
Rapid advancements in the field of GenerativeAI for producing hyper-realistic human photographs have led to a steady increase in cases of forgeries, identity theft and other digital crimes, endangering the credibility of media reports. In this study, we investigate the potential of a modified Resnet Architecture with LeakyReLU for distinguishing authentic human photographs from DeepFakes. This effort aims to extract features from images that can be used to distinguish between real and fake photos.
The remarkable progress in Generative AI-based applications combined in the recent times has enabled the generation of high-quality synthetic images that can often be mistaken for real images. While the rapid development in this field has opened up exciting new possibilities across industries, it has also raised significant ethical concerns regarding misuse.
Applications of Generative AI that can produce lifelike images and videos of people have the risk of being misused for fraudulent purposes, disseminating false information, and depicting people in vulnerable ways. They can also result in serious identity theft.
This project aims to study the use of Deep CNNs, specifically Residual Networks with a modified activation function, to evaluate its potential for identifying deepfakes.
In this paper[1], the authors perform a comparative analysis between CNNs and Vision Transformers in detecting deepfakes using well established-datasets. detection models and conducted experiments over well-established deepfake datasets. The paper also highlights the unique capabilities of CNNs and Transformers models and documents the observed relationships among the different deepfake datasets, to aid future developments in the field.
In this paper[2], the authors explore the use of a modified Resnet18 architecture with multilayer max pooling to classify deepfakes.
Our baseline model incorporates a Resnet50 architecture which incorporates skip-connections or shortcut-connections in the network to address the issue of vanishing/exploding gradients in deeper networks using the concept of Residual Blocks.
In this architecture issue of the vanishing/exploding gradient is addressed using a method known as skip connections. The skip connection connects activations of a layer to deeper layers by skipping some layers in between forming a leftover block known as a residual block. Resnet architecture is made by stacking these residual blocks together.
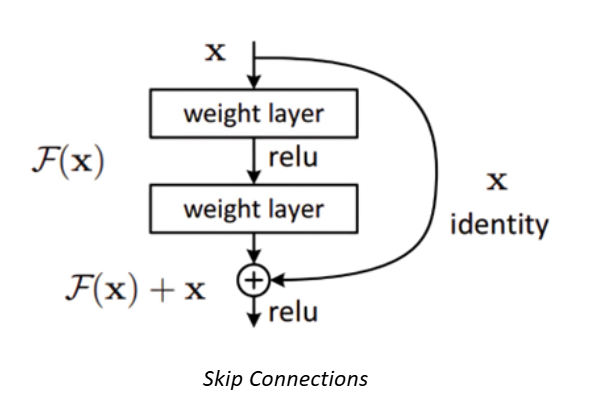
The strategy behind this network is to let the network fit the residual mapping rather than have layers learn the underlying mapping, i.e., instead of the initial mapping of H(x), the network fits,

The advantage of using skip connection is that, regularisation will skip any layer that degrades architecture performance. This makes the process of training an extremely deep neural network possible without encountering issues with vanishing or expanding gradients.
One of the key characteristics of modern deep CNNs is the use of non-saturated activation function instead of saturated activation functions (e.g. sigmoid, tanh) in order to solve the vanishing/exploding gradient problem. In most common activation function Rectified Linear Unit or ReLU, is a piecewise linear function which prunes the negative part to zero, while retaining the positive part.
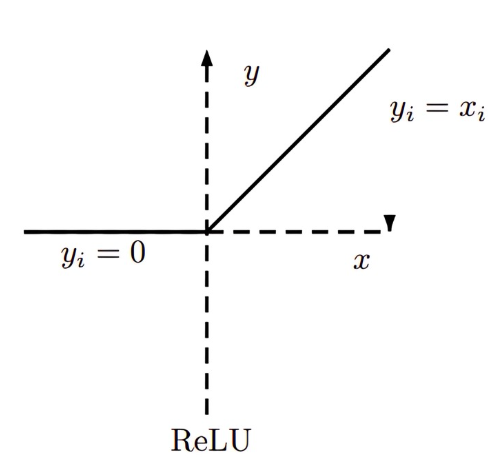
Formally, a ReLU activation is defined as,
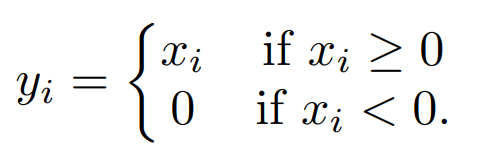
Leaky Rectified Linear activation is first introduced in acoustic model(Maas et al., 2013). In contrast to ReLU, in which the negative part is totally dropped, LeakyReLU assigns a non-zero slope to it.
