Cloudbursts, characterized by sudden, intense rainfall, often trigger flash floods, landslides, and debris flow, posing substantial threats. The study presents a robust cloudburst prediction system employing deep learning techniques, integrating Convolutional Neural Networks (CNN) for images and Feed-Forward Neural Networks (FNN) for tabular data. The motivation stems from the limitations of traditional prediction models, emphasizing the need for accurate, timely warnings. The comprehensive methodology includes data preparation, preprocessing, data splitting, model architecture, training, evaluation, and alert generation. Future prospects encompass data access via APIs, serverless computing, user-friendly interfaces, and collaborative data sharing, promising improved cloudburst prediction and disaster preparedness.
Cloudbursts; flash floods; deep learning; CNN; FNN; prediction system; disaster preparedness;
Cloudburst, a meteorological phenomenon characterized by sudden and intense rainfall, has wreaked havoc on the lives and properties of those inhabiting hilly and mountainous regions[1]. These events, often accompanied by flash floods, landslides, and debris flow, result in catastrophic losses, posing a significant threat to the well-being of local communities.
Consider some recent instances: Leh, Ladakh in 2010, Uttarkashi, Uttarakhand in 2012, Kedarnath in 2013, Chamoli, Uttarakhand in 2021, and Amarnath, Jammu and Kashmir in 2022[2]. Each of these cloudburst events underscores the dire consequences and challenges faced by residents in hilly areas.
The intention here is to comprehensively address the phenomenon of cloudbursts, exploring their causes, effects, and potential mitigation strategies to contribute to the safeguarding of lives and property in hilly regions, where the unique terrain and limited resources often compound the impact of natural disasters.
The primary objective of this research is to develop a highly reliable cloud burst prediction system that leverages mixed stream inputs, including tabular data and images, through the utilization of neural network deep learning techniques. This endeavor aims to significantly enhance public safety and reduce the risks associated with cloud bursts, ultimately making the general population safer from these natural disasters. Key objectives include the integration of mixed stream inputs, employing a Convolutional Neural Network (CNN) for image data and a feed-forward neural network (FNN) for tabular data(weather parameters), enhancing the reliability of cloud burst predictions, contributing to public safety by providing more accurate and early warnings for cloud bursts, and developing an alert generation system to enable timely notifications to local disaster management organizations. This ensures swift and proactive action can be taken to mitigate the potential impact of cloud bursts, thereby facilitating disaster preparedness and response.
The motivation for this research arises from the urgent need to enhance cloud burst prediction systems. Traditional models for cloud burst prediction have demonstrated limitations in terms of accuracy and timeliness, often hindering proactive disaster preparedness and response efforts[3]. These limitations include challenges in effectively capturing the complex and dynamic nature of cloud burst triggers and the potential for false alarms or delayed warnings. By integrating mixed data streams, including meteorological parameters (e.g., temperature, precipitation) in tabular data alongside image data, we aim to revolutionize cloud burst predictions. The integration enables a comprehensive understanding of cloud burst triggers. The ultimate goal is to improve public safety by providing more accurate, early warnings and implementing an alert generation system, thereby mitigating the impact of these events on lives and property.
The methodology section outlines the procedures and techniques employed in cloud burst prediction system.Fig 1 offers a visual context, a schematic diagram illustrating the system working process.
 Figure 1: Schematic Diagram of the Cloudburst Prediction System
Figure 1: Schematic Diagram of the Cloudburst Prediction System
Image Data Collection:
For the purpose of cloud burst prediction, satellite images were collected from Meteorological and Oceanographic Satellite Data Archival Centre(https://mosdac.gov.in/) [4]during the occurrence of cloud bursts, as well as 6 hours prior and 6 hours after the cloudburst.Moreover,images of random non cloudburst events were aslo collected.These images were meticulously classified into four categories: 'cloudburst,' 'precloudburst’, 'postcloudburst, and ‘no cloudburst’ providing a contextual basis for the prediction model.
