Defect Detection Using Convolutional Neural Networks (CNNs)
An analysis of multi-class image classification for defect detection using deep learning

The objective of this project is to develop a machine learning model that can classify images into different categories based on the type of defect they represent. The dataset consists of images of various objects with different types of defects, and the task is to build an efficient Convolutional Neural Network (CNN) model that can detect and classify these defects accurately.
The challenges include:
- Ensuring the model generalizes well across different types of defects
- Dealing with the variability in object appearance and defect types
- Improving model accuracy with limited data
Introduction
This report details the methodology, tools, and technologies used in developing a defect detection model using a convolutional neural network (CNN) to classify defects across multiple categories. The dataset, MVTec Anomaly Detection Dataset, was sourced from MVTec and includes a range of industrial defects across 10 classes.
Tools and Technologies Used
- Programming Language: Python - Chosen for its extensive library support in deep learning.
- Machine Learning and Deep Learning Libraries:
- TensorFlow & Keras: Used to build and train the CNN model, with high-level API support in Keras.
- NumPy: Used for efficient numerical operations during data preprocessing and augmentation.
- Scikit-learn: Used for one-hot encoding labels and dataset splitting.
- Data Processing and Visualization:
- Pandas: Used to handle data and manage labels efficiently.
- Matplotlib and Seaborn: Utilized for visualizing accuracy and loss metrics over epochs.
- Development Environment:
- Jupyter Notebook: Provides step-by-step model iteration and real-time result visualization.
- Anaconda: Used to manage dependencies and ensure consistency across sessions.
- VS Code (optional): Occasionally used for scripting and debugging.
- Data Augmentation:
- Keras ImageDataGenerator: Created variations in training images to enhance generalization and reduce overfitting.
- Model Evaluation and Monitoring:
- EarlyStopping Callback: Used to monitor validation loss, helping prevent overfitting by halting training at performance plateau.
- ModelCheckpoint: Saved model checkpoints to retain best-performing model parameters.
Dataset
The MVTec Anomaly Detection Dataset is a specialized dataset designed for defect detection in industrial settings. It contains thousands of high-resolution images across various object categories, each with labeled defects. The dataset's diverse nature, including texture, shape, and size variations, presented an excellent test bed for the model’s robustness.
Methodology and Results
Following the standard machine learning pipeline, the dataset was preprocessed, augmented, and then trained on a CNN model using Keras. The final model achieved approximately 91.79% accuracy on the training set and 89.13% on the validation set, proving its capability in classifying defect types accurately.
import zipfile with zipfile.ZipFile('ezyzip.zip', 'r') as zip_ref: zip_ref.extractall('Defect_detection') print("Extraction complete.")
Step 1: Importing Libraries and Setting Up the Environment
In this step, we import the necessary libraries and set up the environment for our image classification task. These libraries include TensorFlow for deep learning, os for file operations, and various utilities for image preprocessing.
import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, BatchNormalization from tensorflow.keras.callbacks import EarlyStopping import os from tensorflow.keras.utils import to_categorical from tensorflow.keras import models, layers import matplotlib.pyplot as plt import seaborn as sns import pandas as pd import numpy as np from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix from tensorflow.keras.preprocessing.image import ImageDataGenerator
Step 2: Dataset Preparation
The next step is to load the dataset. We assume that the dataset is structured into subdirectories representing different defect categories. We will use TensorFlow's `image_dataset_from_directory` method to load the dataset into a format suitable for training.
# Set up the path to the dataset directory dataset_dir = './defect_detection/' # List to store datasets for train, validation, and test train_datasets = [] test_datasets = [] # Load datasets for each subcategory for subcategory in os.listdir(dataset_dir): subcategory_path = os.path.join(dataset_dir, subcategory) # Check if the path is a directory (e.g., `object1`, `object2`, etc.) if os.path.isdir(subcategory_path): # Paths to the train, test, and optionally val directories for each subcategory train_dir = os.path.join(subcategory_path, 'train') test_dir = os.path.join(subcategory_path, 'test') # Load training dataset for the current subcategory if the directory exists if os.path.isdir(train_dir): train_ds = tf.keras.utils.image_dataset_from_directory( directory=train_dir, labels="inferred", label_mode="int", # Ensure labels are integers (for sparse_categorical_crossentropy) batch_size=32, image_size=(256, 256), shuffle=True ) train_datasets.append(train_ds) # Load testing dataset for the current subcategory if the directory exists if os.path.isdir(test_dir): test_ds = tf.keras.utils.image_dataset_from_directory( directory=test_dir, labels="inferred", label_mode="int", # Ensure labels are integers (for sparse_categorical_crossentropy) batch_size=32, image_size=(256, 256), shuffle=False # Usually not shuffled for testing ) test_datasets.append(test_ds) # Check class names to ensure labels are correctly inferred class_names = train_ds.class_names print("Class names:", class_names) class_names = test_ds.class_names print("Class names:", class_names) # Concatenate datasets from all subcategories train_ds = train_datasets[0] for ds in train_datasets[1:]: train_ds = train_ds.concatenate(ds) test_ds = test_datasets[0] for ds in test_datasets[1:]: test_ds = test_ds.concatenate(ds) def check_labels(ds): for images, labels in ds: print("Label range:", labels.numpy().min(), "to", labels.numpy().max()) break # Check only the first batch # Assuming num_classes is 9 (0-8) num_classes = 10 # If labels are not one-hot encoded, encode them def encode_labels(ds): return ds.map(lambda x, y: (x, to_categorical(y, num_classes=num_classes))) # Check the labels check_labels(train_ds) check_labels(test_ds) # Apply label encoding if necessary train_ds = encode_labels(train_ds) test_ds = encode_labels(test_ds)
Step 3: Model Definition and Training
In this step, we define a Convolutional Neural Network (CNN) model using Keras. The model consists of several convolutional layers followed by max-pooling and fully connected layers. We use the `categorical_crossentropy` loss function since we are dealing with a multi-class classification problem.