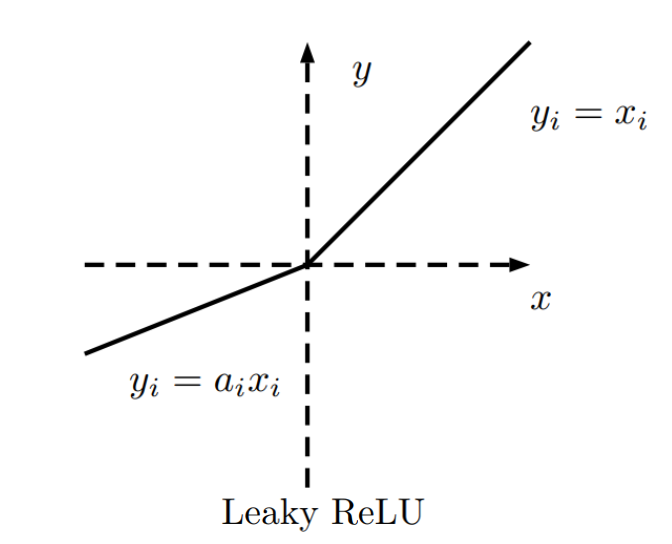
Mathematically, we have,
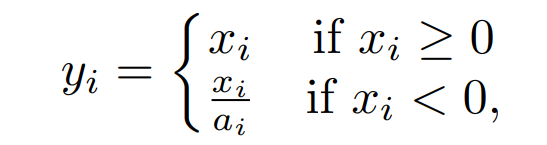
where ai is a fixed parameter in range (1, +∞).
Leaky ReLU address the Dying ReLU Problem[5] which is a kind of vanishing gradient. In this situation ReLU neurons become inactive and only output 0 for any input. It has been known as one of the obstacles in training deeper networks.
We evaluate classification performance on Modified Resnet50 architecture with Leaky ReLU activation function using Tensorflow2x. Cross Entropy Loss with Softmax function are used as the output layer of our network.
• Hardware: Kaggle T4 x2 is a GPU accelerator
