Image Captioning with Multiple Decoder Architectures: A Comparative Study of RNN Architectures
Owen Strength
Auburn University
ods0005@auburn.edu
Jacob Simmons
Auburn University
jss0112@auburn.edu
Abstract
Image captioning is a challenging task that requires combining computer vision and natural language processing. In this project, we conduct a comprehensive comparison of different recurrent neural network (RNN) architectures for caption generation, utilizing a pretrained ResNet50 model as the image encoder. We evaluate four distinct decoder architectures: basic RNN, GRU, and LSTM, all trained on the MSCOCO dataset. Our analysis focuses on the trade-offs between these architectures in terms of performance, complexity, and computational requirements. Results demonstrate the relative advantages of each approach, with particular emphasis on the benefits of long-term memory retention in the LSTM-based model. This comparative study provides insights into the optimal choice of recurrent architecture for image captioning tasks under different constraints.
Introduction
Generating meaningful captions for images is a fundamental problem in AI that requires understanding both visual and textual modalities. Applications include accessibility tools, content moderation, and automated reporting. The sequential nature of language makes recurrent architectures a natural choice for caption generation, as they process and generate text word by word while maintaining contextual information.
While transformer-based models have shown impressive results in recent years, understanding the optimal recurrent architecture for this task remains valuable due to their efficiency and interpretability.
Objectives
Using ResNet50 as a fixed feature extractor, we evaluate three architectures with increasing complexity:
- Basic RNN: Serving as our baseline model
- GRU: Offering potentially better efficiency with moderate performance
- LSTM: Addressing long-term dependencies common in caption generation
Through systematic evaluation using BLEU, CIDEr, and METEOR metrics, we aim to determine whether more sophisticated architectures like LSTM provide meaningful improvements over simpler variants for image captioning.
Background
Image Feature Extraction
ResNet50: A deep convolutional neural network pre-trained on ImageNet, known for its ability to extract hierarchical visual features through residual connections. We utilize this as our encoder, freezing its weights to leverage transfer learning while adding a trainable embedding layer to adapt the features for caption generation.
Recurrent Architectures
Basic RNN
The simplest form of recurrent network processes sequences using a single hidden state, updating it at each time step:
where
While conceptually simple, this architecture suffers from the vanishing gradient problem during backpropagation through time (BPTT). The gradient signal diminishes exponentially as it propagates backward through time steps, making it difficult to learn long-term dependencies. This occurs because the gradient depends on repeated multiplication of the weight matrix
or exploding gradients depending on the eigenvalues of this matrix
GRU (Gated Recurrent Unit)
GRU addresses the vanishing gradient problem by introducing two gates. Key equations:
where
because:
- It combines the forget and input gates into a single update gate
- It merges the cell state and hidden state
- It requires fewer parameters and computations
LSTM (Long Short-Term Memory)
LSTM provides the most comprehensive control over information flow through three gates and a separate memory cell. Formulations include:
The LSTM’s complexity provides several advantages:
- Separate cell state (
) provides a direct pathway for gradient flow, mitigating vanishing
gradients - Independent forget gate allows explicit control over memory retention
- Output gate enables the network to maintain information in the cell state without affecting
the hidden state - Three separate gates provide fine-grained control over information flow
Dataset
MSCOCO Dataset: The Microsoft Common Objects in Context (MSCOCO) [ 5 ] dataset is a large-scale dataset designed for multiple computer vision tasks including image captioning. It contains over 330,000 images with 5 human-annotated captions per image, providing a rich and diverse range of scenes and descriptions. We utilize the 2017 training split which consists of 118,287 images for training and 5,000 images for validation.
