Abstract
Novel view synthesis from sparse views has been a popular topic in 3D computer vision. To achieve fast rendering and quality improvement, a recent framework, InstantSplat, replaced traditional Structure-from-Motion pipelines by combining multi-view stereo predictions and 3D Gaussian Splatting. In this project, we modify InstantSplat by replacing the DUSt3R model with its improved version, the MASt3R model, which enhances image matching and robustness. In InstantSplat, DUSt3R is the key component of 3D Gaussian initialization through providing estimated geometric priors, which is a set of densely covered and pixel-aligned points. However, despite robust to viewpoint changes, DUSt3R's estimated matching from different views is relatively imprecise. To remedy this flaw, MASt3R introduced a second head for the transformer decoders to match the local features of different views. This provides a more accurate structure prior to the initialization under sparse views. We show how applying the MASt3R model improves the rendering image quality.
Introduction
Novel view synthesis has been a crucial task in 3D reconstruction, while the quality depends on the accuracy of estimated camera parameters and 3D point clouds. This makes Structure-from-Motion methods a popular choice for precise estimation of camera poses and 3D points, such as COLMAP [8]. However, Structure-from-Motion methods are time-consuming for their complicated pipeline, and they are also not reliable under sparse-view conditions due to scarce feature matching. This causes errors to accumulate throughout the process.
A novel approach for dense unconstrained stereo 3D reconstruction (DUSt3R) solved the difficulties of Structure-from-Motion methods [11]. Its framework integrates transformer-based architectures to provide dense and accurate geometric priors. Unlike Structure-from-Motion methods, the DUSt3R model gains robustness and simplicity from its end-to-end model structure. This means dense and accurate 3D representation can be completed solely from image pairs even under sparse views, without prior scene and camera information. The confidence-aware regression loss is defined as:
where
For high-quality scene reconstruction, 3D Gaussian Splatting [5] has been an efficient rendering method compared to other techniques, such as NeRF. This method optimizes anisotropic 3D Gaussians which are initialized at points estimated from COLMAP. However, the optimization process involves adaptive density control, which is a complex strategy for creating or deleting 3D Gaussians. Due to random or inaccurate initialization, this tuning strategy is necessary to retain its rendering quality. It is not only time-consuming but also affects the view synthesis performance. Recently, a novel framework, InstantSplat [3], solved this problem by combining multi-view stereo predictions and 3D Gaussian Splatting to reconstruct large-scale scenes under sparse views within a short amount of time. The DUSt3R model plays a key role in predicting the structure prior and camera poses. This initialization is further used for joint optimization of the Gaussian parameters and adjustment of the camera pose parameters, where the formulation is as follows:
where
In this work, we present a modified pipeline of the InstantSplat by using another existing model for geometric estimation. We replace the DUSt3R model with its improved version of matching and stereo 3D reconstruction (MASt3R). The MASt3R model [6] contains the original DUSt3R model with an attached second head on its decoder output. The resulting architecture enhances local feature matching for more precise predictions. Its training objective is the combination of both regression loss in Eq. (1) and matching loss (infoNCE loss), defined as:
and
where
As an extension of the original work, we discuss the potential of introducing feature matching for the original InstantSplat framework to improve the 3D rendering quality. We also point out possible directions from analyzing the results.
Background
The goal of novel view synthesis is to generate unseen views of an object or scene with given images. To work on sparse-view reconstruction, various research introduced different regularization techniques for the optimization of Neural Radiance Fields and 3D Gaussian Splatting methods. For instance, RegNeRF [7] and SparseNeRF [10] used geometric regularization on radiance fields with the depth prior loss. FSGS [13], and SparseGS [12] introduced monocular depth estimators or diffusion models on Gaussian Splatting. These methods require the ground-truth camera estimated from traditional Structure-from-Motion methods.
However, under sparse-view conditions, this type of method cannot provide accurate estimations due to the lack of image correspondences. Hence, some recent studies have started to focus on unconstraint 3D optimization with direct input of only images. For instance, Nope-NeRF [1] and CF-3DGS [4] utilized depth information as a constraint on optimization. With the estimation from DUSt3R, InstantSplat improved the speed of rendering through joint optimization for Gaussian attributes and camera parameters [3].
