In this notebook, we will explore the practical implementations of some primal CV tasks like image classification, image segmentation, and object detection using modern computer vision techniques leveraging some popular pre-trained models.
By the end of this session, you will be able to:
To ensure participants can fully engage and benefit from this workshop, the following are recommended:
Basic Understanding of Python:
Familiarity with Python programming, including syntax, data structures, and basic libraries like numpy and matplotlib.
Google Account:
You'll need a Google account to access and run the Colab notebook we'll be using during the webinar.
Basic Understanding of Deep Learning:
No advanced expertise needed, but a basic grasp of how CNNs process images would be helpful.
All required libraries and dependencies are pre-installed in the Colab environment.
📝 To follow along with this webinar:
The presentation slides used in this webinar are also available in the Resources section as "Ready Tensor Computer Vision Webinar.pdf".
We recommend using the Colab notebook during the code review section for the smoothest experience!
Now, let's dive into computer vision!
Image classification is the task of identifying what's in an image by assigning it a label from a set of predefined categories. For example, determining if a photo contains a dog, cat, car, or person.
When implementing image classification, you have several approaches:
For most real-world applications, using pre-trained models (approach #2) is the smart choice. These models have already learned to recognize a wide variety of visual features, allowing you to:
In this tutorial, we'll use a pre-trained model to classify images. If you're interested in training a model on your own dataset, check out the resources section for a detailed guide on transfer learning and fine-tuning.
Let's get started! 👇
Importing the Libraries
import tensorflow as tf import matplotlib.pyplot as plt import glob as glob import os import cv2 import random import json import numpy as np from PIL import Image
Accessing the Data
base_dataset_path = os.path.join("WebinarContent", "Datasets") classification_data_samples = "ImageClassification" images = os.path.join(base_dataset_path, classification_data_samples) image_paths = [os.path.join(base_dataset_path, classification_data_samples, x) for x in os.listdir(images) ] # Sort files for consistent ordering image_paths.sort()
Visualizing Test Sample
We will use the French Bulldog image for prediction. Let's load and display it.
plt.figure(figsize=(8,4)) image = plt.imread(image_paths[2]) plt.imshow(image) plt.axis("off")

InceptionV3, introduced by Google in 2015, is a successor to InceptionV1 and V2. It is a convolutional neural network designed for high accuracy in image classification while being computationally efficient. The model uses convolutional, pooling, and inception modules, with inception blocks enabling the network to learn features at multiple scales using filters of varying sizes.
Before we move ahead let's take a look at the images the model has been trained on.
Accessing Inception V3 Model Labels
class_index_file = "WebinarContent/ModelConfigs/imagenet_class_index_file.json" with open(class_index_file, 'r') as f: class_mapping = json.load(f)
class_names = [class_mapping[str(i)][1] for i in range(len(class_mapping))] print(f"Total Classes: {len(class_names)}")
> Total Classes: 1000
Visualization of The Classes
random.shuffle(class_names) num_rows, num_cols = 2, 3 fig, ax = plt.subplots(num_rows, num_cols, figsize=(7, 2.5)) fig.suptitle("Sample ImageNet Classes", fontsize=12) for i, ax in enumerate(ax.flat): if i < len(class_names[:6]): ax.text(0.5, 0.5, class_names[i], ha='center', va='center', fontsize=10) ax.set_xticks([]) ax.set_yticks([]) else: ax.axis('off')
InceptionV3 was trained on the ImageNet dataset, a large-scale dataset commonly used for image classification tasks, with categories ranging from animals and plants to everyday objects and scenes, which consists of over 1.2 million labeled images across 1,000 categories.
from tensorflow.keras.applications import InceptionV3 from tensorflow.keras.applications.inception_v3 import preprocess_input
inception_v3_model = InceptionV3(weights='imagenet')
Model Input Size Check
Knowing the image shape is crucial for preprocessing, model compatibility, resource management (memory), and ensuring the model performs optimally with the given data.
Model Compatibility: Most models, including InceptionV3, expect input images of a specific shape (e.g., 299x299x3 for InceptionV3). If the images fed into the model don't match this expected shape, the model will throw an error. Therefore, knowing the image shape ensures that the images are preprocessed correctly to fit the model’s requirements.
