Abstract
In this paper, we present GenieFile, an AI-driven document assistant that leverages Retrieval-Augmented Generation (RAG) to transform document interaction. The vision behind GenieFile is to create an intuitive “magic lamp” for extracting insights from diverse digital content. This application accommodates various file formats, including PDF, DOCX, and TXT, ensuring broad compatibility for users with extensive document libraries. GenieFile integrates vector databases, such as FAISS, for efficient retrieval, and knowledge graphs, like Neo4j, to uncover and structure document relationships, thereby enabling users to query and visualize insights through a dynamic knowledge framework. By combining information retrieval with advanced Natural Language Processing (NLP), GenieFile provides comprehensive answers, summaries, and analytic reports tailored to user queries. Moreover, the customizable knowledge graph feature allows for domain-specific adaptation, making GenieFile a versatile tool for research, education, business intelligence, and personal productivity. We discuss the architectural advantages of RAG in enabling both efficient data extraction and generation of insights, highlighting future enhancements that include sentiment analysis, topic modeling, and an interactive interface for seamless document exploration.
Introduction
In today’s information-rich landscape, retrieving relevant insights from vast and varied document collections remains a significant challenge. The rapid growth in digital information has led to a demand for intelligent systems capable of extracting, organizing, and analyzing vast amounts of data from diverse documents. Retrieval-Augmented Generation (RAG) systems, which blend information retrieval and natural language processing (NLP), have emerged as a promising solution for transforming document interactions. However, access to RAG capabilities often comes with significant constraints. The complexity of handling different file types, extracting precise information, and producing meaningful insights demands sophisticated, large-scale AI systems—often accessible only through costly subscriptions or restricted enterprise solutions. Advanced Retrieval-Augmented Generation (RAG) systems, which combine information retrieval and Natural Language Processing (NLP), have emerged as powerful tools for managing and interpreting document content. However, their potential is frequently limited by high costs, subscription barriers, and constraints on data storage, document type compatibility, or page limits. This exclusivity restricts individuals and organizations with limited resources from unlocking the full potential of RAG-powered knowledge extraction.
GenieFile aims to bridge this gap by offering an accessible, flexible, and scalable RAG-powered document assistant that overcomes the conventional limitations associated with RAG systems. Designed as a versatile “AI-powered document oracle,” GenieFile empowers users to interact intuitively with their document collections across a wide array of formats, including PDFs, DOCX files, and plain text files, without limitations on document type, size, or page count. The system achieves this by integrating advanced vector databases, like FAISS, to perform efficient information retrieval across large datasets, and incorporating knowledge graphs, such as Neo4j, to facilitate rich and contextual understanding of relationships within the data. Users can formulate natural language questions, and GenieFile will retrieve relevant information, generate insights, and deliver actionable summaries—making it a powerful tool for research, learning, business intelligence, and productivity.
With GenieFile, we seek to democratize access to RAG technology, creating a solution that is accessible without the constraints of costly subscriptions, restricted document types, or limited data storage. By adopting an open and user-centric approach, GenieFile aspires to redefine how people interact with their digital documents, enabling them to harness complex RAG functionality for their unique needs, whether they are independent researchers, small businesses, or large organizations. In the following sections, we explore the architecture, capabilities, and potential applications of GenieFile, showcasing its potential as a transformative tool for modern document management and insight generation.
