This submission presents FinRAG, the first-place winning solution for the 4th AI & Data Science Competition, where we achieved the highest scores in both retrieval and generation tasks. Our system is designed for financial document processing using Retrieval-Augmented Generation (RAG), with a focus on handling structured financial data, including tables, numerical reasoning, and contextual retrieval.
The competition aimed to develop a highly effective Retrieval-Augmented Generation (RAG) system capable of processing large-scale financial documents. The competition consisted of two primary tasks:
Participants had to build a system that could effectively retrieve and process financial information, including financial statements, earnings reports, and structured tables.
The competition dataset posed several unique challenges:
| Dataset | Description | Focus Area |
|---|---|---|
| FinDER | 10-K reports | Jargon and abbreviation handling |
| FinQABench | 10-K reports | Hallucination detection and factuality |
| FinanceBench | 10-K reports | Real-world financial queries |
| TATQA | Mixed formats | Numerical reasoning with text and tables |
| FinQA | Earnings reports | Multi-step reasoning |
| ConvFinQA | Earnings reports | Conversational query processing |
| MultiHiertt | Annual reports | Complex hierarchical table reasoning |
Key Technical Challenges:
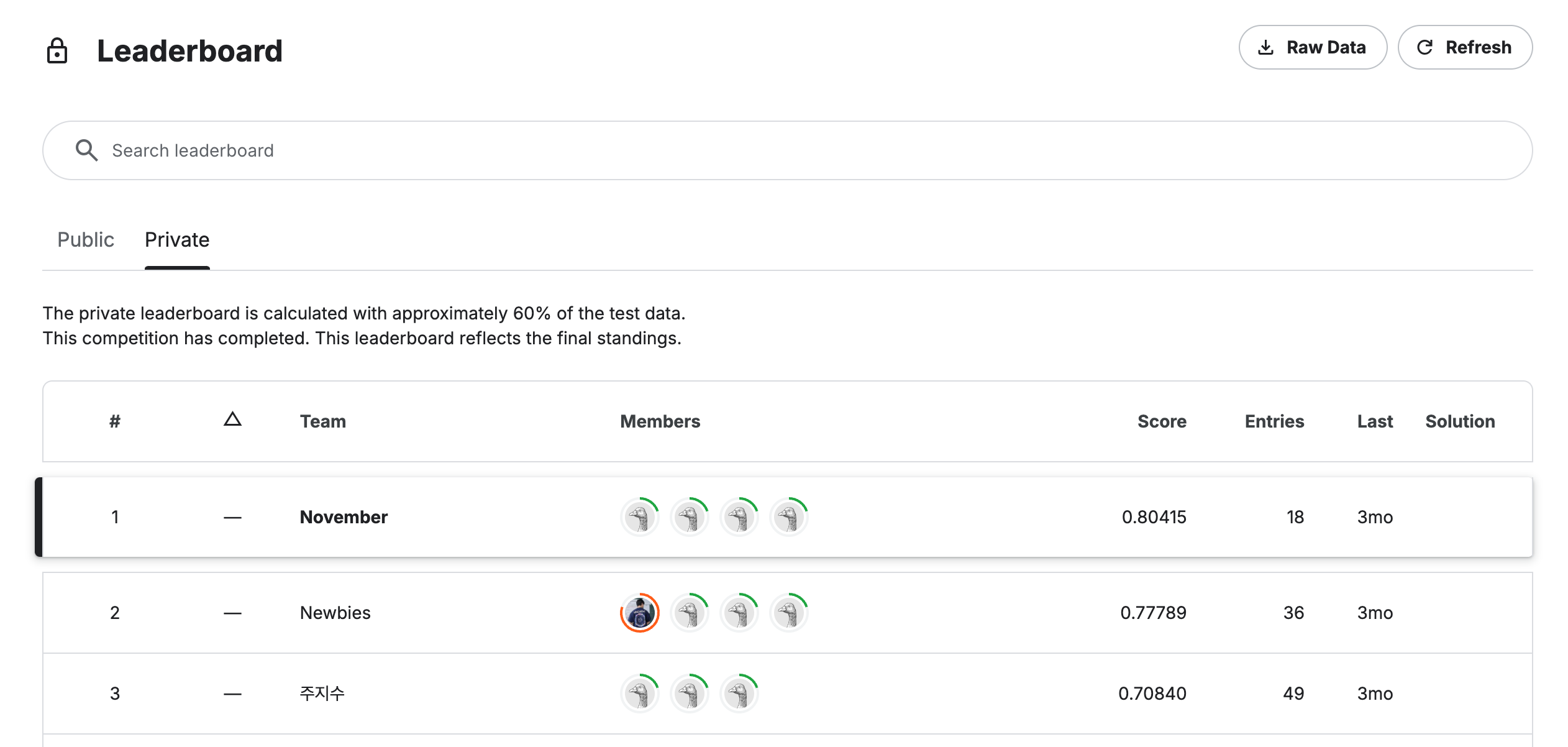
Our system, FinRAG, outperformed all competing teams in both retrieval and generation tasks:
| Rank | Team | nDCG@10 Score |
|---|---|---|
| 🥇 1 | November (US) | 0.80415 |
| 2 | Newbies | 0.7789 |
| 3 | 주지수 | 0.70840 |
| Rank | Team | Score |
|---|---|---|
| 🥇 1 | November (US) | 81 |
| 2 | Newbies | 80 |
| 3 | Board | 77 |
FinRAG is an advanced Retrieval-Augmented Generation (RAG) system designed for financial document processing. Our solution incorporates:
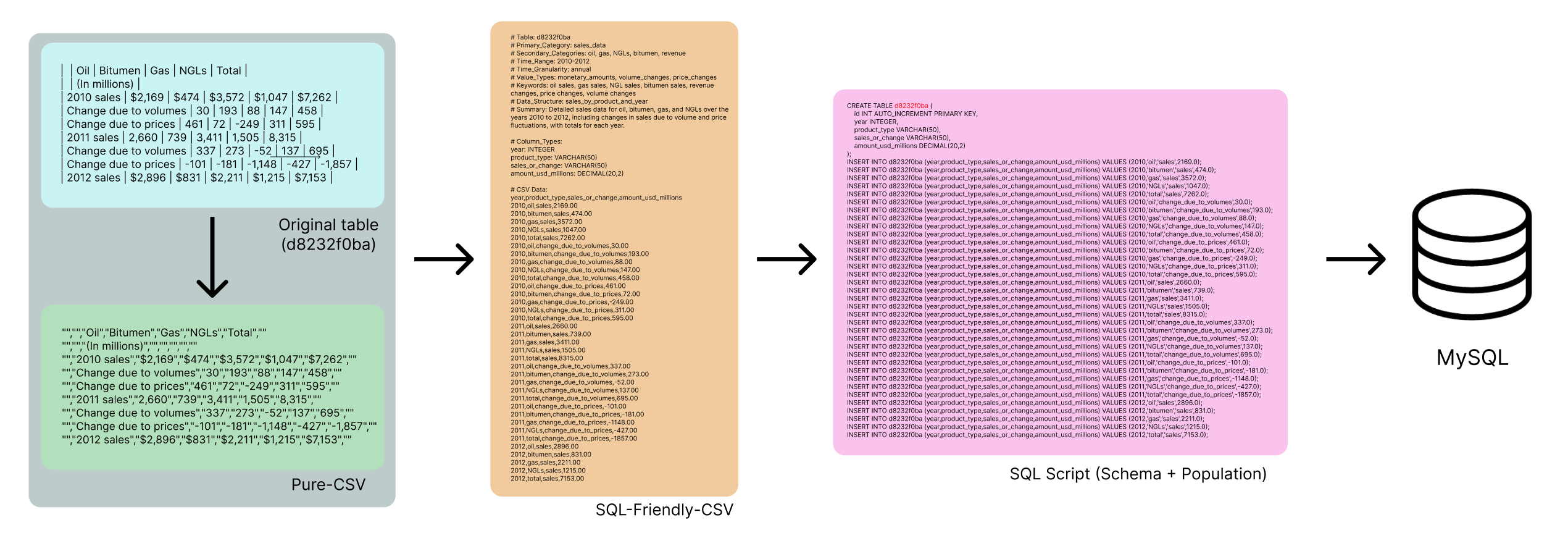
One major challenge in financial document processing was dealing with tables embedded within financial reports. Many financial insights (e.g., revenue trends, debt ratios, stock performance) were hidden within unstructured tabular data rather than plain text.
To address this, we developed a SQL-based preprocessing pipeline:
This preprocessing enabled precise numerical calculations, reducing LLM hallucination errors when handling financial queries.
