
Motivation: Why Causal AI?
In the world of data analysis, we often find ourselves leaning heavily on statistical correlations. After all, correlation is the foundation of many predictive models, from simple regressions to complex machine learning algorithms. These models, using correlations between variables, can deliver astonishingly accurate predictions about unseen data. However, correlation alone is not enough to understand why something happens. And this is where things get tricky.
The Chocolate and Nobel Prize Case
Consider the intriguing case of chocolate consumption and Nobel Prizes. A study published in the New England Journal of Medicine once claimed that higher per capita chocolate consumption in a country correlates with a greater number of Nobel laureates per 10 million people. The authors speculated that chocolate, rich in cocoa flavanols, might boost cognitive function, potentially enhancing creativity and intellectual performance—the kind of qualities associated with winning a Nobel Prize.
On the surface, this seems exciting and plausible, especially with a strong correlation coefficient (which is quite strong) between chocolate consumption and Nobel laureates. Could it be that indulging in chocolate is the secret sauce for genius? If this were true, chocolate lovers everywhere might rejoice, while countries eager for international recognition might start encouraging their citizens to consume more chocolate.
But let’s pause for a moment. Is chocolate really making people smarter? Or is there something deeper at play?
.jpg?Expires=1781570087&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=P0J3YKI8ZO4pCRUyawh723H9-Bi2LC9ruztzpp~P0-AIicIAmkjnchSxWEVgDGdA4vAw9IV4JxTQpEcrpMaUoacn0IU~IHbXgyIaihvWj69PrzkrhK7ijRdVL8MSXqT1RBn-O4tUaczY8ytnid8~6fYTzP2XtgUe6Cqc5B1VQprK462tJj8gcpwkr1OquTx2q4IvCBKQxoMvCqOPOfc7tVGXaznyh5nA6fK80QzoIY9G1jzSnIuk3mGeC2q0CV877IjP9vhAJjTEcT8MAIF6NUyOSSVe80iCr1l9XaWKCiWvlwxFhVN-PdHw4rUwxSEU1Aor4LKsVb4scc7gV8rXzg__)
This graph comes from an article in the New England Journal of Medicine, by Frank H. Messereli, M.D.
https://www.biostat.jhsph.edu/courses/bio621/misc/Chocolate%20consumption%20cognitive%20function%20and%20nobel%20laurates%20(NEJM).pdf
The Pitfall of Correlation
This example is a perfect illustration of how relying on correlation alone can lead to misleading, even absurd, conclusions. What the chocolate-Nobel correlation doesn't account for is the possibility of a third factor—a hidden common cause driving both high chocolate consumption and the number of Nobel laureates.
In this case, that hidden factor is likely the standard of living or Gross Domestic Product (GDP). Wealthier countries with higher standards of living can afford more luxury goods like chocolate, while also investing heavily in education, research, and scientific infrastructure—creating more Nobel-caliber individuals. This means the relationship between chocolate and Nobel prizes isn’t direct. It's confounded by the standard of living: a country’s prosperity leads to both higher chocolate consumption and more Nobel laureates.
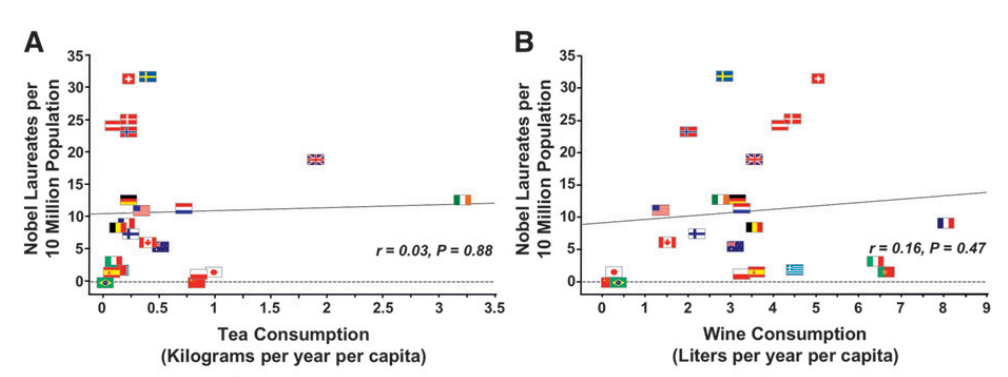
Further evidence refutes the idea that cocoa flavanols in chocolate are boosting Nobel laureate success. If cocoa flavanols were the true cause of enhanced cognitive function, we would expect similar correlations with other flavanol-rich foods and drinks, such as tea and wine. Yet, when researchers looked at these products, they found no significant correlation between their consumption and Nobel laureates in the same 23 countries. This strongly suggests that the chocolate-Nobel relationship is merely coincidental.