# Define the model model = models.Sequential([ layers.InputLayer(shape=(256, 256, 3)), # Adjust input shape if needed layers.Rescaling(1./255), layers.Conv2D(32, (3, 3), activation='relu'), layers.MaxPooling2D((2, 2)), layers.Conv2D(64, (3, 3), activation='relu'), layers.MaxPooling2D((2, 2)), layers.Conv2D(128, (3, 3), activation='relu'), layers.MaxPooling2D((2, 2)), layers.Flatten(), layers.Dense(128, activation='relu'), layers.Dense(num_classes, activation='softmax') # Change num_classes to 10 ])
Step 4: Data Augmentation and Preprocessing
Data augmentation techniques are applied to the training dataset to artificially increase its size and variety. These techniques include rotation, shifting, shearing, and flipping of images. This helps the model generalize better by exposing it to a wide variety of image transformations.
train_datagen = ImageDataGenerator( rescale=1./255, rotation_range=20, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest' ) test_datagen = ImageDataGenerator(rescale=1./255) train_ds = train_datagen.flow_from_directory( directory=dataset_dir, target_size=(256, 256), batch_size=32, class_mode='categorical' ) test_ds = test_datagen.flow_from_directory( directory=dataset_dir, target_size=(256, 256), batch_size=32, class_mode='categorical' )
Step 5: Model Evaluation
After training the model, we evaluate its performance on the test set. This allows us to understand how well the model generalizes to unseen data and provides insights into the accuracy and potential areas for improvement.
# Compile the model model.compile(optimizer='adam', loss='categorical_crossentropy', # For one-hot encoded labels metrics=['accuracy']) # Early stopping callback early_stopping = EarlyStopping(monitor='val_loss', patience=3, restore_best_weights=True) # Train the model result = model.fit( train_ds, epochs=10, validation_data=test_ds, callbacks=[early_stopping] ) # Print results print(result.history)
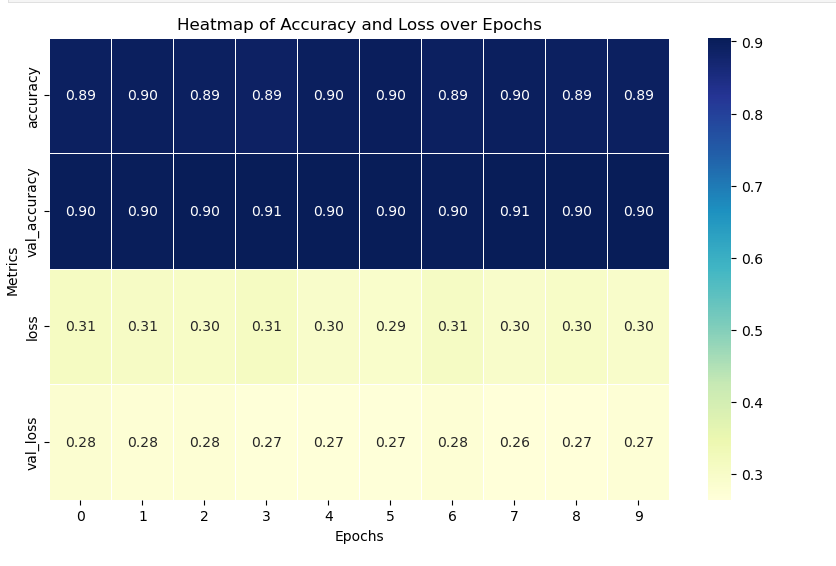
Step 6 : Model Performance Metrics
Below, we observe the model's performance across each epoch. The graphs for Accuracy and Loss showcase how well the model generalizes to the test data and helps us assess whether the model is underfitting or overfitting. The training accuracy and loss curves provide insight into how the model is learning, while the validation curves indicate how well it performs on unseen data.
