
Abstract
This study introduces CairoDep, a novel dataset and set of models for detecting depression in Arabic social media posts using state-of-the-art BERT transformers. We collected and labeled 7,000 posts in Modern Standard Arabic (MSA) and dialectal Arabic. Two pre-trained models, ARABERT and MARBERT, were fine-tuned on CairoDep v1.0, achieving F1-scores of 96.92% and 96.07%, respectively. The results surpass previous lexicon-based and machine learning methods, paving the way for AI-powered mental health applications tailored for Arabic speakers.
Introduction
Mental health issues, particularly depression, have become a global concern, affecting millions of people worldwide. The World Health Organization (WHO) reports that depression is one of the leading causes of disability and a major contributor to suicide. Early detection and intervention can significantly improve treatment outcomes. However, mental health services are often insufficient, especially in under-resourced regions. Additionally, the social stigma surrounding mental health prevents many individuals from seeking professional help, further exacerbating the problem.
With the widespread adoption of social media, people increasingly use these platforms to express their thoughts, emotions, and struggles. This presents an opportunity to leverage social media data for mental health detection using artificial intelligence (AI). While much research has focused on analyzing English-language posts for mental health insights, limited efforts have been made to develop models for Arabic, a language spoken by over 400 million people worldwide. This language gap leaves Arabic-speaking communities underserved by mental health AI solutions.
In this study, we aim to bridge this gap by utilizing advanced natural language processing (NLP) transformers for detecting depression in Arabic social media posts. Specifically, we fine-tuned two pre-trained BERT models for Arabic—ARABERT and MARBERT—on a newly created dataset, CairoDep v1.0, consisting of 7,000 labeled posts. These posts span both Modern Standard Arabic (MSA) and dialectal Arabic, making the models versatile across different linguistic variations.
Our results demonstrate the effectiveness of these transformer models, achieving accuracy and F1-scores above 96%, outperforming traditional machine learning and lexicon-based approaches. The success of this study opens the door for AI-powered mental health applications, including automated mental health assessments on social media platforms and chatbots for Arabic-speaking users.
Data Collection
In this section, we describe the data sources used to create CairoDep v1.0, a balanced dataset containing Arabic social media posts labeled as either depressed or non-depressed.
CairoDep v1.0 consists of 7,000 posts, with 3,600 labeled as depressed and 3,400 labeled as non-depressed. These posts include content in both Modern Standard Arabic (MSA) and Dialectal Arabic, primarily Egyptian and Gulf dialects. The dataset was assembled from five different sources to ensure linguistic and contextual diversity:
-
Crowdsourcing:
Anonymous posts were collected via a web form distributed among friends, colleagues, and social media groups. Contributors were asked to write posts categorized as either "Depressed" or "Normal." -
Mental Health Sites and Forums:
Using web scraping tools like BeautifulSoup, we extracted posts from platforms such as Nafsacy.cc and Arabic mental health pages, targeting sections where users shared depressive thoughts. -
Twitter API:
Posts indicating depression were collected using specific keywords recommended by a clinical psychiatrist. These keywords included emotionally significant terms related to distress and loss. -
Translation from English Datasets:
English posts from the Reddit Mental Health Dataset were translated into Arabic using Google Translate. Manual filtering was conducted to correct cultural and linguistic mismatches. -
Existing Arabic Datasets:
Normal posts were sourced from publicly available Arabic datasets, including Data World and SemEval-2018 Task 1, to ensure balance and consistency in non-depressed samples.
Data Verification
To ensure high-quality and meaningful data, we undertook multiple verification steps across all sources of posts. These efforts aimed to eliminate noise, address cultural and linguistic nuances, and guarantee that the dataset accurately represents depressed and non-depressed posts.
The following steps were undertaken:
-
Consultation with a Clinical Psychiatrist:
A psychiatrist reviewed the data to provide guidelines for identifying posts as potential indicators of depression. The PHQ-9 diagnostic scale was also consulted for reference. -
Review of Crowdsourced Data:
Each crowdsourced post was manually inspected to eliminate spam and confirm accurate labeling based on the psychiatrist’s criteria. -
Verification of Translations:
Translations were carefully reviewed to address cultural differences in meaning. For instance, literal translations such as "I want to go" were corrected to more context-appropriate translations like "I want to die" (أريد أن أموت). -
Filtering Forum and Social Media Posts:
Posts extracted from forums and social media platforms were manually screened to confirm alignment with the appropriate depression or normal category.