Data Preprocessing: Knowing the expected input shape helps in resizing images properly. If an image is too large or too small, resizing it to the required dimensions is necessary for consistent model performance.
Memory and Computational Efficiency:: The shape of the image affects the amount of memory required to store the data. Larger images (higher resolution) require more memory. For instance, images of shape (299, 299, 3) will take up less memory than images of shape (512, 512, 3)
print(inception_v3_model.input_shape)
> (None, 299, 299, 3)
Here, the input shape (None, 299, 299, 3) means the InceptionV3 model expects input images of size 299x299 pixels with 3 color channels (RGB). This shape is consistent with the pre-trained InceptionV3 model, which is designed to work with color images resized to 299x299 pixels.
image_paths[0] > Datasets\ImageClassification\FrenchBullDog.jpg
tf_image = tf.io.read_file(image_paths[0]) #reading image decoded_image = tf.image.decode_image(tf_image) # decode the image into a tensor image_resized = tf.image.resize(decoded_image, inception_v3_model.input_shape[1:3]) # resizing the image to match the expected input shape of the model image_batch = tf.expand_dims(image_resized, axis = 0) # add an extra dimension to the image image_batch = preprocess_input(image_batch) #preprocess the image to match the input format
model_prediction = inception_v3_model(image_batch) decoded_model_prediction = tf.keras.applications.imagenet_utils.decode_predictions( preds = model_prediction, top = 1 ) print("Predicted Result: {} with confidence {:5.2f}%".format( decoded_model_prediction[0][0][1],decoded_model_prediction[0][0][2]*100)) plt.imshow(Image.open(image_paths[0])) plt.axis('off') plt.show()

Oops ! Here the sunglasses overruled :(.
But we can always use a model more specialized for our use case!
When a pre-trained model doesn't deliver satisfactory results for your specific use case, one option is to fine-tune the model or explore other sources that provide fine-tuned models.
Fine-tuning allows you to adapt a model trained on large datasets to perform better on your specific data by updating only the last few layers of the model.
Here are some sources you can utilize:
Let's try using one of the fine-tuned models for our purpose.
from transformers import AutoImageProcessor, AutoModelForImageClassification
image_processor = AutoImageProcessor.from_pretrained("jhoppanne/Dogs-Breed-Image-Classification-V2") model = AutoModelForImageClassification.from_pretrained("jhoppanne/Dogs-Breed-Image-Classification-V2")
This model is a fine-tuned version of microsoft/resnet-152 on the Stanford Dogs dataset, achieving:
Loss: 1.0115
Accuracy: 84.08 %
Source : Model Source
image = Image.open("WebinarContent/Datasets/ImageClassification/FrenchBullDog.jpg") inputs = image_processor(images=image, return_tensors="pt") outputs = model(**inputs) logits = outputs.logits predicted_class_idx = logits.argmax(-1).item() print(f"Predicted class: {model.config.id2label[predicted_class_idx]}.") plt.imshow(image)
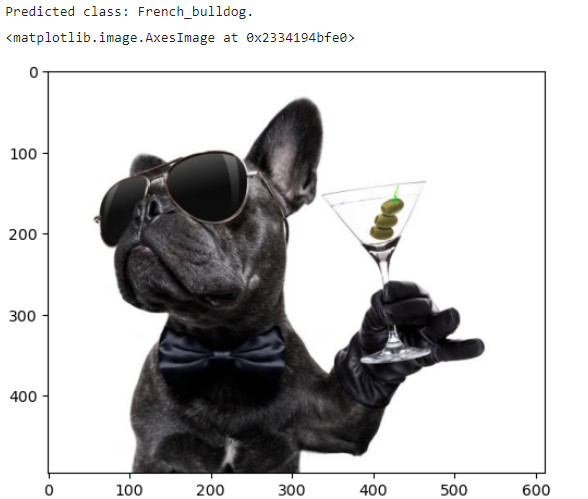
There you go! Just what we needed :)
Object Detection is a computer vision task that involves identifying and localizing objects within an image or video. It not only classifies objects but also uses bounding boxes to pinpoint their positions.
