Features, Height * Width) -> (Batch_Size, Height * Width, Features). Each pixel becomes a feature of size "Features", the sequence length is "Height * Width". x = x.transpose(-1, -2) # Perform self-attention WITHOUT mask # (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features) x = self.attention(x) # (Batch_Size, Height * Width, Features) -> (Batch_Size, Features, Height * Width) x = x.transpose(-1, -2) # (Batch_Size, Features, Height * Width) -> (Batch_Size, Features, Height, Width) x = x.view((n, c, h, w)) # (Batch_Size, Features, Height, Width) + (Batch_Size, Features, Height, Width) -> (Batch_Size, Features, Height, Width) x += residue # (Batch_Size, Features, Height, Width) return x class VAE_ResidualBlock(nn.Module): def __init__(self, in_channels, out_channels): super().__init__() self.groupnorm_1 = nn.GroupNorm(32, in_channels) self.conv_1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1) self.groupnorm_2 = nn.GroupNorm(32, out_channels) self.conv_2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1) if in_channels == out_channels: self.residual_layer = nn.Identity() else: self.residual_layer = nn.Conv2d(in_channels, out_channels, kernel_size=1, padding=0) def forward(self, x): # x: (Batch_Size, In_Channels, Height, Width) residue = x # (Batch_Size, In_Channels, Height, Width) -> (Batch_Size, In_Channels, Height, Width) x = self.groupnorm_1(x) x = F.silu(x) # (Batch_Size, In_Channels, Height, Width) -> (Batch_Size, Out_Channels, Height, Width) x = self.conv_1(x) # (Batch_Size, Out_Channels, Height, Width) -> (Batch_Size, Out_Channels, Height, Width) x = self.groupnorm_2(x) x = F.silu(x) x = self.conv_2(x) return x + self.residual_layer(residue) class VAE_Decoder(nn.Sequential): def __init__(self): super().__init__( # (Batch_Size, 4, Height / 8, Width / 8) -> (Batch_Size, 4, Height / 8, Width / 8) nn.Conv2d(4, 4, kernel_size=1, padding=0), # (Batch_Size, 4, Height / 8, Width / 8) -> (Batch_Size, 512, Height / 8, Width / 8) nn.Conv2d(4, 512, kernel_size=3, padding=1), # (Batch_Size, 512, Height / 8, Width / 8) -> (Batch_Size, 512, Height / 8, Width / 8) VAE_ResidualBlock(512, 512), VAE_AttentionBlock(512), VAE_ResidualBlock(512, 512), VAE_ResidualBlock(512, 512), VAE_ResidualBlock(512, 512), VAE_ResidualBlock(512, 512), # Repeats the rows and columns of the data by scale_factor (like when you resize an image by doubling its size). # (Batch_Size, 512, Height / 8, Width / 8) -> (Batch_Size, 512, Height / 4, Width / 4) nn.Upsample(scale_factor=2), # (Batch_Size, 512, Height / 4, Width / 4) -> (Batch_Size, 512, Height / 4, Width / 4) nn.Conv2d(512, 512, kernel_size=3, padding=1), VAE_ResidualBlock(512, 512), VAE_ResidualBlock(512, 512), VAE_ResidualBlock(512, 512), # (Batch_Size, 512, Height / 4, Width / 4) -> (Batch_Size, 512, Height / 2, Width / 2) nn.Upsample(scale_factor=2), # (Batch_Size, 512, Height / 2, Width / 2) -> (Batch_Size, 512, Height / 2, Width / 2) nn.Conv2d(512, 512, kernel_size=3, padding=1), # (Batch_Size, 512, Height / 2, Width / 2) -> (Batch_Size, 256, Height / 2, Width / 2) VAE_ResidualBlock(512, 256), # (Batch_Size, 256, Height / 2, Width / 2) -> (Batch_Size, 256, Height / 2, Width / 2) VAE_ResidualBlock(256, 256), VAE_ResidualBlock(256, 256), # (Batch_Size, 256, Height / 2, Width / 2) -> (Batch_Size, 256, Height, Width) nn.Upsample(scale_factor=2), # (Batch_Size, 256, Height, Width) -> (Batch_Size, 256, Height, Width) nn.Conv2d(256, 256, kernel_size=3, padding=1), # (Batch_Size, 256, Height, Width) -> (Batch_Size, 128, Height, Width) VAE_ResidualBlock(256, 128), # (Batch_Size, 128, Height, Width) -> (Batch_Size, 128, Height, Width) VAE_ResidualBlock(128, 128), VAE_ResidualBlock(128, 128), nn.GroupNorm(32, 128), nn.SiLU(), # (Batch_Size, 128, Height, Width) -> (Batch_Size, 3, Height, Width) nn.Conv2d(128, 3, kernel_size=3, padding=1), ) def forward(self, x): # x: (Batch_Size, 4, Height / 8, Width / 8) # Remove the scaling added by the Encoder. x /= 0.18215 for module in self: x = module(x) # (Batch_Size, 3, Height, Width) return x
The self-attention block allows the model to focus on different parts of the input feature map, which is particularly useful for capturing long-range dependencies in the data.
The input x is normalized using Group Normalization, this normalizes the activations across the channels of the input feature map. It is less sensitive to batch size compared to Batch Normalization. The feature map is reshaped to treat each pixel as a sequence element. The sequence is transposed to (Batch_Size, Height * Width, Features) to apply self-attention. A custom self-attention mechanism that computes attention scores for each pixel in the feature map. It helps the model focus on relevant parts of the input. The sequence is reshaped back to the original shape (Batch_Size, Features, Height, Width). A residual connection is added to the output to preserve information from the input.
The residual block commonly used in deep neural networks. It helps in training very deep networks by allowing gradients to flow through shortcut connections.
The input x is normalized and passed through a SiLU activation. It is then convolved with the first convolutional layer. The output is normalized again, activated with SiLU, and passed through the second convolutional layer. The result is added to the residual connection (either the original input or a transformed version). If the input and output channels are the same, the residual connection is an identity mapping. Otherwise, a 1x1 convolution is used to match the dimensions.
The residual connection is used when the in and out channels are different
The VAE_Decoder is implemented as sequential module, which allows for a clean and modular definition of the layers. This reconstructs the input data from the latent space.
