Before we dive into all the tech definitions let’s try to understand this with a simple analogy. Think of a sentence like a delicious sandwich. Each part of the sandwich is important for making it tasty. Constituency parsing is like taking apart the sandwich to see how it’s made while dependency parsing is like looking at how each ingredient works together. It tells us which part of the sandwich is doing what.
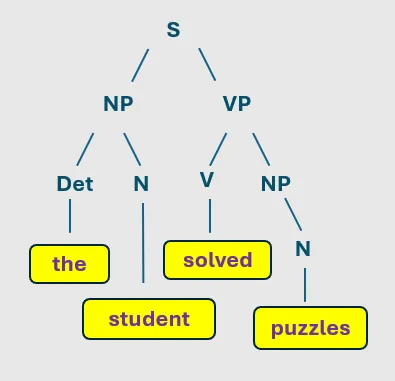
Continuing with our example “The student solved puzzles”. Constituency parsing tells us that:
- The students is one group (a noun phrase) that tells us who is doing the action.
- solved puzzles is another group (a verb phrase) that tells us what action is happening.
So, constituency parsing shows us that the sentence comprises two main parts: one for the subject the students and one for the action solving puzzles
While we saw in dependency parsing that the root word was the verb solved and the students depend on it because they are the ones performing the action and the puzzles rely on it because it tells us what was solved. Hence it focuses on how each word connects to and relies on other words.
Parse tree:
Constituency parsing constructs a phrase structure tree (or parse tree), where each node represents a grammatical unit (such as a word or a phrase). This tree showcases the syntactic structure of a sentence, indicating how smaller components combine to form larger units.
So how do we decide what to use, between constituency and dependency parsing?
Choosing between them depends on the specific use case and requirements.
Dependency Parsing allows for easy extraction of subject-verb-object (SVO) structures making it advantageous for tasks like question answering and information extraction. Dependency parse trees have SVO information readily available while extracting it from constituency trees often requires additional processing. Dependency parsing also excels in free word order languages, where word placement is flexible.
In contrast, Constituency Parsing is better suited for extracting sub-phrases from sentences, as it breaks down sentences into their component phrases, facilitating structural analysis.
Both parsing methods can extract features for supervised machine learning models, providing valuable syntactic information for tasks such as semantic role labeling. Ultimately, the choice between the two should consider the task, language characteristics, and desired outcomes. Each method has its strengths and weaknesses, and often, a combination of both can yield the most effective results in natural language processing applications.
Recommended Reading:
For a simple implementation of constituency parsing check it out on Amal Sarkar’s blog: Understanding Constituency Parsing