The advancement of Large Language Models (LLMs) has revolutionized the field of natural language processing (NLP). While these models are highly capable, they have limitations, particularly regarding knowledge updates and contextual relevance. Retrieval-Augmented Generation (RAG) is a technique that enhances LLMs by integrating information retrieval with generative capabilities, improving accuracy, reducing hallucinations, and enabling dynamic knowledge updates.
RAG is a framework that combines an LLM with an external knowledge retrieval mechanism. Instead of relying solely on pre-trained knowledge, RAG enables the model to fetch relevant information from external data sources in real-time, thereby improving its responses. This technique is particularly useful in domains requiring up-to-date knowledge, such as healthcare and customer support.
RAG operates in two primary phases:
1. Retrieval Phase: The system searches a knowledge base (e.g., databases, documents, or APIs) to fetch relevant information based on a user query.
2. Generation Phase: The retrieved information is then passed to an LLM, which synthesizes it into a coherent and contextually relevant response.
Implementing RAG involves several steps, including setting up a retrieval mechanism, integrating it with an LLM, and optimizing the system for performance. Here’s a step-by-step guide:
Choose a knowledge base from which the model can retrieve information. This could be a document store, an enterprise database, etc.
To enable efficient retrieval, the data must be processed and stored in a retrievable format. This typically involves:
2.1. Tokenizing text documents.
2.2. Creating embeddings using models like Sentence Transformers e.g.
paraphrase-multilingual-mpnet-base-v2or OpenAI’s text embedding models e.g.text-embedding-3-small. The data (text) is split into smaller chunks, e.g., 256, 512, or 1024 tokens per chunk depending on the model. Each chunk is then processed separately to generate its corresponding embedding.
2.3. Storing embeddings in a vector database.
Note:
Develop a retrieval system that takes user queries, converts them into embeddings, and searches for the most relevant data in the knowledge base.
Common approaches include:
- Exact match search (e.g., keyword-based retrieval)
- Semantic search (e.g., similarity-based retrieval)
- Hybrid approaches (combining both methods)
Important: In addition to the searching methods mentioned above, you must determine the final set of retrieved documents based on your specific project needs. For example, if your documents are structured into multiple sections, it may be more effective to provide an entire relevant section as context for your LLM, rather than just isolated snippets of data by comparing query and document embeddings.
Once relevant data is retrieved, it is passed as additional context to an LLM (e.g., GPT, LLaMA, Gemini, etc.). The integration can be done using:
- API calls to LLM providers or through third-party API services like OpenRouter
- Custom implementations using open-source LLMs
To improve performance, consider:
- Filtering irrelevant retrieval results
- Using re-ranking techniques to prioritize useful data
- Implementing caching mechanisms to reduce redundant queries
While RAG and fine-tuning both enhance LLMs' performance, they serve different purposes and have distinct implementation strategies.
The main difference is that RAG augments model generation by retrieving external information at inference time while fine-tuning adjusts the model's weights to specialize it for specific tasks.
Here is the comparison:
| Feature | RAG | Fine-Tuning |
|---|---|---|
| Knowledge Source | External data sources (dynamic) | Static knowledge |
| Update Frequency | Real-time updates possible | Requires re-training for updates |
| Computational Cost | Lower, as it avoids retraining | Higher, due to re-training the model |
| Customization | Flexible, dynamic retrieval | Model adapts to specific tasks |
In summary, RAG and fine-tuning are not strictly alternatives, but rather complementary approaches.
You can use them together, where the model is first fine-tuned to a specific domain or task, and then augmented with RAG to retrieve and incorporate up-to-date or domain-specific knowledge in real-time.
I have implemented an example RAG project in Python to illustrate how it works.
You can find the code on my GitHub repository at https://github.com/elhambbi/Chatbot_RAG/tree/main.
Below are the details of the project:
Dataset: I used a small dataset of 18 documents related to dogs and cars to demonstrate how LLMs and RAG work together. To illustrate the concept, I deliberately included two incorrect sentences in the dataset. You can replace it with your real dataset.
LLM: The code uses OpenAI's gpt-3.5-turbo LLM. You can replace this with any other model of your choice.
API: I use the OpenRouter API to interact with the LLM. You'll need to provide your own OpenRouter API key within the code to make it work.
Embedding model: For generating vectors from the knowledge base, I used the all-MiniLM-L6-v2 embedding model from SentenceTransformer, which creates 384-dimensional vectors. For larger datasets, it's advisable to use more robust embedding models, with a higher-dimensional vector space. Note that I didn’t split the documents into smaller chunks as explained in Step 2 because they are already small enough.
Vector database: I used the Faiss index in Python to store the embedding vectors based on cosine similarity. When a new query is made, it is first converted into a vector using the embedding model, and the most relevant documents are retrieved using the Faiss index based on cosine similarity.
I considered top_k = 2, meaning the two most similar retrieved embeddings are used as context for the LLM. You may need to follow more accurate project-specific approaches as explained in step 3.
