Fetus Intracranial Structures Identification using YOLOv11
Objective
This project aims to investigate whether artificial intelligence (AI) can accurately identify fetal intracranial structures in ultrasound images during pregnancy weeks 11-14. The key goal is to apply the YOLOv11 object detection model to classify nine important fetal structures relevant to nuchal translucency (NT) measurement and Down syndrome assessment.
Dataset
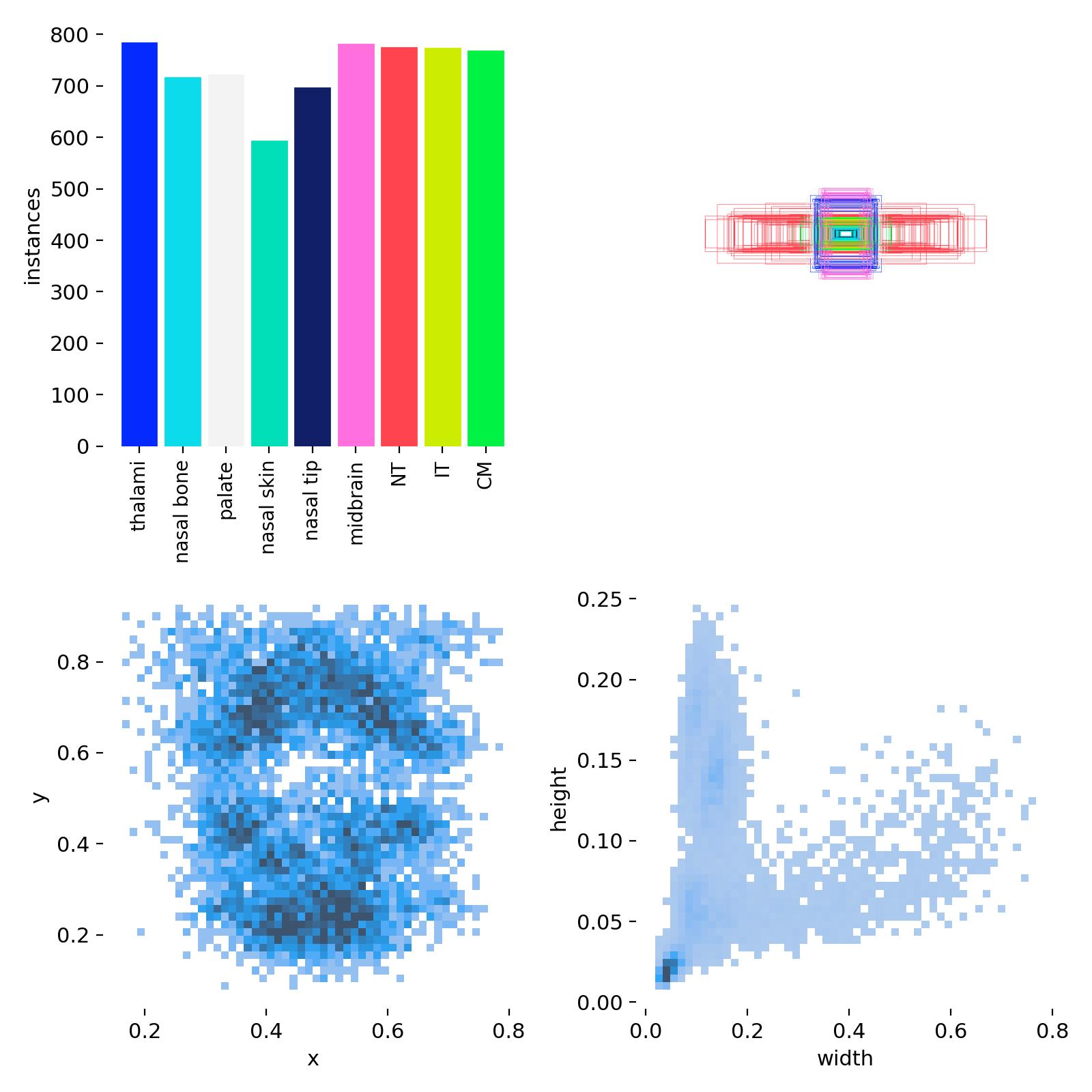
The dataset used in this project contains 1528 2D sagittal-view ultrasound images of 1519 females, collected from Shenzhen People’s Hospital. The dataset includes annotations for nine key structures, as listed below:
- Thalami
- Midbrain
- Palate
- 4th Ventricle
- Cisterna Magna
- Nuchal Translucency (NT)
- Nasal Tip
- Nasal Skin
- Nasal Bone
An external test dataset of 156 images from the Longhua branch of Shenzhen People’s Hospital was also used to evaluate the AI performance.