The dataset’s key characteristics make it particularly suitable for image captioning:
- High-quality annotations with multiple captions per image, capturing different human perspectives
- Complex scenes containing multiple objects in their natural context
- Diverse vocabulary with over 30,000 unique words in the captions
- Wide range of visual scenarios including indoor/outdoor scenes, human activities, and object interactions
For our experiments, we use the Karpathy splits, a widely adopted configuration in the image
captioning community that provides 113,287 training images, 5,000 validation images, and 5,000 test images. Each image is preprocessed using standard transformations including resizing to 256x256 pixels, random cropping to 224x224, horizontal flipping for augmentation, and normalization using ImageNet statistic
Methodology
Architecture Overview
Figure 1: Image Captioning Architecture
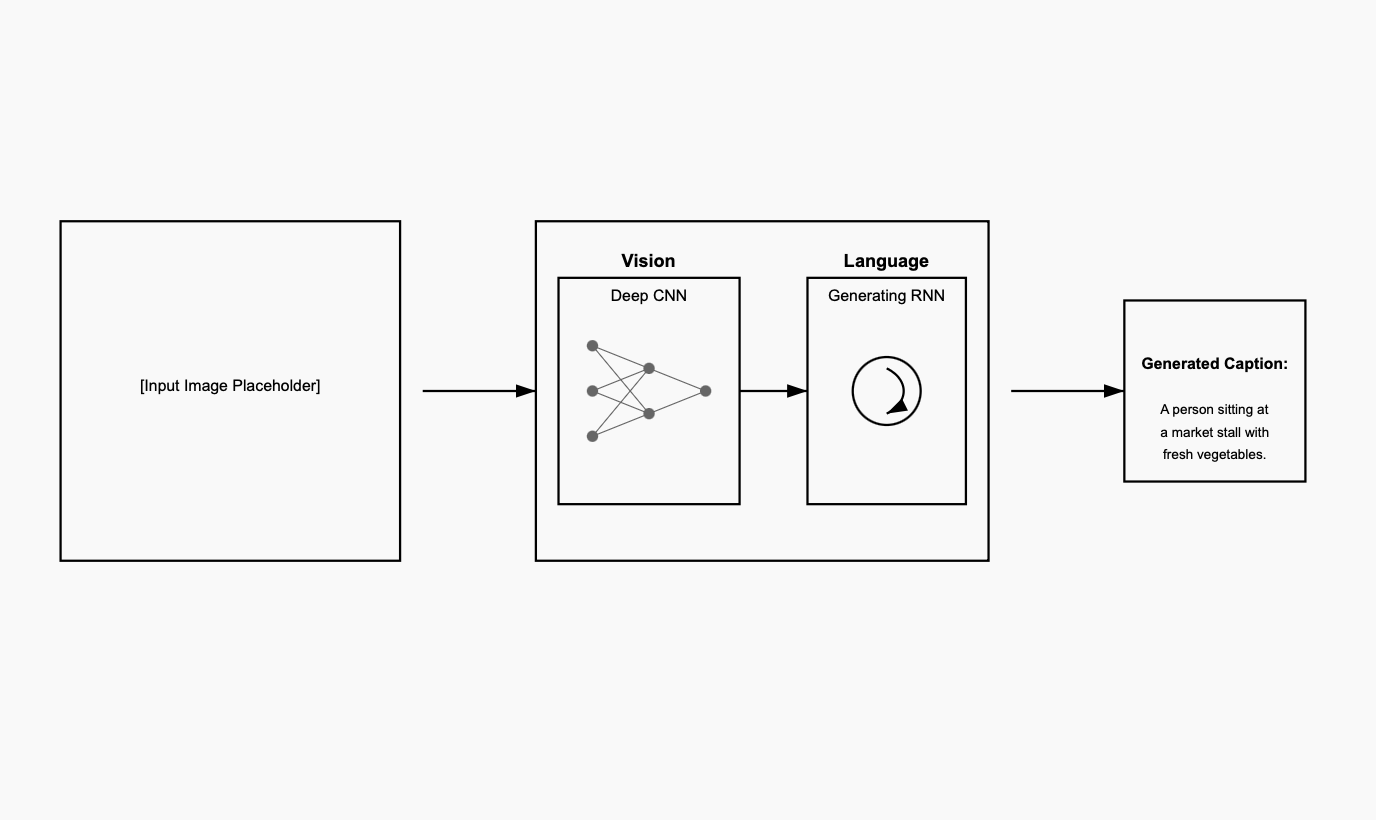
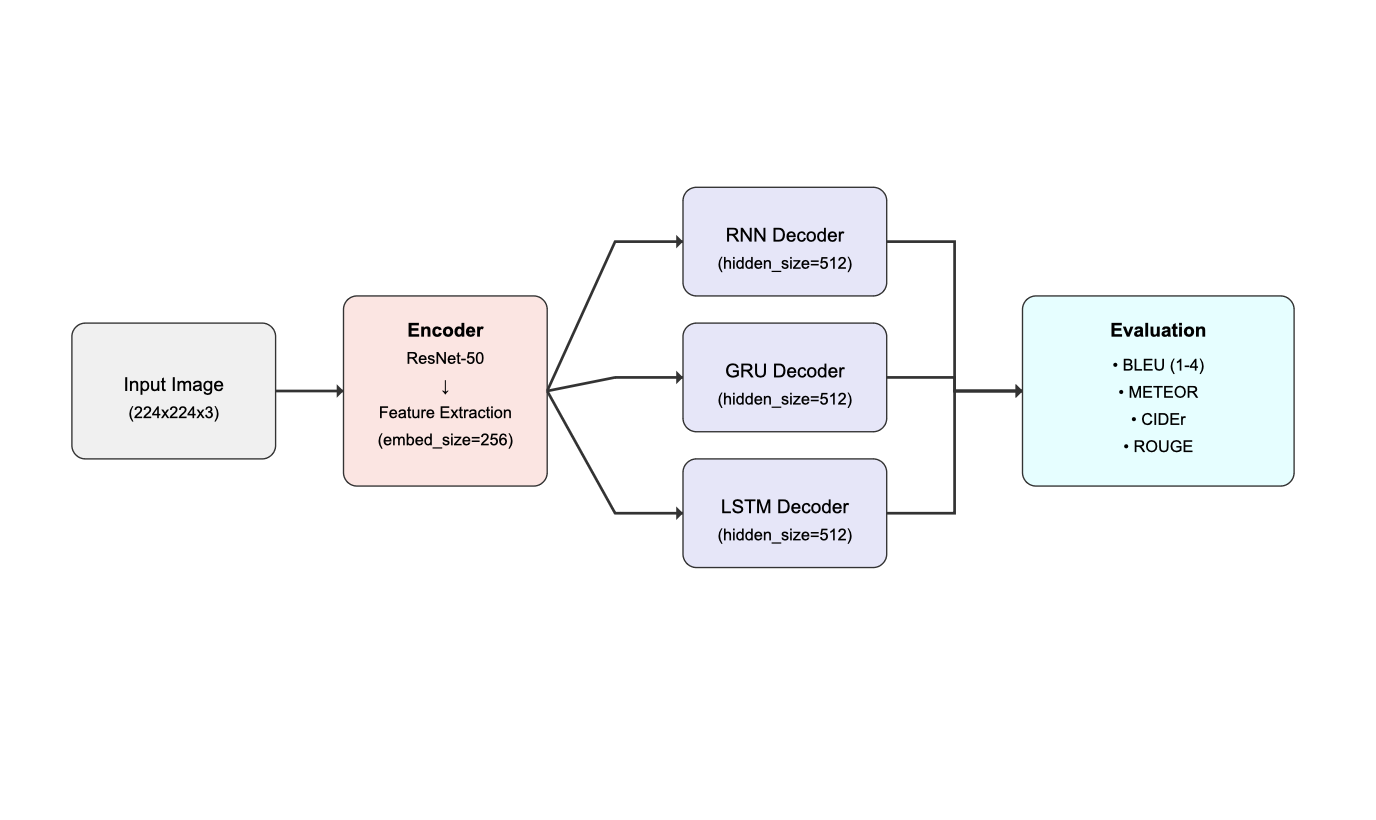
Figure 2: Decoder Architectures
Our system consists of two main components:
-
Encoder (ResNet50):
- Pretrained weights frozen to preserve ImageNet knowledge
- Trainable embedding layer (size: 256)
-
Decoder Variants:
- Embedding layer for word tokens (size: 256)
- Hidden size of 512 units
- Single-layer architecture
- Output layer mapping to vocabulary size
Model Architectures
Basic RNN
- Simple recurrent layer
- Tanh activation function
GRU
- Update and reset gates
- Improved gradient flow
LSTM
- Separate memory cell
- Input, forget, and output gates
