1. Abstract
This is a Deep Learning Model for generating captions for images. It uses techniques from Computer Vision and Natural Language Processing. Some examples of images from test dataset and the captions generated by the model are shown below.

2. Introduction
Deep Learning and Neural Networks have found profound applications in both NLP and Computer Vision. Before the Deep Learning era, statistical and Machine Learning techniques were commonly used for these tasks, especially in NLP. Neural Networks however have now proven to be powerful techniques, especially for more complex tasks. With the increase in size of available datasets and efficient computational tools, Deep Learning is being throughly researched on and applied in an increasing number of areas.Image captioning is the process of taking an image and generating a caption that accurately describes the scene. This is a difficult task for neural networks because it requires understanding both natural language and computer vision. It is the intersection between NLP and Computer Vision.

The purpose of your image captioning project is to develop a system that can generate descriptive captions for images. The primary objective is to automate the process of generating accurate and meaningful textual descriptions that capture the visual content and context of the images.

3. Related work
3.1 Dataset
This project uses the Flickr 8K dataset for training the model. This can be downloaded from here. It contains 8000 images, most of them featuring people and animals in a state of action.Though i have used two more dataset like Flickr 8K and Microsoft CoCo but flickr 8k comparatively doing well from among datasets.Here Each image is provided with five different captions describing the entities and events depicted in the image. Different captions of the same image tend to focus on different aspects of the scene, or use different linguistic constructions. This ensures that there is enough linguistic variety in the description of the images.
4. Used Model
In this project i used several models like vgg16 with lstm,resnet50 with lstm, inception v3 with lstm but considering everything i deployed vgg16 with lstm for my convenience the Vgg16 architecture for obtaining the image features. VGG networks, standing for Visual Geometry Group networks, have played a pivotal role in the realm of Computer Vision. Their significance was highlighted when they secured victory in the prestigious ImageNet Challenge. VGG networks demonstrated a groundbreaking concept—how even deep neural networks (VGG16 and VGG19 are examples) can be effectively trained, transcending the limitations of the vanishing gradient problem.
The hallmark of VGG networks is their simplicity and uniformity. Unlike the original ResNet with its 152 layers, VGG networks feature a straightforward and easily understandable architecture. This simplicity, combined with their effectiveness, makes them a popular choice for various computer vision tasks.
In the world of Transfer Learning, VGG networks shine brightly. Keras, a widely-used deep learning framework, includes pre-trained VGG models along with weights fine-tuned on the expansive ImageNet dataset. This availability has made VGG networks a go-to choice for researchers and practitioners in the field. Since we only need this network for getting the image feature vectors, so we remove the last layer.
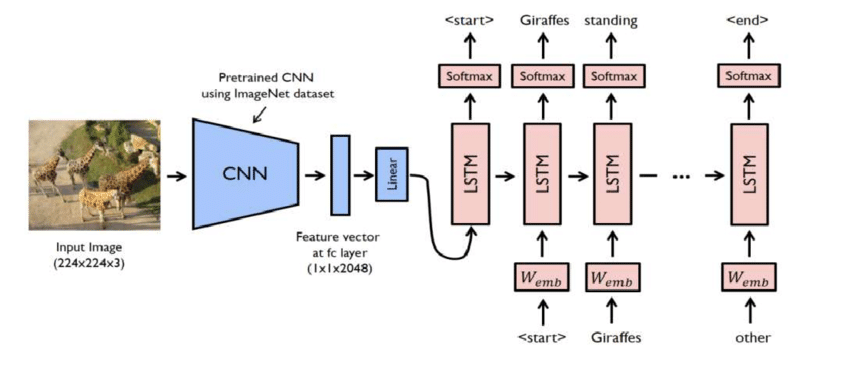
5. Experiments
| Models | Accuracy | BLEU-1 | BLEU-2 |
|---|---|---|---|
| Vgg 16 with Lstm | 0.5125 | 0.540437 | 0.316454 |
| Resnet 50 with Lstm | 0.5522 | 0.538153 | 0.321559 |
| InceptionV3 with Lstm | 0.5012 | 0.545291 | 0.323035 |
6. Prediced Results
| Image | Caption |
|---|---|
 | Generated Caption: Surfer rides the waves. |
 | Generated Caption: Woman in green shirt and glasses is climbing large rock. |
 | Generated Caption: Dog jumps over hurdle. |
 | Generated Caption: Man in blue jacket snowboarding. |
 | Generated Caption: Basketball player dribbles the ball. |
7. Discussion
7.1 Used Frameworks, Libraries & Languages
- Keras
- Tensorflow
- Python3
- Numpy
- Matplotlib
- pickle
7.2 Deployment
I made a web application using streamlit framework. This web application is hosted and deployed on shere.streamlit platforms: share.streamlit.io and the implementation can be found in this Github repository.
7.3 Demo Video
8. Conclusion
8.1 Limitations
This image caption generator application shows promise but currently faces challenges in generating accurate captions due to factors such as limited computational resources, a relatively small dataset, occasional GPU issues, and memory constraints. However, I am committed to making continuous improvements and enhancements to enhance its performance in the future as well as i made this project using a LLM model called Gemini-Pro-Vision you can check out this Github repository which has more accurate prediction. If you have any suggestions regarding this feel free to send me pull request.
9. Acknowledgements
I referred many articles & research papers while working on this project. Some of them are listed below-
- https://www.analyticsvidhya.com/blog/2021/12/step-by-step-guide-to-build-image-caption-generator-using-deep-learning/
- https://data-flair.training/blogs/python-based-project-image-caption-generator-cnn/
- https://towardsdatascience.com/understanding-and-coding-a-resnet-in-keras-446d7ff84d33
- https://www.hackersrealm.net/post/image-caption-generator-using-python
10. Appendix
10.1 Code Snippets
Include key code snippets or scripts that are integral to my project over here, such as:
Preprocessing the dataset.
Model architecture and training process.
Evaluation metrics and calculation of BLEU scores.
Deployment scripts for the Streamlit application.
10.2 Dataset Details
Provide a detailed description of the datasets used (Flickr 8K, Flickr 30K, and MS COCO):
Number of images.
Source and link to download.
Sample captions for a few images.
10.3 Hyperparameters
Document the hyperparameters used during training, such as:
Learning rate.
Batch size.
Epochs.
Optimizer.
10.4 Results Logs
Provide raw logs or outputs from model training, validation, and testing phases, such as:
Training accuracy and loss plots.
BLEU score logs.
10.5 Challenges and Limitations
List the challenges encountered, such as:
GPU or memory constraints.
Dataset size limitations.
Model overfitting or underfitting issues.
10.6 Screenshots of the Application
Add screenshots of the deployed web application, demonstrating its features and functionality.
10.9 Acknowledgments
Include a detailed acknowledgment.