The annotations for the structures can be found in the file ObjectDetection.xlsx.
Model
The project utilizes the YOLOv11 model for object detection. YOLO (You Only Look Once) is a state-of-the-art, real-time object detection system. In this project, YOLOv11 was trained to identify and classify the key fetal intracranial structures in the ultrasound images.
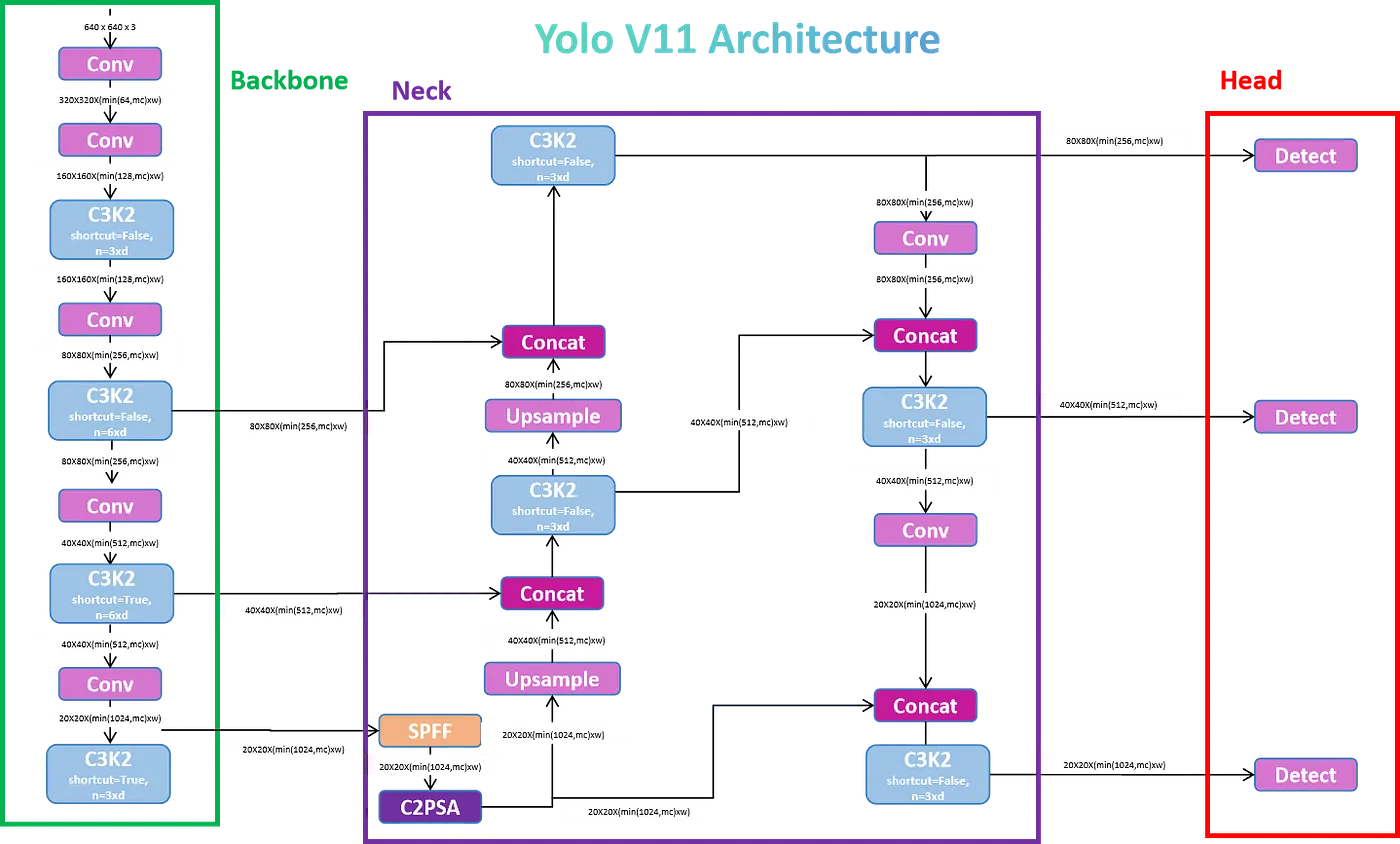
YOLOv11: A Deep Dive
High-Level Overview
YOLOv11 is the latest iteration of the "You Only Look Once" object detection algorithm. It operates in a single pass, dividing the input image into a grid. Each grid cell predicts bounding boxes and class probabilities for objects within its region. This "one-shot" approach makes YOLOv11 exceptionally fast.
Key Architectural Components
-
Backbone:
- Extracts meaningful features from the input image.
- Typically employs efficient architectures like EfficientNet or CSPNet.
- Progressively downsamples the image while increasing the number of feature channels.
-
Neck:
- Aggregates features from different levels of the backbone.