For the estimation of geometric and structural priors, an improved model, MASt3R, derived from DUSt3R provides a more accurate local feature matching. Recently, some works have started to enhance their pipelines by introducing the MASt3R model. For example, CSS [2] and Splatt3R [9] constructed a Gaussian primitive for each point predicted from MASt3R. These works showed the potential of applying MASt3R to the pipeline for enhancement of rendering quality, especially for local feature matching.
Method
In this project, we modify the original pipeline of the InstantSplat framework by replacing the DUSt3R model with MASt3R. We keep the remaining pipeline frozen which includes an additional point cloud downsampling. This process achieves uniform and concise initialization with the farthest point sampling. The joint optimization then trains the 3D Gaussians and camera parameters with photometric loss.
For the experimental setup, we select 3 scenes from each Tanks and Temples, MVImgNet, and MipNeRF360 datasets. To split the train and test dataset, we uniformly sample 24 images from each scene. These images are split in an interleaving order, in which the odd numbers are for training and the even numbers are for testing. For sparse view training, we pick 3 and 6 images as the training sets for each experiment. In addition, we also pick the barn scene from Tanks and Temples to do experiments on extreme angles of the scene. We later discuss the improvements for the rendering quality by using MASt3R.
For implementation details, we use the public pre-trained DUSt3R and MASt3R checkpoints with the corresponding settings for the encoder (ViT-Large), decoder (ViT-Base), head (Dense Prediction Transformer), and supporting resolutions (512x384, 512x336, 512x288, 512x256, 512x160). The optimization iteration for 3D Guassians is set to 1000. The test rendering uses the frozen Gaussian parameters after training, but still conducts pose optimization rather than directly using ground truth COLMAP poses. We perform all experiments on one Nvidia RTX 4070 GPU (12GB) using both DUSt3R and MASt3R models for fair comparisons.
For metrics, we evaluate the improvement of depth and confidence estimation by comparing the DUSt3R and MASt3R models from qualitative results. For novel view rendering, we include standard evaluation metrics, structural similarity index measure (SSIM), learned perceptual image patch similarity (LPIPS), and peak-signal-to-noise ratio (PSNR), for the quantitative results. The absolute trajectory error (ATE) is also used to evaluate the camera poses.
Results
We evaluate the depth and confidence maps for using DUSt3R and MASt3R and pick some scenes of each dataset for comparison shown in Figs. 1 to 4. Overall, the MASt3R model has more accurate depth estimations to detect the sharp edge of the objects in the scenes, such as the bowl in Fig. 1 and the car in Fig. 2. We discover that DUSt3R cannot give accurate predictions for transparent objects and reflections while MASt3R is more precise, some clear examples are the transparent cup in Fig. 1 and the car surface in Fig. 2. The local feature matching of MASt3R can detect small components of the scene, having a higher confidence area than DUSt3R, such as the car wheel in Fig. 2 and the curved metal bar in Fig. 4. However, dense repeated local patterns can be difficult to distinguish for MASt3R due to confusion during feature matching, resulting in a lower confidence area. For example, the square plate in Fig. 1 and the barn wall in Fig. 4.
Quantitative evaluations of Tanks and Temples, MVImgNet, and MipNeRF360 datasets are summarized in Tab. 1. In MipNeRF360, both models have similar performance on all metrics. We consider one possible reason may be the low rendering quality, where some 360-degree reconstruction scenes require more iteration for Gaussian optimization. There is an improvement with MASt3R for MVImgNet in both 3 and 6 views, whereas only a slight improvement for Tanks and Temples in 3 views. We observe that artifacts appear in the areas where the background is not continuous when using DUSt3R, such as the spaces between wooden strips of a ladder or bench. MASt3R reconstructs the scenes with fewer artifacts in those specific areas, which may be a reason for boosting the performance in MVImgNet but not all cases in Tanks and Temples.
Among all experiments, the barn scene from Tanks and Temples improves the most (SSIM and LPIPS: 16% and 21%), while the car scene from MVImgNet also has a significant boost in its performance (SSIM and LPIPS: 11% and 22%). We evaluate the barn scene for its feature matching under extreme angles in 3 views shown in Fig. 5, while also showing the comparison of test views in Fig. 6. With DUSt3R, the main artifact comes from the curved metal bar, while the object is closer to the ground truth with MASt3R. These evaluations show concrete evidence of how local feature matching helps the reconstruction of large angle conditions, having a higher confidence area with MASt3R.