In other words, chocolate consumption and Nobel laureates are correlated, but not because one causes the other. They’re both influenced by a third variable—wealth. This kind of spurious correlation is all too common in statistical analysis and can lead to wildly inaccurate conclusions if we're not careful.
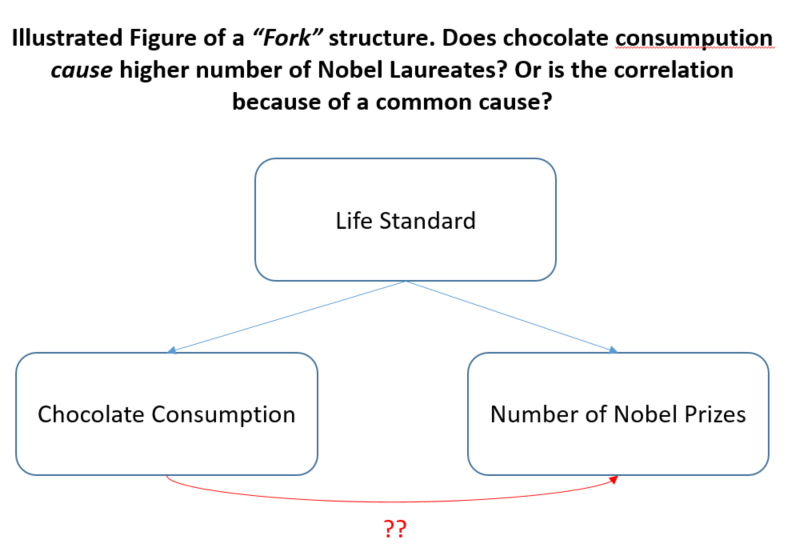
The Promise of Causal AI
This is where causal AI steps in to save the day. Unlike traditional methods that focus solely on correlations, causal AI aims to discover and model the actual cause-and-effect relationships between variables. By understanding the true drivers behind outcomes, causal AI can help avoid the pitfalls of drawing conclusions from coincidental correlations.
In the chocolate-Nobel example, a causal AI approach would start by modeling the potential relationships between variables like chocolate consumption, Nobel laureates, and GDP. By using techniques like conditioning on confounders (in this case, controlling for GDP) or employing causal discovery algorithms, we can determine whether chocolate consumption has any independent causal effect on the number of Nobel laureates. Spoiler alert: it doesn’t.
To distinguish correlation from causation, causal AI leverages tools like Directed Acyclic Graphs (DAGs) to represent relationships between variables and employs techniques such as the backdoor criterion to block spurious pathways that might falsely suggest causality. In our example, a DAG would clearly show that GDP influences both chocolate consumption and Nobel laureates, while there’s no direct link between the two.
The chocolate-Nobel study is a humorous yet serious reminder of the limitations of correlation-based analysis. The same mistake happens in fields as diverse as medicine, economics, marketing, and social sciences. For example, studies that show strong correlations between health outcomes and certain behaviors or lifestyle factors often fail to account for hidden confounders—leading to ineffective or even harmful recommendations.
If we rely on statistical association alone, we risk making decisions based on flawed reasoning. A company might invest in marketing strategies that don’t work, a doctor might recommend treatments that have no effect, or a policymaker might create initiatives that miss the true cause of the problem they’re trying to solve. Causal AI helps us move past these limitations, enabling us to uncover why things happen, not just what happens.
The Fundamental Problem of Causal Inference
Let’s dive into one of the biggest challenges in understanding cause and effect: the fundamental problem of causal inference. To keep it simple, let's use an example about machine maintenance. Imagine you're a technician, and you’re trying to figure out whether doing maintenance on a faulty machine will prevent it from breaking down.
Now, here’s the challenge: to determine if maintenance really prevents failure, you need to compare two possible outcomes for the same machine under the same conditions:
- Y(0): What would happen if you didn’t perform the maintenance?
- Y(1): What would happen if you did perform the maintenance?
In theory, if the machine fails without maintenance (Y(0)) but works perfectly with maintenance (Y(1)), we can confidently say that maintenance prevents failure.

But here’s the catch:
You **can’t observe both outcomes at the same time** for the same machine! You can either:- Perform the maintenance and observe Y(1) (machine outcome with maintenance),
- Or skip the maintenance and observe Y(0) (machine outcome without maintenance).
You can’t magically see what would have happened in the alternate reality where you didn’t choose the path you took. This is the core of the fundamental problem of causal inference—you’re always dealing with potential outcomes that are not observable at the same time. You can’t rewind time, give the machine maintenance, and then also go back and observe what would have happened without it.