The input x (latent space representation) is scaled by dividing by 0.18215 to reverse the scaling applied by the encoder. The input is passed through each module in the nn.Sequential: Convolutional layers; Residual blocks; Attention blocks; Upsampling layers. The final output is a reconstructed image with shape (Batch_Size, 3, Height, Width).
import torch from torch import nn from torch.nn import functional as F import math class SelfAttention(nn.Module): def __init__(self, n_heads, d_embed, in_proj_bias=True, out_proj_bias=True): super().__init__() # This combines the Wq, Wk and Wv matrices into one matrix self.in_proj = nn.Linear(d_embed, 3 * d_embed, bias=in_proj_bias) # This one represents the Wo matrix self.out_proj = nn.Linear(d_embed, d_embed, bias=out_proj_bias) self.n_heads = n_heads self.d_head = d_embed // n_heads def forward(self, x, causal_mask=False): # x: # (Batch_Size, Seq_Len, Dim) # (Batch_Size, Seq_Len, Dim) input_shape = x.shape batch_size, sequence_length, d_embed = input_shape # (Batch_Size, Seq_Len, H, Dim / H) interim_shape = (batch_size, sequence_length, self.n_heads, self.d_head) # (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, Dim * 3) -> 3 tensor of shape (Batch_Size, Seq_Len, Dim) q, k, v = self.in_proj(x).chunk(3, dim=-1) # (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, H, Dim / H) -> (Batch_Size, H, Seq_Len, Dim / H) q = q.view(interim_shape).transpose(1, 2) k = k.view(interim_shape).transpose(1, 2) v = v.view(interim_shape).transpose(1, 2) # (Batch_Size, H, Seq_Len, Dim / H) @ (Batch_Size, H, Dim / H, Seq_Len) -> (Batch_Size, H, Seq_Len, Seq_Len) weight = q @ k.transpose(-1, -2) if causal_mask: # Mask where the upper triangle (above the principal diagonal) is 1 mask = torch.ones_like(weight, dtype=torch.bool).triu(1) # Fill the upper triangle with -inf weight.masked_fill_(mask, -torch.inf) # Divide by d_k (Dim / H). # (Batch_Size, H, Seq_Len, Seq_Len) -> (Batch_Size, H, Seq_Len, Seq_Len) weight /= math.sqrt(self.d_head) weight = F.softmax(weight, dim=-1) # (Batch_Size, H, Seq_Len, Seq_Len) @ (Batch_Size, H, Seq_Len, Dim / H) -> (Batch_Size, H, Seq_Len, Dim / H) output = weight @ v # (Batch_Size, H, Seq_Len, Dim / H) -> (Batch_Size, Seq_Len, H, Dim / H) output = output.transpose(1, 2) # (Batch_Size, Seq_Len, H, Dim / H) -> (Batch_Size, Seq_Len, Dim) output = output.reshape(input_shape) # (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, Dim) output = self.out_proj(output) # (Batch_Size, Seq_Len, Dim) return output class CrossAttention(nn.Module): def __init__(self, n_heads, d_embed, d_cross, in_proj_bias=True, out_proj_bias=True): super().__init__() self.q_proj = nn.Linear(d_embed, d_embed, bias=in_proj_bias) self.k_proj = nn.Linear(d_cross, d_embed, bias=in_proj_bias) self.v_proj = nn.Linear(d_cross, d_embed, bias=in_proj_bias) self.out_proj = nn.Linear(d_embed, d_embed, bias=out_proj_bias) self.n_heads = n_heads self.d_head = d_embed // n_heads def forward(self, x, y): # x (latent): # (Batch_Size, Seq_Len_Q, Dim_Q) # y (context): # (Batch_Size, Seq_Len_KV, Dim_KV) = (Batch_Size, 77, 768) input_shape = x.shape batch_size, sequence_length, d_embed = input_shape # Divide each embedding of Q into multiple heads such that d_heads * n_heads = Dim_Q interim_shape = (batch_size, -1, self.n_heads, self.d_head) # (Batch_Size, Seq_Len_Q, Dim_Q) -> (Batch_Size, Seq_Len_Q, Dim_Q) q = self.q_proj(x) # (Batch_Size, Seq_Len_KV, Dim_KV) -> (Batch_Size, Seq_Len_KV, Dim_Q) k = self.k_proj(y) v = self.v_proj(y) # (Batch_Size, Seq_Len_Q, Dim_Q) -> (Batch_Size, Seq_Len_Q, H, Dim_Q / H) -> (Batch_Size, H, Seq_Len_Q, Dim_Q / H) q = q.view(interim_shape).transpose(1, 2) # (Batch_Size, Seq_Len_KV, Dim_Q) -> (Batch_Size, Seq_Len_KV, H, Dim_Q / H) -> (Batch_Size, H, Seq_Len_KV, Dim_Q / H) k = k.view(interim_shape).transpose(1, 2) v = v.view(interim_shape).transpose(1, 2) # (Batch_Size, H, Seq_Len_Q, Dim_Q / H) @ (Batch_Size, H, Dim_Q / H, Seq_Len_KV) -> (Batch_Size, H, Seq_Len_Q, Seq_Len_KV) weight = q @ k.transpose(-1, -2) # (Batch_Size, H, Seq_Len_Q, Seq_Len_KV) weight /= math.sqrt(self.d_head) weight = F.softmax(weight, dim=-1) # (Batch_Size, H, Seq_Len_Q, Seq_Len_KV) @ (Batch_Size, H, Seq_Len_KV, Dim_Q / H) -> (Batch_Size, H, Seq_Len_Q, Dim_Q / H) output = weight @ v # (Batch_Size, H, Seq_Len_Q, Dim_Q / H) -> (Batch_Size, Seq_Len_Q, H, Dim_Q / H) output = output.transpose(1, 2).contiguous() # (Batch_Size, Seq_Len_Q, H, Dim_Q / H) -> (Batch_Size, Seq_Len_Q, Dim_Q) output = output.view(input_shape) # (Batch_Size, Seq_Len_Q, Dim_Q) -> (Batch_Size, Seq_Len_Q, Dim_Q) output = self.out_proj(output) # (Batch_Size, Seq_Len_Q, Dim_Q) return output
Self-Attention allows a model to focus on different parts of the input sequence when processing each element. It computes relationships (attention scores) between all pairs of elements in the sequence. This mechanism is used in models like BERT, GPT, and Vision Transformers (ViT) to capture relationships within a single sequence (e.g., words in a sentence or patches in an image).
Input Projection: The input tensor x is projected into three matrices: Query (q), Key (k), and Value (v) using a single linear layer (self.in_proj). These matrices are split into n_heads (multi-head attention) to allow the model to focus on different parts of the sequence simultaneously.
Attention Scores: The attention scores are computed as the dot product of q and k, scaled by 1 / sqrt(d_head) to prevent large values that could destabilize training. If causal_mask is enabled, a mask is applied to prevent the model from attending to future tokens (used in autoregressive models like GPT).
The attention scores are passed through a softmax function to normalize them into probabilities. The output is computed as a weighted sum of v using the attention scores.
Output Projection: The concatenated output of the attention heads is projected back to the original dimensionality using self.out_proj.
Cross-Attention allows a model to attend to a different sequence (context) while processing the current sequence. It is commonly used in encoder-decoder architectures (e.g., Transformers for machine translation).
Input Projection: The input tensor x is projected into Query (q) using self.q_proj. The context tensor y is projected into Key (k) and Value (v) using self.k_proj and self.v_proj.
Attention Scores: The attention scores are computed as the dot product of q and k, scaled by 1 / sqrt(d_head).
The attention scores are passed through a softmax function to normalize them into probabilities. The output is computed as a weighted sum of v using the attention scores.
Output Projection: The concatenated output of the attention heads is projected back to the original dimensionality using self.out_proj.