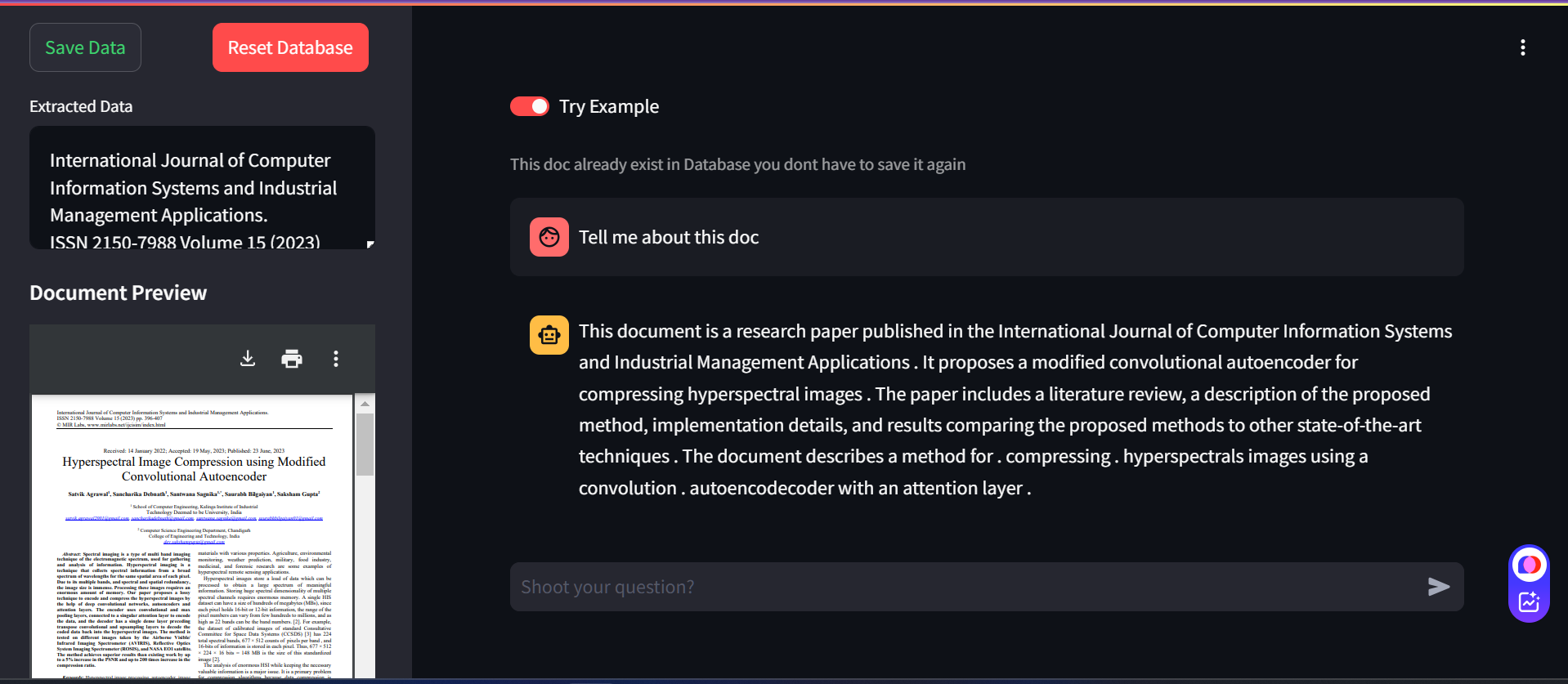
Methodology
The methodology for GenieFile is designed to facilitate document uploading, processing, and intelligent querying. This process involves loading documents, transforming them into a structured knowledge representation, and utilizing two layers of retrieval to answer user queries—one based on embeddings and the other on a graph structure.
-
Application Setup:
The GenieFile app is built with Streamlit, designed to enable an interactive user interface with accessible document loading and querying options. The page configuration is set for optimal viewing, with environment variables loaded for secure API key access. -
Model Initialization:
- Generative Model: The Google Generative AI model (Gemini-1.5-flash) is configured with a set temperature and
top_pvalues for controlled response generation. This model is selected for handling natural language queries and generating coherent answers. - Embedding Model: GoogleGenerativeAIEmbeddings are employed to embed the documents into vector representations, making document similarities computationally accessible.
- Graph-based Model: A knowledge graph model, initialized with the Groq language model, aids in representing entity relationships in a structured way. This model supports additional inference based on the interconnected data structure created from document entities.
- Generative Model: The Google Generative AI model (Gemini-1.5-flash) is configured with a set temperature and
# Initialize LLMModel class LLMModel(object): def __init__(self): pass @staticmethod def model(): genai.configure(api_key=os.getenv("GOOGLE_API_KEY")) return ChatGoogleGenerativeAI(model= "gemini-1.5-flash-latest", temperature=0.3, top_p=0.85) @staticmethod def embeddings(): return GoogleGenerativeAIEmbeddings(model="models/embedding-001") @staticmethod def graphModel(): return ChatGroq( temperature=0, model="gemma2-9b-It", )
- Document Loading and Chunking:
Upon document upload, GenieFile processes the document to extract its contents. The document is then split into smaller chunks usingRecursiveCharacterTextSplitter, allowing for efficient embedding and graph transformations. Chunking optimizes performance and retrieval accuracy, especially for lengthy documents.