- Combines rich semantic information with fine-grained spatial details.
- Introduces the C3k2 block for improved efficiency:
- Replaces the C2f block used in previous versions.
- Employs two smaller convolutions instead of one larger convolution.
-
Detection Heads:
- Make final predictions: bounding box coordinates, object class probabilities, and objectness scores.
- Typically use multiple detection heads operating at different scales.
Key Innovations
- C3k2 Block: Enhances efficiency in the neck.
- SPFF (Spatial Pyramid Pooling - Fast): Extracts features at different spatial scales.
- C2PSA (Convolutional block with Parallel Spatial Attention): Refines feature representations.
Training and Inference
- Training:
- Uses a combination of techniques, including:
- Loss Function: Penalizes errors in bounding box predictions, object classification, and objectness scores.
- Data Augmentation: Increases the model's robustness and generalization ability.
- We have run the model for 15 epochs.
- Uses a combination of techniques, including:
Results:
Detailed Analysis and Inference on Results
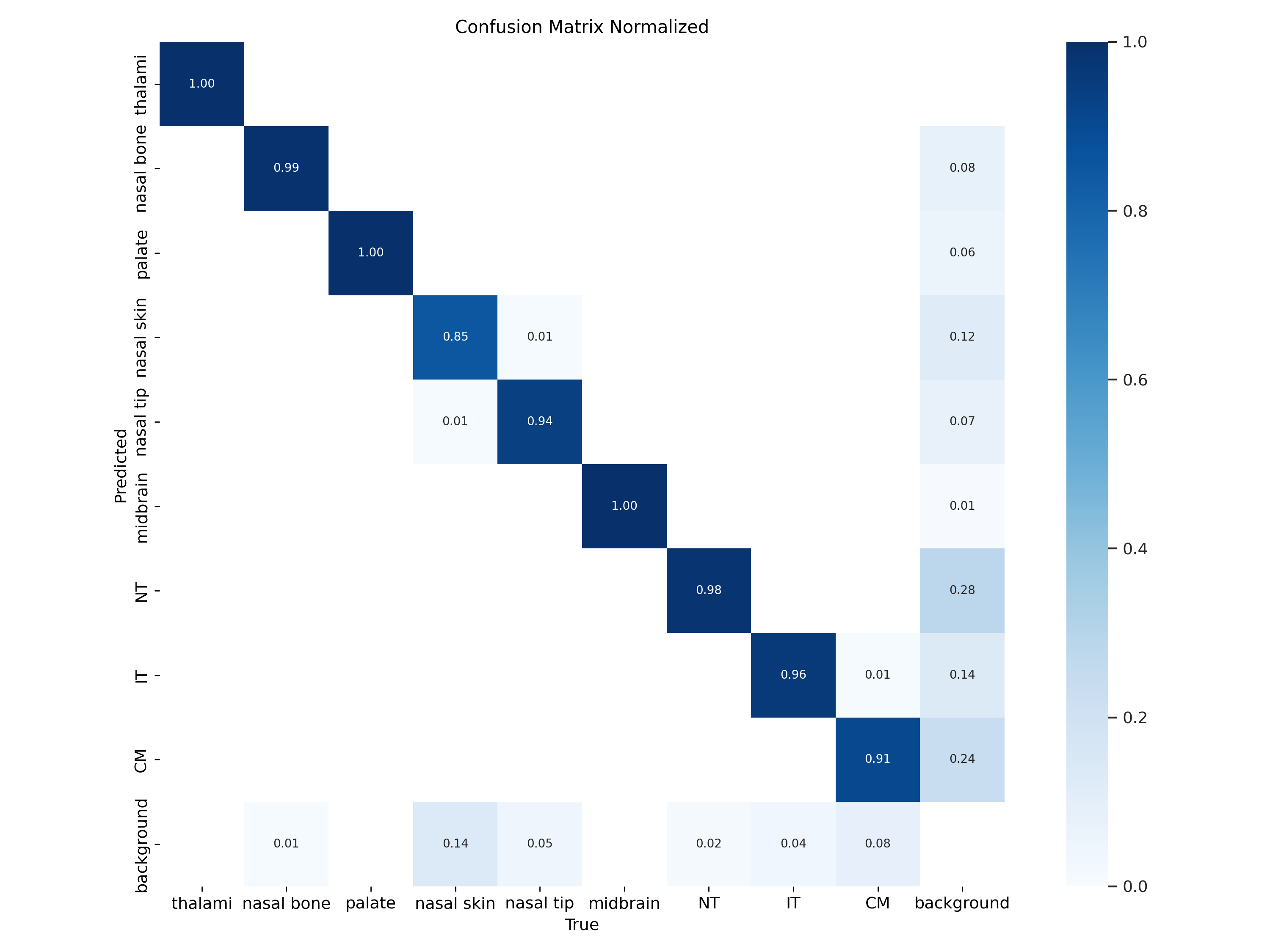
Confusion Matrix Analysis
The normalized confusion matrix provides a comprehensive view of the classification performance across different classes. The diagonal values represent the correct predictions, while off-diagonal values highlight misclassifications.
Observations from the Confusion Matrix:
- High Accuracy for Some Classes:
- Classes such as "thalami," "palate," and "midbrain" demonstrate excellent performance with nearly perfect accuracy values (e.g., 1.0 or close to it).
- Misclassifications:
- "Nasal skin" shows notable misclassification errors, with 15% of its samples classified as "background" and 1% misclassified as "nasal tip."
- "CM" and "IT" classes exhibit misclassifications with confusion particularly observed between "IT" and "CM" and vice versa.
- Background Class:
- Instances of "background" were occasionally confused with other classes such as "nasal skin" (14%).
Insights:
- The confusion matrix indicates robust performance for well-defined classes like "thalami" and "midbrain."
- Challenges exist for classes with overlapping features such as "nasal skin" and "background."