For the Gaussian optimization, the training time is similar for both DUSt3R and MASt3R, which is around 40 seconds (3 views) and 50 seconds (6 views) for 1000 iterations. The camera pose test is also similar in both cases.
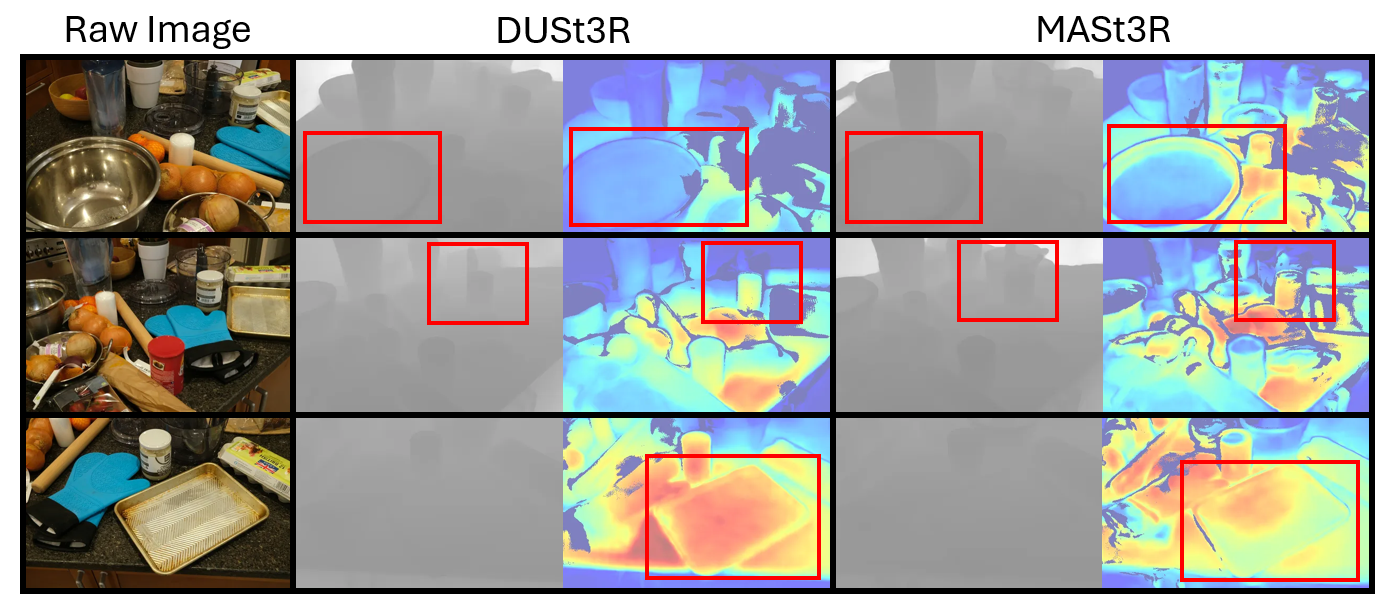
Figure 1. The depth and confidence estimation of DUSt3R and MASt3R models for the counter scene from the MipNeRF360 dataset. Note that the bowl, transparent cup, and square plate are marked with red squares.

Figure 2. The depth and confidence estimation of DUSt3R and MASt3R models for the car scene from the MVImgNet dataset. Note that the car surface and wheels are marked with red squares.

Figure 3. The depth and confidence estimation of DUSt3R and MASt3R models for the family scene from the Tanks and Temples dataset. Note that the statue is marked with red squares.

Figure 4. The depth and confidence estimation of DUSt3R and MASt3R models for the barn scene from the Tanks and Temples dataset. Note that the curved metal bar is marked with red squares.

Figure 5. The visualization of local feature matching under three views for the barn scene from the Tanks and Temples dataset. Each point matches correctly from one view to another.