.png?Expires=1782187132&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=Tc5jMxar79Nm6ymcZC9Pkhil2GdUIPoT22b1TCUZQgezZJ1Wkao27Bi-51IsvPC1YCPKHmaW~FLgxatJUh1917oZOLxebh~H0c886Eql6xRhj01I26XrdnP-C7NzuyiQUm40UEKEhzbBdl30k0HasXk4n~xhfncQpA8xJvMR4oWWwRgk9P7yRJOfPkIqxkdx7L4PsjZD0AYJo-XEPN4u97uGyDdD0CC4jTEKY5d~raFxL~2~N-tagPdmNajogp~rS92qOwhIbZ30ZKBaMatv1dtffMwjLpLdqBIgdAcAtciCsL22DYuwW2wPcbpbFWThxvNGoQwlSnTIg1Y2yQUxRw__)
.png?Expires=1782187132&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=Yo6Caa48j3LAILpAIaiNqZvGqoffTSE3AqsNy-vpw7r75gktiqXzxXSQCaOnhDalmECBTwDUcra-UTU~bvHaMXfeITgx5DGcqhTr-0EgPG3KnPcXNACbbepbCf4qT3e0oGHUPo-H8phObxvb3ZUGoW4e~4Fv505GjyJuoqK2dXJ4vrmiYwdHILodbsZ3Xqh~7fZOSpsDvG7Wj2O9JNLMYABPbItMEFtsuGpvZUgGdaabrrHh07YlEGlTmqtgGg33AJ4WFEBueYtT3LXC141CODAJMO5bb4FVEPIhnXwdbYw31UTquIxnhSfGjTrz5LeJBp-Z0HJSPraxQN5bRANaNA__)
# Plot training and validation accuracy and loss # Convert the history data into a DataFrame history_df = pd.DataFrame(result.history) # Plot accuracy plt.figure(figsize=(10, 6)) sns.lineplot(data=history_df[['accuracy', 'val_accuracy']]) plt.title('Model Accuracy over Epochs') plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.legend(['Train Accuracy', 'Validation Accuracy']) plt.show() # Plot loss plt.figure(figsize=(10, 6)) sns.lineplot(data=history_df[['loss', 'val_loss']]) plt.title('Model Loss over Epochs') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend(['Train Loss', 'Validation Loss']) plt.show()
# Create a DataFrame of accuracy and loss metrics_heatmap_df = history_df[['accuracy', 'val_accuracy', 'loss', 'val_loss']] plt.figure(figsize=(10, 6)) sns.heatmap(metrics_heatmap_df.T, cmap="YlGnBu", annot=True, fmt=".2f", cbar=True, linewidths=0.5) plt.title('Heatmap of Accuracy and Loss over Epochs') plt.xlabel('Epochs') plt.ylabel('Metrics') plt.show()
Step 7 : Model Final Predication
Enter a input to check the model prediction to the unseen image
```python import cv2 import matplotlib.pyplot as plttest_img = cv2.imread('./Defect_detection/wood/test/hole/003.png')
if test_img is None:
print("Error: Image not loaded. Check the path and try again.")
else:
plt.imshow(cv2.cvtColor(test_img, cv2.COLOR_BGR2RGB)) # Convert from BGR to RGB for correct display
plt.show()
test_img = cv2.resize(test_img,(256,256))
test_input= test_img.reshape((1,256,256,3))
predictions=model.predict(test_input)
if np.any(predictions == 1):
print("Defective")
else:
print("Non-Defective")
<!-- RT_DIVIDER -->

<h2 style="color: #2c3e50; text-align: center; font-size: 28px; border-bottom: 2px solid #2c3e50; padding-bottom: 5px;">
Step 8 : Performance Matric after Prediction
</h2>
<p style="font-size: 18px; color: #34495e; line-height: 1.6; text-align: justify; margin: 20px 0;">
Model's performance using classification metrics such as accuracy,
precision, and recall.
</p>
<!-- RT_DIVIDER -->
```python
predicted_labels = np.argmax(predictions, axis=1)
true_labels = np.argmax(test_ds, axis=1) # Since labels are one-hot encoded
# Calculate accuracy
accuracy = accuracy_score(true_labels, predicted_labels)
print(f"Accuracy: {accuracy:.4f}")
# Calculate precision
precision = precision_score(true_labels, predicted_labels, average='weighted') # For multi-class, use 'weighted'
print(f"Precision: {precision:.4f}")
# Calculate recall
recall = recall_score(true_labels, predicted_labels, average='weighted')
print(f"Recall: {recall:.4f}")
# Calculate confusion matrix
conf_matrix = confusion_matrix(true_labels, predicted_labels)
print("Confusion Matrix:")
print(conf_matrix)
Conclusion and Future Work
The MVTec dataset and the tools utilized played a crucial role in the model's success. For future improvement, approaches like transfer learning and incorporating pre-trained models (e.g., ResNet, VGG) can be explored to enhance performance further. This project showcases the effective use of TensorFlow, Keras, and other Python libraries in building a reliable defect classification model suited for industrial applications.