Tabular Data Collection:
Complementary to the image data, essential meteorological parameters including latitude, longitude, 2m temperature, and total precipitation were obtained from the ECMWF ERA5 hourly data on single levels, spanning from 1940 to the present, through the Copernicus Climate Data Store CDS ERA5 Data. This dataset was collected for a 24-hour period surrounding major cloud burst events, such as the incidents in Chamoli, Uttarakhand, on February 7, 2021, the event in Amarnath, Jammu and Kashmir, on July 8, 2022, and the cloudburst in Jaipur on July 18, 2019, among others. Also, data of random non cloudburst events were also collceted. The tabular data, downloaded in NETCDF format, underwent extraction of pertinent features, including latitude, longitude, 2m temperature, and total precipitation, facilitated by the Panoply tool. These features were consolidated into a unified dataset in .CSV format.
Dataset Size:
The data preparation process yielded a dataset comprising 152 data points, which serves as the foundational dataset for model development and training.
Image Data Processing:
In the context of image data, satellite images were categorized into distinct phases, specifically 'cloudburst,' 'precloudburst, 'post-cloudburst, and ‘no-cloudburst,’ providing vital contextual information.Simultaneously, file names and their corresponding paths were extracted, streamlining data management.To ensure data consistency and model compatibility, the images were standardized by converting them from BGR to RGB format.
Tabular Data Integration:
Concurrently, meteorological data, encompassing latitude, longitude, temperature, and precipitation, was collected within the temporal context of major cloud burst events and random non cloudburst events.
The collected data was structured into separate DataFrames, each with a distinct role, and subsequently merged to create a comprehensive dataset that unified all relevant information.Additionally, the dataset underwent streamlining by removing extraneous columns, enhancing dataset efficiency and focusing solely on the most pertinent data.
Data Compression and Preparation:
Given the substantial size of the image data, measures were taken to compress the images into NPZ format, and the corresponding paths within the DataFrame were updated to ensure ease of accessibility.Fig 2 shows the dataframe with the NPZ paths added.
 Figure 2-Snapshot of Dataframe with NPZ paths
Figure 2-Snapshot of Dataframe with NPZ paths
Tabular Data Refinement:
To further refine the dataset, a separate DataFrame was introduced to store temperature and precipitation information, enhancing dataset organization.This stage also involved the calculation of crucial statistical properties, including mean and standard deviation values, which were essential for effective data scaling. The standard deviation values for 2m temperature and total precipitation were determined to be [27.14, 0.0017].The mean values for 2m temperature and total precipitation were found to be approximately [288.62, 0.0009].
TensorFlow Preprocessing Function:
For efficient data scaling, a TensorFlow preprocessing function named 'stat_scaler' was introduced. This function plays a pivotal role in standardizing and optimizing the data for further analysis.
In this phase, the dataset underwent a structured division for training, validation, and testing, achieved through the following steps:
Shuffling and Division:
The dataset was initially shuffled to introduce randomness and minimize potential biases.Subsequently, it was partitioned into three primary subsets
Training Set encompassed the initial 130 entries for model training.Entries 131 to 141 constituted the Validation Set, utilized for model fine-tuning.The Testing Set included entries starting from 142 onwards, designated for evaluating the model's performance.Data Extraction and Preparation:
To ensure the data was structured and ready for model application, an extraction function was employed. This function organized the data into distinct components: image data ('X_pic'), statistical data ('X_stats'), and labels ('y').
Training, Validation, and Testing Data:
The training dataset consisted of two key components, 'X_train_pic' (image data) and 'X_train_stats' (statistical data), accompanied by labels ('y_train').
Likewise, the validation dataset ('X_val_pic', 'X_val_stats', 'y_val') and testing dataset ('X_test_pic', 'X_test_stats', 'y_test') followed a similar structure. Each data component was meticulously organized, ensuring readiness for model deployment.
