Abstract
Traditional image segmentation methods rely solely on visual information, which limits their adaptability in diverse and complex scenarios. To address this, I re-implemented CLIPSeg, a novel approach that builds on Contrastive Language-Image Pretraining (CLIP) to integrate both textual and visual prompts for zero-shot image segmentation. By allowing users to input text prompts alongside images, CLIPSeg enables a more flexible and intuitive way to perform segmentation tasks, especially in cases where traditional methods struggle.
In this project, I added a custom decoder to the pre-trained CLIP model and used Feature-Wise Linear Modulation to condition image features based on text embedding. By using this approach, the model aligns textual inputs with the visual content of the image to accurately segment regions specified in the text.The model was trained on the RefCOCO dataset, a benchmark for referring image segmentation tasks, where natural language expressions are used to identify specific objects in images. The results demonstrate that the model can accurately generate segmentation masks guided by textual inputs. This work highlights the potential of combining vision and language models to develop interactive and robust segmentation systems suitable for real-world applications.
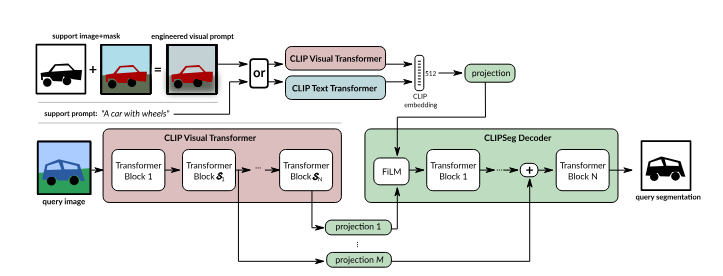
Methodology
I. Model Architecture
The CLIPSegmentationModel is built using the following components:
- Vision Encoder:
The visual backbone of the model uses CLIPVisionModelWithProjection from the pre-trained CLIP (openai/clip-vit-base-patch16). This component extracts image features and outputs hidden states from multiple layers.
self.vision_model = CLIPVisionModelWithProjection.from_pretrained("openai/clip-vit-base-patch16", output_hidden_states=True).to(device) self.vision_processor = AutoProcessor.from_pretrained("openai/clip-vit-base-patch16")
- Text Encoder:
Text inputs are processed using the pre-trained CLIPTextModelWithProjection, which provides text embeddings representing the semantic meaning of user-provided prompts.
self.text_model = CLIPTextModelWithProjection.from_pretrained("openai/clip-vit-base-patch16").to(device) self.text_tokenizer = AutoTokenizer.from_pretrained("openai/clip-vit-base-patch16")
- FiLM Modulation:
A Feature-wise Linear Modulation (FiLM) module is introduced to condition the image features on text features. The FiLM block computes scaling (γγ) and shifting (ββ) factors from the text embeddings and modulates the image features.
class FiLMModulation(nn.Module): def __init__(self, d_model, clip_dim): super(FiLMModulation, self).__init__() self.gamma = nn.Linear(clip_dim, d_model) self.beta = nn.Linear(clip_dim, d_model) def forward(self, x, conditioning): gamma = self.gamma(conditioning).unsqueeze(1) beta = self.beta(conditioning).unsqueeze(1) return gamma * x + beta
- Transformer Decoder:
A stack of transformer decoder layers processes the conditioned image features. Each layer includes multi-head self-attention, feed-forward sublayers, and residual connections to refine the features further.
class TransformerDecoderLayer(nn.Module): def __init__(self, d_model, num_heads=8): super(TransformerDecoderLayer, self).__init__() self.self_attn = nn.MultiheadAttention(d_model, num_heads) self.linear1 = nn.Linear(d_model, d_model * 4) self.dropout = nn.Dropout(0.1) self.linear2 = nn.Linear(d_model * 4, d_model) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.dropout1 = nn.Dropout(0.1) self.dropout2 = nn.Dropout(0.1) def forward(self, x): x2 = self.self_attn(x, x, x)[0] x = x + self.dropout1(x2) x = self.norm1(x) x2 = self.linear2(self.dropout(torch.relu(self.linear1(x)))) x = x + self.dropout2(x2) x = self.norm2(x) return x
- Projection Layer:
A linear projection layer maps the final features into a binary segmentation mask.
self.projection = nn.Linear(d_model, 1).to(device) mask = self.projection(decoder_input) mask = mask[:, 1:, :] batch_size = mask.size(0) num_patches = mask.size(1) height = width = int(num_patches ** 0.5) mask = mask.view(batch_size, height, width, -1) mask = mask.permute(0, 3, 1, 2).contiguous() mask = nn.functional.interpolate(mask, size=(224, 224), mode='bilinear', align_corners=False)
II. Training Details
- Dataset:
The model is trained on the RefCOCO dataset, a benchmark dataset for referring image segmentation. The dataset consists of images and natural language expressions that identify specific objects in the image.
Link to Dataset on Huggingface :- RefCOCO
- Loss Function:
Binary Cross-Entropy Loss (BCE), is used as loss function.
criterion = nn.BCEWithLogitsLoss()
- Optimization:
The model is trained using the Adam optimizer with a learning rate of 0.001.
optimizer = Adam(model.parameters(), lr=0.001)
- Hardware:
Training is conducted on a GPU-enabled google colab notebook for 10 epochs.
Results
The CLIPSeg model demonstrated strong performance in referring image segmentation tasks. Quantitatively, it achieved a Dice Score of 56.56% on the RefCOCO validation set. These results could outperform baseline methods such as U-Net if trained for an extended duration with a more optimized training configuration.
Following figure provides sample visualizations of the segmentation outputs.
| Referring Text | Sample Image | Predicted Mask | Ground Truth Mask |
|---|---|---|---|
| left player |  |  |  |
| bottom case |  |  |  |
References
- CLIP: Radford et al., 2021 - Learning Transferable Visual Models From Natural Language Supervision (https://arxiv.org/abs/2103.00020)
- CLIPSeg: Lüddecke et al., 2022 - Image Segmentation Using Text and Image Prompts (https://arxiv.org/abs/2112.10003)