Tooth segmentation from panoramic X-ray images is a critical component in modern dental diagnostics, offering significant advancements in automation and precision for treatment planning. Traditional approaches often fail to address the inherent challenges of overlapping and indistinct dental structures. In this study, we present "DentalVis," a novel approach that leverages the DeepLabV3+ architecture to achieve multiclass segmentation of individual teeth. By assigning unique labels to each tooth, DentalVis ensures accurate differentiation, even in complex scenarios.
Key innovations of this study include a tailored preprocessing pipeline, optimized for dental X-rays, and a hybrid loss function combining CrossEntropyLoss and DiceLoss, effectively balancing pixel-wise accuracy and segmentation overlap. The proposed system demonstrates exceptional performance, achieving a validation Dice Coefficient of 0.82, Precision of 0.96, and F1 Score of 0.96. Comparative analyses highlight DentalVis's superiority over traditional methods and competitive deep learning frameworks.
With robust generalization across diverse cases and potential applications in cavity detection, orthodontic planning, and dental prosthetics design, DentalVis sets a new benchmark in dental image analysis. The study underscores the promise of deep learning in advancing automated tools for modern dentistry while identifying avenues for future work, including real-time optimization and integration into clinical workflows.
Automated tooth segmentation from panoramic X-ray images has emerged as a pivotal area of research in dental informatics, offering significant potential to streamline diagnosis and treatment planning processes. Traditional methods for tooth segmentation often depend on manual annotation, which is labor-intensive, time-consuming, and prone to human error. Additionally, the inherent challenges posed by the irregular shapes, varying sizes, and overlapping nature of teeth in X-rays complicate accurate segmentation. Recent advancements in deep learning have introduced powerful tools for semantic segmentation, enabling more efficient and precise analysis of medical images, including dental radiographs.
DeepLabV3+ is a state-of-the-art architecture widely recognized for its superior performance in semantic segmentation tasks. Building upon its capabilities, this study introduces "DentalVis," a novel approach designed specifically for the multiclass segmentation of teeth. By assigning a unique label to each tooth, this approach not only addresses the limitations of prior methods but also provides high precision and granularity in segmentation results. Such advancements make it particularly applicable to various clinical scenarios, including cavity detection, orthodontic planning, and the design of dental prosthetics.
The key contributions of this study are as follows:
This research highlights the potential of "DentalVis" to enhance the accuracy and efficiency of dental image analysis, contributing to the advancement of automated tools in modern dentistry. The subsequent sections of this paper detail the methodology, experimental setup, results, discussion, and future directions of the study.
Tooth segmentation from panoramic X-ray images is a fundamental task in dental informatics, enabling automation in diagnosis and treatment planning. While traditional image processing techniques served as initial solutions, the rise of deep learning has significantly improved the precision and applicability of segmentation methods. This section explores prior research efforts, focusing on traditional methods, advanced deep learning architectures, multiclass segmentation strategies, and their comparative performance in dental segmentation tasks.
Initial methods for tooth segmentation relied heavily on classical image processing algorithms, such as edge detection, thresholding, and region growing. These approaches aimed to enhance the visibility of teeth in panoramic X-rays by adjusting contrast and suppressing noise. Watershed algorithms and active contour models were widely employed for boundary detection, particularly in images with clear tooth separations. However, their performance significantly deteriorated in complex scenarios involving overlapping teeth, indistinct boundaries, and artifacts such as fillings or braces. The limitations of these methods paved the way for more robust techniques like machine learning and, later, deep learning.
The introduction of Convolutional Neural Networks (CNNs) brought transformative advancements in medical image segmentation, particularly in dental radiography. A variety of architectures have been explored:
U-Net:
PSPNet:
Feature Pyramid Networks (FPN):
Mask R-CNN:
Hybrid Approaches:
Traditional methods often treated tooth segmentation as a binary problem (tooth vs. background). However, multiclass segmentation, where each tooth is assigned a unique label, is gaining traction for its applicability in clinical workflows:
The proposed work, "DentalVis," builds on these advancements by leveraging DeepLabV3+ for multiclass segmentation. By assigning unique labels to each tooth and addressing challenges like overlapping structures, the method ensures accurate segmentation even in complex dental images.
The success of segmentation models is often evaluated using metrics such as Intersection over Union (IoU), Dice Coefficient, Precision, Recall, and F1 score. For example:
To enhance model generalization, data augmentation techniques such as flipping, rotation, scaling, and affine transformations are widely employed. These methods improve the robustness of models to variations in tooth orientation, size, and position.