So, how can we solve this?
Causal inference methods step in here by using assumptions and techniques to get around this fundamental problem. By making clever use of data and certain assumptions, we can simulate what might have happened in the absence of a treatment (like maintenance) and infer causality. Some techniques include:
- Randomization: If you randomly assign some machines to receive maintenance and others not, and compare the outcomes, you can estimate the causal effect of maintenance.
- Conditioning on Confounders: If you know other factors (like machine age or usage) that affect the likelihood of failure, you can account for those and better isolate the true effect of maintenance.
Exciting, right? By leveraging these assumptions and techniques, causal inference helps us answer the “what if” questions—giving us a way to uncover cause-and-effect relationships, even though we can't observe all potential outcomes simultaneously!
In the next section, we'll give examples on how conditioning on confounders can help us solve the problem.
Conditioning on Confounders
Now that we understand the fundamental problem of causal inference, let’s dive into one of the most powerful tools for overcoming it:
conditioning on confounders.
Confounders are variables that affect both the treatment and the outcome. In our previous example, think of confounders as factors like machine age or frequency of use, which influence both the decision to perform maintenance and the likelihood of machine failure. Ignoring these confounders can lead to misleading conclusions about whether maintenance actually prevents failure.
Example: The Case of Machine Age
Let’s build on our machine maintenance example. Imagine that older machines are more likely to break down and are also more likely to receive maintenance because they’ve been around longer. If you don’t account for machine age, you might see a strong correlation between maintenance and breakdowns and mistakenly conclude that maintenance causes breakdowns, when in reality, older machines are more likely to break down regardless.
By conditioning on machine age (i.e., controlling for it in the analysis), we can isolate the true effect of maintenance on breakdowns. In this scenario, the confounder (machine age) would be held constant, and we’d compare the likelihood of breakdowns between machines of the same age that did or did not receive maintenance. This allows us to separate the effect of maintenance from the effect of machine age.
How Conditioning on Confounders Works
To illustrate this in a simpler way:
- Suppose you have two groups of machines: one group gets maintenance and the other doesn't.
- Without considering age, you might see that machines with maintenance tend to break down more often, but this could be because older machines are both more likely to get maintenance and more likely to break down.
- Once you control for age, comparing only machines of the same age, you can see the true effect of maintenance on machine breakdowns.
By conditioning on the confounder (machine age), you remove the misleading statistical association and reveal the real causal relationship between maintenance and machine failure.
Beyond the Machine Example: Everyday Confounders
This idea of conditioning on confounders applies to many everyday situations. For example:
- Health Studies: You might see a correlation between drinking coffee and heart disease, but if you don’t account for smoking (a common confounder that is associated with both coffee consumption and heart disease), you could incorrectly conclude that coffee causes heart disease.
- Marketing: A company might observe that users who see an online ad are more likely to purchase a product. But if prior brand loyalty is a confounder, it’s possible that loyal customers are both more likely to see the ad and more likely to buy, leading to a misleading conclusion about the ad’s effectiveness.
Why It's Important
Conditioning on confounders helps us to untangle correlation from causation. Without it, we might fall into the trap of interpreting spurious associations as real, leading to poor decisions. By carefully identifying and controlling for confounders, we get closer to answering the big question: Does X cause Y?
The Fork and Backdoor Paths
Let’s get even more specific. What we have in our machine maintenance example is something called a fork. Why is it called a fork? Because it looks just like one! Imagine a simple graph where machine age (the confounder) points to both maintenance and breakdown—these arrows form the prongs of a fork.
- Machine Age affects both Maintenance and Breakdowns.
- If you don’t account for machine age, you open up a backdoor path from maintenance to breakdowns, making it seem like maintenance is causing breakdowns, when in reality, both are influenced by machine age.
This backdoor path is essentially a hidden road leading to false conclusions. By conditioning on the confounder (machine age), you block this path and reveal the true effect of maintenance on breakdowns. In this way, you remove the misleading correlation and can clearly see the true causal relationship.
Another Example: The Job, Income, and Free Time Dilemma
Let’s look at a common scenario—work-life balance. Imagine you're trying to study the effect of working more hours on happiness. Naturally, you’d expect that working more hours might reduce your happiness because it leaves less time for relaxation. But there’s a third factor involved: income.
- Both working more hours and happiness affect income. Working more hours increases your income, and being happier might lead to better job performance, which can also increase your income.
- If you condition on income (say, by only looking at people who earn a certain salary), you might mistakenly think that working more hours leads to less happiness. That’s because people with high income may work fewer hours but still be happy due to their overall financial security. This creates a collider where both happiness and hours worked impact income, leading to a spurious negative relationship between working hours and happiness when, in fact, there may be no direct relationship at all.