Training Protocol
Our training configuration was carefully selected to balance model performance and computational constraints. We employed the Adam optimizer with a learning rate of 1e-3, chosen for its adaptive learning rate properties and consistent performance in similar vision-language tasks. Cross-entropy loss was selected as our objective function due to its effectiveness in classification tasks and caption generation. We set the batch size to 128, which maximized GPU memory utilization while maintaining stable training dynamics. The models were trained for 5 epochs each, with each epoch taking approximately 50 minutes on either an NVIDIA A6000 GPU or a MacBook Pro M3 Pro with 36GB unified memory. This training duration proved sufficient for model convergence while remaining computationally feasible. For data augmentation, we implemented random horizontal flips and the standard ResNet preprocessing pipeline of resizing images to 256x256 followed by random crops to 224x224, maintaining consistency with the pretrained ResNet50's training regime.
Hyperparameter Tuning
Our hyperparameter selection was primarily guided by the seminal "Show and Tell'' paper by Google [7]. Following their successful architecture, we adopted their core hyperparameters: a learning rate of 1e-3, embedding dimension of 256, hidden size of 512, and a single layer for our recurrent networks. The vocabulary size was determined by our tokenizer's vocabulary. While the original paper explored various configurations, we found these parameters provided a strong baseline for our implementation.
Evaluation and Results
We evaluate our models using standard metrics in image captioning:
BLEU (Bilingual Evaluation Understudy): Measures similarity between generated and reference captions by comparing overlapping word sequences of varying lengths (n-grams), from single words (BLEU-1) to four-word sequences (BLEU-4) [Papineni et al., 2002]. This metric evaluates the precision of word matches, with BLEU-4 being the standard reported score as it better captures phrase-level accuracy.
CIDEr (Consensus-based Image Description Evaluation): Measures consensus in generated captions, weighing n-grams by TF-IDF scores [Vedantam et al., 2015]. This metric focuses on capturing the importance of specific words in the image context, making it particularly effective for evaluating the relevance of generated captions.
METEOR (Metric for Evaluation of Translation with Explicit ORdering): Measures similarity between captions by aligning words based on exact matches, stems, and synonyms, with additional consideration for word order [Banerjee and Lavie, 2005]. This metric often correlates better with human judgments than pure n-gram based approaches.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Measures the overlap between generated captions and reference captions by comparing both consecutive word matches and in-sequence matches [Lin, 2004]. This metric focuses on recall and is particularly sensitive to shared word sequences, making it effective for evaluating the completeness of generated captions.