Data Preprocessing
In our experiments, we reused the preprocessing strategy initially designed for ARABERT when fine-tuning MARBERT, ensuring consistency across both models. This approach allowed us to maintain uniformity in the data preparation process, facilitating a fair comparison between the models and optimal performance on the same dataset.
Below are the key preprocessing steps applied:
-
Removal of Elongation:
Repeated letters used for emphasis (e.g., "تعبااااان") were reduced to their base form ("تعبان"). -
Diacritic Removal:
Diacritics were stripped to maintain consistency in word representation (e.g., "لَيسَ" became "ليس"). -
Stemming:
Words were reduced to their root form. For instance, "المسلمون" was decomposed into "مسلم" + "ون." -
URL Removal:
Links and irrelevant tokens were removed to prevent noise in the training data. -
Normalization:
Variants of the letter Alef (ا) were unified across the text (e.g., "أكتئاب" and "اكتئاب" became "اكتئاب").
Final Dataset
The CairoDep v1.0 dataset is composed of 7,000 posts, distributed as follows:
- MSA Posts: 2,000 (1,000 depressed, 1,000 normal)
- Dialectal Posts: 5,000 (2,600 depressed, 2,400 normal)
This dataset is publicly accessible on GitHub, providing a valuable resource for future research in Arabic NLP and mental health detection.
By employing a diverse set of data sources and thorough preprocessing, CairoDep v1.0 ensures both linguistic variety and quality, enabling reliable fine-tuning of ARABERT and MARBERT for depression detection tasks.
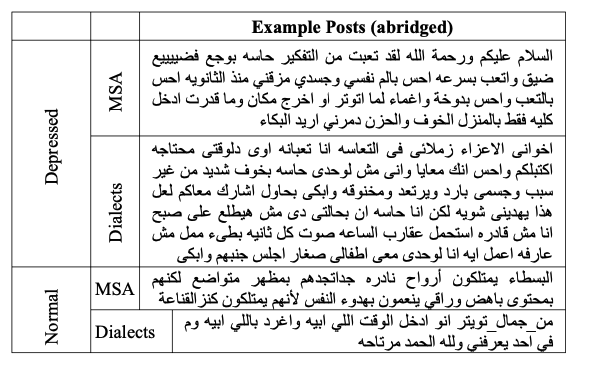
Below are samples from the dataset:
Models: ARABERT and MARBERT
ARABERT and MARBERT are two state-of-the-art transformer models specifically designed for Arabic natural language processing (NLP) tasks. Both models build upon the BERT (Bidirectional Encoder Representations from Transformers) architecture, which uses deep bidirectional attention to capture the context of words from both the left and right sides of a sentence. Below is an overview of each model:
-
ARABERT
ARABERT is a pre-trained BERT model tailored for Modern Standard Arabic (MSA). Developed by the AUB Mind Lab, ARABERT was trained on a large corpus of 61 GB of Arabic text (equivalent to 6.2 billion tokens). It leverages the masked language modeling (MLM) and next-sentence prediction (NSP) techniques for training, making it highly effective at capturing semantic relationships in Arabic text. ARABERT has been widely adopted for various downstream NLP tasks, such as sentiment analysis, text classification, and question answering. Its strength lies in processing the formal Arabic used in news articles, books, and other standard texts. -
MARBERT
MARBERT, developed by Abdul-Mageed et al., extends ARABERT’s capabilities by focusing on both MSA and dialectal Arabic, including content from social media platforms. It was trained on 1 billion Arabic tweets, which contain informal language, slang, and regional variations. MARBERT uses the same BERT architecture but adapts to the complexities of conversational and dialectal Arabic, making it suitable for tasks like sentiment analysis and mental health detection in user-generated content.
These models complement each other: ARABERT performs well on structured text, while MARBERT excels in understanding informal and dialectal Arabic. For the CairoDep v1.0 dataset, we fine-tuned both models to detect depression in posts written in MSA and dialectal Arabic, demonstrating their versatility and ability to capture nuanced emotional expressions across linguistic variations.
