

The diffusion process consists of a forward phase where an image is progressively corrupted by adding Gaussian noise at each step. After many steps, the image effectively becomes indistinguishable from random noise sampled from a normal distribution. This is achieved by applying a transition function at each time step xₜ, where β represents a scheduled amount of noise added to the image at t−1 to produce the image at t.
In the previous discussion, we established that setting α=1−β and computing the cumulative product of these α values at each time step allows us to transition directly from the original image to a noisy version at any given step t. In the reverse process, the model is trained to approximate the reverse distribution. Since both the forward and reverse processes are Gaussian, the goal is for the model to predict the mean and variance of the reverse distribution.
Through detailed derivations, starting from the objective of maximizing the log-likelihood of the observed data, we arrived at the need to minimize the KL divergence between the ground truth denoising distribution (conditioned on x₀) — characterized by a specific mean and variance — and the model’s predicted distribution. The variance is fixed to match that of the target distribution, while the mean is rewritten in the same form. Minimizing the KL divergence simplifies to minimizing the squared difference between the predicted noise and the actual noise sample.
The training process involves sampling an image, selecting a time step t, and adding noise sampled from a normal distribution. The noisy image at t is then passed through the model. The cumulative product terms, derived from the noise schedule, determine the noise added over time. The loss function is the mean squared error (MSE) between the original noise sample and the model’s prediction.
For image generation, we sample from the learned reverse distribution, starting with a random noise sample xₜ from a normal distribution. The mean is computed using the same formulation in terms of xₜ and the predicted noise, with the variance matching that of the ground truth denoising distribution. Using the reparameterization trick, we repeatedly sample from this reverse distribution to generate x₀. At x₀, no additional noise is added; instead, the mean is directly returned as the final output.
To implement the diffusion process, we need to handle computations for both the forward and reverse phases. We’ll create a noise scheduler to manage these tasks. In the forward process, given an image, a noise sample, and a time step t, the scheduler will return the noisy version of the image using the forward equation. To optimize efficiency, it will precompute and store the values of α(1−β) and the cumulative product of α across all time steps.
The author employs a linear noise schedule, where β is scaled linearly from 1×10⁻⁴ to 0.02 over 1,000 time steps. The scheduler also handles the reverse process: given xt and the predicted noise from the model, it will compute xₜ₋₁ by sampling from the reverse distribution. This involves calculating the mean and variance using their respective equations and generating a sample via the reparameterization trick.
To support these computations, the scheduler will also store precomputed values for 1−αₜ, 1−cumulative product terms, and the square root of this term.
import torch class LinearNoiseScheduler: def __init__(self, num_timesteps, beta_start, beta_end): self.num_timesteps = num_timesteps self.beta_start = beta_start self.beta_end = beta_end self.betas = torch.linspace(beta_start, beta_end, num_timesteps) self.alphas = 1. - self.betas self.alpha_cum_prod = torch.cumprod(self.alphas, dim=0) self.sqrt_alpha_cum_prod = torch.sqrt(self.alpha_cum_prod) self.sqrt_one_minus_alpha_cum_prod = torch.sqrt(1 - self.alpha_cum_prod) def add_noise(self, original, noise, t): original_shape = original.shape batch_size = original_shape[0] sqrt_alpha_cum_prod = self.sqrt_alpha_cum_prod.to(original.device)[t].reshape(batch_size) sqrt_one_minus_alpha_cum_prod = self.sqrt_one_minus_alpha_cum_prod.to(original.device)[t].reshape(batch_size) # Reshape till (B,) becomes (B,1,1,1) if image is (B,C,H,W) for _ in range(len(original_shape) - 1): sqrt_alpha_cum_prod = sqrt_alpha_cum_prod.unsqueeze(-1) for _ in range(len(original_shape) - 1): sqrt_one_minus_alpha_cum_prod = sqrt_one_minus_alpha_cum_prod.unsqueeze(-1) # Apply and Return Forward process equation return (sqrt_alpha_cum_prod.to(original.device) * original + sqrt_one_minus_alpha_cum_prod.to(original.device) * noise) def sample_prev_timestep(self, xt, noise_pred, t): x0 = ((xt - (self.sqrt_one_minus_alpha_cum_prod.to(xt.device)[t] * noise_pred)) / torch.sqrt(self.alpha_cum_prod.to(xt.device)[t])) x0 = torch.clamp(x0, -1., 1.) mean = xt - ((self.betas.to(xt.device)[t]) * noise_pred) / (self.sqrt_one_minus_alpha_cum_prod.to(xt.device)[t]) mean = mean / torch.sqrt(self.alphas.to(xt.device)[t]) if t == 0: return mean, x0 else: variance = (1 - self.alpha_cum_prod.to(xt.device)[t - 1]) / (1.0 - self.alpha_cum_prod.to(xt.device)[t]) variance = variance * self.betas.to(xt.device)[t] sigma = variance ** 0.5 z = torch.randn(xt.shape).to(xt.device) return mean + sigma * z, x0
After initializing all the parameters using the arguments passed to this class, we will define β values to increase linearly from the starting to the ending range, ensuring that βₜ progresses from 0 to the final time step. Following this, we will set up all the variables required for the forward and reverse process equations.
The add_noise() function represents the forward process. It takes an original image, a noise sample, and a time step ttt as inputs. The images and noise will have dimensions b×h×w, while the time step will be a 1D tensor of size b. For the forward process, we calculate the square root of the cumulative product terms for the given time steps and 1−cumulative product terms. These values are reshaped to dimensions b×1×1×1. Finally, we apply the forward process equation to generate the noisy image.
The next function in the scheduler class handles the reverse process. It generates a sample from the learned reverse distribution using the noisy image xₜ , the noise prediction from the model, and the time step t as inputs. We save the original image prediction x₀ for visualization purposes, which is obtained by rearranging the forward process equation to compute x₀ using the noise prediction instead of the actual noise.
For sampling during the reverse process, we calculate the mean using the reverse mean equation. At t=0, we simply return the mean. For other time steps, noise is added to the mean, with the variance being the same as that of the ground truth denoising distribution conditioned on x₀. Finally, we sample from the Gaussian distribution using the computed mean and variance, applying the reparameterization trick to generate the result.
This completes the noise scheduler, which manages both the forward process of adding noise and the reverse process of sampling. For diffusion models, we have the flexibility to choose any architecture, provided it satisfies two key requirements. The first is that the input and output shapes must be identical, and the second is that there must be a way to incorporate time step information.
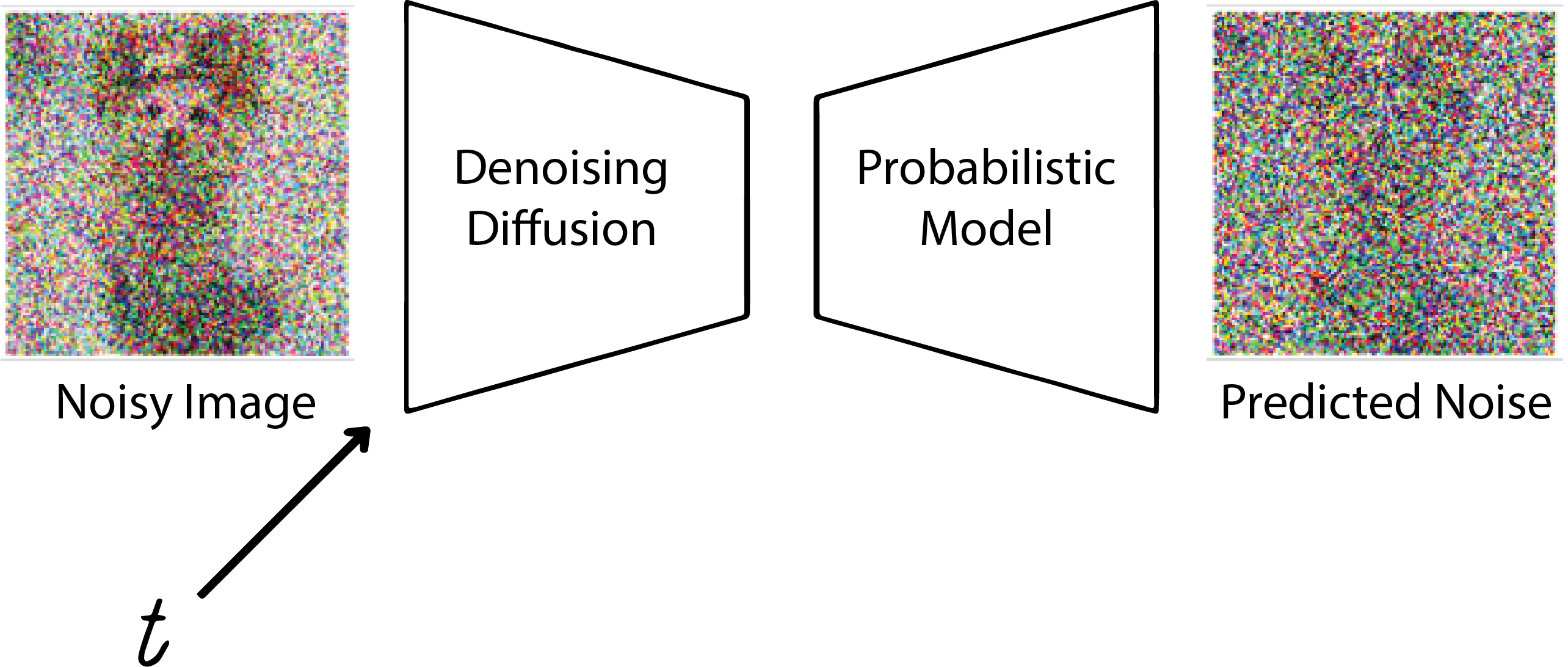
The time step information is always accessible, whether during training or sampling. Including this information helps the model better predict the original noise because it indicates how much of the input image is noise. Instead of providing only the image to the model, we also supply the corresponding time step.
For the model architecture, we will use a UNet, which is also the choice of the original authors. To ensure consistency, we will replicate the exact specifications of the blocks, activations, normalizations, and other components as implemented in the Stable Diffusion UNet used in Hugging Face’s Diffusers pipeline.
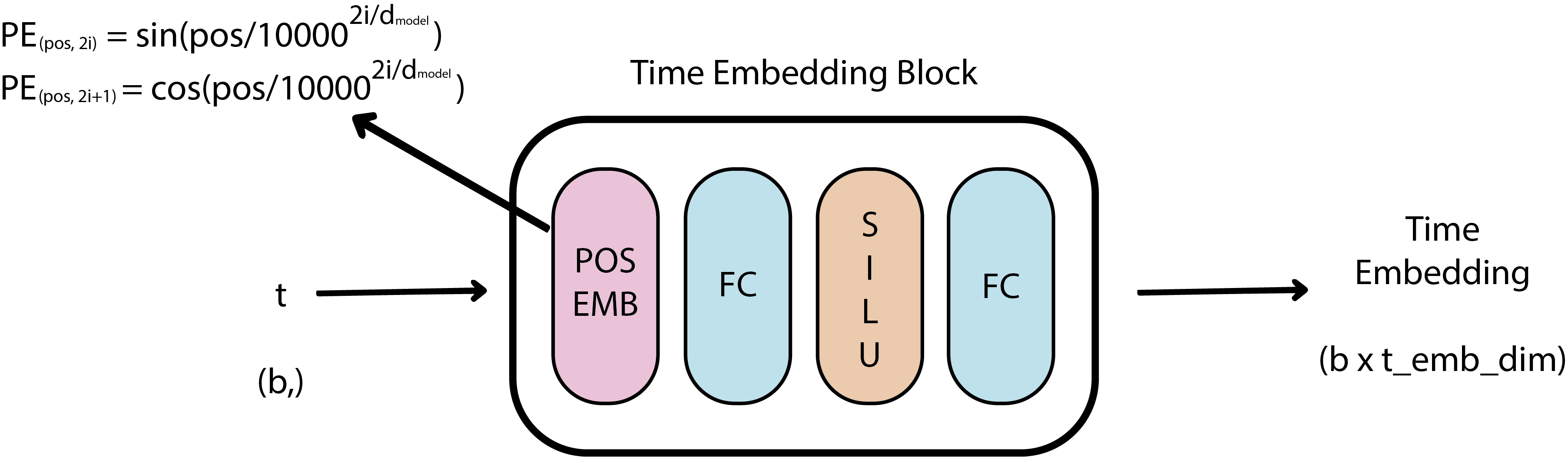
The time step is handled using a Time Embedding Block, which takes a 1D tensor of time steps of size b (batch size) and outputs a representation of size t_emb_dim for each time step in the batch. This block first converts the integer time steps into a vector representation through an embedding space. This embedding is then passed through two linear layers with an activation function in between, producing the final time step representation. For the embedding space, the authors use the sinusoidal positional embedding approach, commonly utilized in Transformers. Throughout the architecture, the activation function used is the sigmoid linear unit (SiLU), though other activations can also be chosen.
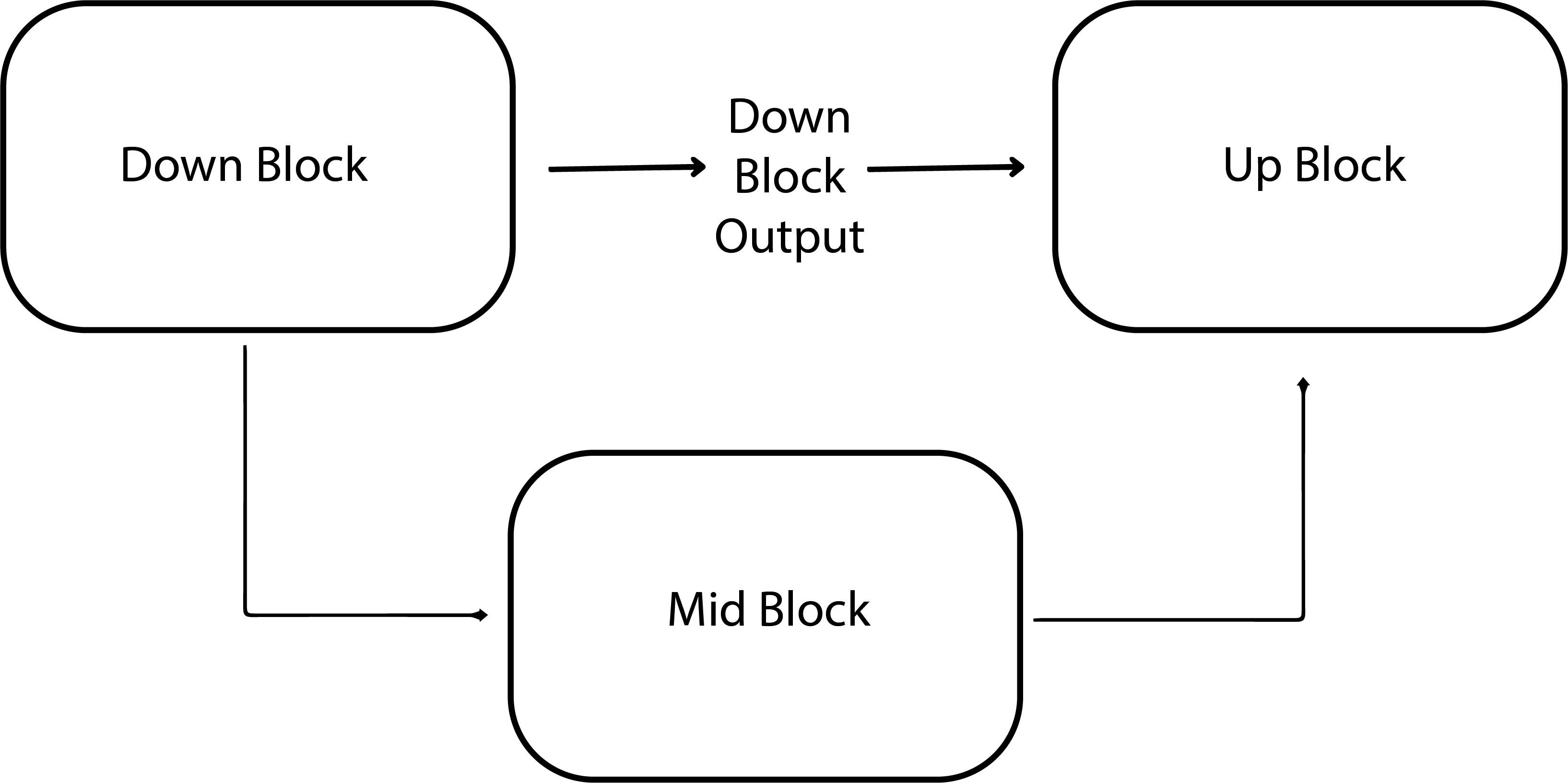
The UNet Architecture follows a simple Encoder-Decoder design. The encoder consists of multiple downsampling blocks, where each block reduces the spatial dimensions of the input, typically halving them, while increasing the number of channels. The output from the final downsampling block is processed by several layers in the mid-block, all operating at the same spatial resolution. Following this, the decoder employs upsampling blocks, which progressively increase the spatial dimensions and decrease the number of channels, ultimately matching the original input size. In the decoder, the upsampling blocks integrate outputs from their corresponding downsampling blocks at the same resolution through residual skip connections. While most diffusion models adhere to this general UNet architecture, they vary in the specific details and configurations within individual blocks.
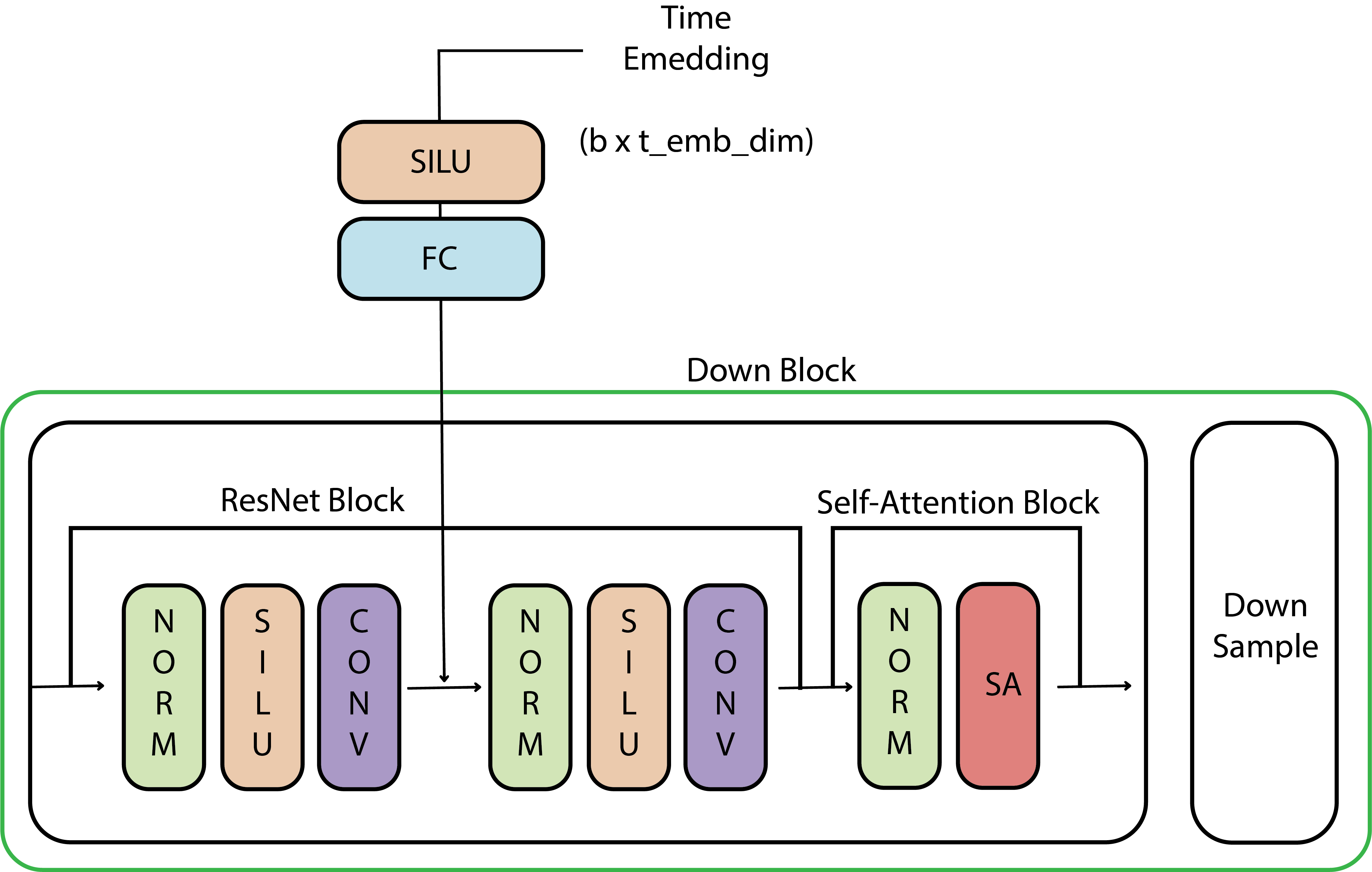
The down block in most variations typically consists of a ResNet block, followed by a self-attention block and a downsampling layer. Each ResNet block is constructed using a sequence of operations: Group Normalization, an activation layer, and a convolutional layer. The output of this sequence is passed through another set of normalization, activation, and convolutional layers. A residual connection is added by combining the input of the first normalization layer with the output of the second convolutional layer. This complete sequence forms the ResNet block, which can be thought of as two convolutional blocks connected via a residual connection.
Following the ResNet block, there is a normalization step, a self-attention layer, and another residual connection. While models often use multiple layers of ResNet and self-attention, for simplicity, our implementation will use just one layer of each.
To incorporate time information, each ResNet block includes an activation layer followed by a linear layer, which processes the time embedding representation. The time embedding, represented as a tensor of size t_emb_dim, is passed through this linear layer to project it into a tensor with the same size and number of channels as the convolutional layer’s output. This allows the time embedding to be added to the convolutional layer’s output by replicating the time step representation across the spatial dimensions.
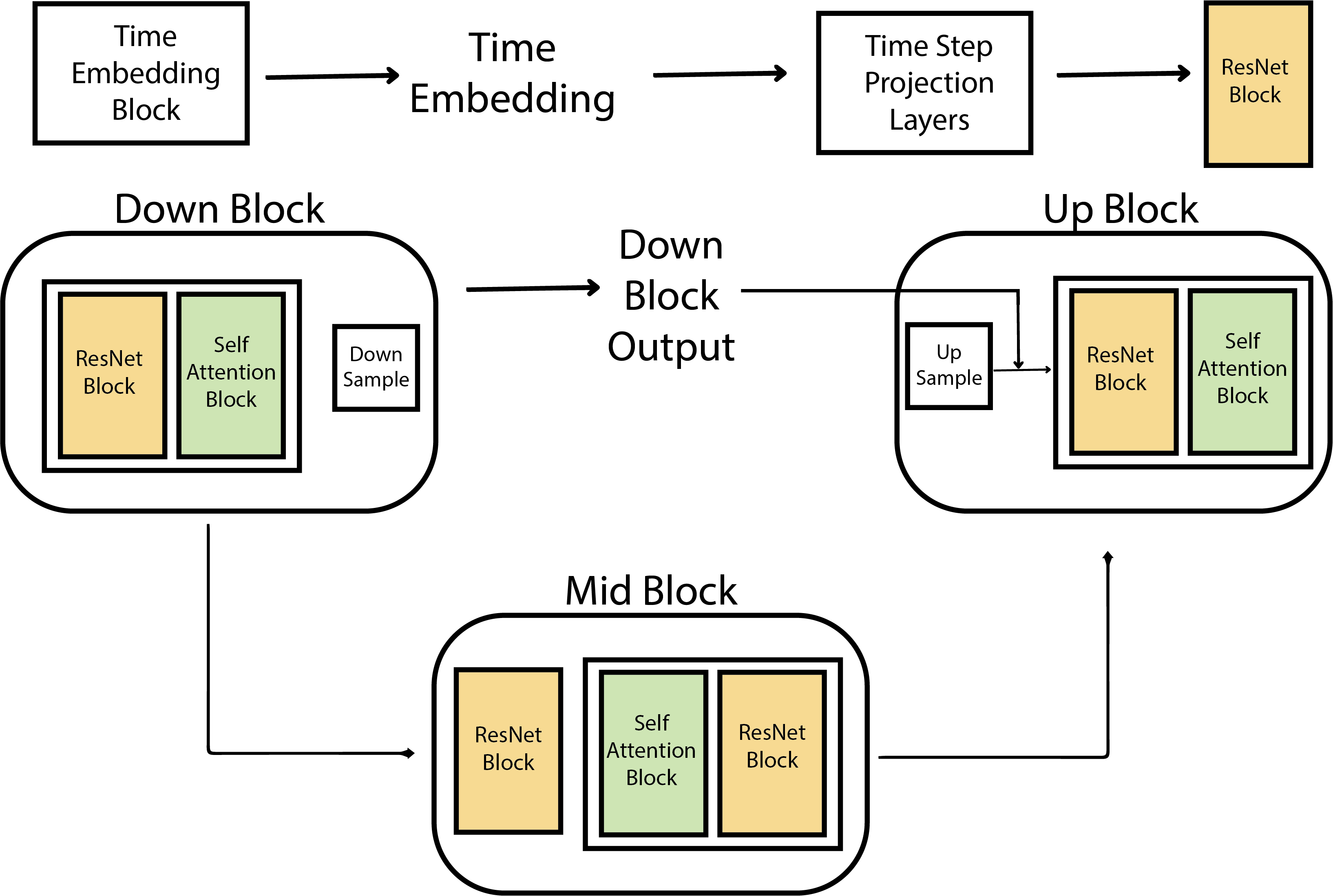
The other two blocks are using the same components just slightly different. The Up Block is excatly same except that it first up samples the input to twice the spatial size and then concentrates the down block output of the same spatial resolution across the channel dimension. Then we have the same layers of resnet and self-attention blocks. The layers of Mid Block always maintain the input to the same spatial resolution. The hugging face version has first one resnet block and and then followed by layers of self-attention and resnet. For each of these resnet blocks we have a time step projection layer. The exisiting time step representation goes through these blocks before being added to the output of first convolution layer of the resnet.
import torch import torch.nn as nn def get_time_embedding(time_steps, temb_dim): assert temb_dim % 2 == 0, "time embedding dimension must be divisible by 2" # factor = 10000^(2i/d_model) factor = 10000 ** ((torch.arange( start=0, end=temb_dim // 2, dtype=torch.float32, device=time_steps.device) / (temb_dim // 2)) ) # pos / factor # timesteps B -> B, 1 -> B, temb_dim t_emb = time_steps[:, None].repeat(1, temb_dim // 2) / factor t_emb = torch.cat([torch.sin(t_emb), torch.cos(t_emb)], dim=-1) return t_emb
The first function get_time_embedding generates a time embedding for given time steps. It is inspired by the sinusoidal position embeddings used in Transformer models.
time_steps: A tensor of time step values (shape: [B] where B is the batch size). Each value represents a discrete time step for the batch element.
temb_dim: The dimensionality of the time embedding. This determines the size of the generated embedding for each time step.
Ensures that temb_dim is even because the sinusoidal embedding requires splitting the embedding into two halves for sine and cosine components. Scales seamlessly to handle any batch size or embedding dimension.
class DownBlock(nn.Module): def __init__(self, in_channels, out_channels, t_emb_dim, down_sample=True, num_heads=4, num_layers=1): super().__init__() self.num_layers = num_layers self.down_sample = down_sample self.resnet_conv_first = nn.ModuleList( [ nn.Sequential( nn.GroupNorm(8, in_channels if i == 0 else out_channels), nn.SiLU(), nn.Conv2d(in_channels if i == 0 else out_channels, out_channels, kernel_size=3, stride=1, padding=1), ) for i in range(num_layers) ] ) self.t_emb_layers = nn.ModuleList([ nn.Sequential( nn.SiLU(), nn.Linear(t_emb_dim, out_channels) ) for _ in range(num_layers) ]) self.resnet_conv_second = nn.ModuleList( [ nn.Sequential( nn.GroupNorm(8, out_channels), nn.SiLU(), nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1), ) for _ in range(num_layers) ] ) self.attention_norms = nn.ModuleList( [nn.GroupNorm(8, out_channels) for _ in range(num_layers)] ) self.attentions = nn.ModuleList( [nn.MultiheadAttention(out_channels, num_heads, batch_first=True) for _ in range(num_layers)] ) self.residual_input_conv = nn.ModuleList( [ nn.Conv2d(in_channels if i == 0 else out_channels, out_channels, kernel_size=1) for i in range(num_layers) ] ) self.down_sample_conv = nn.Conv2d(out_channels, out_channels, 4, 2, 1) if self.down_sample else nn.Identity() def forward(self, x, t_emb): out = x for i in range(self.num_layers): # Resnet block of Unet resnet_input = out out = self.resnet_conv_first[i](out) out = out + self.t_emb_layers[i](t_emb)[:, :, None, None] out = self.resnet_conv_second[i](out) out = out + self.residual_input_conv[i](resnet_input) # Attention block of Unet batch_size, channels, h, w = out.shape in_attn = out.reshape(batch_size, channels, h * w) in_attn = self.attention_norms[i](in_attn) in_attn = in_attn.transpose(1, 2) out_attn, _ = self.attentions[i](in_attn, in_attn, in_attn) out_attn = out_attn.transpose(1, 2).reshape(batch_size, channels, h, w) out = out + out_attn out = self.down_sample_conv(out) return out
The DownBlock class combines ResNet blocks, self-attention blocks, and optional downsampling, with time embedding integration to incorporate time step information. Combines convolutional layers with residual connections for better gradient flow and more efficient learning. Projects the time step representation into the feature space, enabling the model to incorporate time-dependent information. Captures long-range dependencies by modeling relationships between all spatial locations. Reduces spatial dimensions to focus on larger-scale features in deeper layers.
in_channels: Number of input channels.
out_channels: Number of output channels.
t_emb_dim: Dimension of the time embedding.
down_sample: Boolean to determine if downsampling is applied at the end of the block.
num_heads: Number of attention heads in the multihead attention layer.
num_layers: Number of ResNet + attention layers in this block.
resnet_conv_first: First convolutional layer of ResNet blocks.
t_emb_layers: Time embedding projection layers.
resnet_conv_second: Second convolutional layer of ResNet blocks.
residual_input_conv: A 1x1 convolution for residual connections.
attention_norms: Group normalization layers before attention.
attentions: Multihead attention layers.
down_sample_conv: Applies a convolution to reduce spatial dimensions (if down_sample=True).
The Forward Pass method defines how the input tensor x is processed through the block: out is initialized as the input x. For each layer we have ResNet Block and Self-Attention Block.
In ResNet Block we have First Convolutional Layer which applies GroupNorm, SiLU activation, and 3x3 convolution and a Time Embedding Function which passes the time embedding t_emb through a linear layer (to project to out_channels), and adds this projected time embedding to out (broadcasted over spatial dimensions). Then we have Second Convolution and a Residual Connection which adds the original input (resnet_input) to the output of the second convolution.
In Self-Attention Block we flattens the spatial dimensions into one dimension (h * w) for the attention mechanism. Normalizes the input and transposes to match the attention layer input format. Multihead Attention which performs self-attention using in_attn as the query, key, and value. Reshape Back which transposes and reshapes back to the original spatial dimensions. Residual Connection and Downsampling.
class MidBlock(nn.Module): def __init__(self, in_channels, out_channels, t_emb_dim, num_heads=4, num_layers=1): super().__init__() self.num_layers = num_layers self.resnet_conv_first = nn.ModuleList( [ nn.Sequential( nn.GroupNorm(8, in_channels if i == 0 else out_channels), nn.SiLU(), nn.Conv2d(in_channels if i == 0 else out_channels, out_channels, kernel_size=3, stride=1, padding=1), ) for i in range(num_layers+1) ] ) self.t_emb_layers = nn.ModuleList([ nn.Sequential( nn.SiLU(), nn.Linear(t_emb_dim, out_channels) ) for _ in range(num_layers + 1) ]) self.resnet_conv_second = nn.ModuleList( [ nn.Sequential( nn.GroupNorm(8, out_channels), nn.SiLU(), nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1), ) for _ in range(num_layers+1) ] ) self.attention_norms = nn.ModuleList( [nn.GroupNorm(8, out_channels) for _ in range(num_layers)] ) self.attentions = nn.ModuleList( [nn.MultiheadAttention(out_channels, num_heads, batch_first=True) for _ in range(num_layers)] ) self.residual_input_conv = nn.ModuleList( [ nn.Conv2d(in_channels if i == 0 else out_channels, out_channels, kernel_size=1) for i in range(num_layers+1) ] ) def forward(self, x, t_emb): out = x # First resnet block resnet_input = out out = self.resnet_conv_first[0](out) out = out + self.t_emb_layers[0](t_emb)[:, :, None, None] out = self.resnet_conv_second[0](out) out = out + self.residual_input_conv[0](resnet_input) for i in range(self.num_layers): # Attention Block batch_size, channels, h, w = out.shape in_attn = out.reshape(batch_size, channels, h * w) in_attn = self.attention_norms[i](in_attn) in_attn = in_attn.transpose(1, 2) out_attn, _ = self.attentions[i](in_attn, in_attn, in_attn) out_attn = out_attn.transpose(1, 2).reshape(batch_size, channels, h, w) out = out + out_attn # Resnet Block resnet_input = out out = self.resnet_conv_first[i+1](out) out = out + self.t_emb_layers[i+1](t_emb)[:, :, None, None] out = self.resnet_conv_second[i+1](out) out = out + self.residual_input_conv[i+1](resnet_input) return out
The MidBlock class is a module that sits in the middle of a U-Net architecture in a diffusion model. It consists of ResNet blocks and self-attention layers and integrates time embedding to handle temporal information. This is a crucial component of models used for tasks such as denoising diffusion. Additionally we have:
Time Embedding: Time information (e.g., denoising step in diffusion models) is incorporated by projecting it into the feature space and adding it to the convolutional features.
Layer Iteration: Alternates between attention and ResNet blocks, processing the input sequentially through num_layers of these combinations.
class UpBlock(nn.Module): def __init__(self, in_channels, out_channels, t_emb_dim, up_sample=True, num_heads=4, num_layers=1): super().__init__() self.num_layers = num_layers self.up_sample = up_sample self.resnet_conv_first = nn.ModuleList( [ nn.Sequential( nn.GroupNorm(8, in_channels if i == 0 else out_channels), nn.SiLU(), nn.Conv2d(in_channels if i == 0 else out_channels, out_channels, kernel_size=3, stride=1, padding=1), ) for i in range(num_layers) ] ) self.t_emb_layers = nn.ModuleList([ nn.Sequential( nn.SiLU(), nn.Linear(t_emb_dim, out_channels) ) for _ in range(num_layers) ]) self.resnet_conv_second = nn.ModuleList( [ nn.Sequential( nn.GroupNorm(8, out_channels), nn.SiLU(), nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1), ) for _ in range(num_layers) ] ) self.attention_norms = nn.ModuleList( [ nn.GroupNorm(8, out_channels) for _ in range(num_layers) ] ) self.attentions = nn.ModuleList( [ nn.MultiheadAttention(out_channels, num_heads, batch_first=True) for _ in range(num_layers) ] ) self.residual_input_conv = nn.ModuleList( [ nn.Conv2d(in_channels if i == 0 else out_channels, out_channels, kernel_size=1) for i in range(num_layers) ] ) self.up_sample_conv = nn.ConvTranspose2d(in_channels // 2, in_channels // 2, 4, 2, 1) \ if self.up_sample else nn.Identity() def forward(self, x, out_down, t_emb): x = self.up_sample_conv(x) x = torch.cat([x, out_down], dim=1) out = x for i in range(self.num_layers): resnet_input = out out = self.resnet_conv_first[i](out) out = out + self.t_emb_layers[i](t_emb)[:, :, None, None] out = self.resnet_conv_second[i](out) out = out + self.residual_input_conv[i](resnet_input) batch_size, channels, h, w = out.shape in_attn = out.reshape(batch_size, channels, h * w) in_attn = self.attention_norms[i](in_attn) in_attn = in_attn.transpose(1, 2) out_attn, _ = self.attentions[i](in_attn, in_attn, in_attn) out_attn = out_attn.transpose(1, 2).reshape(batch_size, channels, h, w) out = out + out_attn return out
The UpBlock class is part of the decoder stage of a U-Net-like architecture, typically used in diffusion models or other image generation/segmentation tasks. It combines up-sampling, skip connections, ResNet blocks, and self-attention to reconstruct the output image while preserving fine-grained details from earlier encoder stages.
class Unet(nn.Module): def __init__(self, model_config): super().__init__() im_channels = model_config['im_channels'] self.down_channels = model_config['down_channels'] self.mid_channels = model_config['mid_channels'] self.t_emb_dim = model_config['time_emb_dim'] self.down_sample = model_config['down_sample'] self.num_down_layers = model_config['num_down_layers'] self.num_mid_layers = model_config['num_mid_layers'] self.num_up_layers = model_config['num_up_layers'] assert self.mid_channels[0] == self.down_channels[-1] assert self.mid_channels[-1] == self.down_channels[-2] assert len(self.down_sample) == len(self.down_channels) - 1 # Initial projection from sinusoidal time embedding self.t_proj = nn.Sequential( nn.Linear(self.t_emb_dim, self.t_emb_dim), nn.SiLU(), nn.Linear(self.t_emb_dim, self.t_emb_dim) ) self.up_sample = list(reversed(self.down_sample)) self.conv_in = nn.Conv2d(im_channels, self.down_channels[0], kernel_size=3, padding=(1, 1)) self.downs = nn.ModuleList([]) for i in range(len(self.down_channels)-1): self.downs.append(DownBlock(self.down_channels[i], self.down_channels[i+1], self.t_emb_dim, down_sample=self.down_sample[i], num_layers=self.num_down_layers)) self.mids = nn.ModuleList([]) for i in range(len(self.mid_channels)-1): self.mids.append(MidBlock(self.mid_channels[i], self.mid_channels[i+1], self.t_emb_dim, num_layers=self.num_mid_layers)) self.ups = nn.ModuleList([]) for i in reversed(range(len(self.down_channels)-1)): self.ups.append(UpBlock(self.down_channels[i] * 2, self.down_channels[i-1] if i != 0 else 16, self.t_emb_dim, up_sample=self.down_sample[i], num_layers=self.num_up_layers)) self.norm_out = nn.GroupNorm(8, 16) self.conv_out = nn.Conv2d(16, im_channels, kernel_size=3, padding=1) def forward(self, x, t): # Shapes assuming downblocks are [C1, C2, C3, C4] # Shapes assuming midblocks are [C4, C4, C3] # Shapes assuming downsamples are [True, True, False] # B x C x H x W out = self.conv_in(x) # B x C1 x H x W # t_emb -> B x t_emb_dim t_emb = get_time_embedding(torch.as_tensor(t).long(), self.t_emb_dim) t_emb = self.t_proj(t_emb) down_outs = [] for idx, down in enumerate(self.downs): down_outs.append(out) out = down(out, t_emb) # down_outs [B x C1 x H x W, B x C2 x H/2 x W/2, B x C3 x H/4 x W/4] # out B x C4 x H/4 x W/4 for mid in self.mids: out = mid(out, t_emb) # out B x C3 x H/4 x W/4 for up in self.ups: down_out = down_outs.pop() out = up(out, down_out, t_emb) # out [B x C2 x H/4 x W/4, B x C1 x H/2 x W/2, B x 16 x H x W] out = self.norm_out(out) out = nn.SiLU()(out) out = self.conv_out(out) # out B x C x H x W return out
The Unet class is an implementation of a U-Net architecture designed for image processing tasks, such as segmentation or generation, often used in diffusion models. The network includes down-sampling, mid-level processing, and up-sampling stages. It utilizes time embeddings for dynamic tasks (e.g., diffusion models), skip connections to retain spatial information, and GroupNorm for normalization.

import torch import yaml import argparse import os import numpy as np from tqdm import tqdm from torch.optim import Adam from dataset.mnist_dataset import MnistDataset from torch.utils.data import DataLoader from models.unet_base import Unet from scheduler.linear_noise_scheduler import LinearNoiseScheduler device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') def train(args): with open(args.config_path, 'r') as file: try: config = yaml.safe_load(file) except yaml.YAMLError as exc: print(exc) print(config) diffusion_config = config['diffusion_params'] dataset_config = config['dataset_params'] model_config = config['model_params'] train_config = config['train_params'] # Create the noise scheduler scheduler = LinearNoiseScheduler(num_timesteps=diffusion_config['num_timesteps'], beta_start=diffusion_config['beta_start'], beta_end=diffusion_config['beta_end']) # Create the dataset mnist = MnistDataset('train', im_path=dataset_config['im_path']) mnist_loader = DataLoader(mnist, batch_size=train_config['batch_size'], shuffle=True, num_workers=4) # Instantiate the model model = Unet(model_config).to(device) model.train() # Create output directories if not os.path.exists(train_config['task_name']): os.mkdir(train_config['task_name']) # Load checkpoint if found if os.path.exists(os.path.join(train_config['task_name'],train_config['ckpt_name'])): print('Loading checkpoint as found one') model.load_state_dict(torch.load(os.path.join(train_config['task_name'], train_config['ckpt_name']), map_location=device)) # Specify training parameters num_epochs = train_config['num_epochs'] optimizer = Adam(model.parameters(), lr=train_config['lr']) criterion = torch.nn.MSELoss() # Run training for epoch_idx in range(num_epochs): losses = [] for im in tqdm(mnist_loader): optimizer.zero_grad() im = im.float().to(device) # Sample random noise noise = torch.randn_like(im).to(device) # Sample timestep t = torch.randint(0, diffusion_config['num_timesteps'], (im.shape[0],)).to(device) # Add noise to images according to timestep noisy_im = scheduler.add_noise(im, noise, t) noise_pred = model(noisy_im, t) loss = criterion(noise_pred, noise) losses.append(loss.item()) loss.backward() optimizer.step() print('Finished epoch:{} | Loss : {:.4f}'.format( epoch_idx + 1, np.mean(losses), )) torch.save(model.state_dict(), os.path.join(train_config['task_name'], train_config['ckpt_name'])) print('Done Training ...') if __name__ == '__main__': parser = argparse.ArgumentParser(description='Arguments for ddpm training') parser.add_argument('--config', dest='config_path', default='config/default.yaml', type=str) args = parser.parse_args() train(args)
Load Configuration: Reads training configurations (like dataset paths, hyperparameters, and model settings) from a YAML file.
Setup Components:
Training Loop: For each epoch:
-Iterates through the dataset, adding noise to images based on a sampled timestep.
Completion: Prints epoch loss and saves the model at the end of each epoch.
import torch import torchvision import argparse import yaml import os from torchvision.utils import make_grid from tqdm import tqdm from models.unet_base import Unet from scheduler.linear_noise_scheduler import LinearNoiseScheduler device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') def sample(model, scheduler, train_config, model_config, diffusion_config): xt = torch.randn((train_config['num_samples'], model_config['im_channels'], model_config['im_size'], model_config['im_size'])).to(device) for i in tqdm(reversed(range(diffusion_config['num_timesteps']))): # Get prediction of noise noise_pred = model(xt, torch.as_tensor(i).unsqueeze(0).to(device)) # Use scheduler to get x0 and xt-1 xt, x0_pred = scheduler.sample_prev_timestep(xt, noise_pred, torch.as_tensor(i).to(device)) # Save x0 ims = torch.clamp(xt, -1., 1.).detach().cpu() ims = (ims + 1) / 2 grid = make_grid(ims, nrow=train_config['num_grid_rows']) img = torchvision.transforms.ToPILImage()(grid) if not os.path.exists(os.path.join(train_config['task_name'], 'samples')): os.mkdir(os.path.join(train_config['task_name'], 'samples')) img.save(os.path.join(train_config['task_name'], 'samples', 'x0_{}.png'.format(i))) img.close() def infer(args): # Read the config file # with open(args.config_path, 'r') as file: try: config = yaml.safe_load(file) except yaml.YAMLError as exc: print(exc) print(config) diffusion_config = config['diffusion_params'] model_config = config['model_params'] train_config = config['train_params'] # Load model with checkpoint model = Unet(model_config).to(device) model.load_state_dict(torch.load(os.path.join(train_config['task_name'], train_config['ckpt_name']), map_location=device)) model.eval() # Create the noise scheduler scheduler = LinearNoiseScheduler(num_timesteps=diffusion_config['num_timesteps'], beta_start=diffusion_config['beta_start'], beta_end=diffusion_config['beta_end']) with torch.no_grad(): sample(model, scheduler, train_config, model_config, diffusion_config) if __name__ == '__main__': parser = argparse.ArgumentParser(description='Arguments for ddpm image generation') parser.add_argument('--config', dest='config_path', default='config/default.yaml', type=str) args = parser.parse_args() infer(args)
Load Configuration: Reads model, diffusion, and training parameters from a YAML file.
Model Setup: Loads the trained U-Net model checkpoint. Initializes a noise scheduler to guide the reverse diffusion process.
Sampling Process:
dataset_params: im_path: 'data/train/images' diffusion_params: num_timesteps : 1000 beta_start : 0.0001 beta_end : 0.02 model_params: im_channels : 1 im_size : 28 down_channels : [32, 64, 128, 256] mid_channels : [256, 256, 128] down_sample : [True, True, False] time_emb_dim : 128 num_down_layers : 2 num_mid_layers : 2 num_up_layers : 2 num_heads : 4 train_params: task_name: 'default' batch_size: 64 num_epochs: 40 num_samples : 100 num_grid_rows : 10 lr: 0.0001 ckpt_name: 'ddpm_ckpt.pth'
This configuration file provides settings for training and inference of a diffusion model.
Dataset Parameters: Specifies the path (im_path) to training images.
Diffusion Parameters: Sets the number of timesteps for the diffusion process and the range of noise parameters (beta_start and beta_end).
Model Parameters:
im_size).down_sample).Training Parameters:
import glob import os import torchvision from PIL import Image from tqdm import tqdm from torch.utils.data.dataloader import DataLoader from torch.utils.data.dataset import Dataset class MnistDataset(Dataset): self.split = split self.im_ext = im_ext self.images, self.labels = self.load_images(im_path) def load_images(self, im_path): assert os.path.exists(im_path), "images path {} does not exist".format(im_path) ims = [] labels = [] for d_name in tqdm(os.listdir(im_path)): for fname in glob.glob(os.path.join(im_path, d_name, '*.{}'.format(self.im_ext))): ims.append(fname) labels.append(int(d_name)) print('Found {} images for split {}'.format(len(ims), self.split)) return ims, labels def __len__(self): return len(self.images) def __getitem__(self, index): im = Image.open(self.images[index]) im_tensor = torchvision.transforms.ToTensor()(im) # Convert input to -1 to 1 range. im_tensor = (2 * im_tensor) - 1 return im_tensor
Initialization: Takes a split name, image file extension (im_ext), and image path (im_path). Calls load_images to load image paths and their corresponding labels.
Image Loading: load_images traverses the directory structure at im_path, assuming subdirectories are labeled (e.g., 0, 1, ... for digit classes). Collects image file paths and assigns labels based on the folder name.
Dataset Length: __len__ returns the total number of images.
Data Retrieval: __getitem__ retrieves an image by index, converts it to a tensor, and scales pixel values to the range −1,1-1, 1−1,1.