Exploring the Capabilities of Stable Diffusion for Data Augmentation in Deep Learning Based Visual Inspection of Electromagnetic Coils.
Table of Contents
- Aim of the Project
- Project Structure
- Results of Base Model
- Results of Performance Comparison with Augmented Data
- Setup Instructions
Cover Image

Aim of the Project
In this study, we investigate the capabilities of Stable Diffusion for data augmentation in deep learning-based visual inspection of electromagnetic coils. We first construct two base models: a transformer-based model, Distillation with no labels Version 2 using ViT-Large architecture (DINOv2-L), and a CNNs-based model, EfficientNet Version 2 Large variant (EfficientNetV2-L). After developing the base models, we generate images using Stable Diffusion’s img2img and Dreambooth’s txt2img techniques. These generated images are then added to the training dataset to evaluate whether there is an improvement in the F1-score.
Project Structure
ai-faps-ekaansh-khosla/
├── Base_model/ # all files of Base model
│ ├── labels/ # all files of labels for Base model
| | ├── splits/ # all splits of train.csv
| | | ├── train_half.csv # 50% of train.csv
| | | ├── train_quarter.csv # 25% of train.csv
| | | ├── train_ten.csv # 10% of train.csv
| | ├── analysis_of_coils.pdf # Analysis of coils, how splits are chosen
| | ├── analysis_of_splits.xlsx # Analysis of all splits(train, validation, test)
| | ├── test.csv # test file
| | ├── train.csv # train file
| | └── validation.csv # validation file
│ └── models/ # DinoV2_L and EfficientNet_V2_L results
│ ├── DinoV2_L/ # all files of DinoV2_L
| | ├── 10%_data/ # Optuna and test results using 10% training data
| | ├── 100%_data/ # Optuna and test results using 100% training data
| | ├── 25%_data/ # Optuna and test results using 25% training data
| | ├── 50%_data/ # Optuna and test results using 50% training data
| | ├── Freezing_Layers_experiments/ # DinoV2-L layer freezing experiments
| | └── Visualization_dinoV2_l/ # Visualization of Optuna Study
│ └── EfficientNet_V2_L/ # all files of EfficientNet_V2_L
| ├── 10%_data/ # Optuna and test results using 10% training data
| ├── 100%_data/ # Optuna and test results using 100% training data
| ├── 25%_data/ # Optuna and test results using 25% training data
| ├── 50%_data/ # Optuna and test results using 50% training data
| └── Visualization_efficientNet_l/ # Visualization of Optuna Study
|
├── Modular_code/ # Modular code files for reproducibility
| ├── Optuna/ # all files for Optuna
| │ ├── config.py # Define all training labels and image paths
| │ ├── data_loader.py # load data
| │ ├── main.py # run this file to have optuna study
| │ ├── model_dino.py # Define DINOv2-L model
| │ ├── model_efficientnet.py # Define EfficientNetV2-L model
| │ ├── optimization.py # Define Objective function of Optuna
| │ └── trainer.py # Training loop
| └── Testing/ # all files for Testing a model
| ├── config.py # Define all training labels and image paths
| ├── data_loader.py # load data
| ├── main.py # run this file for testing a model
| ├── model_dino.py # Define DINOv2-L model
| ├── model_efficientnet.py # Define EfficientNetV2-L model
| └── train_and_test.py # Training and Testing loop
|
├── stable_diffusion_enhanced_models/ # all files of model enhanced by Augmented images
| ├── dreambooth_txt2img/ # all files of Dreambooth technique
| │ ├── calculating_FID_values/ # all files of calculating FID files
| | | ├── calculate FID.ipynb # calculating FID Code
| | | ├── fid_values_Dreambooth_txt2img.csv # Results of FID
| | | └── get_random500_images.ipynb # filtering images to get one type of defect