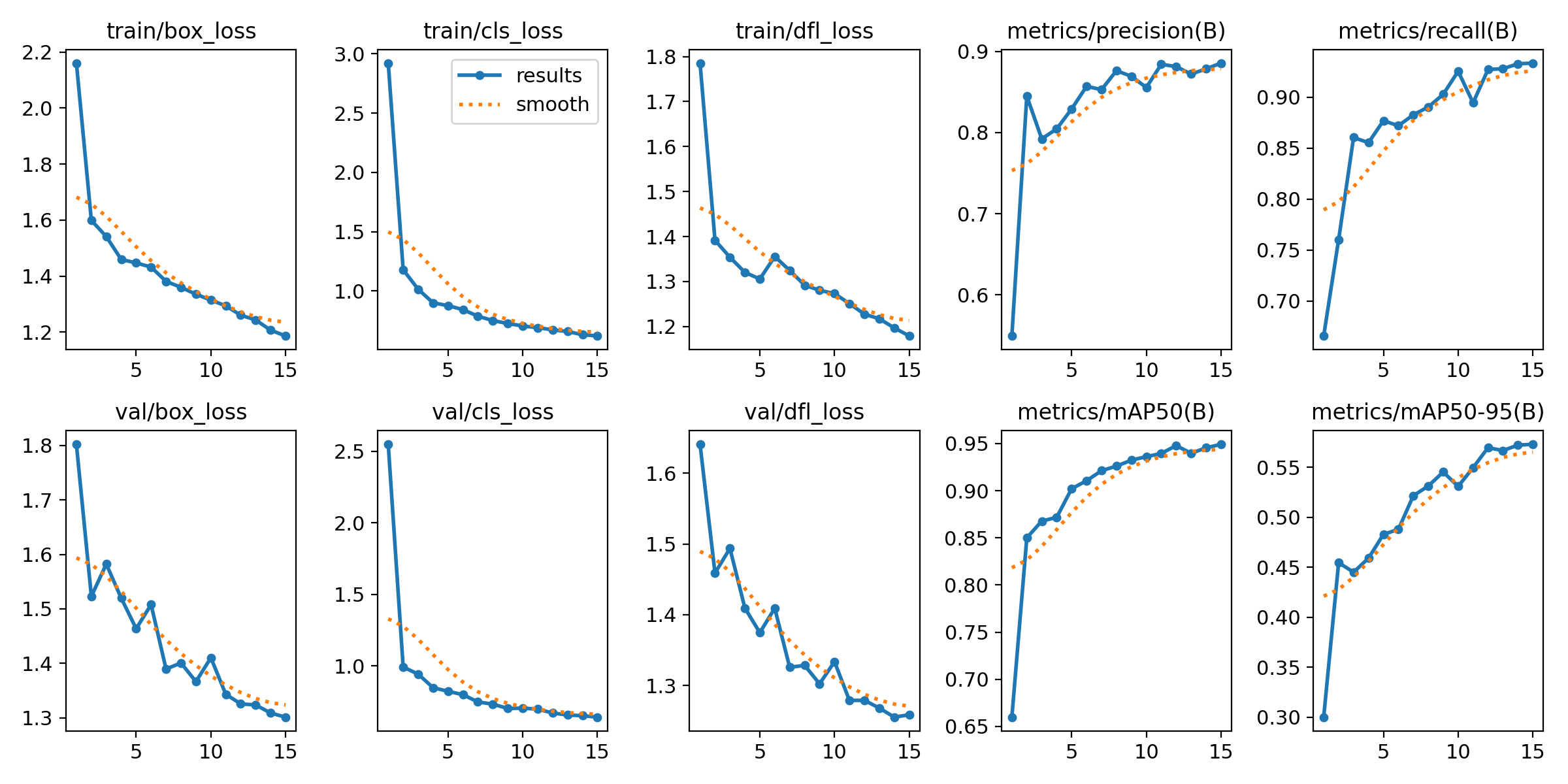
Training Metrics Overview
Epoch-wise Metrics
Key Metrics Observations Across Epochs:
- Box Loss: Progressive reduction from 1.432 in epoch 6 to 1.186 in epoch 15 indicates that the model improved in localizing bounding boxes.