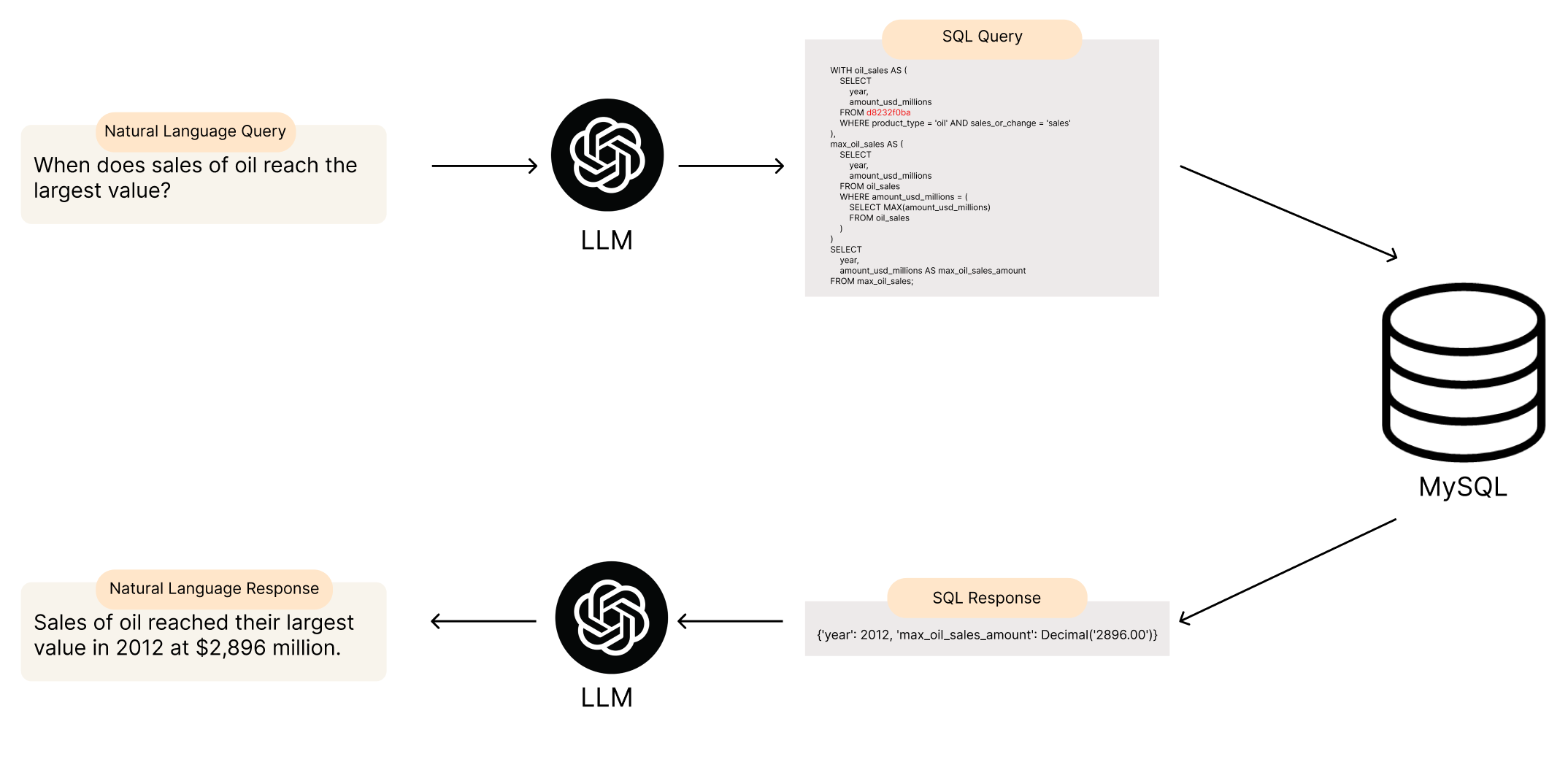
Since financial queries often required numerical operations, we implemented a Text-to-SQL pipeline that translated natural language queries into structured SQL queries.
🔹 Example Query Transformation:
💬 User Query: "When does sales of oil reach the largest value?"
🔄 LLM-Generated SQL Query:
WITH oil_sales AS ( SELECT year, amount_usd_millions FROM d8232f0ba WHERE product_type = 'oil' AND sales_or_change = 'sales' ), max_oil_sales AS ( SELECT year, amount_usd_millions FROM oil_sales WHERE amount_usd_millions = ( SELECT MAX(amount_usd_millions) FROM oil_sales ) ) SELECT year, amount_usd_millions AS max_oil_sales_amount FROM max_oil_sales;
✅ Database Result: {'year': 2012, 'max_oil_sales_amount': Decimal('2896.00')}
This approach significantly improved numerical accuracy, reducing calculation errors in financial queries.
