Publication Details
This project is part of a broader exploration of deploying YOLOv5m for TensorFlow Lite.
View the publication here: GitHub Repository
Abstract
This project presents a custom object detection system utilizing YOLOv5m, fine-tuned to accurately identify rocks and bags. The model is optimized for real-time inference on edge devices and has been successfully integrated into an Android application running on a Pixel 7a smartphone. By converting the PyTorch-trained model to TensorFlow Lite, the system achieves efficient, low-latency performance suitable for mobile deployment. The project emphasizes user flexibility, allowing customization of the detection pipeline and application to accommodate various use cases. While not specifically designed for autonomous driving, the system explores challenges pertinent to object misidentification in such contexts, enhancing decision-making and safety by distinguishing between similar objects like rocks and bags.

Introduction
Object detection is a critical task in computer vision, enabling machines to identify and localize objects within images or video frames. It has wide-ranging applications, including autonomous driving, security systems, and mobile applications. However, deploying high-performance object detection models on resource-constrained devices, such as smartphones, presents unique challenges, particularly in balancing accuracy, speed, and efficiency. This project addresses these challenges by leveraging YOLOv5m, a state-of-the-art object detection model, fine-tuned to detect two visually distinct but potentially confusing objects: bags and rocks.
The model is trained on a custom dataset of road images, specifically captured and annotated to optimize its performance for real-world scenarios. By employing techniques such as model quantization and conversion to TensorFlow Lite, the trained YOLOv5m model is optimized for real-time inference on mobile devices. The resulting system has been integrated into an Android application, enabling users to detect and differentiate between bags and rocks on the road. This setup provides a practical proof-of-concept for deploying advanced computer vision models in mobile environments, showcasing the feasibility of running edge AI solutions without relying on cloud processing.
The primary motivation for this project lies in its potential applications in safety-critical scenarios, such as enhancing the decision-making process in autonomous systems. By addressing the challenge of distinguishing between visually similar objects in constrained environments, this work contributes to the broader field of mobile computer vision. Furthermore, the project's open-source nature aims to provide researchers and developers with a robust framework to explore and extend the deployment of object detection models on edge devices.
Methodology
Data Collection and Preprocessing
The dataset was collected by photographing bags and rocks in diverse environments, including indoors, roads, grass, concrete, and various lighting conditions such as incandescent, outdoor sunlight, golden hour, overcast, and rain. To reduce false positives, background images without objects were also captured, including scenes with grass, roads, indoor settings, and leaves. The dataset comprises 2,833 images, split into 2,499 for training, 167 for testing, and 167 for validation. The splits were randomized using a custom Python script.
Annotations were performed using the LabelImg tool, with labels formatted for YOLOv5. To standardize the dataset, images were cropped into square dimensions while maintaining their original DPI, using a custom Python script.
Model Selection and Training
The YOLOv5m model was selected after evaluating YOLOv5s and YOLOv5l. YOLOv5s lacked the desired accuracy, while YOLOv5l was too slow for inference on edge devices. Images were resized to 320x320 pixels for training, with bounding boxes automatically adjusted. Training was conducted in PyTorch, leveraging YOLOv5’s built-in normalization, data augmentation, and early stopping features. Data augmentation included horizontal flipping, HSV color adjustment, scaling, translation, and mosaic augmentation.
Training was conducted for 170 explicit epochs with a batch size of 130, maximizing the available 12GB of RAM on an RTX 4070 GPU. Default hyperparameters from YOLOv5m’s hyp.scratch-low.yaml configuration were used, including:
Learning rate: 0.01
Momentum: 0.937
Weight decay: 0.0005
The default optimizer (SGD) and loss functions (CIoU for box regression, BCE for objectness and classification) were employed.
Model Optimization and Deployment
The trained YOLOv5m model was quantized to FP16 to enable efficient inference on resource-constrained devices. Deployment to an Android app involved converting the PyTorch model to the ONNX format and then to TensorFlow Lite (TFLite). The TFLite Interpreter was integrated into the Android app to enable real-time inference.
Camera integration allowed the app to process video streams frame-by-frame, performing resizing and normalization for inference and rendering bounding boxes and labels in real-time. The app leveraged an open-source template from TensorFlow for Android.