Key Components:
Lets try using the YOLO (a pretrained) model from UltraLytics for our object detection task
Why Use YOLO from Ultralytics?
Ultralytics YOLO models are optimized for fast and accurate inferencing, ideal for real-time tasks like object detection and segmentation. Pre-trained models can be deployed on edge devices and support formats like ONNX and TensorFlow Lite for versatile usage. So, we look forward to leveraging it.
Loading Libraries
#!pip install ultralytics
Loading the YOLO Module
from ultralytics import YOLO
yolo11_model = YOLO(os.path.join("WebinarContent", "Models", "yolov11m.pt"))
Visualization of The Classes
yolo11_classes = yolo_classes = list(yolo11_model.names.values()) random.seed(0) random.shuffle(yolo11_classes) num_rows, num_cols = 3, 6 fig, ax = plt.subplots(num_rows, num_cols, figsize=(8, 2)) fig.suptitle("Sample Yolo11 Classes", fontsize=12) for i, ax in enumerate(ax.flat): if i < len(yolo11_classes[:18]): ax.text(0.5, 0.5, yolo11_classes[i], ha='center', va='center', fontsize=8) ax.set_xticks([]) ax.set_yticks([]) else: ax.axis('off')
Visualizing Test Sample
We will use a road traffic image for object detection. Let's visualize it first.
test_image_path = "/content/WebinarContent/Datasets/ObjectDetection/roadTraffic.png"
test_image = Image.open(test_image_path) ig, ax = plt.subplots() ax.imshow(test_image)

results = yolo11_model.predict(test_image_path)
image 1/1 WebinarContent\Datasets\ObjectDetection\roadTraffic.png: 352x640 3 persons, 8 cars, 339.6ms
Speed: 4.0ms preprocess, 339.6ms inference, 2.0ms postprocess per image at shape (1, 3, 352, 640)
print(f"The number of objects detected in the image is:{len(results[0].boxes)}")
The number of objects detected in the image is: 11
prediction_ccordinates = [] predictions = [] for box in results[0].boxes: class_id = results[0].names[box.cls[0].item()] predictions.append(class_id) cords = box.xyxy[0].tolist() cords = [round(x) for x in cords] prediction_ccordinates.append(cords) conf = round(box.conf[0].item(), 2)
fig, ax = plt.subplots() ax.imshow(test_image) for i, bbox in enumerate(prediction_ccordinates): rect = plt.Rectangle((bbox[0], bbox[1]), bbox[2] - bbox[0], bbox[3] - bbox[1], linewidth=2, edgecolor='r', facecolor='none') ax.add_patch(rect) ax.text(bbox[0], bbox[1] - 10, f'{predictions[i]}', color='b', fontsize=6, backgroundcolor='none') plt.show()
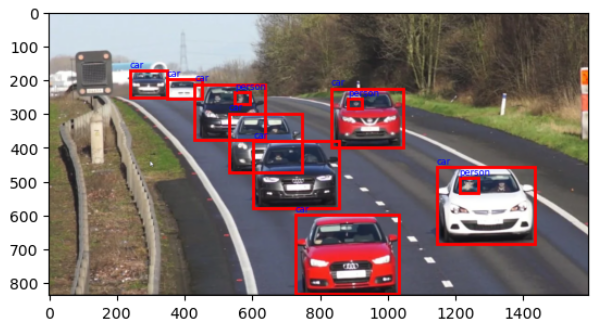
This way using a pre-trained YOLOv8 model for car detection in traffic management we can gain several benefits:
Automatic Traffic Analysis: It can count the number of vehicles, detect traffic jams, and measure the speed of cars, enabling smart traffic lights and dynamic traffic management.
Parking Management: YOLOv8 can help in detecting available parking spots by identifying parked cars in parking lots, improving the user experience in urban areas.
And more
These applications can significantly enhance traffic management, improve road safety, and optimize urban planning.
Let's try to take a level up next !