To fix this, you would need to uncondition on income—meaning you shouldn’t restrict your analysis to a certain income bracket. Instead, you should focus directly on the relationship between working more hours and happiness to see the true effect.
Why Does This Matter?
These examples show how conditioning or unconditioning on certain variables can completely change our understanding of relationships between variables. In the job example, by mistakenly conditioning on income, you might conclude that working more hours always reduces happiness, when in reality, other factors like job satisfaction or financial goals might play a role.
By correctly identifying when to condition (like blocking the backdoor path from age in the machine maintenance example) or when to uncondition (like ignoring income in the job example), we can accurately reveal the true causal relationships hidden in our data.
The Power of Causal Graphs
Imagine if you had a graph that mapped out all the relationships between variables in your life—how work hours influence happiness, how happiness affects income, and even how things like personal time or job satisfaction fit in. By using causal inference, you can identify which factors you need to control for (condition on) and which ones you should leave alone to uncover the real story.
Causal inference techniques help you go beyond surface-level correlations and get to the root causes of what’s really happening. Whether it’s work-life balance or any other scenario, mastering these techniques allows you to make better decisions based on true cause and effect.
In the next sections, we’ll explore more tools and techniques for mapping out these relationships and applying them to your own data. With causal inference, you can become the detective of your own data-driven life!
Causal Discovery Algorithms: Building a Causal Graph from Scratch
Imagine you’re starting from scratch with no prior knowledge of how variables in your data interact. How do you go about building a causal graph that maps out the relationships? This is where causal discovery algorithms come into play. These algorithms use statistical patterns in the data to automatically build a causal graph—a map of how variables influence each other.
Examples of Causal Discovery Algorithms
-
PC Algorithm: This algorithm starts by identifying all the correlations between variables and then systematically removes paths that don’t indicate direct causal relationships. It's like trying to untangle a web of relationships, slowly pruning away connections that don’t hold up under scrutiny.
-
LiNGAM: LiNGAM (Linear Non-Gaussian Acyclic Model) goes a step further by assuming that relationships between variables are linear and that the data doesn't follow the typical bell-curve (Gaussian) distribution. It works great in situations where data might have weird outliers or skewed distributions, helping you identify true causes from effects.
Both algorithms are powerful because they help you create a causal graph when you have little or no prior knowledge of the relationships between your variables.
Why Having a Causal Graph Is Even Better
But what if you already know how your variables are connected? Let’s say you have a clear understanding of your domain, like knowing the relationship between advertising spend and sales in a business. This is where things get even more exciting.
If you already have a graph—whether from expert knowledge or previous studies—you can use tools like DoWhy to test whether the relationships in your data are indeed causal. Instead of building the graph from scratch, you start with your known graph and then ask specific questions like:
- Does increased advertising spend really cause higher sales, or is there a hidden factor (like seasonality) affecting both?
DoWhy tries to block backdoor paths—those misleading associations—based on your given graph, ensuring you’re seeing true causal effects. You can even give weights to different variables to see how much each one impacts your target variable. For example:
- How much does advertising spend affect sales?
- Does the effect change if you also account for competitor promotions?
The Power of Combining Discovery with Expert Knowledge
While causal discovery algorithms like PC and LiNGAM help when you’re starting from scratch, having domain knowledge and a well-defined graph is even more powerful. You can use causal inference techniques to not only validate your graph but also quantify the impact of different variables, giving you deeper insights into the real drivers of outcomes in your data.
In short, if you have a graph, you can use tools like DoWhy to fine-tune your understanding and reveal true cause-and-effect relationships, ensuring your decisions are based on solid causal insights. And that’s where the magic happens—knowing not just what happens, but why it happens!
The MPG Dataset
Imagine you’re an engineer tasked with designing the next generation of fuel-efficient cars. You’ve been handed the MPG dataset, a treasure trove of information about cars from the past, and your goal is to uncover the hidden secrets behind what makes a car more fuel efficient. What’s going to give you the best fuel mileage—less weight? More horsepower? Or maybe it’s something deeper, like engine displacement?
The dataset has six key features:
- MPG: Your golden metric, representing miles per gallon, the crown jewel of fuel efficiency.
- Cylinders: The number of cylinders in the engine—fewer might mean better fuel economy, right?
- Displacement: A measure of the engine's capacity—bigger engines pack more punch, but do they guzzle more fuel?
- Horsepower: How much raw power the engine can generate—does more power come at the cost of fuel efficiency?
- Weight: Heavier cars might be more stable, but surely they burn through fuel faster.
- Acceleration: How quickly can a car go from 0 to 60 mph? But at what cost to MPG?