In both the mechanism no explicit activation function is used. However, the output of the these blocks are often passed through a non-linear activation function (e.g., GELU) in subsequent layers.
import torch from torch import nn from attention import SelfAttention class CLIPEmbedding(nn.Module): def __init__(self, n_vocab: int, n_embd: int, n_token: int): super().__init__() self.token_embedding = nn.Embedding(n_vocab, n_embd) # A learnable weight matrix encodes the position information for each token self.position_embedding = nn.Parameter(torch.zeros((n_token, n_embd))) def forward(self, tokens): # (Batch_Size, Seq_Len) -> (Batch_Size, Seq_Len, Dim) x = self.token_embedding(tokens) # (Batch_Size, Seq_Len) -> (Batch_Size, Seq_Len, Dim) x += self.position_embedding return x class CLIPLayer(nn.Module): def __init__(self, n_head: int, n_embd: int): super().__init__() # Pre-attention norm self.layernorm_1 = nn.LayerNorm(n_embd) # Self attention self.attention = SelfAttention(n_head, n_embd) # Pre-FNN norm self.layernorm_2 = nn.LayerNorm(n_embd) # Feedforward layer self.linear_1 = nn.Linear(n_embd, 4 * n_embd) self.linear_2 = nn.Linear(4 * n_embd, n_embd) def forward(self, x): # (Batch_Size, Seq_Len, Dim) residue = x ### SELF ATTENTION ### # (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, Dim) x = self.layernorm_1(x) # (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, Dim) x = self.attention(x, causal_mask=True) # (Batch_Size, Seq_Len, Dim) + (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, Dim) x += residue ### FEEDFORWARD LAYER ### # Apply a feedforward layer where the hidden dimension is 4 times the embedding dimension. residue = x # (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, Dim) x = self.layernorm_2(x) # (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, 4 * Dim) x = self.linear_1(x) # (Batch_Size, Seq_Len, 4 * Dim) -> (Batch_Size, Seq_Len, 4 * Dim) x = x * torch.sigmoid(1.702 * x) # QuickGELU activation function # (Batch_Size, Seq_Len, 4 * Dim) -> (Batch_Size, Seq_Len, Dim) x = self.linear_2(x) # (Batch_Size, Seq_Len, Dim) + (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, Dim) x += residue return x class CLIP(nn.Module): def __init__(self): super().__init__() self.embedding = CLIPEmbedding(49408, 768, 77) self.layers = nn.ModuleList([ CLIPLayer(12, 768) for i in range(12) ]) self.layernorm = nn.LayerNorm(768) def forward(self, tokens: torch.LongTensor) -> torch.FloatTensor: tokens = tokens.type(torch.long) # (Batch_Size, Seq_Len) -> (Batch_Size, Seq_Len, Dim) state = self.embedding(tokens) # Apply encoder layers similar to the Transformer's encoder. for layer in self.layers: # (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, Dim) state = layer(state) # (Batch_Size, Seq_Len, Dim) -> (Batch_Size, Seq_Len, Dim) output = self.layernorm(state) return output
The CLIPEmbedding class converts input tokens (text) into embeddings. It combines token embeddings (learned representations of words) with positional embeddings (to encode the position of each token in the sequence).
Token Embedding: A learnable embedding layer that maps token indices to dense vectors of size n_embd.
Positional Embedding: A learnable parameter that encodes the position of each token in the sequence. It has a shape of (n_token, n_embd).
Operation: A tensor of shape (Batch_Size, Seq_Len) containing token indices is passed through self.token_embedding to produce token embeddings of shape (Batch_Size, Seq_Len, Dim). The positional embeddings are added to the token embeddings to incorporate positional information. The output is a tensor of shape (Batch_Size, Seq_Len, Dim) containing the combined token and positional embeddings.
The CLIPLayer class represents a single layer of the CLIP text encoder. It consists of a self-attention mechanism followed by a feedforward neural network (FNN), with residual connections and layer normalization applied at each step.
Self-Attention: A multi-head self-attention mechanism that computes relationships between all tokens in the sequence. Uses layer normalization and residual connections.
Feedforward Network: A two-layer feedforward network with a QuickGELU activation function. Expands the dimensionality to 4 * n_embd and then projects it back to n_embd. Uses layer normalization and residual connections.
Operation: A tensor of shape (Batch_Size, Seq_Len, Dim) is normalized and passed through the self-attention mechanism. The residual connection (original input) is added to the output of self-attention. The output of the self-attention block is normalized and passed through the feedforward network (linear_1 -> activation -> linear_2). The residual connection (output of self-attention) is added to the output of the feedforward network. The output is a tensor of shape (Batch_Size, Seq_Len, Dim).
The CLIP class represents the full CLIP text encoder. It stacks multiple CLIPLayer modules to form a deep neural network.
Operation: The input tokens of shape (Batch_Size, Seq_Len) are converted into embeddings using self.embedding. The embeddings are passed through each of the 12 CLIPLayer modules. Layer normalization is applied to the final output. The output is a tensor of shape (Batch_Size, Seq_Len, Dim) representing the encoded text.
import torch from torch import nn from torch.nn import functional as F from attention import SelfAttention, CrossAttention class TimeEmbedding(nn.Module): def __init__(self, n_embd): super().__init__() self.linear_1 = nn.Linear(n_embd, 4 * n_embd) self.linear_2 = nn.Linear(4 * n_embd, 4 * n_embd) def forward(self, x): # x: (1, 320) # (1, 320) -> (1, 1280) x = self.linear_1(x) # (1, 1280) -> (1, 1280) x = F.silu(x) # (1, 1280) -> (1, 1280) x = self.linear_2(x) return x class UNET_ResidualBlock(nn.Module): def __init__(self, in_channels, out_channels, n_time=1280): super().__init__() self.groupnorm_feature = nn.GroupNorm(32, in_channels) self.conv_feature = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1) self.linear_time = nn.Linear(n_time, out_channels) self.groupnorm_merged = nn.GroupNorm(32, out_channels) self.conv_merged = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1) if in_channels == out_channels: self.residual_layer = nn.Identity() else: self.residual_layer = nn.Conv2d(in_channels, out_channels, kernel_size=1, padding=0) def forward(self, feature, time): # feature: (Batch_Size, In_Channels, Height, Width) # time: (1, 1280) residue = feature # (Batch_Size, In_Channels, Height, Width) -> (Batch_Size, In_Channels, Height, Width) feature = self.groupnorm_feature(feature) feature = F.silu(feature) # (Batch_Size, In_Channels, Height, Width) -> (Batch_Size, Out_Channels, Height, Width) feature = self.conv_feature(feature) # (1, 1280) -> (1, 1280) time = F.silu(time) # (1, 1280) -> (1, Out_Channels) time = self.linear_time(time) # Add width and height dimension to time. # (Batch_Size, Out_Channels, Height, Width) + (1, Out_Channels, 1, 1) -> (Batch_Size, Out_Channels, Height, Width) merged = feature + time.unsqueeze(-1).unsqueeze(-1) # (Batch_Size, Out_Channels, Height, Width) -> (Batch_Size, Out_Channels, Height, Width) merged = self.groupnorm_merged(merged) merged = F.silu(merged) merged = self.conv_merged(merged) # (Batch_Size, Out_Channels, Height, Width) + (Batch_Size, Out_Channels, Height, Width) -> (Batch_Size, Out_Channels, Height, Width) return merged + self.residual_layer(residue) class UNET_AttentionBlock(nn.Module): def __init__(self, n_head: int, n_embd: int, d_context=768): super().