Figure 6. The visual comparison of the rendering quality for DUSt3R and MASt3R models after Gaussian training under three views for the barn scene from the Tanks and Temples dataset. Note that the test views are new views for the 3D Gaussians, however, the camera poses of test views 1, 5, and 11 are very close to the corresponding three training views. These specific test views should have better rendering performance than other test views that are farther from the training views.

Table 1. The quantitative evaluations on MipNeRF360, MVImgNet, and Tanks and Temples datasets. InstantSplat with MASt3R framework has a better rendering quality for MVImgNet, and Tanks and Temples datasets, while the results are similar to using DUSt3R for MipNeRF360.
Conclusion
We modified the InstantSplat framework to adapt to the MASt3R model and also evaluated its capabilities of local feature matching. Results showed that MASt3R outperformed DUSt3R in specific cases, such as transparent objects, reflections, and extreme angles. In our experiments, the largest improvement in rendering performance is in the barn scene, with an increase of 16% for SSIM and 21% for LPIPS. The scene and image picking may be a potential reason for the difference in the ATE evaluation for some cases. However, we discovered that the shortcomings mostly came from the lack of consistency rather than the camera poses. The elimination of this border could be a potential future direction to achieve an overall improvement in local feature matching, focusing on the information for consistency. This could involve redesigning the photogeometric loss or employing smoothing techniques.
We demonstrated fast rendering frameworks can also be enhanced through feature matching with a small set of experiment. With this initial validation, a possible way to extend this advantage is to add regularization constraints on the loss function for depth estimations. Larger experiment sets should also be conducted with a more complete result for the work. These future directions can be potential ways of discovering how to strengthen fast and accurate scene reconstruction under sparse-view conditions.
References
[1] Wenjing Bian, Zirui Wang, Kejie Li, Jia-Wang Bian, and Victor Adrian Prisacariu. Nope-nerf: Optimising neural radiance field with no pose prior, 2023.
[2] Runze Chen, Mingyu Xiao, Haiyong Luo, Fang Zhao, Fan Wu, Hao Xiong, Qi Liu, and Meng Song. Css: Overcoming pose and scene challenges in crowd-sourced 3d gaussian splatting, 2024.
[3] Zhiwen Fan, Wenyan Cong, Kairun Wen, Kevin Wang, Jian Zhang, Xinghao Ding, Danfei Xu, Boris Ivanovic, Marco Pavone, Georgios Pavlakos, Zhangyang Wang, and Yue Wang. Instantsplat: Sparse-view sfm-free gaussian splatting in seconds, 2024.
[4] Yang Fu, Sifei Liu, Amey Kulkarni, Jan Kautz, Alexei A. Efros, and Xiaolong Wang. Colmap-free 3d gaussian splatting, 2024.
[5] Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering, 2023.
[6] Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r, 2024.
[7] Michael Niemeyer, Jonathan T. Barron, Ben Mildenhall, Mehdi S. M. Sajjadi, Andreas Geiger, and Noha Radwan. Regnerf: Regularizing neural radiance fields for view synthesis from sparse inputs, 2021.
[8] Johannes L. Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[9] Brandon Smart, Chuanxia Zheng, Iro Laina, and Victor Adrian Prisacariu. Splatt3r: Zero-shot gaussian splatting from uncalibrated image pairs, 2024.
[10] Guangcong Wang, Zhaoxi Chen, Chen Change Loy, and Ziwei Liu. Sparsenerf: Distilling depth ranking for few-shot novel view synthesis, 2023.
[11] Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy, 2024.
[12] Haolin Xiong, Sairisheek Muttukuru, Rishi Upadhyay, Pradyumna Chari, and Achuta Kadambi. Sparsegs: Realtime 360° sparse view synthesis using gaussian splatting, 2024.
[13] Zehao Zhu, Zhiwen Fan, Yifan Jiang, and Zhangyang Wang. Fsgs: Real-time few-shot view synthesis using gaussian splatting, 2024.
Acknowledgements and Codebase
This work is an extension that is based on the original research paper and codebase of InstantSplat, DUSt3R, and MASt3R. We sincerely appreciate these authors and their contribution of releasing the original code to the open-source community. We hope this work can also be helpful for others, especially those who are interested in improving 3D Gaussian Splatting on sparse-view 3D reconstruction tasks.