You’ve got a hunch, but you need more than intuition. So, you turn to the DirectLiNGAM algorithm, a tool designed to uncover the hidden causal relationships between these variables. You’re not just looking for correlations—you want to know which factors cause a car to be more or less fuel efficient.
To begin with, we load the data as follows:
from dowhy import CausalModel import numpy as np import pandas as pd import networkx as nx import matplotlib.pyplot as plt from lingam import DirectLiNGAM from sklearn.preprocessing import StandardScaler
data_mpg = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data-original', delim_whitespace=True, header=None, names = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model year', 'origin', 'car name']) data_mpg.dropna(inplace=True) #drop unnecessary columns data_mpg.drop(['model year', 'origin', 'car name'], axis=1, inplace=True)
We then apply a standard scaler to all the data. This step standardizes the data, bringing each feature to the same scale, thus preventing any bias that may arise from the differences in magnitude across the features.
#standard scaling from sklearn.preprocessing import StandardScaler scaler = StandardScaler() data_mpg_scaled = scaler.fit_transform(data_mpg) data_mpg_scaled = pd.DataFrame(data_mpg_scaled, columns=data_mpg.columns) data_mpg_scaled.head()
Unveiling the Causal Structure: The Graph
You feed the MPG dataset into the LiNGAM algorithm, and the result is like pulling back the curtain on a complex mechanical system. The algorithm spits out a causal graph—a web of connections showing how each factor influences the others. But to keep things simple, you focus only on the variables that directly or indirectly affect your main goal: MPG.
# Apply DirectLiNGAM algorithm model = DirectLiNGAM() model.fit(data_mpg_scaled) # Get the adjacency matrix (causal structure) adj_matrix = model.adjacency_matrix_ # Define labels for the graph nodes labels = [f'{col}' for i, col in enumerate(data_mpg_scaled.columns)] # Create a NetworkX graph G = nx.DiGraph() # Add edges based on the adjacency matrix for i in range(adj_matrix.shape[0]): for j in range(adj_matrix.shape[1]): if adj_matrix[i, j] != 0: # There is a causal relationship from i to j G.add_edge(labels[i], labels[j]) # Define the target variable (e.g., 'mpg') target = 'mpg' # Find all ancestors of the target node ancestors = nx.ancestors(G, target) # Create a subgraph containing only the target node, its ancestors, and their outgoing edges subgraph_nodes = ancestors | {target} subgraph = G.subgraph(subgraph_nodes) # Visualize the subgraph plt.figure(figsize=(15, 10)) pos = nx.spring_layout(subgraph, k=0.5) # Adjust k to control node spacing # Draw the subgraph without edge weights nx.draw(subgraph, pos, with_labels=True, node_size=700, node_color='lightblue', arrows=True, font_size=10) plt.title(f'Root Cause Analysis for {target} and its Ancestors') plt.show()
The graph looks like the following:
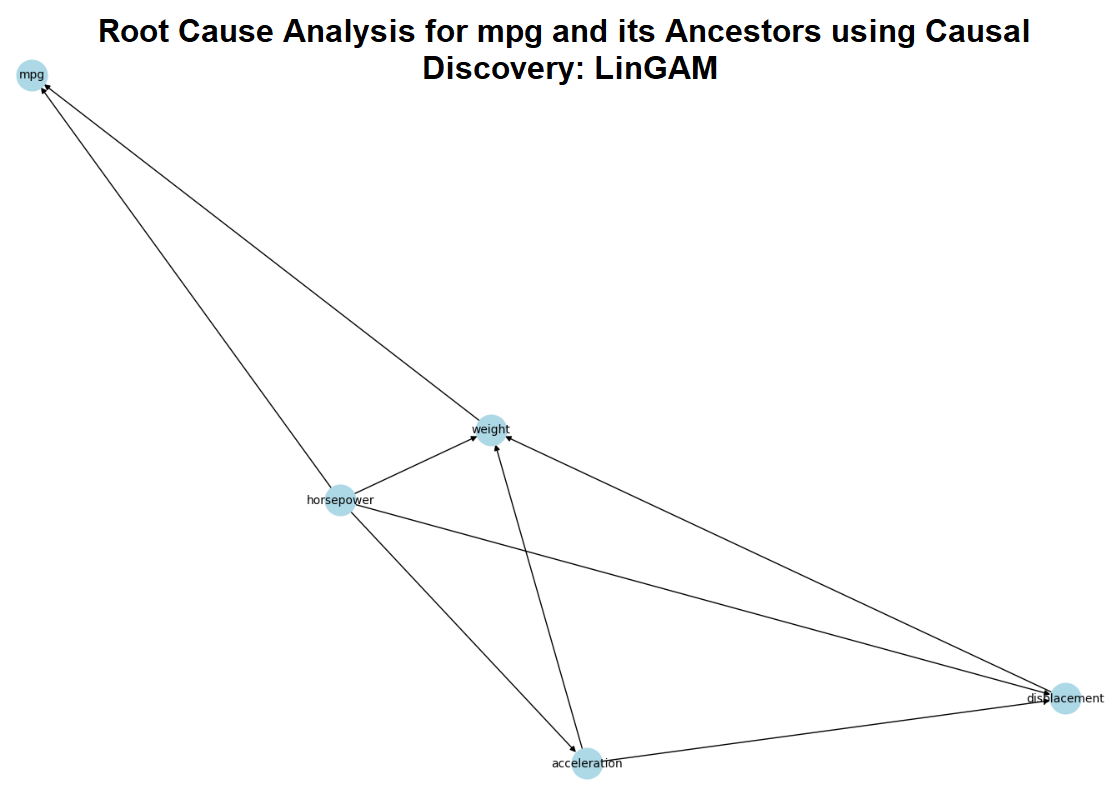
The graph reveals the following:
-
Horsepower Directly Affects Weight:
- This is an interesting result. Horsepower affects weight, which means that more powerful engines often lead to heavier cars. This is because stronger engines often require sturdier, more robust builds to handle their power, thus increasing weight. This relationship reflects how design choices are closely linked in vehicle manufacturing.
-
Weight and Horsepower Drive MPG:
- Weight directly impacts MPG, which makes sense since heavier cars require more energy to move, lowering fuel efficiency.