__init__() channels = n_head * n_embd self.groupnorm = nn.GroupNorm(32, channels, eps=1e-6) self.conv_input = nn.Conv2d(channels, channels, kernel_size=1, padding=0) self.layernorm_1 = nn.LayerNorm(channels) self.attention_1 = SelfAttention(n_head, channels, in_proj_bias=False) self.layernorm_2 = nn.LayerNorm(channels) self.attention_2 = CrossAttention(n_head, channels, d_context, in_proj_bias=False) self.layernorm_3 = nn.LayerNorm(channels) self.linear_geglu_1 = nn.Linear(channels, 4 * channels * 2) self.linear_geglu_2 = nn.Linear(4 * channels, channels) self.conv_output = nn.Conv2d(channels, channels, kernel_size=1, padding=0) def forward(self, x, context): # x: (Batch_Size, Features, Height, Width) # context: (Batch_Size, Seq_Len, Dim) residue_long = x # (Batch_Size, Features, Height, Width) -> (Batch_Size, Features, Height, Width) x = self.groupnorm(x) x = self.conv_input(x) n, c, h, w = x.shape # (Batch_Size, Features, Height, Width) -> (Batch_Size, Features, Height * Width) x = x.view((n, c, h * w)) # (Batch_Size, Features, Height * Width) -> (Batch_Size, Height * Width, Features) x = x.transpose(-1, -2) # Normalization + Self-Attention with skip connection # (Batch_Size, Height * Width, Features) residue_short = x # (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features) x = self.layernorm_1(x) x = self.attention_1(x) # (Batch_Size, Height * Width, Features) + (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features) x += residue_short # (Batch_Size, Height * Width, Features) residue_short = x # Normalization + Cross-Attention with skip connection # (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features) x = self.layernorm_2(x) # (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features) x = self.attention_2(x, context) # (Batch_Size, Height * Width, Features) + (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features) x += residue_short # (Batch_Size, Height * Width, Features) residue_short = x # Normalization + FFN with GeGLU and skip connection # (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features) x = self.layernorm_3(x) # GeGLU as implemented in the original code: https://github.com/CompVis/stable-diffusion/blob/21f890f9da3cfbeaba8e2ac3c425ee9e998d5229/ldm/modules/attention.py#L37C10-L37C10 # (Batch_Size, Height * Width, Features) -> two tensors of shape (Batch_Size, Height * Width, Features * 4) x, gate = self.linear_geglu_1(x).chunk(2, dim=-1) # Element-wise product: (Batch_Size, Height * Width, Features * 4) * (Batch_Size, Height * Width, Features * 4) -> (Batch_Size, Height * Width, Features * 4) x = x * F.gelu(gate) # (Batch_Size, Height * Width, Features * 4) -> (Batch_Size, Height * Width, Features) x = self.linear_geglu_2(x) # (Batch_Size, Height * Width, Features) + (Batch_Size, Height * Width, Features) -> (Batch_Size, Height * Width, Features) x += residue_short # (Batch_Size, Height * Width, Features) -> (Batch_Size, Features, Height * Width) x = x.transpose(-1, -2) # (Batch_Size, Features, Height * Width) -> (Batch_Size, Features, Height, Width) x = x.view((n, c, h, w)) # Final skip connection between initial input and output of the block # (Batch_Size, Features, Height, Width) + (Batch_Size, Features, Height, Width) -> (Batch_Size, Features, Height, Width) return self.conv_output(x) + residue_long class Upsample(nn.Module): def __init__(self, channels): super().__init__() self.conv = nn.Conv2d(channels, channels, kernel_size=3, padding=1) def forward(self, x): # (Batch_Size, Features, Height, Width) -> (Batch_Size, Features, Height * 2, Width * 2) x = F.interpolate(x, scale_factor=2, mode='nearest') return self.conv(x) class SwitchSequential(nn.Sequential): def forward(self, x, context, time): for layer in self: if isinstance(layer, UNET_AttentionBlock): x = layer(x, context) elif isinstance(layer, UNET_ResidualBlock): x = layer(x, time) else: x = layer(x) return x class UNET(nn.Module): def __init__(self): super().__init__() self.encoders = nn.ModuleList([ # (Batch_Size, 4, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 8, Width / 8) SwitchSequential(nn.Conv2d(4, 320, kernel_size=3, padding=1)), # (Batch_Size, 320, Height / 8, Width / 8) -> # (Batch_Size, 320, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 8, Width / 8) SwitchSequential(UNET_ResidualBlock(320, 320), UNET_AttentionBlock(8, 40)), SwitchSequential(UNET_ResidualBlock(320, 320), UNET_AttentionBlock(8, 40)), # (Batch_Size, 320, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 16, Width / 16) SwitchSequential(nn.Conv2d(320, 320, kernel_size=3, stride=2, padding=1)), # (Batch_Size, 320, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16) SwitchSequential(UNET_ResidualBlock(320, 640), UNET_AttentionBlock(8, 80)), # (Batch_Size, 640, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16) SwitchSequential(UNET_ResidualBlock(640, 640), UNET_AttentionBlock(8, 80)), # (Batch_Size, 640, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 32, Width / 32) SwitchSequential(nn.Conv2d(640, 640, kernel_size=3, stride=2, padding=1)), # (Batch_Size, 640, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 32, Width / 32) SwitchSequential(UNET_ResidualBlock(640, 1280), UNET_AttentionBlock(8, 160)), # (Batch_Size, 1280, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 32, Width / 32) SwitchSequential(UNET_ResidualBlock(1280, 1280), UNET_AttentionBlock(8, 160)), # (Batch_Size, 1280, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 64, Width / 64) SwitchSequential(nn.Conv2d(1280, 1280, kernel_size=3, stride=2, padding=1)), # (Batch_Size, 1280, Height / 64, Width / 64) -> (Batch_Size, 1280, Height / 64, Width / 64) SwitchSequential(UNET_ResidualBlock(1280, 1280)), SwitchSequential(UNET_ResidualBlock(1280, 1280)), ]) self.bottleneck = SwitchSequential( # (Batch_Size, 1280, Height / 64, Width / 64) -> (Batch_Size, 1280, Height / 64, Width / 64) UNET_ResidualBlock(1280, 1280), UNET_AttentionBlock(8, 160), UNET_ResidualBlock(1280, 1280), ) self.decoders = nn.ModuleList([ # (Batch_Size, 2560, Height / 64, Width / 64) -> (Batch_Size, 1280, Height / 64, Width / 64) SwitchSequential(UNET_ResidualBlock(2560, 1280)), SwitchSequential(UNET_ResidualBlock(2560, 1280)), # (Batch_Size, 2560, Height / 64, Width / 64) -> (Batch_Size, 1280, Height / 64, Width / 64) -> (Batch_Size, 1280, Height / 32, Width / 32) SwitchSequential(UNET_ResidualBlock(2560, 1280), Upsample(1280)), # (Batch_Size, 2560, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 32, Width / 32) SwitchSequential(UNET_ResidualBlock(2560, 1280), UNET_AttentionBlock(8, 160)), SwitchSequential(UNET_ResidualBlock(2560, 1280), UNET_AttentionBlock(8, 160)), # (Batch_Size, 1920, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 32, Width / 32) -> (Batch_Size, 1280, Height / 16, Width / 16) SwitchSequential(UNET_ResidualBlock(1920, 1280), UNET_AttentionBlock(8, 160), Upsample(1280)), # (Batch_Size, 1920, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16) SwitchSequential(UNET_ResidualBlock(1920, 640), UNET_AttentionBlock(8, 80)), # (Batch_Size, 1280, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16) SwitchSequential(UNET_ResidualBlock(1280, 640), UNET_AttentionBlock(8, 80)), # (Batch_Size, 960, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 16, Width / 16) -> (Batch_Size, 640, Height / 8, Width / 8) SwitchSequential(UNET_ResidualBlock(960, 640), UNET_AttentionBlock(8, 80), Upsample(640)), # (Batch_Size, 960, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 8, Width / 8) SwitchSequential(UNET_ResidualBlock(960, 320), UNET_AttentionBlock(8, 40)), # (Batch_Size, 640, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 8, Width / 8) SwitchSequential(UNET_ResidualBlock(640, 320), UNET_AttentionBlock(8, 40)), SwitchSequential(UNET_ResidualBlock(640, 320), UNET_AttentionBlock(8, 40)), ]) def forward(self, x, context, time): # x: (Batch_Size, 4, Height / 8, Width / 8) # context: (Batch_Size, Seq_Len, Dim) # time: (1, 1280) skip_connections = [] for layers in self.encoders: x = layers(x, context, time) skip_connections.append(x) x = self.bottleneck(x, context, time) for layers in self.decoders: # Since we always concat with the skip connection of the encoder, the number of features increases before being sent to the decoder's layer x = torch.cat((x, skip_connections.pop()), dim=1) x = layers(x, context, time) return x class UNET_OutputLayer(nn.Module): def __init__(self, in_channels, out_channels): super().