- Class Loss: Decreased steadily from 0.8418 to 0.62, showing improved classification accuracy.
- DFL Loss: Reduced from 1.356 to 1.179, reflecting better model confidence in boundary and feature learning.
General Trends:
- The model shows consistent improvement over the epochs, as seen in the reduction of loss values.
- GPU Memory Usage: Varied between 4.54G and 4.7G, demonstrating resource stability during training.
- Training Speed: Each epoch completed in approximately 16-17 seconds with consistent performance metrics.
Validation Results Summary
Key Performance Metrics:
- Precision (P): Indicates the model’s ability to avoid false positives.
- Recall (R): Measures the capability of detecting true positives.
- mAP50 and mAP50-95: Provide a standard evaluation metric for object detection, reflecting precision-recall performance.
Final Results for All Classes:
- Precision: 0.885
- Recall: 0.933
- mAP50: 0.949
- mAP50-95: 0.575
Class-wise Performance:
- Top-Performing Classes:
- "Thalami" and "midbrain" achieved near-perfect precision and recall with mAP50 values of 0.995.
- Challenged Classes:
- "CM": Precision and recall were 0.801 and 0.853, respectively, indicating scope for improvement.
- "Nasal skin": Struggled with lower mAP50-95 (0.402) due to overlapping features with other classes and background.
Inference and Recommendations
Strengths:
- Robust detection for well-defined classes like "thalami," "palate," and "midbrain."
- Model performance steadily improved with training, as evidenced by decreasing loss values and increasing mAP50.
Weaknesses:
- Overlapping classes such as "IT" and "CM" or "nasal skin" and "background" present classification challenges.
- Lower mAP50-95 values for some classes highlight difficulty in precise localization across IoU thresholds.
Recommendations:
- Data Augmentation:
- Include more diverse examples of challenging classes like "nasal skin" to improve differentiation.
- Hyperparameter Tuning:
- Experiment with learning rates, weight decay, and anchor box configurations to enhance precision and recall.
- Post-Processing:
- Refine the non-maximum suppression (NMS) parameters to reduce misclassification in overlapping categories.
- Model Architecture:
- Consider integrating a hybrid approach (e.g., CNN-transformer models) for enhanced feature extraction and classification.
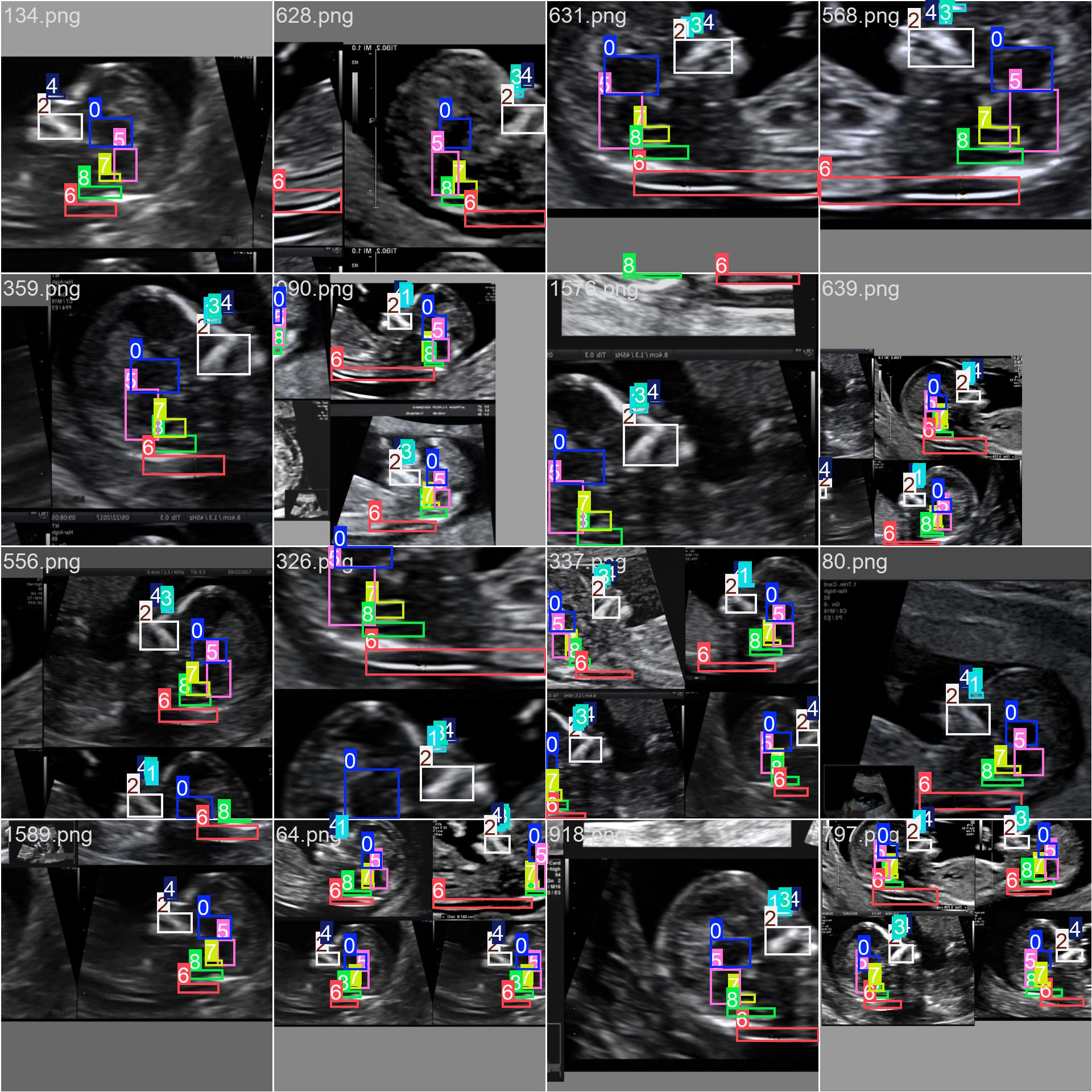
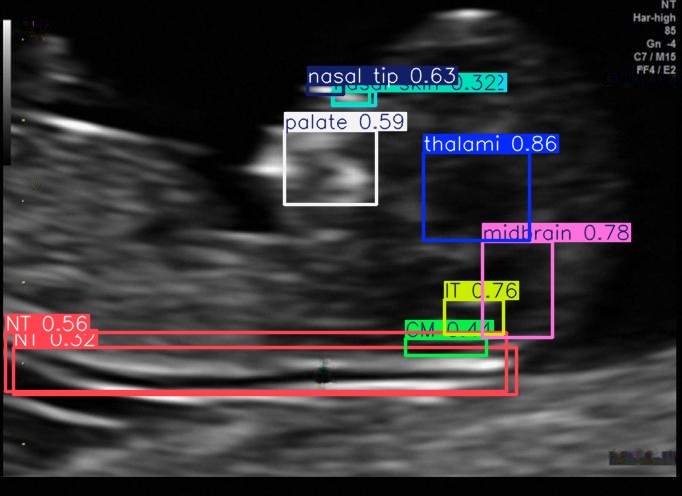
Testing on a sample test image
Conclusion
The model demonstrates strong performance overall, with high mAP50 and robust detection capabilities for certain classes. However, specific challenges remain for overlapping and ambiguous classes, necessitating targeted improvements through data augmentation, architecture enhancement, and hyperparameter tuning.