- Horsepower also directly affects MPG. More horsepower means more power, but it comes at the cost of fuel consumption. This direct impact is intuitive: faster, more powerful cars tend to burn more fuel.
-
Acceleration is Affected by Horsepower:
- Acceleration is influenced by horsepower. This means that how quickly a car can accelerate is largely determined by how powerful the engine is. Heavier cars may still accelerate quickly if they have sufficient horsepower, showing that weight does not directly slow down acceleration as long as there's enough engine power.
-
Displacement’s Indirect Impact Through Weight:
- Displacement, the engine’s size, does not directly influence MPG but has an indirect effect through weight. Larger engines typically increase the car’s weight, which in turn lowers MPG. This indirect relationship is key, as it highlights how multiple factors work together to influence fuel efficiency.
-
Horse Power affects Weight:
The relationship between horsepower affecting weight might be becuase cars with more horsepower tend to have larger, more powerful engines, and these engines are often physically heavier. More power requires a larger, more robust engine structure, which in turn increases the overall weight of the car.
In essence, cars with more horsepower need bigger engines to generate that power, and bigger engines mean more weight. This perfectly fits the real-world dynamics of vehicle design.
Unveiling the Drivers of MPG
Why a Predefined Causal Graph is Even Better?
As powerful as LiNGAM is, imagine if you already knew the relationships between these variables. If you could build a causal graph based on domain knowledge—like knowing that displacement influences weight, or that horsepower affects MPG—you could dig even deeper into the strenght of the causal effects these relationships.
Enter DoWhy—a library that lets you take an existing causal graph and ask the important questions:
- Does more horsepower really decrease MPG?
- How much does reducing weight improve fuel efficiency?
- Could an unexpected factor, like acceleration, be skewing the results?
With a predefined graph, DoWhy helps you block backdoor paths—those sneaky correlations that trick you into thinking something is causal when it’s not. You can also assign weights to variables to see how much each one truly affects MPG. For example, if you want to maximize fuel efficiency, you might focus on reducing weight and managing horsepower.
We started with our simple goal—understanding what makes a car more or less fuel-efficient. But instead of relying on simple correlations, we wanted to uncover the true causal relationships between different car features and MPG (miles per gallon), the key measure of fuel efficiency.
Building the Causal Graph
First, we constructed a causal graph using common knowledge. Here are some key relationships from the graph:
- Cylinders → Displacement: More cylinders often mean a bigger engine, which increases displacement (the engine's total capacity).
- Horsepower → Weight: Cars with higher horsepower tend to have bigger engines, which makes the car heavier.
- Horsepower → MPG: More power comes at a cost—higher horsepower generally decreases MPG since powerful engines consume more fuel.
- Acceleration → MPG: Fast acceleration can also decrease MPG, as cars designed for speed often prioritize performance over efficiency.
causal_graph = """ digraph { cylinders -> displacement; cylinders -> horsepower; displacement -> horsepower; horsepower -> weight; horsepower -> mpg; weight -> mpg; displacement -> mpg; acceleration -> mpg; } """
With this graph, we mapped out how different car features influence MPG both directly and indirectly.