__init__() self.groupnorm = nn.GroupNorm(32, in_channels) self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1) def forward(self, x): # x: (Batch_Size, 320, Height / 8, Width / 8) # (Batch_Size, 320, Height / 8, Width / 8) -> (Batch_Size, 320, Height / 8, Width / 8) x = self.groupnorm(x) x = F.silu(x) # (Batch_Size, 320, Height / 8, Width / 8) -> (Batch_Size, 4, Height / 8, Width / 8) x = self.conv(x) # (Batch_Size, 4, Height / 8, Width / 8) return x class Diffusion(nn.Module): def __init__(self): super().__init__() self.time_embedding = TimeEmbedding(320) self.unet = UNET() self.final = UNET_OutputLayer(320, 4) def forward(self, latent, context, time): # latent: (Batch_Size, 4, Height / 8, Width / 8) # context: (Batch_Size, Seq_Len, Dim) # time: (1, 320) # (1, 320) -> (1, 1280) time = self.time_embedding(time) # (Batch, 4, Height / 8, Width / 8) -> (Batch, 320, Height / 8, Width / 8) output = self.unet(latent, context, time) # (Batch, 320, Height / 8, Width / 8) -> (Batch, 4, Height / 8, Width / 8) output = self.final(output) # (Batch, 4, Height / 8, Width / 8) return output
The TimeEmbedding class encodes time steps into a high-dimensional space, which is used to condition the model on the current timestep during the diffusion process.
Linear Layers:
self.linear_1: Projects the input time embedding from n_embd to 4 * n_embd.
self.linear_2: Projects the intermediate embedding back to 4 * n_embd.
Activation Function: SiLU (Sigmoid Linear Unit) applied after the first linear layer.
Operation: The input time embedding x of shape (1, 320) is passed through the first linear layer to produce an intermediate embedding of shape (1, 1280). The SiLU activation function is applied to the intermediate embedding. The result is passed through the second linear layer to produce the final time embedding of shape (1, 1280).
The UNET_ResidualBlock class is a residual block that processes feature maps while incorporating time embeddings.
Group Normalization:
self.groupnorm_feature: Normalizes the input feature maps.
self.groupnorm_merged: Normalizes the merged feature maps.
Convolutional Layers:
self.conv_feature: Convolves the input feature maps to produce output feature maps.
self.conv_merged: Convolves the merged feature maps to produce the final output.
Linear Layer:
self.linear_time: Projects the time embedding to match the dimensionality of the feature maps.
Residual Connection: If the input and output channels are the same, the residual connection is an identity mapping. Otherwise, a 1x1 convolution is used to match the dimensions.
Operation: The input feature maps are normalized and passed through a SiLU activation. The feature maps are convolved to produce output feature maps. The time embedding is passed through a SiLU activation and projected to match the dimensionality of the feature maps. The time embedding is added to the feature maps, and the result is normalized and convolved. The final output is the sum of the processed feature maps and the residual connection.
The UNET_AttentionBlock class integrates Self-Attention and Cross-Attention mechanisms into the UNET architecture.
Group Normalization:
self.groupnorm: Normalizes the input feature maps.
Convolutional Layers:
self.conv_input: Convolves the input feature maps.
self.conv_output: Convolves the output feature maps.
Attention Mechanisms:
self.attention_1: Self-Attention mechanism.
self.attention_2: Cross-Attention mechanism.
Feedforward Network:
self.linear_geglu_1: Projects the input to a higher-dimensional space.
self.linear_geglu_2: Projects the result back to the original dimensionality.
Layer Normalization: Applied before each attention mechanism and the feedforward network.
Operation: The input feature maps are normalized and convolved. The feature maps are reshaped and transposed to apply self-attention. The self-attention output is added to the input feature maps. The result is passed through cross-attention, where it attends to the context (e.g., text embeddings). The output of cross-attention is passed through a feedforward network with a GeGLU activation. The final output is the sum of the processed feature maps and the initial input.
The Upsample class increases the spatial resolution of the feature maps.
Convolutional Layer:
self.conv: Convolves the upsampled feature maps.
Operation: The input feature maps are upsampled using nearest-neighbor interpolation. The upsampled feature maps are convolved to produce the final output.
The SwitchSequential class is a custom sequential module that applies layers conditionally based on their type.
Operation: For each layer in the module, if the layer is an UNET_AttentionBlock, it is applied with the context. If the layer is an UNET_ResidualBlock, it is applied with the time embedding. Otherwise, the layer is applied directly to the input.
The UNET class is the core of the diffusion model, consisting of an encoder, a bottleneck, and a decoder.
Encoder: A series of SwitchSequential modules that downsample the input feature maps while increasing the number of channels.
Bottleneck: Processes the feature maps at the lowest resolution.
Decoder: A series of SwitchSequential modules that upsample the feature maps while decreasing the number of channels. Skip connections from the encoder are concatenated with the decoder's inputs.
Operation: The input feature maps are passed through the encoder, and skip connections are saved. The feature maps are processed by the bottleneck. The feature maps are passed through the decoder, with skip connections from the encoder concatenated at each step.
The UNET_OutputLayer class produces the final output of the UNET.
Group Normalization:
self.groupnorm: Normalizes the input feature maps.
Convolutional Layer:
self.conv: Convolves the feature maps to produce the final output.
Operation: The input feature maps are normalized and passed through a SiLU activation. The feature maps are convolved to produce the final output.
The Diffusion class combines the Time Embedding, UNET, and Output Layer to form the complete diffusion model.
Time Embedding: Encodes the timestep into a high-dimensional space.
UNET: Processes the latent representation and context (e.g., text embeddings) conditioned on the time embedding.
Output Layer: Produces the final output of the diffusion model.
Operation: The time embedding is computed from the input timestep. The latent representation and context are passed through the UNET, conditioned on the time embedding. The output of the UNET is passed through the output layer to produce the final result.