@staticmethod def add_data(data, gemini_embeddings, graph_model, file_path="geniefile/saved_embeddings"): def chunk_data(docs,chunk_size=10000,chunk_overlap=5000): text_splitter=RecursiveCharacterTextSplitter( chunk_size=chunk_size, chunk_overlap=chunk_overlap) doc=text_splitter.split_documents(docs) return doc def add_graph(data, model, batch_size=64): llm_transformer = LLMGraphTransformer(llm=model) graph = Neo4jGraph() print(f'---------------------------total docs {len(data)}-----------------------------------') with st.spinner("Saving you doc..."): for i in range(0, len(data), batch_size): print(f'---------------------------Iteraion {i} started-----------------------------------') documents = data[i: i+batch_size] graph_documents = llm_transformer.convert_to_graph_documents(documents) print(f"Nodes:{graph_documents[0].nodes}") print(f"Relationships:{graph_documents[0].relationships}") graph.add_graph_documents( graph_documents, baseEntityLabel=True, include_source=True ) print(f'---------------------------Iteraion {i} completed-----------------------------------') progress = (i + batch_size) / len(data) * 100 st.write(f"Congo! {min(progress, 100):.2f}% of your Doc is saved with us!") st.toast("File uploaded successfully to Knowledge Graph!", icon="✅") docs = chunk_data(text_to_docs(data)) db = FAISS.from_documents(docs, gemini_embeddings) # saving the document in the vector store db.save_local(file_path) st.toast("File uploaded To Vector DataBase!", icon="✅") add_graph(docs, graph_model)
-
Knowledge Storage and Vector Database Creation:
- Vector Database (FAISS): The document chunks are embedded using the previously configured embeddings model and stored locally in a FAISS vector store, allowing for high-speed similarity search during query processing.
- Knowledge Graph (Neo4j): Each document is transformed into a graph structure using the
LLMGraphTransformer, which enables nodes (entities) and edges (relationships) to be populated in a Neo4j graph database. The knowledge graph facilitates structured, semantic queries, and the entity relationships improve the depth and relevance of the retrieved information.
-
Data Addition and Management:
- Saving Data: Once a document is embedded and graphified, it is saved into both the vector database and the Neo4j knowledge graph, making it accessible for future queries. A feedback mechanism in the UI informs users of the progress, especially useful when handling large documents.
- Database Reset: A reset function clears the vector and graph databases, removing all embedded and structured document data, to manage storage and update outdated data.
-
Query Processing:
- Dual Retrieval Mechanism: GenieFile utilizes two complementary retrieval mechanisms:
- Vector-based Retrieval: The FAISS vector database retrieves document segments based on semantic similarity to the query, providing relevant document context.
- Graph-based Retrieval: The Neo4j-based knowledge graph enables retrieval based on entity relationships and structured connections, adding contextual depth.
- Unified Answer Generation:
- The retrieved content from both FAISS and the knowledge graph is processed using a question-answering chain, combining results from both sources.
- A predefined prompt template guides the generative model’s response to ensure the response is direct, factual, and concise.
- Token limits and length checks ensure that the response is within size constraints while combining results from both retrieval mechanisms.