| │ ├── data_transformation_files/ # all files for data transformation for Dreambooth
| | | ├── defects_split/ # Excel files for each type of defect
| | | ├── get_required_images.ipynb # code for seperating images of each defect
| | | ├── randomly_selecting_100_images.ipynb # selection 100 images for Dreambooth training
| | | ├── resize_images-720x468.ipynb # convert images from 468x468 to 720x468
| | | └── resize_images_468x468.ipynb # convert images from 720x468 to 468x468
| │ ├── labels/ # all labels including augmented images
| | | └── train_ten_25_text2img_dreambooth.csv # labels of 10% to 25% data
| │ ├── models/ # Results of model enhanced by dreambooth
| | | ├── DinoV2_L/10%-25%/ # DinoV2_L results
| | | └── EfficientNetV2_L/10%-25%/ # EfficientNetV2_L results
| │ ├── Apply_configuration.ipynb # Applying configuration before running Dreambooth
| │ └── dreambooth_txt2img.py # Dreambooth training file
| └── stable_diffusion_img2img/ # all files of stable_diffusion_img2img technique
| ├── calculating_FID_values/ # all files of calculating FID files
| | ├── calculate FID.ipynb # calculating FID Code
| | ├── fid_values_SD_img2img.csv # Results of FID
| | └── get_random500_images.ipynb # filtering images to get one type of defect
| ├── labels/ # all labels including augmented images
| | ├── 100_200_augmented.csv # labels of 100% to 200% data
| | ├── 10_25_augmented.csv # labels of 10% to 25% data
| | ├── 10_50_augmented.csv # labels of 10% to 50% data
| | ├── 25_50_augmented.csv # labels of 25% to 50% data
| | └── 50_100_augmented.csv # labels of 50% to 100% data
| ├── models/ # Results-model enhanced by stable_diffusion_img2img
| | ├── DINOv2/ # DinoV2_L results
| | └── EfficientNetV2/ # EfficientNetV2_L results
| └── img2img.py # main file changed in CompVis/stable-diffusion
├── README.md # README
├── Results_base_model.png # Results summary of base model
├── Results_base_model.xlsx # Results summary of base model
├── Results_stable_diffusion_img2img.png # Results summary of stable_diffusion_img2img
├── Results_stable_diffusion_img2img.xlsx # Results summary of stable_diffusion_img2img
├── environment.yml # environment file
├── overview.png # Results summary of stable_diffusion_img2img
└── requirements.txt # requirements file
Results of Base Model
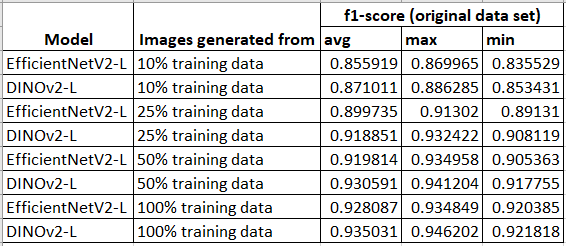
Model Performance Comparison with Augmented Data
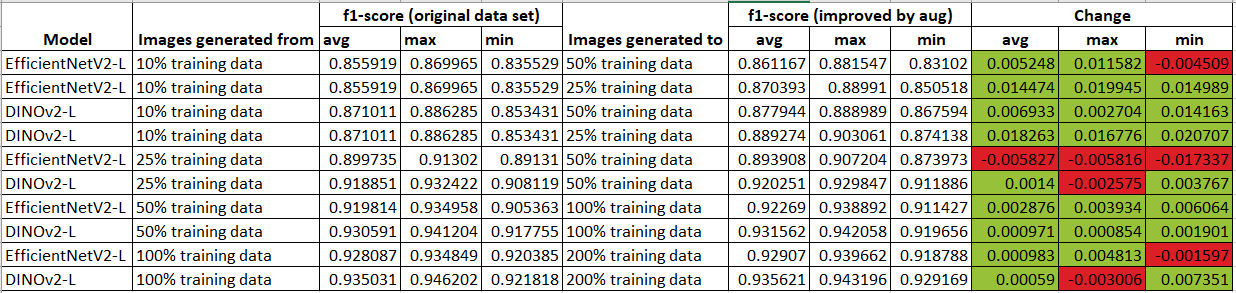
Setup Instructions
Create the Environment
Using Conda:
conda env create -f environment.yml
Using Pip:
pip install -r requirements.txt
Running the Models
1. For Optuna:
- Navigate to the
Modular_code/Optunadirectory. - Update
config.pywith the necessary training labels and image paths. - Run the following command to perform Optuna-based hyperparameter optimization:
python main.py
2. For Testing:
- Navigate to the
Modular_code/Testingdirectory. - Update
config.pywith the testing labels and image paths. - Run the following command to test the models:
python main.py
Running Stable Diffusion img2img Technique
Steps:
-
Clone the Stable Diffusion repository:
git clone https://github.com/CompVis/stable-diffusion.git cd stable-diffusion -
Download the pre-trained model (
sd-v1-4.ckpt) from Hugging Face and place it in the root directory of the cloned repository. -
Run the img2img script with the following command:
python scripts/img2img.py --prompt "Image similar to this" --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1 --n_iter 4 --precision autocast --strength 0.05 --ddim_steps 500
Running Dreambooth Technique
Steps:
- Navigate to the directory containing the Dreambooth script.
- Run the Dreambooth script:
python dreambooth.py