The major blocks are ready for the diffusion model so now we will combine them all to complete the architecture.
import torch import numpy as np from tqdm import tqdm from ddpm import DDPMSampler WIDTH = 512 HEIGHT = 512 LATENTS_WIDTH = WIDTH // 8 LATENTS_HEIGHT = HEIGHT // 8 def generate( prompt, uncond_prompt=None, input_image=None, strength=0.8, do_cfg=True, cfg_scale=7.5, sampler_name="ddpm", n_inference_steps=50, models={}, seed=None, device=None, idle_device=None, tokenizer=None, ): with torch.no_grad(): if not 0 < strength <= 1: raise ValueError("strength must be between 0 and 1") if idle_device: to_idle = lambda x: x.to(idle_device) else: to_idle = lambda x: x # Initialize random number generator according to the seed specified generator = torch.Generator(device=device) if seed is None: generator.seed() else: generator.manual_seed(seed) clip = models["clip"] clip.to(device) if do_cfg: # Convert into a list of length Seq_Len=77 cond_tokens = tokenizer.batch_encode_plus( [prompt], padding="max_length", max_length=77 ).input_ids # (Batch_Size, Seq_Len) cond_tokens = torch.tensor(cond_tokens, dtype=torch.long, device=device) # (Batch_Size, Seq_Len) -> (Batch_Size, Seq_Len, Dim) cond_context = clip(cond_tokens) # Convert into a list of length Seq_Len=77 uncond_tokens = tokenizer.batch_encode_plus( [uncond_prompt], padding="max_length", max_length=77 ).input_ids # (Batch_Size, Seq_Len) uncond_tokens = torch.tensor(uncond_tokens, dtype=torch.long, device=device) # (Batch_Size, Seq_Len) -> (Batch_Size, Seq_Len, Dim) uncond_context = clip(uncond_tokens) # (Batch_Size, Seq_Len, Dim) + (Batch_Size, Seq_Len, Dim) -> (2 * Batch_Size, Seq_Len, Dim) context = torch.cat([cond_context, uncond_context]) else: # Convert into a list of length Seq_Len=77 tokens = tokenizer.batch_encode_plus( [prompt], padding="max_length", max_length=77 ).input_ids # (Batch_Size, Seq_Len) tokens = torch.tensor(tokens, dtype=torch.long, device=device) # (Batch_Size, Seq_Len) -> (Batch_Size, Seq_Len, Dim) context = clip(tokens) to_idle(clip) if sampler_name == "ddpm": sampler = DDPMSampler(generator) sampler.set_inference_timesteps(n_inference_steps) else: raise ValueError("Unknown sampler value %s. ") latents_shape = (1, 4, LATENTS_HEIGHT, LATENTS_WIDTH) if input_image: encoder = models["encoder"] encoder.to(device) input_image_tensor = input_image.resize((WIDTH, HEIGHT)) # (Height, Width, Channel) input_image_tensor = np.array(input_image_tensor) # (Height, Width, Channel) -> (Height, Width, Channel) input_image_tensor = torch.tensor(input_image_tensor, dtype=torch.float32, device=device) input_image_tensor = rescale(input_image_tensor, (0, 255), (-1, 1)) # (Height, Width, Channel) -> (Batch_Size, Height, Width, Channel) input_image_tensor = input_image_tensor.unsqueeze(0) # (Batch_Size, Height, Width, Channel) -> (Batch_Size, Channel, Height, Width) input_image_tensor = input_image_tensor.permute(0, 3, 1, 2) # (Batch_Size, 4, Latents_Height, Latents_Width) encoder_noise = torch.randn(latents_shape, generator=generator, device=device) latents = encoder(input_image_tensor, encoder_noise) # Add noise to the latents (the encoded input image) # (Batch_Size, 4, Latents_Height, Latents_Width) sampler.set_strength(strength=strength) latents = sampler.add_noise(latents, sampler.timesteps[0]) to_idle(encoder) else: # (Batch_Size, 4, Latents_Height, Latents_Width) latents = torch.randn(latents_shape, generator=generator, device=device) diffusion = models["diffusion"] diffusion.to(device) timesteps = tqdm(sampler.timesteps) for i, timestep in enumerate(timesteps): # (1, 320) time_embedding = get_time_embedding(timestep).to(device) # (Batch_Size, 4, Latents_Height, Latents_Width) model_input = latents if do_cfg: # (Batch_Size, 4, Latents_Height, Latents_Width) -> (2 * Batch_Size, 4, Latents_Height, Latents_Width) model_input = model_input.repeat(2, 1, 1, 1) # model_output is the predicted noise # (Batch_Size, 4, Latents_Height, Latents_Width) -> (Batch_Size, 4, Latents_Height, Latents_Width) model_output = diffusion(model_input, context, time_embedding) if do_cfg: output_cond, output_uncond = model_output.chunk(2) model_output = cfg_scale * (output_cond - output_uncond) + output_uncond # (Batch_Size, 4, Latents_Height, Latents_Width) -> (Batch_Size, 4, Latents_Height, Latents_Width) latents = sampler.step(timestep, latents, model_output) to_idle(diffusion) decoder = models["decoder"] decoder.to(device) # (Batch_Size, 4, Latents_Height, Latents_Width) -> (Batch_Size, 3, Height, Width) images = decoder(latents) to_idle(decoder) images = rescale(images, (-1, 1), (0, 255), clamp=True) # (Batch_Size, Channel, Height, Width) -> (Batch_Size, Height, Width, Channel) images = images.permute(0, 2, 3, 1) images = images.to("cpu", torch.uint8).numpy() return images[0] def rescale(x, old_range, new_range, clamp=False): old_min, old_max = old_range new_min, new_max = new_range x -= old_min x *= (new_max - new_min) / (old_max - old_min) x += new_min if clamp: x = x.clamp(new_min, new_max) return x def get_time_embedding(timestep): # Shape: (160,) freqs = torch.pow(10000, -torch.arange(start=0, end=160, dtype=torch.float32) / 160) # Shape: (1, 160) x = torch.tensor([timestep], dtype=torch.float32)[:, None] * freqs[None] # Shape: (1, 160 * 2) return torch.cat([torch.cos(x), torch.sin(x)], dim=-1)
The generate function is the main pipeline for generating images from text prompts. It handles text encoding, latent space manipulation, diffusion sampling, and image decoding.
Parameters:
prompt: The text prompt for image generation.uncond_prompt: The unconditional prompt (used for classifier-free guidance).input_image: An optional input image for image-to-image translation.strength: Controls the amount of noise added to the input image (used in image-to-image translation).do_cfg: Whether to use classifier-free guidance.cfg_scale: The scale for classifier-free guidance.sampler_name: The diffusion sampler to use (e.g., DDPM).n_inference_steps: The number of diffusion steps.models: A dictionary containing the pre-trained models (CLIP, encoder, diffusion, decoder).seed: The random seed for reproducibility.device: The device (e.g., CPU or GPU) to run the computation on.idle_device: The device to move models to when they are not in use.tokenizer: The tokenizer for encoding text prompts.Text Encoding: The text prompt is tokenized and encoded into embeddings using the CLIP model. If classifier-free guidance is enabled (do_cfg=True), both the conditional and unconditional prompts are encoded, and their embeddings are concatenated.
Latent Space Initialization: If an input image is provided, it is encoded into the latent space using the encoder model. Noise is added to the latents based on the strength parameter. If no input image is provided, random noise is sampled in the latent space.