Results
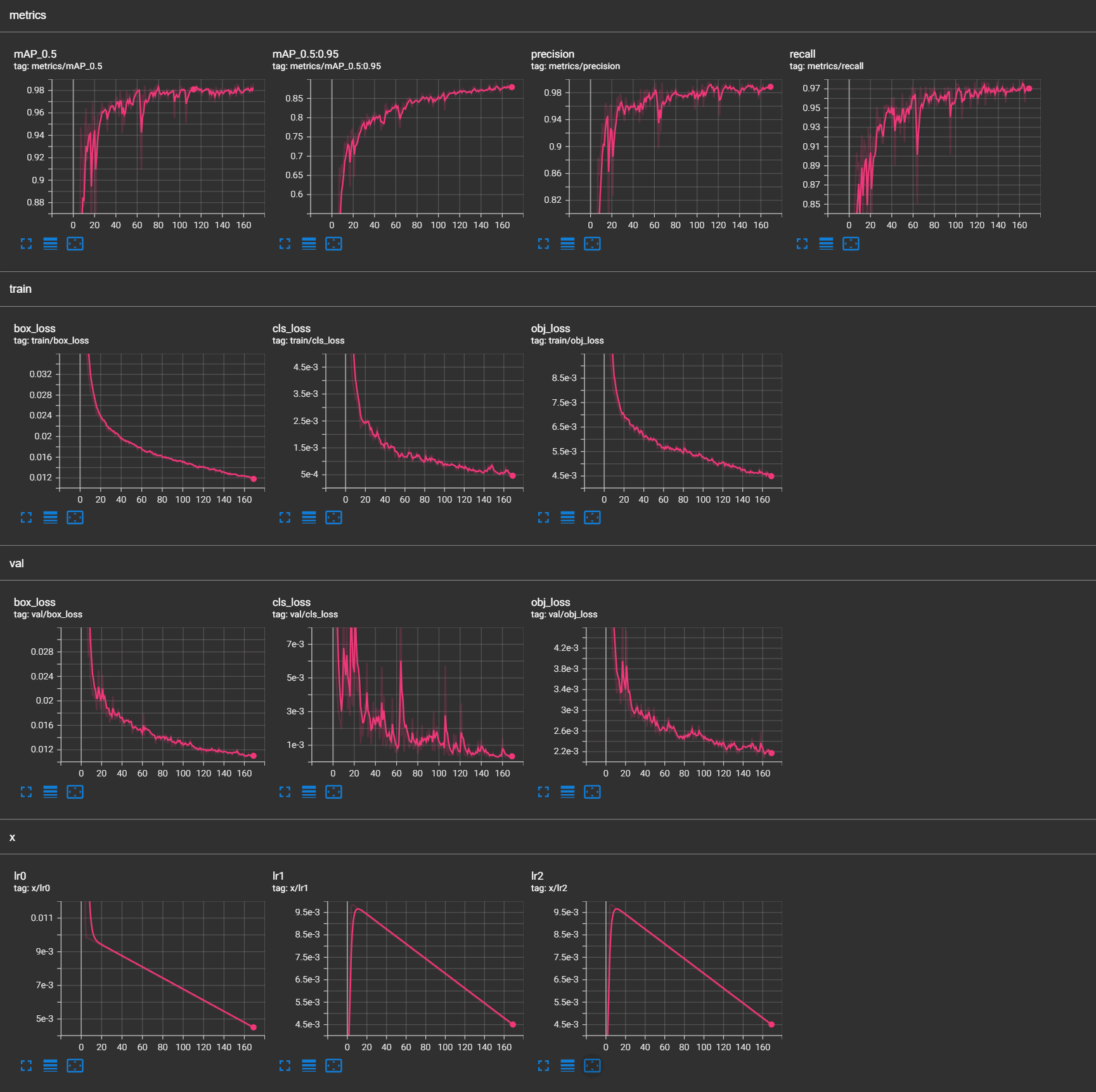
Quantitative Performance
The model achieved high accuracy metrics, demonstrating strong performance across a range of evaluation criteria:
Mean Average Precision (mAP):
mAP@0.5: ~0.982
mAP@0.5
Precision: >0.98, indicating a low false-positive rate.
Recall: ~0.97, highlighting effective detection of objects.
Training Loss Analysis:
Box Loss: ~0.012
Classification Loss: ~5e-4
Objectness Loss: ~4.5e-3
Validation Loss Analysis:
Box Loss: <0.012
Classification Loss: <1e-3
Objectness Loss: <2.2e-3
The low losses and high metrics indicate the model’s generalization ability, with no signs of overfitting.
Real-World Testing
The model was tested on an Android smartphone under various environmental and lighting conditions:
Device: Android smartphone
Testing Scenarios: Real-time detection in indoor and outdoor settings, including roads and grass, under daylight and artificial light.
Performance: The app displayed bounding boxes and labels in real-time, confirming its practical usability and robustness.
Comparative Analysis
Although direct comparisons with other models are not explicitly documented, the high mAP scores and low losses position this model competitively alongside state-of-the-art architectures like EfficientDet and Faster R-CNN. Its balance of precision, recall, and speed makes it well-suited for edge applications.
Experiments
Including background-only images in the training dataset proved effective in reducing the false positive (FP) rate. Background images, such as those depicting grass, roads, indoor scenes, and leaves without target objects (bags and rocks), helped the model learn to ignore non-object features and focus on relevant detections. This addition enhanced the model's ability to differentiate between objects and environmental noise, significantly reducing misclassifications. As a result, the precision metric improved from approximately 0.93 to over 0.98, particularly in complex scenarios like outdoor environments with cluttered backgrounds. This approach highlights the value of incorporating diverse and balanced datasets in optimizing object detection performance.
Conclusion
This project successfully demonstrates the development, training, optimization, and deployment of an object detection model capable of identifying bags and rocks in diverse real-world scenarios. By leveraging YOLOv5m, the model achieves a balance between accuracy and inference speed, making it suitable for deployment on resource-constrained edge devices. The inclusion of background-only images in the dataset was a critical factor in reducing false positives, enhancing the model’s precision and robustness in complex environments.
The deployment to an Android application highlights the practicality of the solution, showcasing real-time inference with TensorFlow Lite. The achieved metrics, including a high mAP of ~0.982 and low training and validation losses, underscore the model’s strong generalization ability. This project not only provides a scalable and efficient solution for object detection but also serves as a framework for future developments in edge AI applications, demonstrating how state-of-the-art machine learning models can be adapted to meet real-world constraints and requirements.