In our research, a sophisticated model architecture was designed and established to harness the mixed stream inputs, blending Convolutional Neural Networks (CNN) and Feed-Forward Neural Networks (FNN) for optimal performance. The model's construction involved the following key components:
Picture Stream (CNN):
A dedicated input layer was defined for image data, shaped as (224, 224, 3), providing the dimensions suitable for our dataset.Preprocessing of the input data was executed using a Lambda layer, ensuring compatibility with the MobileNetV2 architecture.The MobileNetV2 architecture, pre-trained on a large image dataset, was incorporated with the 'include_top' layer set to 'False,' facilitating feature extraction[5].A Global Average Pooling 2D layer condensed the extracted features, serving as a bridge between CNN and FNN components.Subsequently, a Dense layer with 256 units and a rectified linear unit (ReLU) activation function was introduced to enhance the network's capacity to capture complex patterns.To mitigate overfitting, a Dropout layer with a rate of 0.5 was added, applying regularization[6].
Stats Stream (Feed-Forward):
For tabular data, a separate input layer was defined with a shape of (2), matching the dimensions of our statistical features.Utilizing a Lambda layer, data was scaled and standardized, ensuring consistency with the neural network model.A Dense layer with 128 units and a ReLU activation function enriched the model's capability to process statistical data.To further address overfitting, a Dropout layer with a rate of 0.3 was integrated.
Model Fusion:
The outputs of the CNN and FNN streams were concatenated, creating a unified feature representation of the mixed stream inputs.
Output Layer:
To facilitate classification into four distinct classes (ranging from 0 to 3), a Dense layer with a softmax activation function was defined, ensuring the model's ability to provide probability distributions for each class.
Final Model:
The architecture culminated in the establishment of the final model. The model seamlessly incorporated both image and statistical data, providing a robust framework for cloud burst prediction.
The model summary has been provided below:
| Layer (type) | Output Shape | Param # | Connected to |
|---|---|---|---|
| input_1 (InputLayer) | (None, 224, 224, 3) | 0 | [] |
| lambda (Lambda) | (None, 224, 224, 3) | 0 | ['input_1[0][0]'] |
| mobilenetv2_1.00_224 (Functional) | (None, 7, 7, 1280) | 2,257,984 | ['lambda[0][0]'] |
| input_3 (InputLayer) | (None, 2) | 0 | [] |
| global_average_pooling2d (GlobalAveragePooling2D) | (None, 1280) | 0 | ['mobilenetv2_1.00_224[0][0]'] |
| lambda_1 (Lambda) | (None, 2) | 0 | ['input_3[0][0]'] |
| dense (Dense) | (None, 256) | 327,936 | ['global_average_pooling2d[0][0]'] |
| dense_1 (Dense) | (None, 128) | 384 | ['lambda_1[0][0]'] |
| dropout (Dropout) | (None, 256) | 0 | ['dense[0][0]'] |
| dropout_1 (Dropout) | (None, 128) | 0 | ['dense_1[0][0]'] |
| concatenate (Concatenate) | (None, 384) | 0 | ['dropout[0][0]', 'dropout_1[0][0]'] |
| dense_2 (Dense) | (None, 4) | 1,540 | ['concatenate[0][0]'] |
The model training process was implemented as follows:
Model Saving Callback:
A model checkpoint ('cp') was implemented to save the best model during training for future use.
Optimizer Definition and Compilation:
The model was compiled with the Adam optimizer, 'sparse_categorical_crossentropy' as the loss function, and 'accuracy' as the evaluation metric.