Diffusion Sampling: The diffusion model is used to iteratively denoise the latents over n_inference_steps timesteps. At each time steps, the current latents and time embedding are passed through the diffusion model to predict the noise. If classifier-free guidance is enabled, the predicted noise is adjusted using the guidance scale (cfg_scale). The latents are updated using the diffusion sampler (e.g., DDPM).
Image Decoding: The final denoised latents are decoded into an image using the decoder model. The output image is rescaled to the range [0, 255] and converted to a NumPy array.
2.1. rescale: Rescales a tensor from one range to another.
Parameters:
x: The input tensor.old_range: The original range of the tensor.new_range: The target range.clamp: Whether to clamp the output to the new range.Operation: The input tensor is shifted and scaled to fit the new range.
2.2. get_time_embedding: Generates a time embedding for a given timestep.
Parameters:
timestep: The current timestep in the diffusion process.Operation: A set of frequencies is computed using a geometric progression. The timestep is multiplied by the frequencies to produce sinusoidal embeddings.
**3.1. Text-to-Image Generation: **The text prompt is encoded into embeddings using the CLIP model. Random noise is sampled in the latent space. The diffusion model iteratively denoises the latents over n_inference_steps timesteps. The final denoised latents are decoded into an image using the decoder model.
3.2. Image-to-Image Translation: The input image is encoded into the latent space using the encoder model. Noise is added to the latents based on the strength parameter. The diffusion model iteratively denoises the latents over n_inference_steps timesteps. The final denoised latents are decoded into an image using the decoder model.
import torch import numpy as np class DDPMSampler: def __init__(self, generator: torch.Generator, num_training_steps=1000, beta_start: float = 0.00085, beta_end: float = 0.0120): # Params "beta_start" and "beta_end" taken from: https://github.com/CompVis/stable-diffusion/blob/21f890f9da3cfbeaba8e2ac3c425ee9e998d5229/configs/stable-diffusion/v1-inference.yaml#L5C8-L5C8 # For the naming conventions, refer to the DDPM paper (https://arxiv.org/pdf/2006.11239.pdf) self.betas = torch.linspace(beta_start ** 0.5, beta_end ** 0.5, num_training_steps, dtype=torch.float32) ** 2 self.alphas = 1.0 - self.betas self.alphas_cumprod = torch.cumprod(self.alphas, dim=0) self.one = torch.tensor(1.0) self.generator = generator self.num_train_timesteps = num_training_steps self.timesteps = torch.from_numpy(np.arange(0, num_training_steps)[::-1].copy()) def set_inference_timesteps(self, num_inference_steps=50): self.num_inference_steps = num_inference_steps step_ratio = self.num_train_timesteps // self.num_inference_steps timesteps = (np.arange(0, num_inference_steps) * step_ratio).round()[::-1].copy().astype(np.int64) self.timesteps = torch.from_numpy(timesteps) def _get_previous_timestep(self, timestep: int) -> int: prev_t = timestep - self.num_train_timesteps // self.num_inference_steps return prev_t def _get_variance(self, timestep: int) -> torch.Tensor: prev_t = self._get_previous_timestep(timestep) alpha_prod_t = self.alphas_cumprod[timestep] alpha_prod_t_prev = self.alphas_cumprod[prev_t] if prev_t >= 0 else self.one current_beta_t = 1 - alpha_prod_t / alpha_prod_t_prev # For t > 0, compute predicted variance βt (see formula (6) and (7) from https://arxiv.org/pdf/2006.11239.pdf) # and sample from it to get previous sample # x_{t-1} ~ N(pred_prev_sample, variance) == add variance to pred_sample variance = (1 - alpha_prod_t_prev) / (1 - alpha_prod_t) * current_beta_t # we always take the log of variance, so clamp it to ensure it's not 0 variance = torch.clamp(variance, min=1e-20) return variance def set_strength(self, strength=1): """ Set how much noise to add to the input image. More noise (strength ~ 1) means that the output will be further from the input image. Less noise (strength ~ 0) means that the output will be closer to the input image. """ # start_step is the number of noise levels to skip start_step = self.num_inference_steps - int(self.num_inference_steps * strength) self.timesteps = self.timesteps[start_step:] self.start_step = start_step def step(self, timestep: int, latents: torch.Tensor, model_output: torch.Tensor): t = timestep prev_t = self._get_previous_timestep(t) # 1. compute alphas, betas alpha_prod_t = self.alphas_cumprod[t] alpha_prod_t_prev = self.alphas_cumprod[prev_t] if prev_t >= 0 else self.one beta_prod_t = 1 - alpha_prod_t beta_prod_t_prev = 1 - alpha_prod_t_prev current_alpha_t = alpha_prod_t / alpha_prod_t_prev current_beta_t = 1 - current_alpha_t # 2. compute predicted original sample from predicted noise also called # "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf pred_original_sample = (latents - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5) # 4. Compute coefficients for pred_original_sample x_0 and current sample x_t # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * current_beta_t) / beta_prod_t current_sample_coeff = current_alpha_t ** (0.5) * beta_prod_t_prev / beta_prod_t # 5. Compute predicted previous sample µ_t # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * latents # 6. Add noise variance = 0 if t > 0: device = model_output.device noise = torch.randn(model_output.shape, generator=self.generator, device=device, dtype=model_output.dtype) # Compute the variance as per formula (7) from https://arxiv.org/pdf/2006.11239.pdf variance = (self._get_variance(t) ** 0.5) * noise # sample from N(mu, sigma) = X can be obtained by X = mu + sigma * N(0, 1) # the variable "variance" is already multiplied by the noise N(0, 1) pred_prev_sample = pred_prev_sample + variance return pred_prev_sample def add_noise( self, original_samples: torch.FloatTensor, timesteps: torch.IntTensor, ) -> torch.FloatTensor: alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype) timesteps = timesteps.to(original_samples.device) sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5 sqrt_alpha_prod = sqrt_alpha_prod.flatten() while len(sqrt_alpha_prod.shape) < len(original_samples.shape): sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1) sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5 sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten() while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape): sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1) # Sample from q(x_t | x_0) as in equation (4) of https://arxiv.org/pdf/2006.11239.pdf # Because N(mu, sigma) = X can be obtained by X = mu + sigma * N(0, 1) # here mu = sqrt_alpha_prod * original_samples and sigma = sqrt_one_minus_alpha_prod noise = torch.randn(original_samples.shape, generator=self.generator, device=original_samples.device, dtype=original_samples.dtype) noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise return noisy_samples
The DDPMSampler class implements the sampling process for a DDPM. It handles the forward (noise addition) and reverse (denoising) processes of the diffusion model.
Parameters:
generator: A random number generator for reproducibility.
num_training_steps: The total number of timesteps in the diffusion process (default: 1000).
beta_start: The starting value of the noise schedule (default: 0.00085).
beta_end: The ending value of the noise schedule (default: 0.0120).
Noise Schedule: The noise schedule is defined by the betas, which control the amount of noise added at each timestep. The betas are computed as a linearly spaced sequence between beta_start and beta_end, and then squared to ensure positivity. The alphas are defined as 1 - betas, and the cumulative product of alphas (alphas_cumprod) is computed to represent the total noise added up to each timestep.
Timesteps: The timesteps array represents the sequence of timesteps in the diffusion process. During inference, the number of timesteps can be reduced using set_inference_timesteps.