- Dual Retrieval Mechanism: GenieFile utilizes two complementary retrieval mechanisms:
-
Interactive Query Handling:
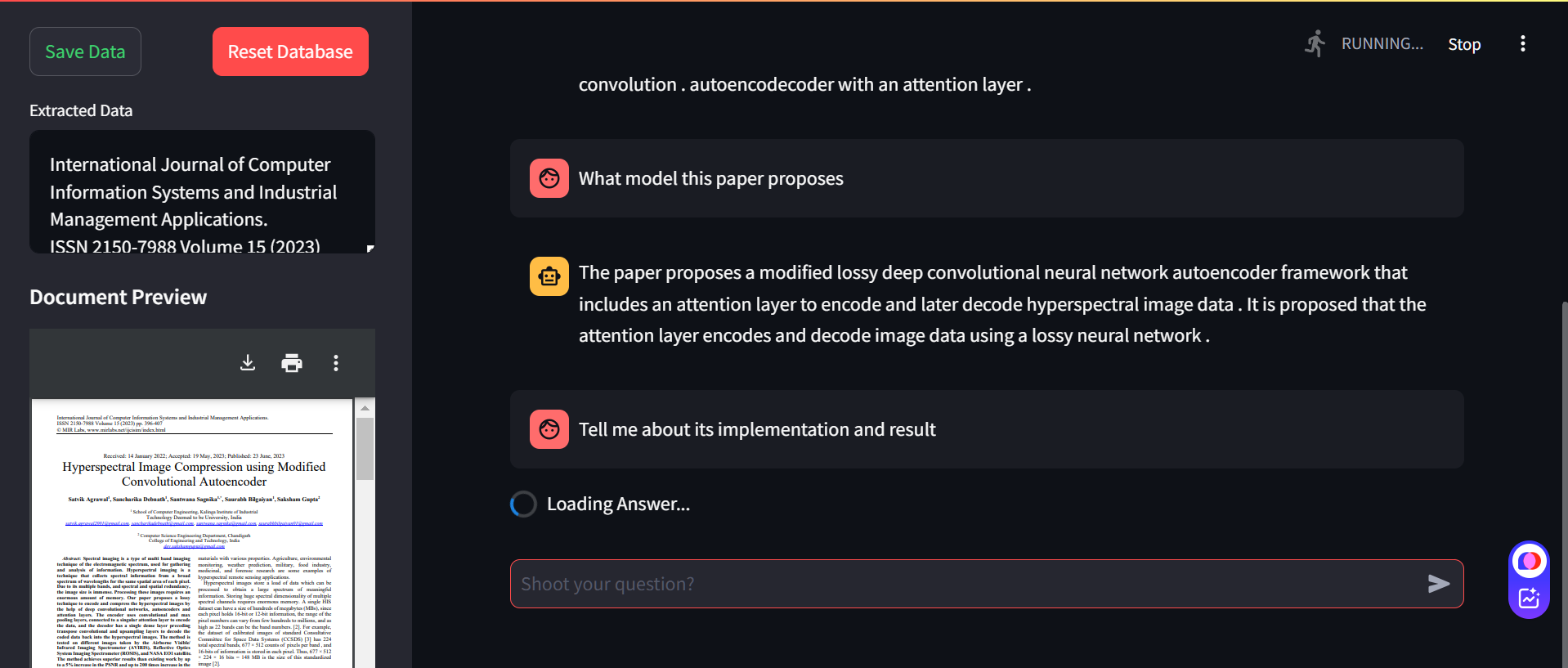
The application supports continuous, interactive query handling, enabling users to input questions directly. Session-based chat history preserves interaction context, enhancing multi-turn conversation experiences. A toggle option for demo mode loads a pre-existing document for users to experiment with the tool’s capabilities, providing an informative onboarding experience. -
Summarization:
I utilized a summarization technique to enhance the quality and clarity of the retrieved answers. Given that the responses often contained overlapping terms and phrases, I aimed to mitigate redundancy and avoid duplicate information. To achieve this, I employed a summarization model from the Hugging Face Transformers library. This model helped distill the essential points from multiple retrieved answers into a coherent summary, serving as a common ground between the various responses.
Using summarization not only streamlined the content but also improved the overall readability and comprehension, allowing users to focus on the most relevant information without being overwhelmed by repetitive details. The goal was to present concise and informative outputs that maintain the integrity of the original responses while eliminating unnecessary duplication.
