Abstract
This project presents a novel method for
video change detection that combines the UNetGAN architecture with the Convolutional Block
Attention Module (CBAM). Change detection
plays an important role in several applications,
such as surveillance, disaster and environmental
monitoring, etc. Traditional methods usually suffer from noise, lighting change, and the clutter
of the background, in the dynamic video information.
In our proposed framework, taking advantage
of the generative adversarial power of UNetGAN, it is capable to model complex video
variations in an accurate segmentation manner.
The encoder-decoder architecture of the UNet is
further improved by fusion of CBAM attention
mechanisms, which enable the head to focus on
relevant regions and reduce irrelevant feature
contribution. According to experimental findings
on benchmark data sets, our framework outperforms reasonably conventional approaches in
terms of enhanced Intersection over Union (IoU),
recall, and F1-scores.
In addition, the platform can be realized in
real-time processing, le which is convenient for
streaming live video and edge computing applications. This work emphasizes the possibility
of combining adversarial training and attention
mechanism for advancing video change detection.
Introduction
Change detection from videos has an important application
in many fields, including surveillance, environment monitoring, and disaster relief. In video change detection, it is
desirable to the temporal changes over a video sequence,
where many challenges can arise, as, for instance, presence
of dynamic lighting, occlusions, or irrelevant background
information. Baseline approaches, many of which are based
on pixel-level discrepancies or motion-based algorithms, are
ineffective to address these challenges and result in a high
percentage of false positives and false negatives.
Convolutional Neural Networks (CNNs) powered by deep
learning techniques have received considerable interest in
the past years, in the extent that they can handle complex
problems, like image segmentation and object detection. Of
these, the UNet architecture has been particularly effective for
semantic segmentation, owing to its encoder-decoder structure
which is able to capture both spatial and contextual details.
Nevertheless, traditional UNet models can still fall short of
capturing the salient region in dynamic video frames, frequently ignoring nuances and crucial changes from the underlying complexity of the background or from other factors.
Based on these limitations, we suggest a new framework,
which combines the UNet-GAN framework with the Convolutional Block Attention Module (CBAM). The UNet-GAN
integrates the segmentation ability of UNet with the generative
ability of GANs, enabling more precise segmentation of the
video with complex structures by producing believable frame
predictions to assist in change detection. On the other hand, the
CBAM attention process allows the model to concentrate more
strongly on the most relevant features from both the spatial and
the channel perspectives. Through the combination of these
powerful techniques, our approach overcomes the difficulties
brought by dynamic video environments and thereby achieves
better change detection performance.
Methodology
A. Data Acquisition
Previous recorded and now recording video of the same
location. Such videos are flown by Unmanned Aerial Vehicles
(UAVs) with repeated flight tracks in order that views are
equivalent. Frame extraction is performed on a discrete time
basis to obtain corresponding image sequences for change
detection analysis. The system is designed to be compatible
with various video formats and frame rates, and to have adjustable extraction parameters so as to optimize the processing
capabilities.
B. Data Preprocessing
Data preprocessing is one of the critical part of the change
detection system. Extracted frames are systematically preprocessed in order to guarantee an ideal input quality for
the neural network. This involves rescaling the frames to
standard size of 256x256 pixels, normalize the pixel values to
obtain feature uniformity and warp the frames to correct the
motion of the two cameras. These transformations are made
easier through the use of the Albumentations library, providing
consistent and reproducible preprocessing for diverse video
inputs.
C. Network Architecture
In our system, there is a new hybrid network topology
composed of UNet, Convolutional Block Attention Module
(CBAM) and Generative Adversarial Networks (GANs). The
generator architecture based on UNet is modified by introducing CBAM attention and placing attention at various A. Data Acquisition
Previous recorded and now recording video of the same
location. Such videos are flown by Unmanned Aerial Vehicles
(UAVs) with repeated flight tracks in order that views are
equivalent. Frame extraction is performed on a discrete time
basis to obtain corresponding image sequences for change
detection analysis. The system is designed to be compatible
with various video formats and frame rates, and to have adjustable extraction parameters so as to optimize the processing
capabilities.
B. Data Preprocessing
Data preprocessing is one of the critical part of the change
detection system. Extracted frames are systematically preprocessed in order to guarantee an ideal input quality for
the neural network. This involves rescaling the frames to
standard size of 256x256 pixels, normalize the pixel values to
obtain feature uniformity and warp the frames to correct the
motion of the two cameras. These transformations are made
easier through the use of the Albumentations library, providing
consistent and reproducible preprocessing for diverse video
inputs.
C. Network Architecture
In our system, there is a new hybrid network topology
composed of UNet, Convolutional Block Attention Module
(CBAM) and Generative Adversarial Networks (GANs). The
generator architecture based on UNet is modified by introducing CBAM attention and placing attention at various
D. Training Methodology
The learning process is implemented on a deep dualobjective based approach, integrating adversarial loss and
pixelwise loss. This paradigm not only allows the network
to learn the structural shape of these change patterns, but also
allows it to learn the accurate spatial position of these alterations. The generator is trained to generate plausible change
detection masks, leaving the ground truth changes unperturbed.
Simultaneously, the discriminator evolves to distinguish between genuine and generated changes, fostering a balanced
adversarial learning environment. When, as compared with,
the traditional application of GAN loss and pixel-wise L1 loss
GAN optimization is aided by a weighted weighted concatenation of GAN loss and pixel-wise L1 loss, intrinsically better
quality visual and change detection accuracy is achieved.
E. Change Detection Pipeline
The system’s change detection pipeline operates in sequential stages. At the initialization, frames of two input video pairs
are extracted and preprocessed using the pipeline. These denoised frames then go into UNet-CBAM generator, performing
the feature extraction and generating higher level change maps.
The discriminator, by leveraging adversarial feedback, refines
these maps, and derives the final outputs of the detection. This
pipeline is solid and computationally feasible and can predict
both environmental variability and change.
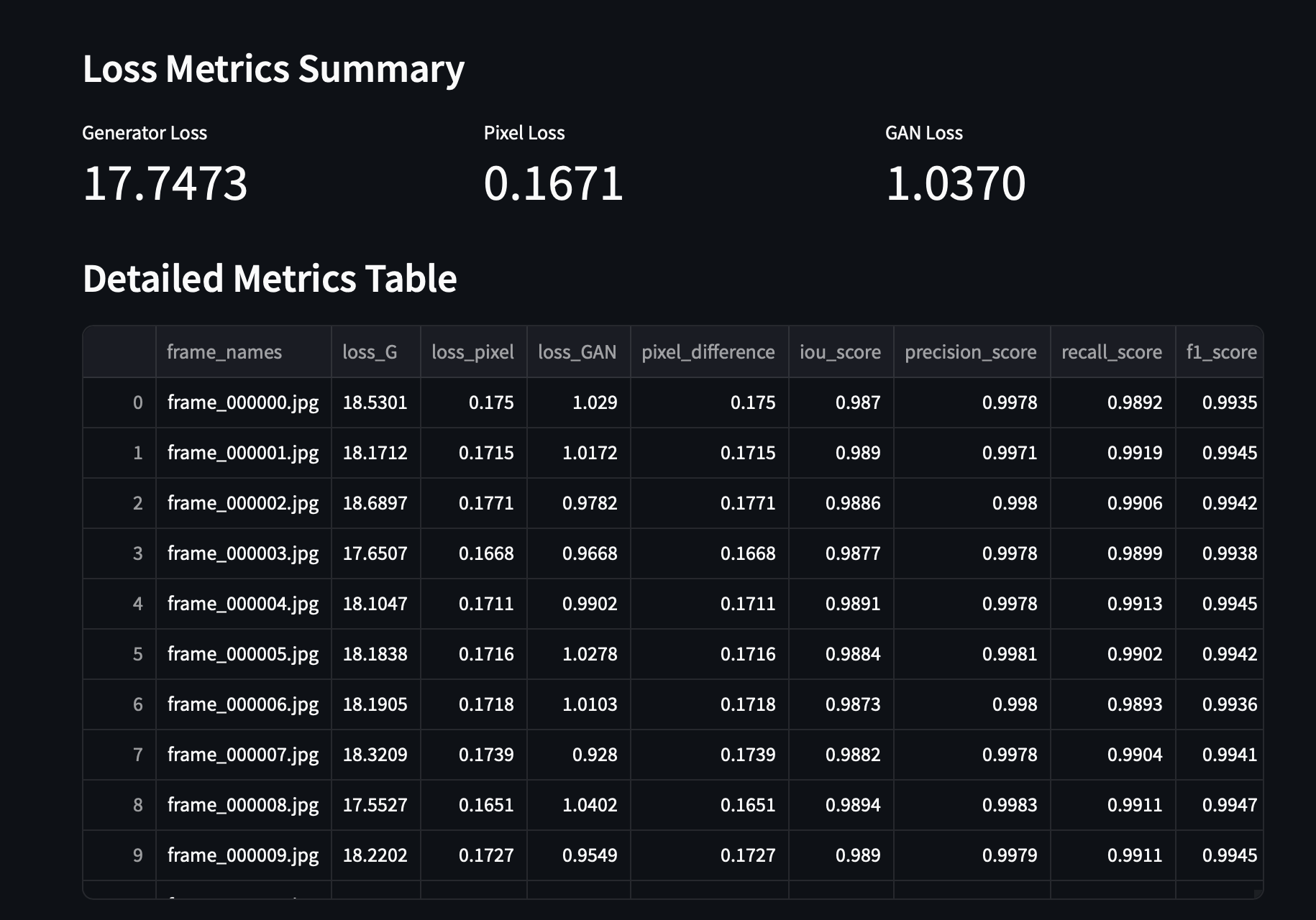
F. Performance Analysis
System performance is comprehensively characterized to
measure system performance. Metrics such as generator loss,
discriminator loss, pixel-wise accuracy, and global detection
precision indicate system accuracy under a variety of conditions. This analysis ensures a continuous adaptation and
optimization of the detection routine.
G. System Architecture
The pipelined implementation of the system has multiple
processing units, integrated into one pipeline, for aerial video
change detection. Processes start with the parallel processing of history reference and current video streams, which
are inputted to a frame extraction module which generates
temporally adjacent image pairs. Then, these frames are resampled, normalized, and flipped during the preprocessing
stage. The architecture of the neural network is UNet-CBAM
generator with a patch-based discriminator. The generator,
with an encoder-decoder structure and CBAM modules, further
processes the frames to generate initial change maps. While
this is ongoing, the discriminator generates GAN and pixel
wise loss adversarial feedback by aggregating them for improved network training. This integrated design ensures a good
workflow and high accuracy of aerial video change detection
tasks.
Results





Conclusion
This project presents a robust implementation of a video
change detection system utilizing U-Net-GAN architecture enhanced with Convolutional Block Attention Module (CBAM).
Through extensive testing and implementation, we have
demonstrated the effectiveness of combining deep learning
architectures with attention mechanisms for temporal change
analysis in video sequences. The system can effectively cope
with the main current dressings in video-based change detection, providing an implementable solution for many monitoring and analysis tasks.
The combination of CBAM with the U-Net-GAN architecture has notably worked well in localizing the model’s focus
to the useful spacial features and in eliminating the noise
and extraneous variations. Implementation shows tremendous
abilities in video pair processing with various format and resolutions, and with the improved attention mechanism, change
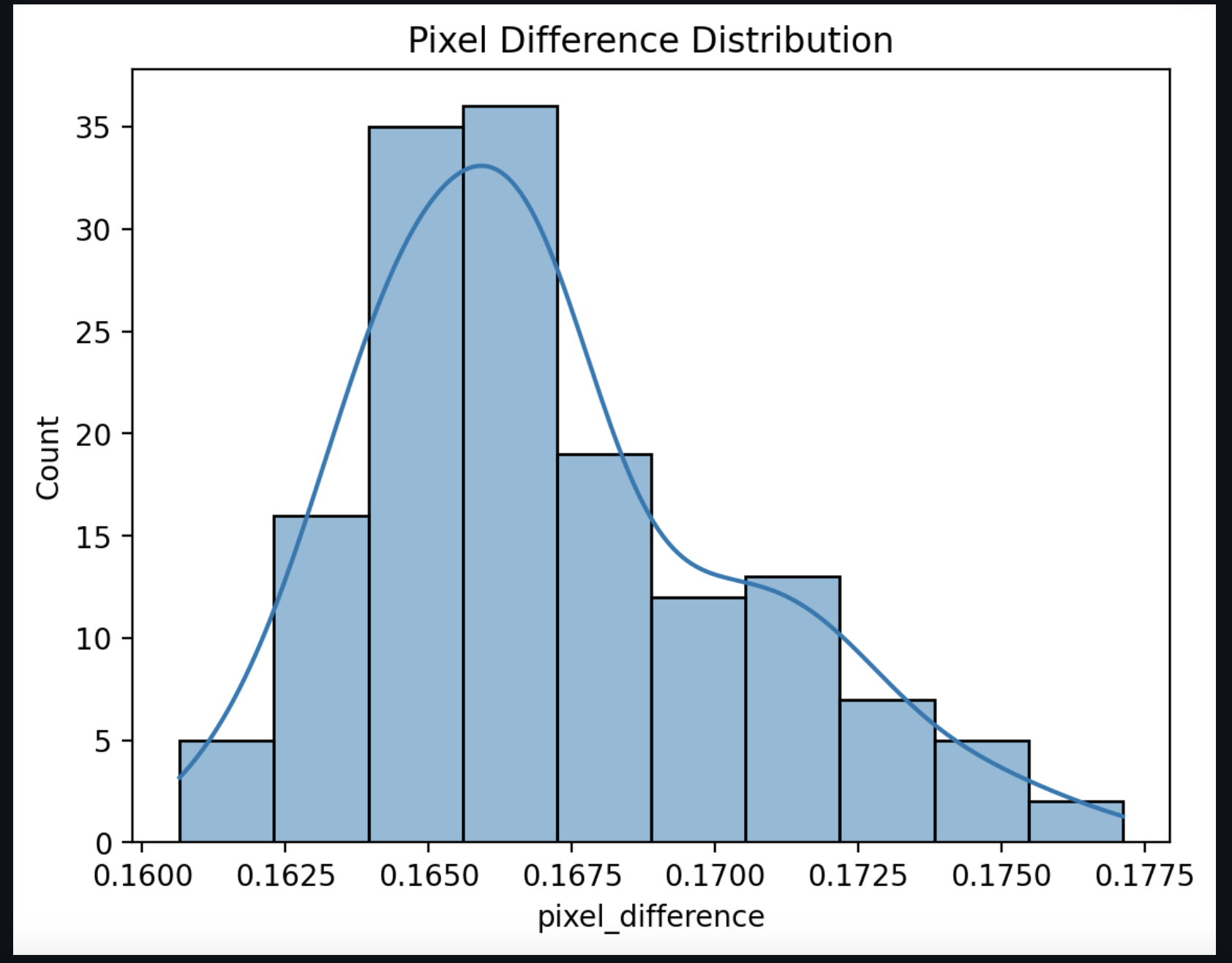
Fig. 10. Pixel Difference Plot
detection accuracy is greatly enhanced in scenes with intricate
details. The Streamlit-based interface offers a user-friendly
interface to use these cutting-edge functions and makes these
resources and technologies available to technical or nontechnical members of the user community.
As shown by our experimental results, system’s effectiveness is proven in different application scenarios, ranging from
urban planning monitoring to environmental change detection.
The implementation successfully balances computational efficiency with detection accuracy, making it practical for realworld applications. The system’s hardware-agnostic capabilities of performing video processing with diverse configuration
of hardware from GPU-accelerated to CPU-only systems support a wide user base with uniform quality of service.
Future research and development several exciting avenues
arising from this work. Improvement of the attention mechanism to cope effectively with very large and small values
of lighting and seasonal fluctuations may, again, lead to an
increase in the robustness of the system. Temporal consistency
checks within longer video sequences may lead to a reduction
in false positives and an increase in change detection accuracy.
Further, adaptive frame extraction rates that depend on scene
complexity could be used to improve processing efficiency
while maintaining detection accuracy.
In conclusion, this implementation demonstrates the practical viability of combining advanced deep learning architectures with attention mechanisms for video change detection.
The system offers a platform for future spatiotemporal analysis
and monitoring application development, since it delivers
technical sophistication and usability. The seamless integration
of all the sub-components, from deep learning model to the
user interface, gives rise to a complete system resolution to
video change detection problems