Abstract
Document parsing is a critical task for automating workflows across various industries, traditionally reliant on optical character recognition (OCR) methods that are often computationally expensive and limited in flexibility. In this work, we leverage Google’s Paligemma, a state-of-the-art vision-language model, to fine-tune its capabilities for structured document parsing. By training Paligemma on a custom receipts dataset, we enable it to output structured JSON files. This approach reduces manual data entry efforts and demonstrates practical feasibility, operating efficiently on a single T4 GPU. Our results highlight the transformative potential of vision-language models in real-world document understanding tasks.
Introduction
Document parsing plays a pivotal role in automating data extraction processes, especially in industries such as finance, retail, and logistics. Documents like receipts and invoices are typically unstructured, making manual data entry both time-consuming and prone to errors. Traditional OCR techniques, though widely used, struggle with noisy data, diverse layouts, and high computational demands, particularly when scaled to real-world applications.
To address these challenges, we employ Google’s Paligemma model, a cutting-edge vision-language architecture designed for multimodal tasks. Paligemma integrates the SigLIP image encoder and Gemma text decoder through a linear adapter, combining visual comprehension with linguistic capabilities. The SigLIP encoder uses pairwise Sigmoid loss for efficient training and improved generalization, while the Gemma decoder generates structured textual outputs from tokenized inputs.
This project fine-tunes Paligemma for parsing receipt images into structured JSON files, facilitating seamless integration into database tools for automated workflows such as expense management and inventory tracking. The model demonstrates robust performance on a single T4 GPU, making it both cost-effective and practical for business applications. By leveraging advanced vision-language models over traditional OCR systems, our approach emphasizes computational efficiency, adaptability, and accuracy in document parsing tasks.
Literature Review
The motivation for this project stemmed from the limitations of traditional OCR-based document parsing methods, which often faltered when dealing with complex layouts, non-standard fonts, or low-resolution images. To overcome these challenges, we explored OCR-free approaches, such as the DONUT transformer, which presented a promising framework for document parsing. However, DONUT lacked the robustness required to handle diverse document formats comprehensively.
The release of Google’s Paligemma in July 2024 introduced a significant advancement in vision-language models. With 3 billion parameters and pretraining on multimodal datasets, Paligemma demonstrated exceptional capabilities for tasks requiring an intricate understanding of visual and textual information. Its modular architecture, documented extensively on platforms like Hugging Face, provided a flexible and powerful foundation for transfer learning in complex downstream tasks.
Recognizing Paligemma’s potential, we integrated it into our workflow to address the challenges of receipt parsing. The extensive documentation and resources on Hugging Face enabled efficient fine-tuning of the model for extracting key-value pairs from receipt images into structured JSON formats. This project represents the confluence of our need for an improved document parsing approach and the opportunity to leverage state-of-the-art vision-language technology.
Methodology
In this study, we fine-tuned Google’s Paligemma-3B-224 model using the PyTorch Lightning module for structured document parsing. The methodology involved several critical steps, starting with dataset preparation, where we employed a custom receipts dataset comprising images, unique IDs, parsed data, and raw data. This dataset was specifically selected to encapsulate diverse layouts and noisy characteristics commonly encountered in receipt parsing tasks.
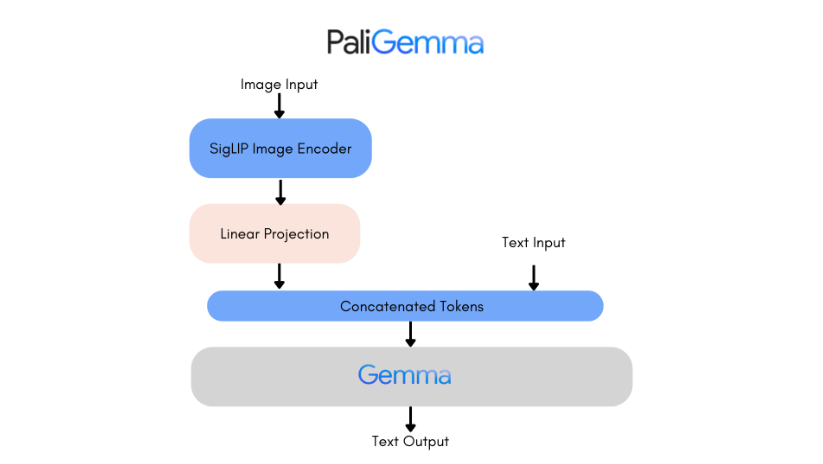
The Paligemma-3B-224 model was configured to balance efficiency and performance. It integrates the SigLIP image encoder and the Gemma text decoder, which facilitate multimodal input processing. Given the limited computational resources of a T4 GPU, we updated the weights in the model’s attention layers (approximately 170 million parameters) and opted for the Stochastic Gradient Descent (SGD) optimizer instead of the more resource-intensive Adam optimizer to enhance computational efficiency.