Applying Causal Inference
Next, we applied causal inference to test the impact of each variable on MPG. We used each car feature (e.g., cylinders, displacement, horsepower) as a treatment variable that we want to know its causal effect and estimated its causal effect on fuel efficiency using backdoor linear regression. This method allowed us to isolate the effect of each variable while accounting for hidden confounders—those pesky variables that might influence both the treatment and the outcome. The code uses the doWhy library as follows:
# Define list of treatment variables (all except 'mpg') treatment_variables = ['cylinders', 'displacement', 'horsepower', 'weight', 'acceleration'] # Dictionary to store causal estimates causal_estimates = {} # Loop over each treatment variable to estimate its causal effect on 'mpg' for treatment in treatment_variables: # Create a causal model for each treatment model = CausalModel( data=data_mpg_scaled, treatment=treatment, outcome="mpg", graph=causal_graph ) # Identify the causal effect identified_estimand = model.identify_effect() # Estimate the causal effect using linear regression estimate = model.estimate_effect(identified_estimand, method_name="backdoor.linear_regression") # Store the estimate in the dictionary causal_estimates[treatment] = estimate.value
The Results: Causal Estimates of Car Features on MPG
The result? A clear picture of which car features have the greatest impact on MPG. Below is the code that plots a graph showing the causal estimates for each feature:
# Convert causal estimates to DataFrame df_causal_estimates = pd.DataFrame(list(causal_estimates.items()), columns=['Treatment', 'Causal Estimate']) # Sort the DataFrame by the causal estimate in descending order df_causal_estimates = df_causal_estimates.sort_values(by='Causal Estimate', ascending=False) # Plot the sorted causal estimates plt.figure(figsize=(10, 8)) plt.barh(df_causal_estimates['Treatment'], df_causal_estimates['Causal Estimate'], color='skyblue') plt.title('Sorted Causal Estimates on MPG') plt.xlabel('Causal Estimate') plt.ylabel('Treatment') plt.gca().invert_yaxis() # Invert y-axis to show the most important treatments at the top plt.show()
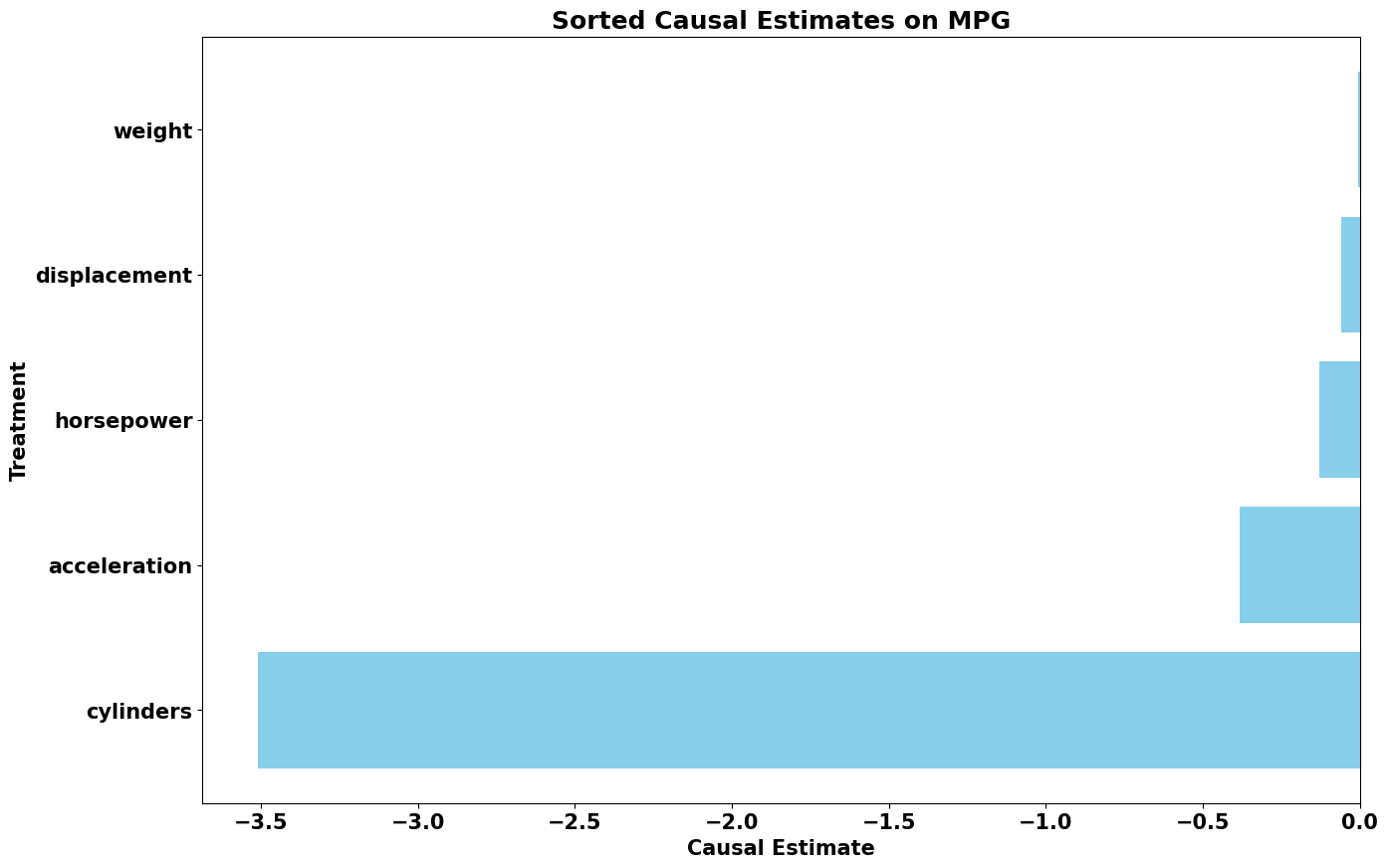
Breakdown of Results:
-
Cylinders: The strongest negative impact on MPG came from cylinders. More cylinders mean bigger, less fuel-efficient engines, which leads to fewer miles per gallon. This aligns perfectly with what we’d expect—a car with more cylinders burns through fuel faster.
-
Horsepower: A similar story for horsepower—more horsepower leads to lower MPG. More powerful engines consume more fuel, prioritizing performance over efficiency.
-
Weight and Displacement: Both variables also negatively affect MPG, but not as strongly as cylinders or horsepower. Weight and displacement are closely related to engine size and power, which indirectly lowers fuel efficiency.
-
Acceleration: Interestingly, acceleration showed a relatively smaller effect compared to other features. While it affects performance, its direct impact on MPG is not as large. The real fuel impact comes from the engine's size and power rather than how fast the car accelerates.