Table 1: BLEU, CIDEr, and METEOR Metrics
| Metric | GRU | LSTM | Naive RNN |
|---|---|---|---|
| BLEU-1 | 63.5 | 66.3 | 64.7 |
| BLEU-2 | 43.3 | 45.4 | 42.7 |
| BLEU-3 | 30.0 | 31.7 | 29.1 |
| BLEU-4 | 20.8 | 22.0 | 20.1 |
| CIDEr | 66.1 | 68.7 | 60.8 |
| METEOR | 43.1 | 43.6 | 40.7 |
| ROUGE | 50.0 | 50.9 | 49.2 |
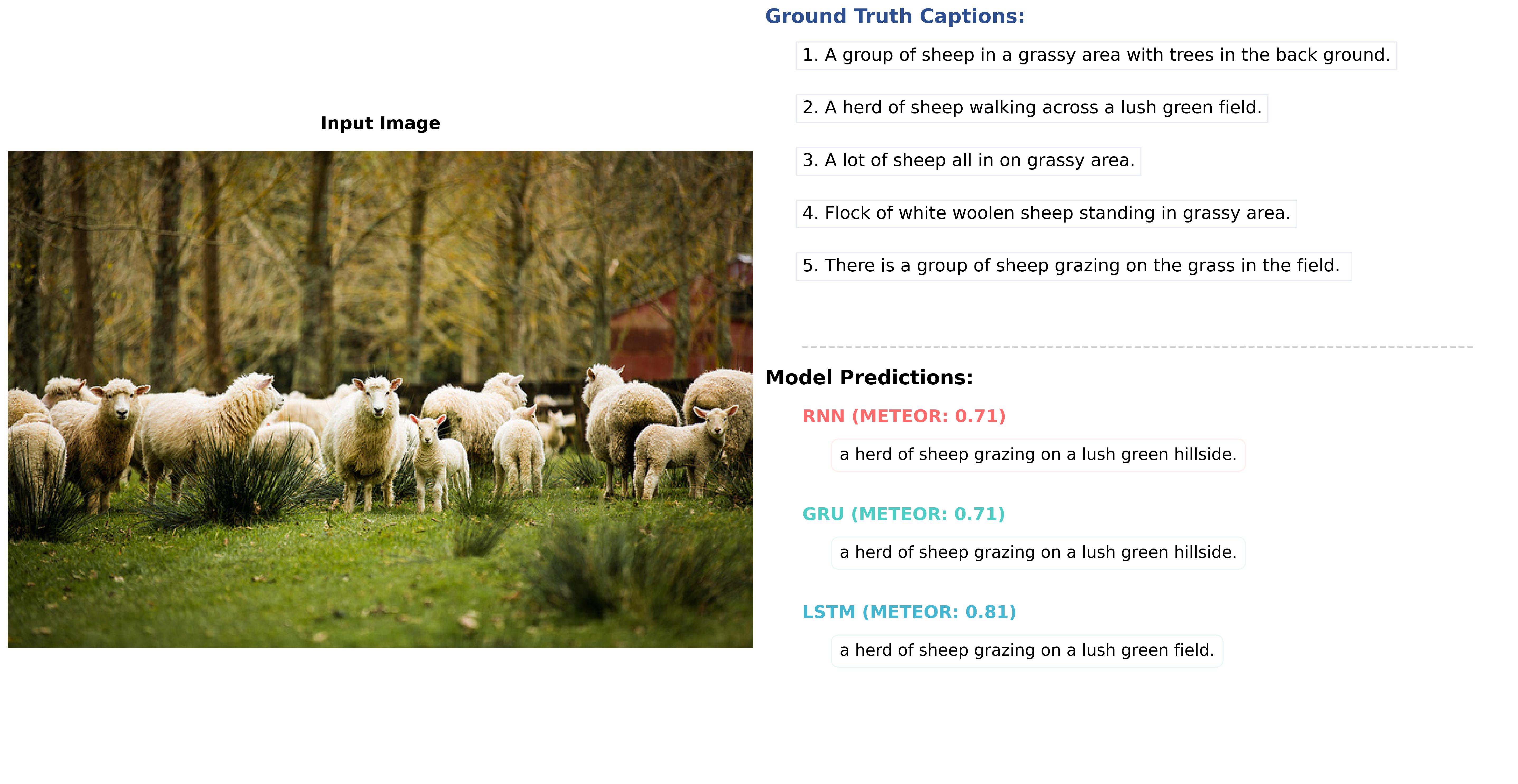
Figure 3: Sample Output

Figure 4: Sample Output