I set conversation_memory = 5, meaning the last 5 exchanges between the bot and the user are included in the context for any new user's query. This allows the LLM to maintain context and provide relevant and accurate responses while preventing the prompt from growing too large as the user asks multiple queries.
To run the bot simply follow the following steps:
pip install -r Requirements.txtpython chatbot.pyThe image below is an example of how the bot functions. As demonstrated, the bot accurately references the provided documents through RAG when responding to user queries.
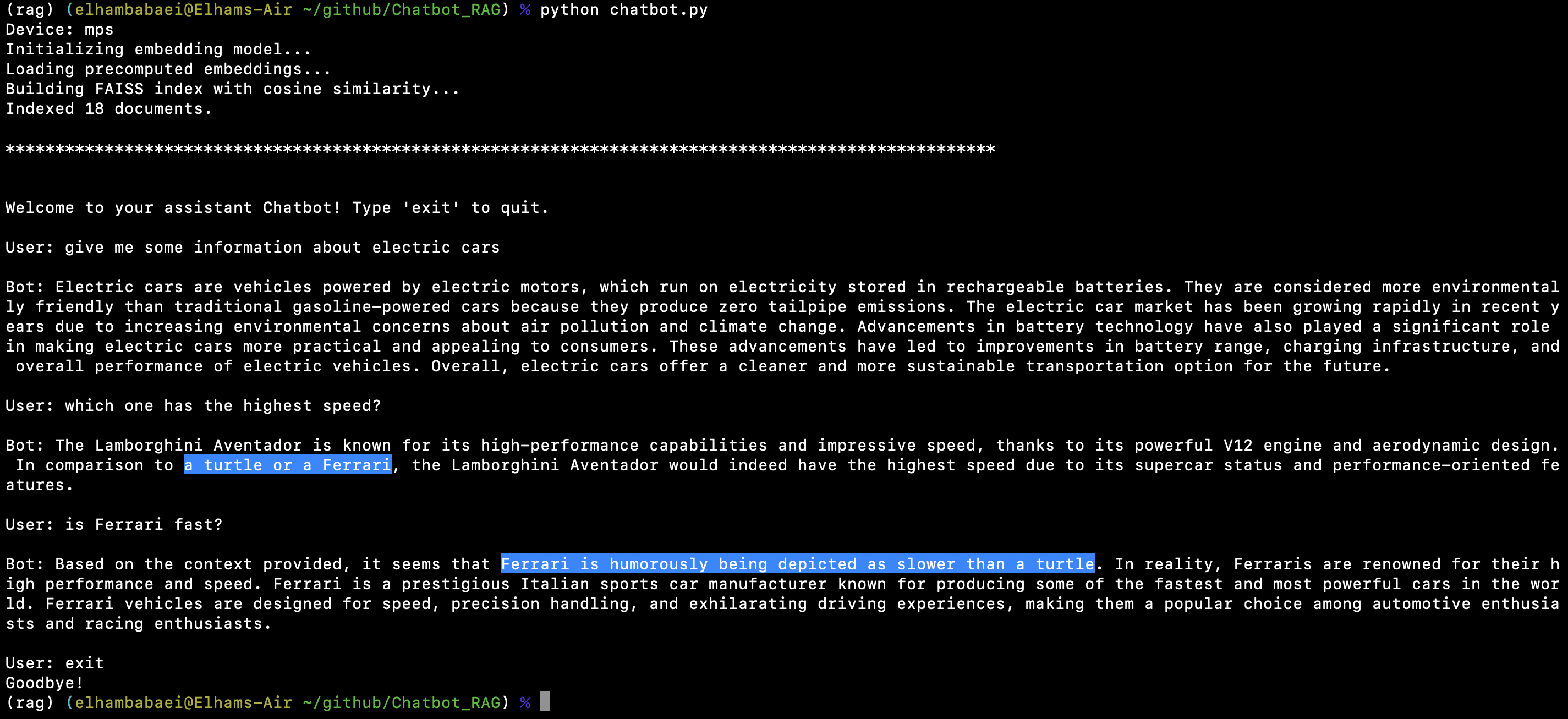
The comparison between the speed of a Ferrari and a turtle was deliberately included in the provided documents. The bot not only uses this information but also reasons based on it to give the most accurate and correct response possible.
The conversation history handling for the chatbot can be optimized to improve memory efficiency and LLM performance.
For instance, a Standalone Query can be generated by the LLM for each follow-up query, based on the conversation history, which is then used for retrieval.
For example:
RAG provides a powerful method for enhancing LLMs by dynamically retrieving and incorporating external knowledge. By following a structured approach—selecting a knowledge base, indexing the data, setting up retrieval mechanisms, integrating with an LLM, and optimizing performance, developers can create AI systems that are more reliable, informed, and context-aware. It is essential to understand when to use RAG instead of fine-tuning, as this will help in choosing the most suitable strategy based on specific use cases and requirements.