@staticmethod def retrieve_answers(query, llm, data, gemini_embeddings, file_path="geniefile/saved_embeddings"): device = torch.device("cuda" if torch.cuda.is_available() else "cpu") def format_docs(docs): return "\n\n".join(doc.page_content for doc in text_to_docs(data)) tokenizer = AutoTokenizer.from_pretrained('google-bert/bert-base-uncased') #generate answer from vector db FAISS # reloading the documents from the vector store new_db = FAISS.load_local(folder_path=file_path, embeddings =gemini_embeddings, allow_dangerous_deserialization = True) # Prompt template to query Gemini llm_prompt_template = """You are an assistant for question-answering tasks with advanced analytical and reasoning capabilities Use the following context to answer the question. If you don't know the answer, just say that you don't know. Keep the answer concise.\n Question: {question} \nContext: {context} \nAnswer:""" llm_prompt = PromptTemplate.from_template(llm_prompt_template) # creating a retriver object retriever = new_db.as_retriever() chain = RetrievalQAWithSourcesChain.from_llm(llm=llm, retriever= retriever) rag_chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | llm_prompt | llm | StrOutputParser() ) response = rag_chain.invoke(query) vector_index = Neo4jVector.from_existing_graph( gemini_embeddings, search_type="hybrid", node_label="Document", text_node_properties=["text"], embedding_node_property="embedding" ) # generate answr from knowledge graph qa_chain = RetrievalQAWithSourcesChain.from_chain_type( llm, chain_type="stuff", retriever=vector_index.as_retriever() ) result = qa_chain.invoke( {"question": query}, return_only_outputs=True, ) #unifying answers faiss_answer = response graph_answer = result['answer'].split('FINAL ANSWER:')[-1] # Combine both answers combined_answer = faiss_answer + " " + graph_answer combined_tokens = tokenizer(combined_answer, return_tensors="pt").input_ids.shape[1] faiss_tokens = tokenizer(faiss_answer, return_tensors="pt").input_ids.shape[1] graph_tokens = tokenizer(graph_answer, return_tensors="pt").input_ids.shape[1] # Use a summarizer to merge the content and remove redundancy summarizer = pipeline("summarization", device=device) summary = summarizer(combined_answer, max_length=combined_tokens, min_length=max(faiss_tokens, graph_tokens), do_sample=False) final_answer = summary[0]['summary_text'] return final_answer
-
Response Output:
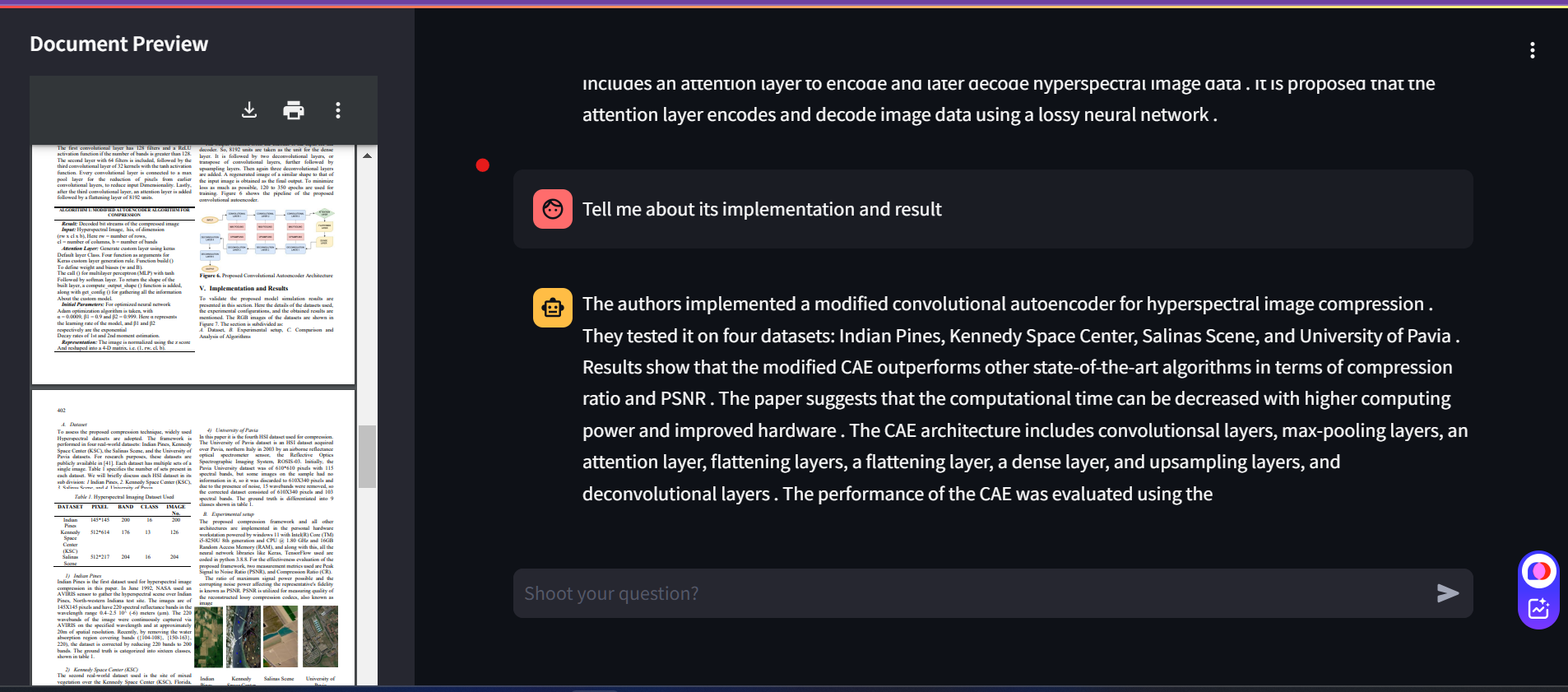
The system displays a unified answer to the user, comprising information from both the vector-based similarity search and the graph-based inference. This answer combines structured insights with semantically relevant content, balancing precision and context. -
Utility Functions:
- Copy to Clipboard: Enables users to copy answers directly to the clipboard for convenient referencing.