Figure 5: Sample Output
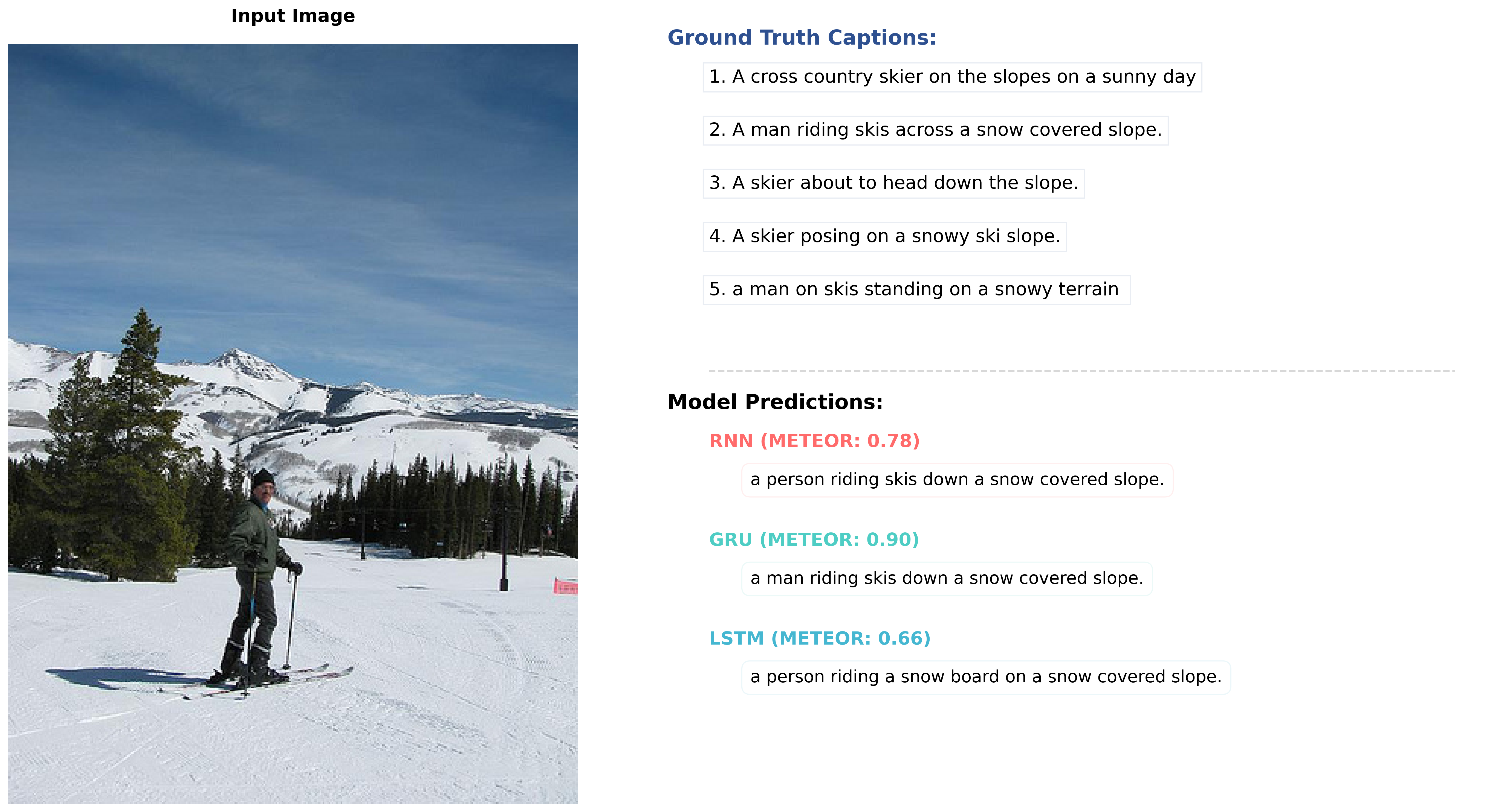
The performance of different decoder architectures for image captioning using a ResNet encoder is summarized in Table. The results indicate that the LSTM decoder achieves the best scores across all metrics, including BLEU, CIDEr, METEOR, and ROUGE. This highlights the effectiveness of LSTM in generating high-quality captions.