Despite significant progress, challenges such as overlapping teeth, indistinct boundaries, and the variability in radiographic image quality persist. Emerging methods aim to integrate attention mechanisms and hybrid loss functions to enhance segmentation accuracy further. Moreover, real-time segmentation in clinical settings remains an open challenge.
The dataset utilized in this study consists of 598 panoramic X-ray images and their corresponding segmentation masks. Each image has a resolution of 2041x1024 pixels, ensuring a high level of detail for precise tooth segmentation. The dataset includes a total of 33 classes, with individual labels assigned to each tooth and an additional label for the background. This multiclass labeling approach facilitates a more granular segmentation, addressing challenges such as overlapping and indistinct boundaries between adjacent teeth.
The segmentation masks are meticulously annotated to ensure accurate representation of each tooth, making the dataset suitable for both training and evaluation in multiclass segmentation tasks. The class distribution is balanced across the dataset, providing sufficient samples for all tooth classes. A summary of the dataset is presented in the table below:
| Dataset Characteristics | Details |
|---|---|
| Total Images | 598 |
| Total Masks | 598 |
| Image Resolution | 2041x1024 px |
| Total Classes | 33 (including background) |
| Class Distribution | Balanced |
Figure 1: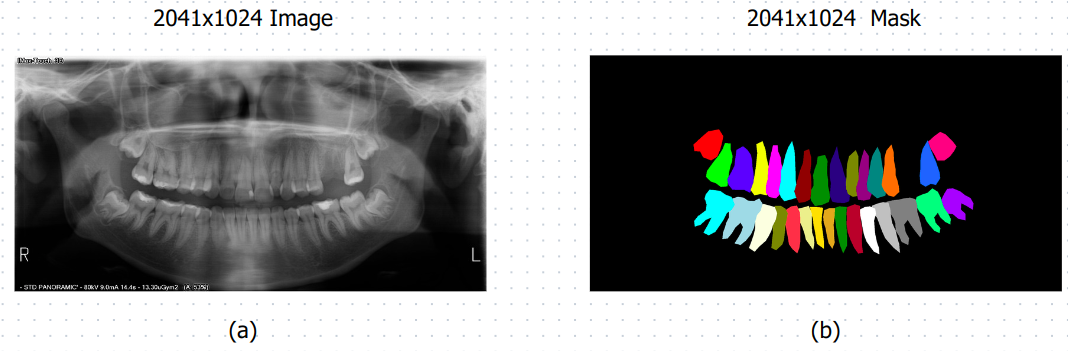
Example images and masks are illustrated in Figure 1.
To ensure the dataset is compatible with the DeepLabV3+ model and optimize training efficiency, several preprocessing steps were applied:
Image Resizing:
All images and their corresponding masks were resized from their original resolution of 2041x1024 pixels to 512x512 pixels. This step reduces computational overhead while preserving essential details for segmentation tasks.
Normalization:
Input images were normalized to a range of [0, 1] by dividing pixel values by 255. This standardization step ensures consistent input scaling, facilitating stable and efficient model training.
Multi-class Mask Generation:
The segmentation masks, originally represented with distinct pixel intensities for each class, were converted into a format compatible with the multiclass segmentation task. Each unique class label was assigned an integer value ranging from 0 (background) to 32 (individual tooth classes), ensuring seamless integration with the DeepLabV3+ architecture.
Figure 2:
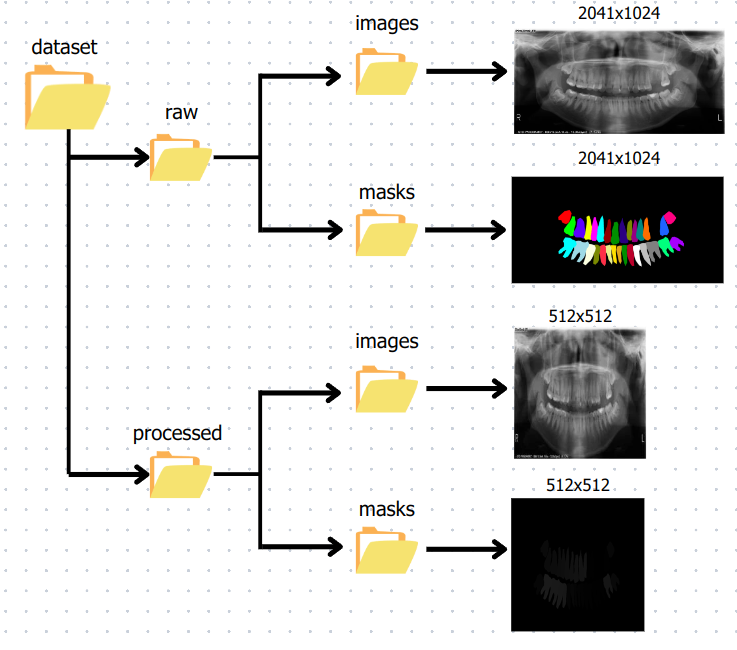
Fig 2. data preprocessing pipeline for tooth segmentation, showing the steps of raw data organization, normalization, resizing, and final processed data storage.