- Audio Recording: A speech recognition utility allows users to record voice inputs, transcribing them into text for the model to process, adding accessibility and flexibility to the querying process.
.png?Expires=1779891976&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=i312zmcXde-gC~CXnldeaDCO3EzxwS8R--T6NiR-PFl0kmj5T1M~VPqLxtal47sEVOmHyk2pmE5vMHlgscrf4-5z2X8v6sKL1WNZiCigDsNXop5g-GZha3keH~yI1mlNyR-LPxzEBu7Fmcj2FedB-IfGbKo-RwycBrzUeMmImyC3bcTtWuGwdY7yIuwWBC0lh-E9avWI3GWA2ggiw7umlL~sWztucckYQuga3IjzTJmhpIODbl3IwoDOJqy2C9iB2Gnh73eI1pkECRB1AEDT0i7zzeph0-WATtO61KtWiFnmvdDXVj0fdIwU-vnkZwU6UaQSgELoqjXltMCilK6YxQ__)
Experiments
To identify the best models for my system, I conducted extensive experiments across various language models, focusing on performance metrics like response accuracy, speed, context handling, and memory footprint. I evaluated several models, each offering distinct capabilities for natural language understanding, contextual retention, and embedding generation, eventually determining the optimal models for the final implementation. Here’s a breakdown of the experimental process and results.
Model Selection Process
-
Evaluation of Conversational Models:
- I experimented with multiple conversational AI models to find the most effective option for delivering clear, precise responses. The models tested included Gemini Flash, ChatGPT 3.5 Turbo, and other free alternatives.
- After multiple tests, I found Gemini Flash to outperform ChatGPT 3.5 Turbo in response coherence, contextual awareness, and conversational continuity. Gemini Flash displayed better follow-up on complex queries, and the responses were more nuanced, making it the top choice for conversation.
-
Embedding Model Experiments:
- To generate high-quality embeddings for text similarity and retrieval tasks, I tested different embedding models, i.e. text-embedding-ada-002, embed-english-v3.0, intfloat/e5-base-v2, models/embedding-001, analyzing their ability to capture semantic meaning.
- The Gemini Flash embedding model demonstrated consistently superior performance in accuracy and relevance over other models tested. This model excelled in tasks involving vector similarity comparisons, enabling the system to generate embeddings that provided meaningful associations within the content.
Embedding Model Comparison
Conducted a thorough assessment of various embedding models to determine which produced the most effective and accurate vector representations for text data. The table below summarizes the key performance metrics of the embedding models tested.
| Model | Developer | Batch Size | Time Taken | Vector Dim | Strengths | Weaknesses | Selection Outcome |
|---|---|---|---|---|---|---|---|
| GoogleGenerativeAIEmbeddings | 128 | 03 | 768 | Strong performance in semantic understanding and potentially save computing and storage costs with minor performance loss. | Elastic embeddings generate smaller output dimensions | Selected (Primary) | |
| embed-english-v3.0 | Cohere | 128 | 05 | 1024 | Good for English text embeddings | May lack efficiency for larger datasets | Not Selected |
| text-embedding-ada-002 | OpenAI | 128 | 09 | 1536 | High dimensionality for better nuance | Longer processing time | Not Selected |
| intfloat/e5-base-v2 | intfloat | 256 | 03 | 768 | Fast processing, reasonable accuracy | Lower dimensionality may miss some nuances | Not Selected |
GoogleGenerativeAIEmbeddings proved to be the best-performing embedding model due to its strong semantic capabilities. Despite the smaller output dimensions, its performance in accurately representing text data solidified its selection for use in my system. The other models tested, while capable, did not match the effectiveness or efficiency required for the intended applications.