Data preprocessing was conducted using the Paligemma AutoProcessor, which performs image processing and tokenization. The parsed data was transformed into tokens suitable for training, followed by collation to prepare the data for model input. The training pipeline required inputs such as prompts, processed images, and text tokens, while evaluation tasks utilized prompts and processed images. Data loaders ensured that the processed inputs included input IDs, token type IDs, attention masks, pixel values, and labels for training and evaluation purposes.
class CustomDataset(Dataset): def __init__(self, dataset_path: str, split: str = "train", sort_json_key: bool = True, ): super().__init__() self.split = split self.sort_json_key = sort_json_key self.dataset = load_dataset(dataset_path, split=self.split) self.dataset_length = len(self.dataset) self.gt_token_sequence = [] for sample in self.dataset: samplep1 = ast.literal_eval(re.search('({.+})', sample["parsed_data"]).group(0)) final_sample = ast.literal_eval(re.search('({.+})', samplep1["json"]).group(0)) if "header" not in samplep1.keys(): d_doc = json_to_token(final_sample) self.gt_token_sequence.append(d_doc) else: d_doc = json_to_token(final_sample['header']) + json_to_token(final_sample['items'][0]) + json_to_token(final_sample['summary']) self.gt_token_sequence.append(d_doc) def json_to_token(self, obj: Any, sort_json_key: bool = True): ### Converting JSON to Token if type(obj) == dict: if len(obj) == 1 and 'text_sequence' in obj: return obj['text_sequence'] else: output = "" if sort_json_key: keys = sorted(obj.keys(), reverse = True) else: keys = obj.keys() for k in keys: token = self.json_to_token(obj[k], sort_json_key) if token is not None: output += (fr"" + token + fr"") return output elif type(obj) == list: return r"".join([self.json_to_token(item, sort_json_key) for item in obj]) else: obj = str(obj) return obj def __len__(self) -> int: return self.dataset_length def __getitem__(self, index: int) -> Dict: sample = self.dataset[index] # Input image = sample["image"] target_sequence = self.gt_token_sequence[index] return image, target_sequence def train_collate_fn(examples): images = [example[0] for example in examples] texts = [PROMPT for _ in range(len(images))] target_sequences = [example[1] for example in examples] inputs = processor(text = texts, images = images, suffix = target_sequences, return_tensors = "pt", padding = True, truncation = "only_second", max_length = MAX_LENGTH, tokenize_newline_separately = False) input_ids = inputs["input_ids"] token_type_ids = inputs["token_type_ids"] attention_mask = inputs["attention_mask"] pixel_values = inputs["pixel_values"] labels = inputs["labels"] return input_ids, token_type_ids, attention_mask, pixel_values, labels def eval_collate_fn(examples): images = [example[0] for example in examples] texts = [PROMPT for _ in range(len(images))] target_sequences = [example[1] for example in examples] inputs = processor(text = texts, images = images, return_tensors = "pt", padding = True, tokenize_newline_separately = False) input_ids = inputs["input_ids"] attention_mask = inputs["attention_mask"] pixel_values = inputs["pixel_values"] return input_ids, attention_mask, pixel_values, target_sequences
The training pipeline utilized the SigLIP encoder for visual processing of images with pairwise Sigmoid loss and the Gemma decoder for generating structured textual outputs from tokenized sequences. The PyTorch Lightning module streamlined the process, enabling efficient training and validation. Training and validation steps were implemented to optimize performance, where the SGD optimizer facilitated faster convergence, although it sacrificed some of the precision provided by AdamW.