Variance Calculation: The variance for each timestep is computed using the formula from the DDPM paper. This variance is used to add noise during the reverse process.
Strength Adjustment: The set_strength method adjusts the amount of noise added to the input image. A higher strength value results in more noise, while a lower strength value results in less noise.
Forward Process (Noise Addition): The add_noise method is used to add noise to the original samples (original_samples) for a given set of timesteps. The amount of noise added is controlled by the noise schedule (alphas_cumprod).
Reverse Process (Denoising): The step method is used to iteratively denoise the latent representations (latents) over a sequence of timesteps. At each timestep, the predicted noise (model_output) is used to compute the predicted original sample (pred_original_sample). The predicted previous sample (pred_prev_sample) is computed using the predicted original sample and the current latent representation. Noise is added to the predicted previous sample based on the computed variance.
This code is used to load the pre-trained weights of stable diffusion. For this download the model_converter file.
Download the v1-5-pruned-emaonly.ckpt file from: Stable-Diffusion-V1–5/main. And download the vocab.json and merges.txt files from: Stable-Diffusion-V1–5/tokenizer.
Also we can test any fine-tuned model up to v1.5, like InkPunk Diffusion, Illstration Diffusion, Comic Diffusion, etc.
from clip import CLIP from encoder import VAE_Encoder from decoder import VAE_Decoder from diffusion import Diffusion import model_converter def preload_models_from_standard_weights(ckpt_path, device): state_dict = model_converter.load_from_standard_weights(ckpt_path, device) encoder = VAE_Encoder().to(device) encoder.load_state_dict(state_dict['encoder'], strict=True) decoder = VAE_Decoder().to(device) decoder.load_state_dict(state_dict['decoder'], strict=True) diffusion = Diffusion().to(device) diffusion.load_state_dict(state_dict['diffusion'], strict=True) clip = CLIP().to(device) clip.load_state_dict(state_dict['clip'], strict=True) return { 'clip': clip, 'encoder': encoder, 'decoder': decoder, 'diffusion': diffusion, }
The preload_models_from_standard_weights function loads the pre-trained models (CLIP, VAE Encoder, VAE Decoder, and Diffusion) from a checkpoint file and returns them as a dictionary.
Parameters:
ckpt_path: The path to the checkpoint file containing the pre-trained model weights.
device: The device (e.g., CPU or GPU) to load the models onto.
Load State Dictionary: The checkpoint file is loaded using a helper function (model_converter.load_from_standard_weights), which converts the weights into a format compatible with the models. The state dictionary contains the weights for all the models (CLIP, VAE Encoder, VAE Decoder, and Diffusion).
Initialize Models: Each model (CLIP, VAE Encoder, VAE Decoder, and Diffusion) is initialized and moved to the specified device.
Load Weights: The weights from the state dictionary are loaded into each model using load_state_dict.
Return Models: The loaded models are returned as a dictionary for easy access.
import model_loader import pipeline from PIL import Image from pathlib import Path from transformers import CLIPTokenizer import torch DEVICE = "cuda" ALLOW_CUDA = True ALLOW_MPS = False if torch.cuda.is_available() and ALLOW_CUDA: DEVICE = "cuda" elif (torch.has_mps or torch.backends.mps.is_available()) and ALLOW_MPS: DEVICE = "mps" print(f"Using device: {DEVICE}") tokenizer = CLIPTokenizer("vocab.json", merges_file="merges.txt") model_file = "v1-5-pruned-emaonly.ckpt" models = model_loader.preload_models_from_standard_weights(model_file, DEVICE) ## TEXT TO IMAGE prompt = "A cat with sunglasses, wearing comfy hat, highly detailed, ultra sharp, cinematic, 100mm lens, 8k resolution." uncond_prompt = "" # Optional: negative prompt do_cfg = True cfg_scale = 8 # min: 1, max: 14 input_image = None # No image for Text-to-Image strength = 1 # Use 1 as a default value for Text-to-Image ## IMAGE TO IMAGE image_path = "cat.jpg" # Path to input image prompt = "A cat wearing sunglasses, highly detailed, ultra sharp, cinematic, 100mm lens, 8k resolution." uncond_prompt = "" # Optional: negative prompt do_cfg = True cfg_scale = 8 # min: 1, max: 14 input_image = Image.open(image_path) strength = 0.8 # Strength to control how much transformation occurs ## SAMPLER sampler = "ddpm" num_inference_steps = 50 seed = 42 output_image = pipeline.generate( prompt=prompt, uncond_prompt=uncond_prompt, input_image=input_image, strength=strength, do_cfg=do_cfg, cfg_scale=cfg_scale, sampler_name=sampler, n_inference_steps=num_inference_steps, seed=seed, models=models, device=DEVICE, idle_device="cuda", tokenizer=tokenizer, ) output_pil = Image.fromarray(output_image) # Show the image output_pil.show() # Save the image (optional) output_pil.save("output.png")
By this we can generate images either from text prompts (text-to-image) or by modifying an existing image (image-to-image).
For image generation, define a text prompt: “A man with sunglasses, wearing a comfy hat, looking at the camera, highly detailed, ultra sharp, cinematic, 100mm lens, 8k resolution.” This prompt describes the desired image in detail. It also initializes an empty “unconditional prompt” (negative prompt), which is used in CFG-based sampling to help guide the model toward better results. The cfg_scale value is set to 8, determining how much the model should prioritize the provided prompt over randomness.
If image-to-image generation is enabled, the code loads an input image. The strength parameter, set to 0.9, controls how much noise is added to the input image. A higher strength means the final output will differ more from the original image, while a lower strength keeps the output closer to the input.
Once the image is generated, it is converted into a PIL image, displayed on the screen, and optionally saved as output.png.
Prompt for main model: “A cat with sunglasses, wearing comfy hat, highly detailed, ultra sharp, cinematic, 100mm lens, 8k resolution.”
Prompt for InkPunk: “A cat with sunglasses, cold color palette, muted colors, detailed, 8k.”
Prompt for Illustation: “A digital painting of a cat wearing sunglasses, colorful, glowing lighting, detailed.”
Prompt for Comic: “A comic book style drawing of a cat wearing sunglasses, dramatic lighting, and bold inky outlines.”


Output Image 1 is generated by v1-5-pruned-emaonly.ckpt model. Output Image 2 is generated by InkPunk Diffusion model, Output Image 3 is generated by Illustration Diffusion model and Output Image 4 is generated by Comic Diffusion model.
Prompt for main model: “A cat wearing sunglasses, highly detailed, ultra sharp, cinematic, 100mm lens, 8k resolution.”
Prompt for InkPunk: “A cat with sunglasses, cold color palette, muted colors, detailed, 8k.”
Prompt for Illustation: “A digital painting of a cat wearing sunglasses, colorful, glowing lighting, detailed.”
Prompt for Comic: “A comic book style drawing of a cat wearing sunglasses, dramatic lighting, and bold inky outlines.”


The image at top-left is the input image that is being passed with the prompt. The output image 1 is generated by v1-5-pruned-emaonly.ckpt model. The output image 2 is generated by InkPunk Diffusion model. The output image 3 is generated by Illustration Diffusion model and The output image 4 is generated by Comic Diffusion model.
The code is available in my GitHub repository.