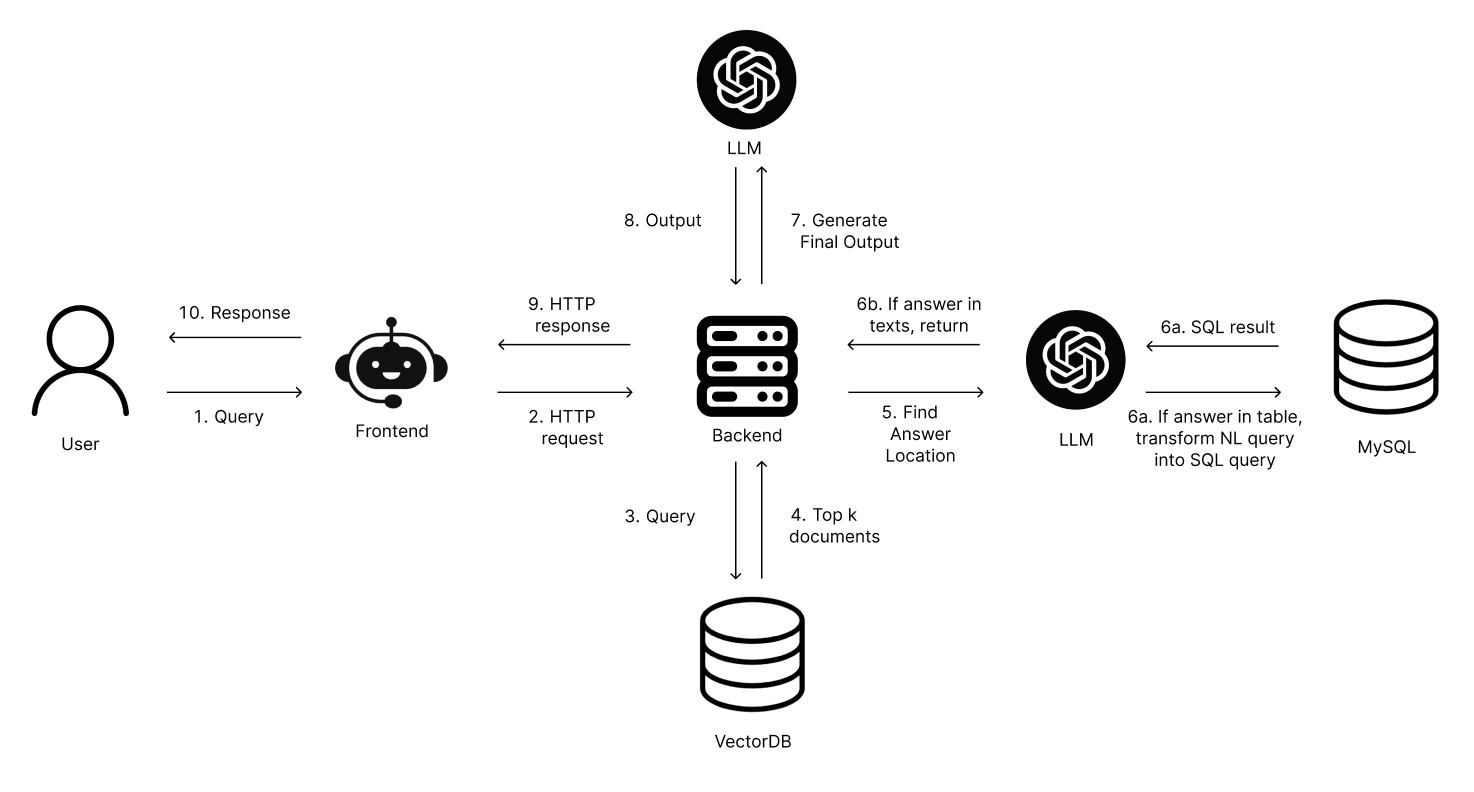
Our final FinRAG pipeline integrates retrieval, SQL processing, and LLM-based generation:
To demonstrate FinRAG’s capabilities, we built a real-time chatbot interface:
FinRAG provides a highly effective financial RAG system, demonstrating state-of-the-art retrieval and generation performance. Future work includes:
✅ Expanding to additional financial datasets (e.g., live market data, real-time stock analysis).
✅ Fine-tuning LLMs for financial text comprehension to further reduce hallucinations.
✅ Optimizing SQL parsing techniques to handle even more complex table structures.
The full FinRAG solution is open-source and available on GitHub: