Introduction
AI agents are transforming various fields, with one of their most powerful applications being data analysis. By bridging the gap between complex databases and non-technical users, these agents eliminate the need for SQL expertise or database knowledge. Instead of writing queries, users can simply ask questions in natural language and receive meaningful insights—making data exploration more accessible than ever.
This publication showcases an AI agent designed for Funnel Analysis on real-time streaming data that:
- accepts questions in natural language,
- retrieves the schema and metadata of the database,
- generates, validates, and executes SQL queries to find the answer, and
- returns the results in natural language for easy interpretation.
Developed as part of the StarTree Mission Impossible: Data Reckoning Challenge, this AI agent secured 2nd place in the competition.
Problem Statement
The challenge was to develop an AI-powered Funnel Analysis Agent that could analyze a real-time clickstream dataset sourced from Kafka topics. The agent leverages Function Calling Tools to translate natural language questions into Apache Pinot queries, enabling real-time insights into user behavior and clickstream analytics.
The agent should be capable of answering critical business questions, such as:
- What is the overall funnel conversion rate?
- What is the biggest drop-off in the funnel?
- Who are the top 3 users in terms of time spent?
- What other products can we recommend to these users?
- What are the top 5 electronic items sold?
Data Collection
The datasets required for this project were readily available from StarTree for the Data Reckoning Challenge. They were ingested into StarTree Cloud's Apache Pinot instance using StarTree Data Manager, making them accessible for querying via Apache Pinot SQL.
The following table provides an overview of the datasets, including their type, purpose, and source.
| Dataset Name | Type | Description | Data Source |
|---|---|---|---|
| Clickstream Data | Transactional | This contains transactional information about user events (view, click, save, purchase), when they were performed and the duration. | Apache Kafka topic |
| Purchase Data | Transactional | This contains transactional information about purchases performed by users (buyers), including the item purchased, quantity, and date of purchase. | Apache Kafka topic |
| Products | Dimensional | This contains information about the items and their descriptions. | AWS S3 Bucket |
| Users | Dimensional | This contains detailed information about users (buyers) - including the name, address, contact information, etc. | AWS S3 Bucket |
Methodology
1. Agent Design and Architecture
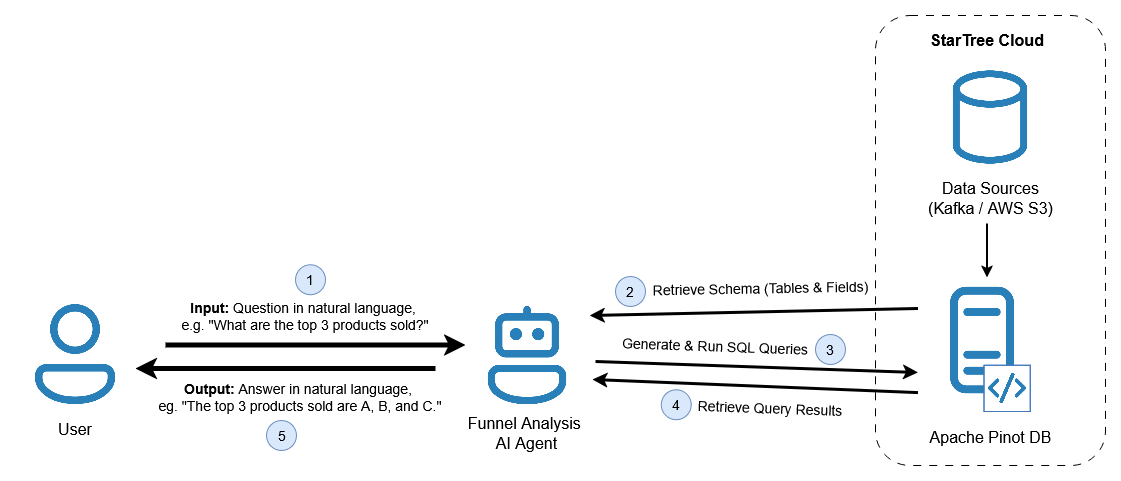
The AI agent bridges user queries with Apache Pinot, following a structured workflow:
- User Input: The agent receives a business question in natural language.
- Schema Retrieval: It retrieves table and field metadata from Pinot to guide query generation.
- Query Generation and Execution: Using the metadata and user input, the agent constructs and validates an SQL query, executing it on Apache Pinot.
- Result Retrieval: The agent fetches the query results from Pinot.
- Response Generation: The results are processed into a natural language response, which is returned to the user.
The system architecture diagram below outlines this end-to-end process, highlighting the agent’s role in schema-aware query generation and real-time data retrieval.
2. Data Pipeline and Storage
The data pipeline integrates real-time clickstream events and purchase data, streamed through Kafka topics, with dimensional data such as product descriptions and user details stored in AWS S3 buckets. This data is ingested into Apache Pinot (hosted on StarTree Cloud) using StarTree Data Manager. Pinot serves as both the real-time OLAP store for queries and the schema provider to inform query generation.
from sqlalchemy.dialects import registry from pinotdb.sqlalchemy import PinotDialect, PinotHTTPSDialect from langchain_community.utilities import SQLDatabase from langchain.agents.agent_toolkits import SQLDatabaseToolkit # Register Apache Pinot SQLAlchemy Dialect for accurate query validation registry.register("pinot", "pinotdb.sqlalchemy", "PinotDialect") PinotDialect.supports_statement_cache = False PinotHTTPSDialect.supports_statement_cache = False # Initialize connection to Apache Pinot pinot_db = SQLDatabase.from_uri("<pinot_connection_uri>")
3. Agent Setup and Initialization
The agent was built using LangChain's SQLDatabase and SQLDatabaseToolkit, simplifying the interaction with Pinot through pre-built tools.
from langchain.agents import create_react_agent from langchain_openai import ChatOpenAI # Initialize LLM llm = ChatOpenAI(api_key="<api_key>", temperature=0, model="gpt-4o-mini") # Initialize toolkit toolkit = SQLDatabaseToolkit(db=pinot_db, llm=llm)
The core tools part of this toolkit are:
- ListSQLDatabaseTool: Lists all tables in the database.
- InfoSQLDatabaseTool: Retrieves schema details for specified tables.
- QuerySQLCheckerTool: Validates the correctness of SQL queries before execution.
- QuerySQLDatabaseTool: Executes validated SQL queries and returns results.
A specialized Funnel Analysis Prompt was added to fine-tune the agent's understanding of clickstream analysis, incorporating Pinot-specific functions like FUNNEL_COUNT and LOOKUP.
# Load specialized prompt from LangChain Hub from langchain import hub from finetuned_prompt import finetuned_prompt # local import # Pull prompt prompt_template = hub.pull("langchain-ai/sql-agent-system-prompt") system_message = ( prompt_template.format(dialect="Apache Pinot MYSQL_ANSI dialect", top_k=3) + finetuned_prompt ) # Create agent agent_executor = create_react_agent( llm, toolkit.get_tools(), state_modifier=system_message )
4. Query Processing and Response Generation
Schema retrieval is crucial for ensuring that the agent generates accurate queries based on up-to-date table structures. By fetching table and column names dynamically, the agent avoids assumptions about the data schema, enhancing its adaptability to real-time changes.
When a user inputs a natural language query, the agent autonomously orchestrates the process using the provided tools. It retrieves the schema with InfoSQLDatabaseTool, generates and validates the SQL query with QuerySQLCheckerTool, executes the query with QuerySQLDatabaseTool, and finally formats the results into a natural language response.
Model Invocation:
The model is invoked using a helper function that takes the user input and passes it to the agent for processing:
def invoke_model(user_input: str): print("You:", user_input) # Invoke model events = agent_executor.stream( {"messages": [("user", user_input)]}, stream_mode="values", ) print_results(events) # Custom function for formatting SQL queries, intermediate steps, and final answers.
Example Invocation:
With the helper function in place, the model can be invoked effortlessly by passing the user question as input:
# Example question user_input = "What is the overall funnel conversion rate?" invoke_model(user_input)
Note: The full notebook code, including print_results() and additional details, can be found in the attached GitHub link.
5. Evaluation and Performance Considerations
The system was evaluated for speed, accuracy, and robustness. Pinot's real-time OLAP capabilities ensured sub-second query responses, making the agent highly performant for large streaming datasets. Key considerations included:
- Schema Handling: Ensured no assumptions about table names, relying on real-time schema retrieval.
- No Joins Support: Pinot does not support joins natively, so the agent used the LOOKUP function for enriching results with product/user details.
- Query Validation: The inclusion of a validation step significantly reduced query failures.
- Limitations and Future Work:
- No Support for Vector Similarity Search: This limits the agent’s ability to handle queries like "What other products can we recommend to these top users?". Ideally, product embeddings (already present in the products dimension table) could be compared using cosine similarity to identify the top matches.
- Lookup Function Reliability: The LOOKUP function does not always work as expected, occasionally requiring fallback queries to pull product/user details. This introduces the risk of hallucination if the lookup ID is incorrect, yielding inaccurate results.
- Pinot-Specific Functions: The model's performance when using Pinot-specific functions is inconsistent, especially when relying on prompts to infer query structure. Enhancing native support for these functions could improve accuracy.
This methodology allowed the agent to dynamically adapt to real-time data, leveraging Pinot’s capabilities while ensuring that queries adhered to its constraints.