• Augmentation: RandomFlip, RandomRotation, RandomZoom, RandomContrast
• LeakyReLU parameter value: 0.2
• Epochs: 100
• Training-Validation Split: 75
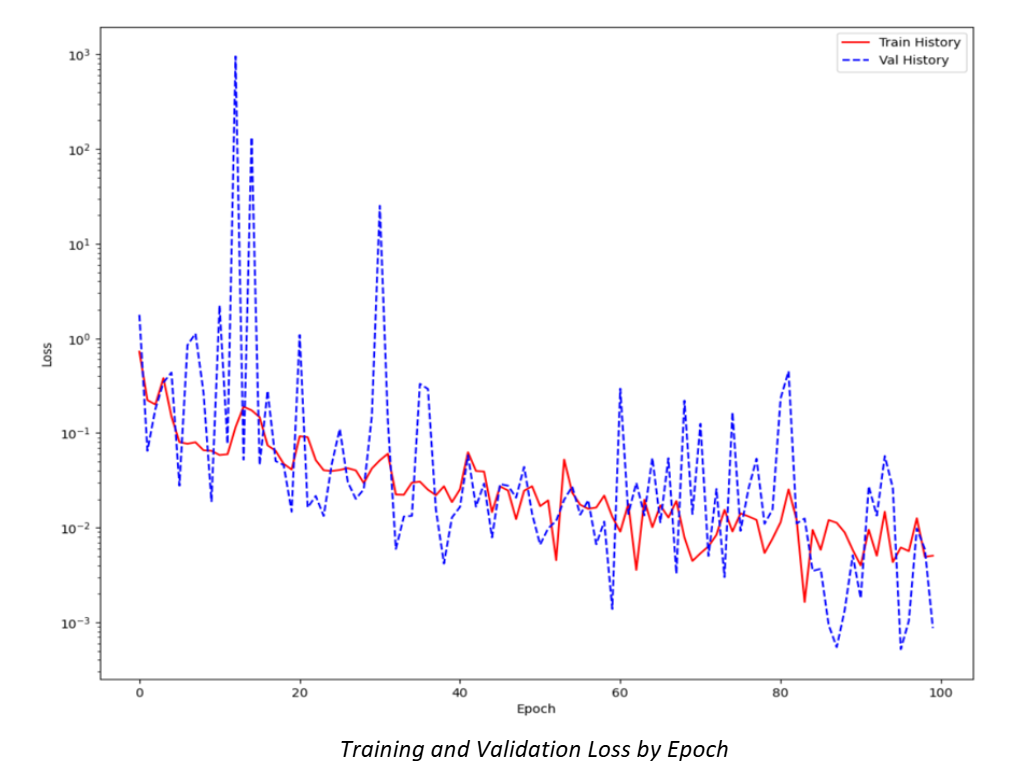
Training accuracy: 0.9975
Training loss: 0.0075
Validation accuracy: 0.9990
Validation loss: 0.0033

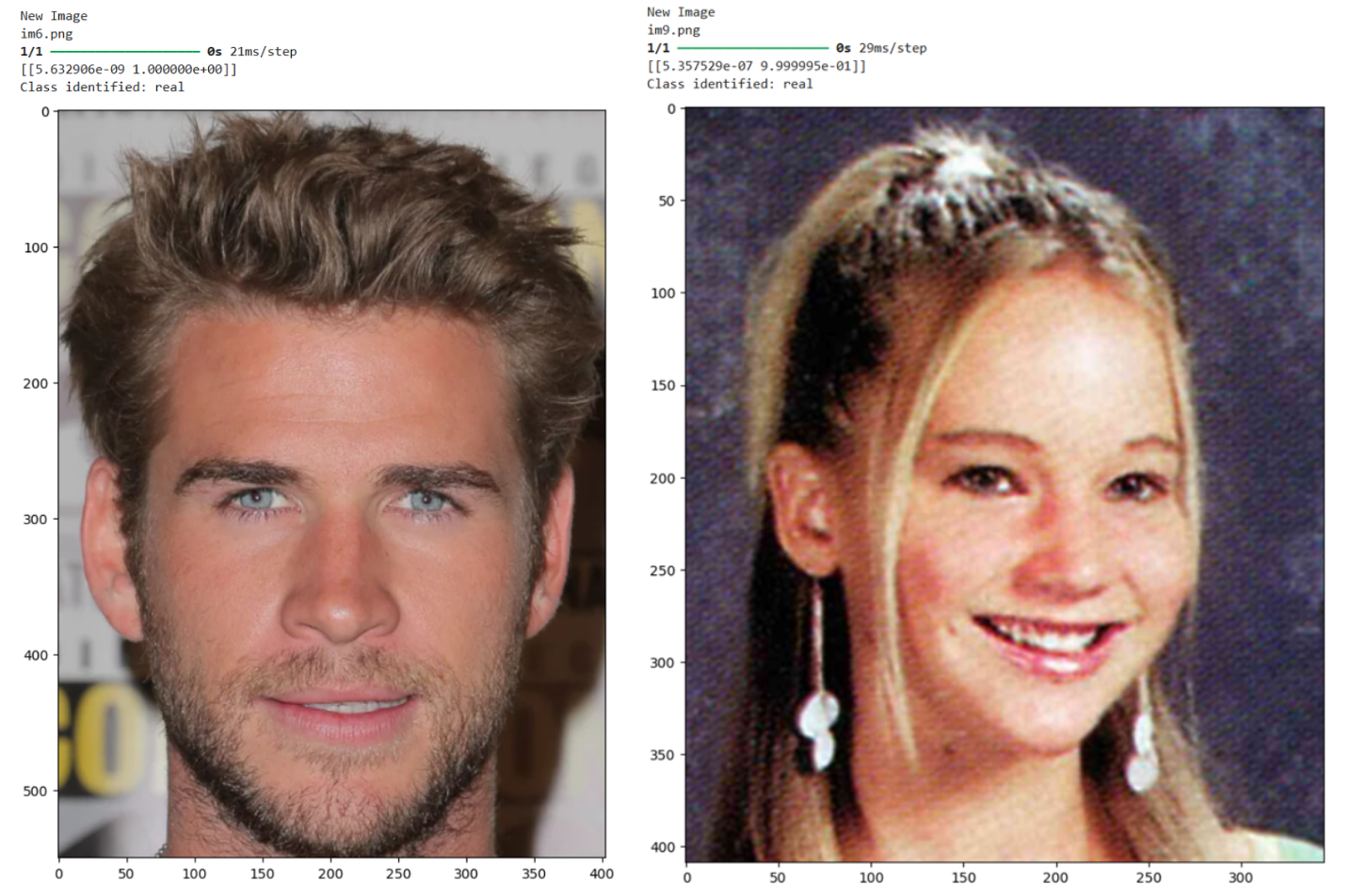
• Experimenting with data augmentation techniques to make the model more robust to quality changes
• Incorporating Explainable AI techniques for understanding the classification process and strategize improvements in the model performance
• Building a robust dataset to incorporate more variations of generated portraits