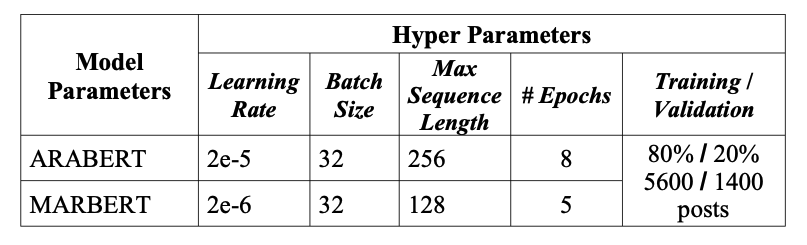
Hyperparameters
The table below outlines the hyperparameters used during the fine-tuning of ARABERT and MARBERT. These parameters include key configurations such as learning rate, batch size, sequence length, and the number of epochs. Both models were trained and evaluated using the same 80/20 data split to ensure consistency and comparability in their performance on detecting depression from Arabic social media posts.
Model Evaluation
To evaluate the performance of ARABERT and MARBERT on the CairoDep v1.0 dataset, we used four standard classification metrics: accuracy, precision, recall, and F1-score. These metrics provide a comprehensive understanding of how well each model identifies both depressed and non-depressed posts. The models were trained using an 80/20 split of the dataset, with 80% used for training and 20% for validation.
Results
The table below shows the performance metrics for ARABERT and MARBERT compared to other approaches from the literature.
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| ARABERT | 96.93% | 96.92% | 96.93% | 96.92% |
| MARBERT | 96.07% | 96.11% | 96.04% | 96.07% |
| Alabdulkreem (RNN-based) [1] | 72.00% | 71.00% | 68.00% | 69.00% |
| Alghamdi et al. (Lexicon) [2] | 80.45% | 82.30% | 80.81% | 79.36% |
| Alghamdi et al. (ML-based) [2] | 73.00% | 75.00% | 77.00% | 73.00% |
Analysis
Our evaluation shows that both ARABERT and MARBERT significantly outperform traditional approaches, including lexicon-based and machine learning methods. ARABERT achieved slightly better results than MARBERT, likely due to the structured nature of some posts in the dataset. However, MARBERT's robust handling of dialectal Arabic ensures high performance across informal and colloquial content.
These results demonstrate the superiority of transformer-based models for depression detection, especially in Arabic texts, where traditional methods have shown limitations. This performance highlights the potential of ARABERT and MARBERT for developing AI-powered mental health solutions for Arabic-speaking users.
Conclusion
In this study, we developed and evaluated two transformer-based models, ARABERT and MARBERT, to detect depression from Arabic social media posts using the newly curated CairoDep v1.0 dataset. Our results demonstrate the effectiveness of both models, with ARABERT achieving 96.93% F1-score and MARBERT achieving 96.07% F1-score, outperforming traditional lexicon-based and machine learning approaches. These high scores highlight the value of using transformer-based architectures for nuanced text classification tasks, especially for mental health detection.
This research addresses a critical gap in mental health solutions for Arabic-speaking populations, as most prior studies have focused on English-language texts. By including posts in both Modern Standard Arabic (MSA) and Dialectal Arabic, the models show robust performance across varied linguistic styles, paving the way for real-world applications.
The CairoDep models can serve as a foundation for AI-powered mental health tools, such as depression screening systems, chatbots, and early intervention platforms tailored for Arabic users. Future work may focus on expanding the dataset, incorporating other mental health conditions, and enhancing model generalization through multi-task learning approaches. We hope this research contributes to the development of accessible mental health solutions for underserved communities.
References
[1] Eatedal Alabdulkreem. "Prediction of Depressed Arab Women Using Their Tweets." Journal of Decision Systems, volume 30, issue 2-3, pp. 102-117, 2021,
[2] Norah Saleh Alghamdi, Hanan A. Hosni Mahmoud, Ajith Abraham, Samar Awadh Alanazi, and Laura García-Hernández. "Predicting Depression Symptoms in an Arabic Psychological Forum." IEEE Access, 8 (2020): 57317-57334, 2020.