class PeliGemmaModel(L.LightningModule): def __init__(self, config, processor, model): super().__init__() self.config = config self.processor = processor self.model = model self.eval_collate_fn = eval_collate_fn self.train_collate_fn = train_collate_fn self.batch_size = config.get("batch_size") def training_step(self, batch, batch_idx): input_ids, token_type_ids, attention_mask, pixel_values, labels = batch outputs = self.model(input_ids = input_ids, attention_mask = attention_mask, token_type_ids = token_type_ids, pixel_values = pixel_values, labels = labels) loss = outputs.loss self.log("train_loss", loss, prog_bar=True, logger=True) return loss def validation_step(self, batch, batch_idx): print("Entered Validation Step") input_ids, attention_mask, pixel_values, answers = batch print("Generated inputs") generate_ids = self.model.generate(input_ids = input_ids, attention_mask = attention_mask, pixel_values = pixel_values, max_new_tokens = MAX_LENGTH) print("Generated predictions") predictions = self.processor.batch_decode(generate_ids[:, input_ids.size(1):], skip_special_tokens=True) print("Decoded predictions") scores = [] for pred, answer in zip(predictions, answers): print("entered validation loop") pred = re.sub(r"(?:(?<=>) | (?=</s_))", "", pred) score = edit_distance(pred, answer) / max(len(pred), len(answer)) scores.append(score) if self.config.get("verbose", False) and len(scores) == 1: print(f"Prediction: {pred}") print(f"Answer: {answer}") self.log("val_edit_distance", np.mean(scores), prog_bar=True, logger=True) return scores def configure_optimizers(self): optimizer = torch.optim.AdamW(self.parameters(), lr=self.config.get("lr")) return optimizer def train_dataloader(self): return DataLoader(train_dataset, batch_size = self.batch_size, shuffle = True, collate_fn = self.train_collate_fn, num_workers = 4) def val_dataloader(self): return DataLoader(val_dataset, batch_size=2, shuffle=False, collate_fn=self.eval_collate_fn, num_workers =4)
To make the model memory efficient, quantization to 8-bit precision was implemented, reducing the weights from Float32 to 8-bit without significantly compromising accuracy. The project also introduced Low-Rank Adaptation (LoRA), which applies targeted updates to specific layers of the model. These layers included the query, key, value, and output projections, as well as gate, up, and down projections. This approach maintained high computational efficiency while enhancing the adaptability of the fine-tuned model for the document parsing task.
bnb_config = BitsAndBytesConfig(load_n_4bit = True, bnb_4bit_quant_type = "nf4", bnb_4bit_compute_type = torch.bfloat16, bnb_4bit_use_double_quant = True, ) lora_config = LoraConfig(r = 8, target_modules = ["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"], task_type = "CAUSAL_LM", ) model = PaliGemmaForConditionalGeneration.from_pretrained(REPO_ID, quantization_config = bnb_config, device_map = {"":0}, ) model = get_peft_model(model, lora_config) model.print_trainable_parameters()
Through these methodical steps, we fine-tuned Paligemma to effectively handle receipt parsing and structured data extraction, achieving optimal performance within the computational constraints of the project.
Results
The fine-tuned Paligemma model demonstrated robust performance in parsing receipt images into structured JSON files. Key-value pairs were extracted with high accuracy, showcasing the model’s ability to handle diverse layouts and noisy data effectively. The integration of 8-bit quantization and LoRA optimizations ensured that the model operated efficiently on a single T4 GPU, making it cost-effective for practical applications.