This is an advanced use case where the model is applied to segment objects in an image, rather than just detecting them. Unlike traditional object detection, segmentation involves classifying each pixel in an image, allowing precise boundaries for objects like cars, people, or building.
The training of Object Detection and Image Segmentation models differs mainly in the output and data requirements. Object detection models, like YOLO, produce bounding boxes around objects and assign class labels, requiring annotations that specify object locations. Segmentation models, like YoloV8-Seg, generate pixel-wise masks, assigning a class to each pixel in the image, requiring more detailed pixel-level annotations.
While object detection typically uses simpler loss functions (e.g., bounding box and classification loss) and is less computationally expensive, image segmentation is more resource-intensive, requiring more complex models and loss functions (e.g., Dice loss) to provide precise object boundaries.
segmentation_model = YOLO(os.path.join("WebinarContent", "Models", "yolov11m-seg.pt"))
Loading The Test Image
segmentation_test_image_path = os.path.join("WebinarContent", "Datasets", "ImageSegmentation", "beatles.png") img = cv2.cvtColor(cv2.imread(segmentation_test_image_path,cv2.IMREAD_COLOR), cv2.COLOR_BGR2RGB) plt.imshow(img)
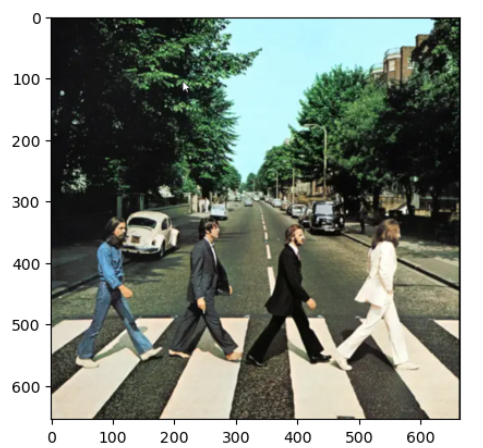
Accessing the Model Labels
yolo_seg_classes = list(segmentation_model.names.values()) classes_ids = [yolo_classes.index(clas) for clas in yolo_seg_classes]
conf = 0.5 # setting threshold results = segmentation_model.predict(img, conf=conf)
colors = [random.choices(range(256), k=3) for _ in classes_ids] person_class_id = 0 for result in results: for mask, box in zip(result.masks.xy, result.boxes): points = np.int32([mask]) class_id = int(box.cls[0]) if (class_id == person_class_id ): cv2.polylines(img, points, True, (255, 0, 0), 1) color_number = classes_ids.index(int(box.cls[0])) cv2.fillPoly(img, points, colors[color_number]) plt.imshow(img)
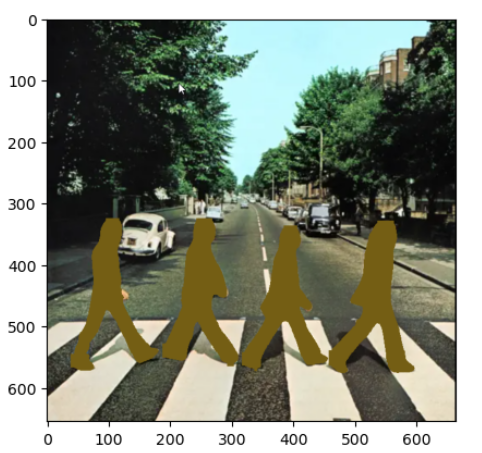
Voila ! You did it!
As we have demonstrated in this hands-on session, building production-grade computer vision systems is now achievable within an hour thanks to pre-trained models like InceptionV3 and YOLO. By leveraging these powerful models, we can quickly implement complex tasks from image classification to segmentation, making advanced computer vision capabilities readily accessible for real-world applications.
Here are some exercises to help you practice and extend what you've learned. They are arranged in increasing order of difficulty:
Try using ResNet50 instead of InceptionV3 for image classification:
Experiment with different YOLO model sizes:
Implement object tracking in a video:
Combine segmentation and tracking in a video pipeline:
Tips and starter code for each exercise are available in the GitHub repository. Feel free to share your project work in a publication on Ready Tensor!