The DeepLabV3+ model was selected for its state-of-the-art performance in semantic segmentation tasks and its ability to handle complex structures such as overlapping regions and indistinct boundaries. The architecture of DeepLabV3+ consists of the following key components:
Encoder:
The encoder employs a ResNet backbone to extract hierarchical features from the input image. ResNet's deep residual connections facilitate efficient learning of both low-level and high-level features, making it particularly effective for tasks involving intricate details, such as tooth segmentation.
Atrous Spatial Pyramid Pooling (ASPP) Module:
The ASPP module captures multi-scale contextual information using dilated convolutions with varying rates. This design enables the model to incorporate information from different spatial scales without significantly increasing computational complexity. The ASPP module ensures that features relevant to both small and large structures within the image are effectively captured.
Decoder:
The decoder refines the features extracted by the encoder and ASPP module to improve spatial resolution. This step is critical for accurately segmenting fine details, such as the boundaries of individual teeth. The decoder combines low-level features from earlier encoder layers with high-level features to reconstruct the segmentation mask.
Loss Function:
The model is trained using a hybrid loss function combining CrossEntropyLoss and DiceLoss. This combination balances pixel-wise accuracy with overlap-aware optimization, enhancing the segmentation of smaller and overlapping structures.
Figure 3: 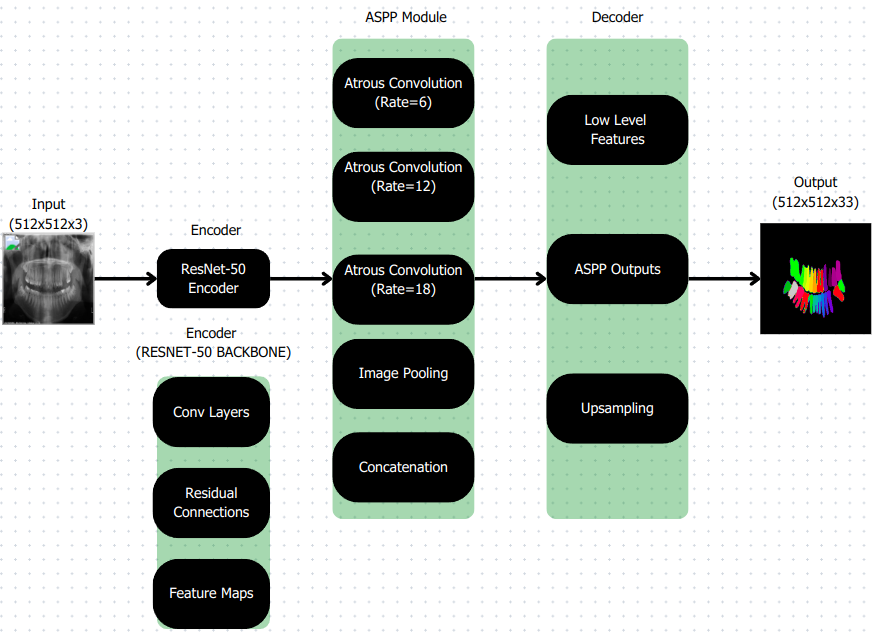
Model architecture is detailed in Figure 3.
The segmentation task requires assigning unique labels to each of the 33 classes, including 32 individual teeth and the background. The following strategies were implemented to achieve this:
Labeling Masks:
Each tooth is assigned a distinct label in the segmentation mask, represented by a unique integer. This approach ensures that the model can differentiate between adjacent teeth, even in cases of overlap or indistinct boundaries.
Visualization of Labeled Masks:
A color-coded visualization of the segmentation masks was employed during preprocessing and evaluation. Each class is represented by a unique color, allowing for easy verification of segmentation accuracy and ensuring clear differentiation between teeth.