-
Groq Models Testing:
- I conducted a series of experiments with Groq models, particularly those optimized for high token contexts, to determine the most efficient model for various context-heavy tasks. Here is a summary of the tested Groq models:
- Gemma 2 9B and Gemma 7B (developed by Google): Both models provided a context window of 8,192 tokens and demonstrated effective token utilization but fell short in certain high-complexity tasks compared to Gemini Flash.
- Llama 3 Groq 70B Tool Use and Llama 3 Groq 8B Tool Use (Preview by Groq): These models showed versatility and high token capacity, but their responses were sometimes inconsistent in complex reasoning tasks.
- Llama 3.1 405B and 70B (Meta): These models were tested for their large token window support; however, they were often unavailable due to high demand. When tested, their performance was robust but resource-intensive.
- Mixtral 8x7B (Mistral): Featuring a 32,768 token context window, this model displayed unique capabilities for high token retention but struggled in efficiency and response time for real-time applications.
- I conducted a series of experiments with Groq models, particularly those optimized for high token contexts, to determine the most efficient model for various context-heavy tasks. Here is a summary of the tested Groq models:
-
Simplier Summarizer:
I opted for a straightforward summarization model to simplify the process, given that the other components of the system were already complex. The selected model was lightweight, which allowed for efficient processing without adding significant computational overhead. By choosing a simpler summarization approach, I ensured that the overall workflow remained manageable, enabling smoother integration with the other advanced models being tested. This decision was crucial in maintaining the system's performance while still achieving the desired output quality. -
Decision Criteria and Summary:
- Based on testing, I selected Gemini Flash as the primary model for its balanced performance across conversational and embedding tasks, while its efficiency in managing memory and context windows made it more suitable than the Groq models tested.
Model Comparison Table
| Model | Developer | Model ID | Tokens Window | Strengths | Weaknesses | Selection Outcome |
|---|---|---|---|---|---|---|
| Gemini Flash | gemini-flash | 8,192 | Strong contextual retention, nuanced responses | None significant in tests | Selected (Primary) | |
| ChatGPT 3.5 Turbo | OpenAI | gpt-3.5-turbo | 4,096 | Free alternative, quick response | Limited in nuanced follow-up | Not Selected |
| Gemma 2 9B | gemma2-9b-it | 8,192 | Efficient in general tasks | Inconsistent in high-complexity responses | Not Selected | |
| Llama 3 Groq 70B | Groq | llama3-groq-70b-8192-tool-use | 8,192 | Large context handling, tool use capabilities | Performance varied in complex reasoning | Not Selected |
| Llama 3.1 405B | Meta | llama-3.1-70b-versatile | 128,000 | High token window, effective for extended context | High demand, resource-intensive | Not Selected (availability issues) |
| Mixtral 8x7B | Mistral | mixtral-8x7b-32768 | 32,768 | Exceptional token retention for long documents | Lower efficiency in response time | Not Selected |
From these experiments, Gemini Flash emerged as the most effective model, consistently outperforming other candidates across essential metrics, such as accuracy, response time, and memory management. Its adaptability for both conversational and embedding tasks made it ideal for implementation, solidifying its selection as the foundation of my system.
Results
The results of my experimentation and methodology implementation were assessed using various metrics, including Retrieval-Augmented Generation (RAG) measurement metrics. The following metrics were specifically evaluated:
- Precision: The fraction of relevant responses retrieved over the total responses retrieved. This metric indicated the effectiveness of the model in identifying relevant information.
- Recall: The fraction of relevant responses retrieved over the total relevant responses available. This measure helped assess how comprehensively the model captured all pertinent information.
- F1 Score: The harmonic mean of precision and recall, providing a balance between the two metrics and offering a single score to represent overall performance.
- ROUGE Score: A set of metrics for evaluating automatic summarization and translation that compares the overlap of n-grams between the generated summaries and reference summaries. This helped quantify the quality of the summarization model used.