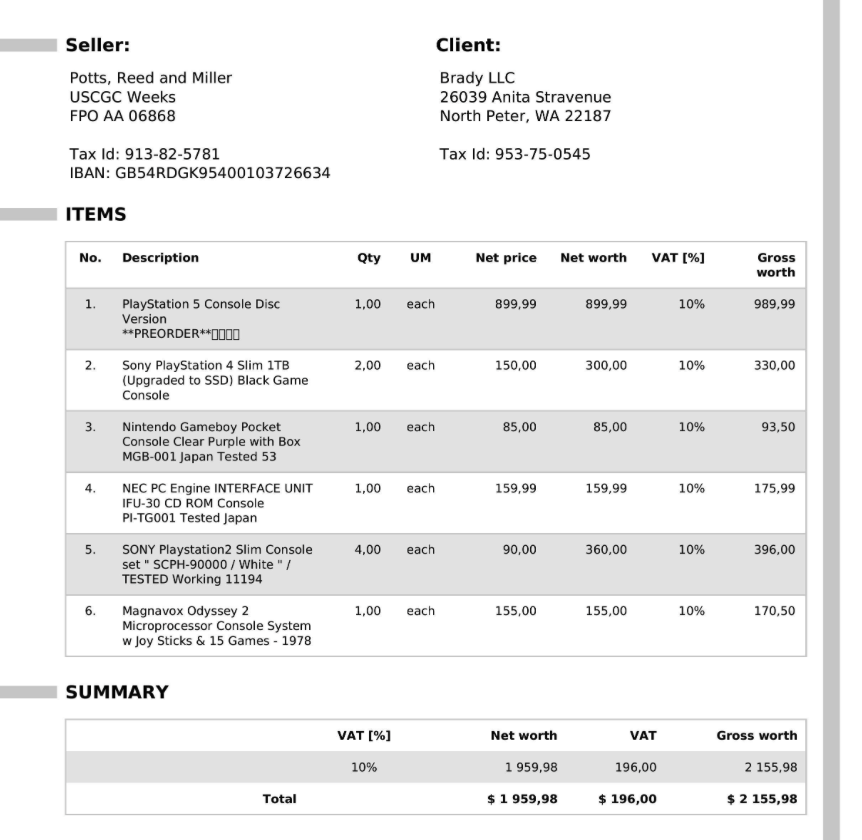
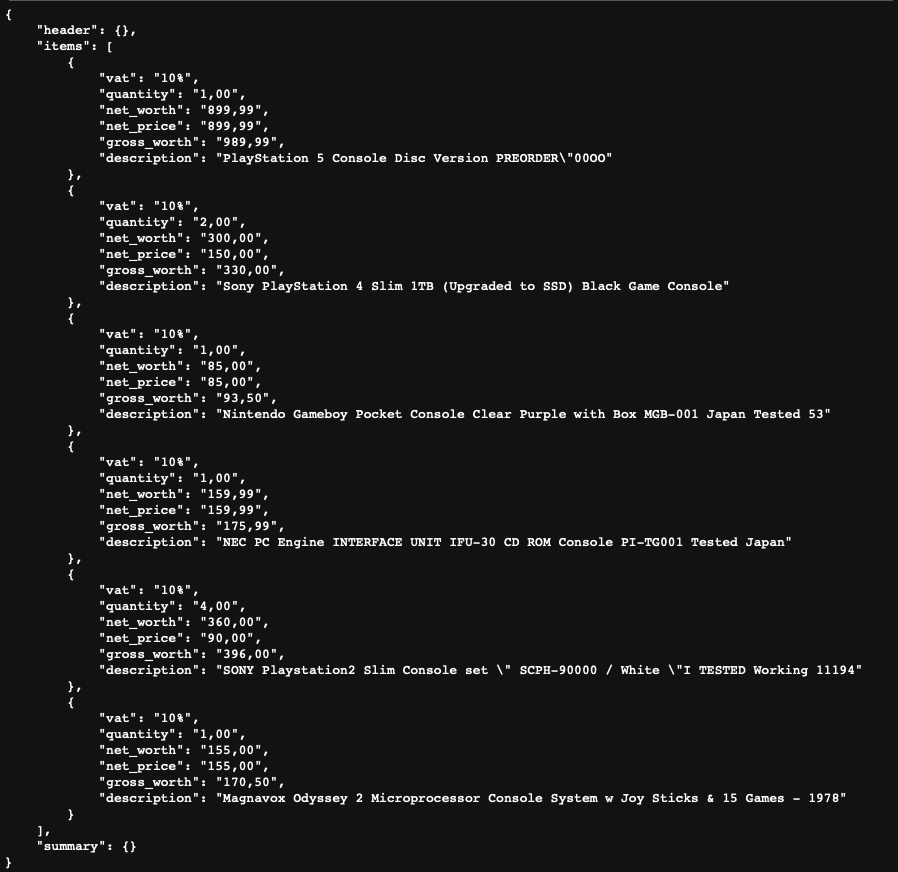
Conclusion
This project demonstrates the efficacy of leveraging advanced vision-language models like Paligemma for document understanding and key-value extraction from complex receipt images. By addressing the limitations of traditional OCR methods, we implemented an OCR-free pipeline capable of parsing and structuring information with high accuracy.
The integration of Paligemma into our workflow underscores the transformative potential of cutting-edge AI technologies in handling diverse and intricate document layouts. This project contributes to advancements in document understanding and highlights the importance of transfer learning and domain-specific adaptations in maximizing the utility of pre-trained models.
Future work could explore further optimization, including multilingual support and application to other document types. This project sets a solid foundation for innovations in document parsing, advancing the automation and efficiency of data extraction and processing.