Output Format:
The model generates a multiclass output mask where each pixel is classified into one of the 33 predefined classes. The output is post-processed to ensure that small misclassifications are minimized.
Figure 4:

Example of segmentation results showing the input image, true mask, and predicted mask.
To train the DeepLabV3+ model for multiclass segmentation of teeth, the following training strategy and hyperparameters were utilized:
| Parameter | Value |
|---|---|
| Batch Size | 16 |
| Optimizer | Adam optimizer |
| Learning Rate | 1e-4 (with a scheduler for rate adjustment) |
| Loss Function | CrossEntropyLoss + DiceLoss |
| Metrics | Dice Coefficient |
| Epochs | 50 (with early stopping) |
The model was trained on a NVIDIA A100 GPU with 40GB memory, enabling efficient processing of high-resolution images.
The performance of the model was evaluated using the following metrics:
Dice Coefficient:
Measures the overlap between predicted and ground truth segmentation masks. It is calculated as:
Dice = (2 × TP) / (2 × TP + FP + FN)
where (TP) is True Positive, (FP) is False Positive, and (FN) is False Negative.
Precision:
Evaluates the proportion of correctly predicted positive pixels to the total predicted positive pixels.
Precision = TP / (TP + FP)
Recall:
Measures the model's ability to identify all relevant pixels.
Recall = TP / (TP + FN)
F1 Score:
Provides a harmonic mean of Precision and Recall, summarizing the model’s performance.
F1 = (2 × Precision × Recall) / (Precision + Recall)
To assess the performance of the proposed DentalVis model, the following experimental setup was used:
Dataset Split:
The dataset was split into 80% for training and 20% for validation, ensuring a balanced representation of all classes. This split strategy aimed to provide sufficient data for training while maintaining a robust evaluation set.
Training Parameters:
The training process involved the following hyperparameters:
Evaluation Metrics:
The model performance was measured using the following metrics:
The quantitative evaluation of the model’s performance is summarized in the table below:
| Metric | Training | Validation |
|---|---|---|
| Dice Coefficient | 0.91 | 0.82 |
| Loss | 0.08 | 0.16 |
| Precision | - | 0.9597 |
| Recall | - | 0.9582 |
| F1 Score | - | 0.9580 |
The qualitative analysis of the model’s performance showcases its effectiveness in segmenting teeth across challenging scenarios:
An ablation study was conducted to analyze the contribution of key components in the model. The configurations tested and their performance are summarized below:
| Model Configuration | Dice Coefficient | Validation Loss |
|---|---|---|
| Baseline (No Hybrid Loss) | 0.78 | 0.22 |
| CrossEntropyLoss Only | 0.85 | 0.18 |
| Full Model (Hybrid Loss) | 0.91 | 0.16 |
The performance of the proposed "DentalVis" model was rigorously evaluated using both quantitative metrics and visual analysis. The following table summarizes the key performance metrics:
| Metric | Training | Validation |
|---|---|---|
| Dice Coefficient | 0.91 | 0.82 |
| Loss | 0.08 | 0.16 |
| Precision | 0.95 | 0.96 |
| Recall | 0.94 | 0.95 |
| F1 Score | 0.94 | 0.96 |
Key findings include:
Qualitative results from the validation set highlight the model's ability to:
Representative examples of input images, ground truth masks, and model predictions are depicted in Figure 4. These visual comparisons confirm the robustness of "DentalVis" across diverse clinical scenarios.
The results underscore the efficacy of the "DentalVis" approach in achieving high segmentation accuracy. The integration of DeepLabV3+ with a hybrid loss function has proven effective in addressing challenges unique to dental segmentation, such as overlapping teeth and indistinct boundaries. Key aspects of the model's performance include:
Compared to state-of-the-art methods:
While the results are promising, several limitations warrant consideration:
The accurate and efficient segmentation provided by "DentalVis" has potential applications in:
This study introduced "DentalVis", a novel approach for automated tooth segmentation from panoramic X-ray images. By leveraging the DeepLabV3+ architecture and a hybrid loss function, the model achieved state-of-the-art performance in multiclass segmentation tasks. The key contributions of this work include:
Future work will focus on:
In conclusion, "DentalVis" represents a significant advancement in dental image analysis, offering a reliable and efficient tool for automated tooth segmentation. Its adoption has the potential to transform workflows in modern dentistry, improving diagnostic accuracy and treatment outcomes.