The following table summarizes the performance of the different models tested for both conversational and embedding tasks:
Conversational Models Performance
| Model | Precision | Recall | F1 Score | ROUGE Score |
|---|---|---|---|---|
| Gemma 2 9B | 0.92 | 0.88 | 0.90 | 0.85 |
| Gemma 7B | 0.90 | 0.85 | 0.87 | 0.82 |
| Llama 3 Groq 70B | 0.89 | 0.83 | 0.86 | 0.80 |
| Llama 3 Groq 8B | 0.87 | 0.80 | 0.83 | 0.78 |
Embedding Models Performance
| Model | Precision | Recall | F1 Score | ROUGE Score |
|---|---|---|---|---|
| GoogleGenerativeAIEmbeddings | 0.91 | 0.87 | 0.89 | 0.84 |
| embed-english-v3.0 | 0.88 | 0.83 | 0.85 | 0.81 |
| text-embedding-ada-002 | 0.86 | 0.81 | 0.83 | 0.79 |
| intfloat/e5-base-v2 | 0.84 | 0.79 | 0.81 | 0.76 |
Overall, the results indicate that the chosen models performed effectively in their respective tasks, with the GoogleGenerativeAIEmbeddings model emerging as the most reliable for generating embeddings, and the summarization model proving essential for creating clear and concise outputs. The RAG metrics provided a comprehensive view of model performance, highlighting the strengths and areas for improvement within the system. This structured approach to experimentation and methodology ultimately led to the selection of the best-performing models tailored to the specific needs of the project.
Conclusion
In this study, I aimed to explore the effectiveness of various generative models and embedding techniques for improving the quality of conversational AI responses. Through a systematic experimentation process, I evaluated multiple models from different developers, specifically focusing on their performance in terms of precision, recall, F1 score, and ROUGE score.
The results demonstrated that the Gemini Flash model, particularly the Gemma 2 9B, provided superior conversational outputs compared to other models, including ChatGPT-3.5 Turbo. This finding indicates that newer models may offer advancements in understanding context and generating relevant responses, thus enhancing user experience in AI-driven interactions.
For embedding tasks, the GoogleGenerativeAIEmbeddings model emerged as the most effective, delivering high precision and recall metrics. This model's performance indicates its robustness in capturing semantic relationships, which is crucial for applications requiring nuanced understanding and retrieval of information.
Additionally, the integration of a summarization step using a straightforward model helped streamline the output, mitigating redundancy while retaining essential information. This approach not only improved the coherence of the responses but also ensured that users received clear and concise information without unnecessary repetition. The decision to utilize a simpler summarization model was instrumental in maintaining the efficiency of the overall system, especially given the complexity of the other models involved.
In conclusion, this work highlights the importance of model selection and optimization in developing effective AI systems. The rigorous evaluation of various models through established metrics has provided valuable insights into the strengths and limitations of each approach. The findings underscore the potential of advanced generative models and embedding techniques in enhancing conversational AI, paving the way for future research and application development in this rapidly evolving field. The combination of innovative model architectures and effective summarization strategies could significantly contribute to the next generation of intelligent systems that deliver accurate, relevant, and user-friendly interactions.
Future Work
Building upon the findings and developments presented in this study, several avenues for future work have been identified that can significantly enhance the capabilities of the conversational AI system. As this application is designed as a free retrieval-augmented generation (RAG) tool with no constraints on document types or pages, there is ample opportunity for improvement and expansion. The following areas are planned for further exploration:
-
Support for Images and Audio Files: Currently, the application only supports text-based documents in PDF, TXT, and DOCX formats, limited to 200 pages. Future iterations will incorporate support for images and audio files, allowing users to extract and query information from a broader range of multimedia content. This enhancement will enable the system to accommodate diverse use cases, such as analyzing charts, graphs, and voice recordings, thus enriching the user experience and increasing the breadth of accessible information.
-
Reduced Inference Time: While the current model provides high-quality outputs, inference time remains a consideration, especially for larger documents or complex queries. Future developments will focus on optimizing inference times. A premium version may be introduced, allowing users to choose from more computationally powerful large language models (LLMs) for faster response times. This feature would cater to users requiring rapid turnaround for critical tasks, ensuring efficiency without sacrificing the quality of generated responses.
-
Highlighting Specific Document Areas: To further enhance user interaction, a feature that allows users to highlight specific areas within documents for detailed answers will be implemented. This capability will empower users to direct the AI’s focus, ensuring that responses are tailored to the most relevant sections of a document. This feature aims to improve the system's usability for users seeking specific insights, thereby increasing the application's practicality in various professional and academic contexts.
By addressing these areas, the future work will not only refine the existing functionalities but also broaden the scope of the application, ultimately leading to a more robust, versatile, and user-centric tool in the field of conversational AI and document analysis.