Training:
Model training was carried out for 10 epochs, using both image data ('X_train_pic') and statistical data ('X_train_stats') along with corresponding labels ('y_train').During the training, the model's performance was monitored, and the training loss was evaluated, resulting in a train loss of 0.2735 and a train accuracy of 90%.Validation data ('X_val_pic' and 'X_val_stats' with 'y_val') were used to assess the model's performance, ensuring accuracy and reliability in cloud burst prediction. The validation process also provided a validation loss of 2.4811 and a validation accuracy of 50%.Fig 3 demonstrates the Training and Validation Loss Over Epochs whereas Fig 4 demonstrates the Training and Validation Accuracy Over Epochs
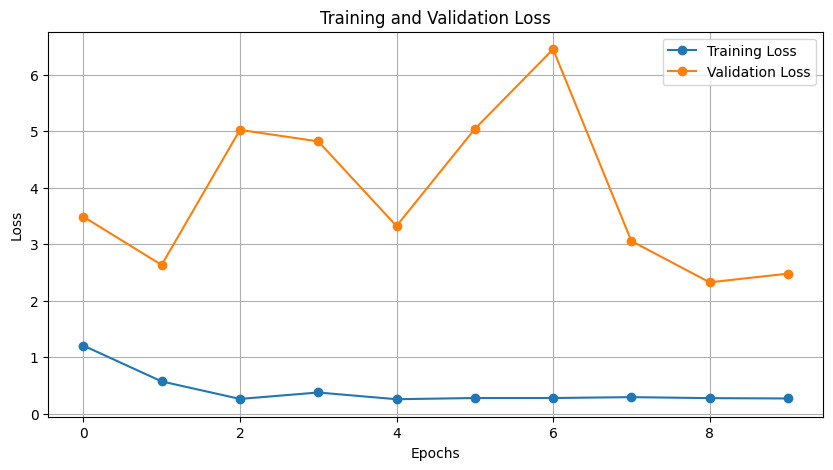 Figure 3-Training and Validation Loss Over Epochs
Figure 3-Training and Validation Loss Over Epochs
 Figure 4-Training and Validation Accuracy Over Epochs
Figure 4-Training and Validation Accuracy Over Epochs
The trained model was evaluated using the testing dataset to assess its performance in real-world scenarios.The testing data, comprising 'X_test_pic' (image data) and 'X_test_stats' (statistical data) along with labels 'y_test,' was used for evaluation.The 'evaluate' method was employed to compute the test loss and accuracy, resulting in a test loss of 2.7470 and a test accuracy of 60%.
In this critical phase, a robust alert generation system was implemented. To ensure timely and secure communication with disaster management agencies and forecasting organizations, a secure email communication framework was established. This framework involved configuring the system with password-protected credentials for email access. Messages, including crucial information about cloudburst predictions and recommended actions, were meticulously prepared. These alerts were then securely transmitted via the SMTP server to designated recipients.
As part of future enhancements, plans were put in place for the integration of SMS services via Twilio, contingent upon obtaining the necessary authorizations. This strategic expansion is aimed at further extending the reach of alerts and enhancing the overall effectiveness of the alert generation system.Fig 5 shows a demo advisory email sent for cloudburst situation.
 Figure 5-Demo Advisory email sent for Cloudburst situation
Figure 5-Demo Advisory email sent for Cloudburst situation
The research presented in this paper opens promising avenues for further development:
Direct Data Fetching via APIs:
Future work can focus on seamless integration of data sources through APIs to ensure real-time data access, reducing latency and improving predictive accuracy.
Serverless Computing for Continuous Monitoring:
Leveraging serverless platforms like AWS Lambda, Google Cloud Functions, or Azure Functions allows for automated, regular updates to the model with fresh data, enhancing its relevance.
Widespread Information Accessibility:
Developing user-friendly interfaces and mobile applications can empower a wider audience with essential cloudburst information, aiding informed decision-making and disaster preparedness.
Collaborative Data Sharing:
Establishing collaborative networks and data-sharing protocols among research institutions and meteorological agencies can enrich data quality and lead to more robust prediction models.
Cloudburst events, characterized by sudden, intense rainfall, pose severe threats to hilly regions, causing flash floods, landslides, and debris flow. Recent incidents highlight the urgent need for improved prediction systems. This research aims to enhance public safety by developing a robust cloudburst prediction system, utilizing deep learning techniques with mixed data inputs, combining tabular and image data. The motivation arises from the limitations of traditional prediction models, emphasizing the importance of timely and accurate warnings.
The methodology encompasses data preparation, preprocessing, splitting, model architecture, training, evaluation, and alert generation. This comprehensive approach integrates image and tabular data, yielding a strong predictive framework. The future scope includes direct data fetching via APIs, serverless computing for continuous monitoring, widespread information accessibility, and collaborative data sharing, promising improvements in cloudburst prediction and disaster preparedness.