However, it is noteworthy that the GRU decoder performs very close to the LSTM in all metrics. For instance, the BLEU-4 score for the GRU is 20.8 compared to 22.0 for the LSTM, and the CIDEr score for the GRU is 66.1 versus 68.7 for the LSTM. The METEOR and ROUGE scores also show minimal differences between the two architectures.
Given that GRU is computationally simpler and requires fewer parameters compared to LSTM, its performance makes it an attractive alternative in scenarios where computational efficiency is a priority. The Naive RNN decoder, while functional, lags behind both the GRU and LSTM in every metric, highlighting its limitations in this context.
Conclusion
In this work, we explored different recurrent neural network architectures for image captioning, implementing and comparing Naive RNN, LSTM, and GRU models. We also attempted to implement an attention mechanism with LSTM [8], though this model did not converge during training. The attention mechanism was designed to allow the model to focus on different parts of the image features while generating each word, potentially enabling more precise and contextually relevant captions. While the theoretical benefits of attention are well-documented in literature, getting such models to converge often requires careful hyperparameter tuning and longer training times than were available for this project.
Our experimental results showed that the LSTM model achieved the best performance metrics, followed closely by the GRU model, while the Naive RNN performed notably worse. This aligns with theoretical expectations, as both LSTM and GRU are designed to handle the vanishing gradient problem that plagues simple RNNs. This allows them to better capture long-term dependencies in sequential data. The LSTM's superior performance can be attributed to its more sophisticated gating mechanism, which allows for better control over information flow through the network.
However, when considering the trade-off between performance and model complexity, the GRU is a particularly attractive option. The GRU model offers an excellent balance of efficiency and effectiveness with fewer parameters and a simpler architecture than LSTM, but nearly matching performance. This makes it potentially the best choice for practical applications where computational resources may be limited.
Future work could focus on successfully implementing the attention mechanism, which would require more extensive hyperparameter optimization and training time. Additionally, exploring more recent architectures like Transformers could provide interesting comparisons to these traditional recurrent approaches. The integration of pre-trained vision models for feature extraction could also potentially improve the quality of the generated captions across all architectures.
References
[1]S. Banerjee and A. Lavie. METEOR: An automatic metric for MT evaluation with improved
correlation with human judgments. In J. Goldstein, A. Lavie, C.-Y. Lin, and C. Voss, editors,
Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine
Translation and/or Summarization, pages 65–72, Ann Arbor, Michigan, June 2005. Association
for Computational Linguistics.
[2]J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical
image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages
248–255, 2009.
[3]K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition.CoRR,
abs/1512.03385, 2015.
[4]C.-Y. Lin. ROUGE: A package for automatic evaluation of summaries. InText Summariza-
tion Branches Out, pages 74–81, Barcelona, Spain, July 2004. Association for Computational
Linguistics.
[5]T. Lin, M. Maire, S. J. Belongie, L. D. Bourdev, R. B. Girshick, J. Hays, P. Perona, D. Ramanan,
P. Dollár, and C. L. Zitnick. Microsoft COCO: common objects in context.CoRR, abs/1405.0312,
2014.
[6]K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu. Bleu: a method for automatic evaluation of
machine translation. In P. Isabelle, E. Charniak, and D. Lin, editors,Proceedings of the 40th
Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia,
Pennsylvania, USA, July 2002. Association for Computational Linguistics.
[7]O. Vinyals, A. Toshev, S. Bengio, and D. Erhan. Show and tell: A neural image caption generator.
CoRR, abs/1411.4555, 2014.
[8]K. Xu, J. Ba, R. Kiros, K. Cho, A. C. Courville, R. Salakhutdinov, R. S. Zemel, and Y. Ben-
gio. Show, attend and tell: Neural image caption generation with visual attention. CoRR,
abs/1502.03044, 2015.