Conclusion: What We Learned
The results confirm that cylinders, horsepower, and weight are the heavy hitters when it comes to reducing MPG. Cars with more cylinders, powerful engines, and heavier designs are less fuel-efficient, while lighter, less powerful cars perform better in terms of miles per gallon.
Through causal inference, we’ve moved beyond simple correlations to uncover the true drivers of fuel efficiency. By understanding the causal impact of these features, car designers, engineers, and even consumers can make more informed decisions about optimizing vehicles for better fuel economy.
Causal inference has shown us why things happen, not just what happens—and that’s where the real power of data lies!
Limitations of Causal AI
While causal AI offers powerful insights into understanding cause-and-effect relationships, it also comes with several limitations and assumptions that need to be carefully considered. These challenges can affect the reliability of the results and must be addressed to avoid drawing incorrect conclusions.
- Assumption of a True and Complete Causal Graph
- Problem: Causal inference methods rely heavily on the accuracy of the causal graph provided as input. The assumption is that the graph is true and complete, meaning it captures all relevant variables and their relationships. However, in reality, it is difficult to ensure that the graph is truly complete.
- Example: If an important factor influencing MPG (e.g., road conditions or driving behavior) is left out of the graph, the causal conclusions could be skewed. Missing variables may lead to incorrect or misleading causal estimates.
- Hidden Confounding Variables
- Problem: Causal AI assumes that no hidden confounders exist—variables that affect both the treatment and the outcome but aren’t captured in the data. Hidden confounders can create spurious associations and lead to incorrect causal conclusions.
- Example: In the MPG dataset, failing to account for driving habits (a confounder that could affect both acceleration and MPG) might lead to the wrong conclusion that acceleration alone is driving changes in MPG.
- Data Quality and Size Requirements
- Problem: Causal inference techniques rely heavily on conditioning on covariates to isolate the causal effect. However, this conditioning can drastically reduce the amount of usable data. The more variables we condition on, the smaller our effective sample size becomes, leading to a loss of statistical power.
- Example: If we condition on multiple variables (like weight, horsepower, and acceleration) in our MPG dataset, we may end up with very few cars that fit all the required conditions, making it difficult to draw robust conclusions.
- Dependence on Accurate Conditioning
- Problem: Causal AI methods rely heavily on the strategy of conditioning on the right set of variables to block backdoor paths and isolate true causal relationships. Incorrectly identifying which variables to condition on can result in either overconditioning (leading to biased estimates) or underconditioning (allowing spurious relationships to persist).
- Example: Overconditioning on acceleration might lead to removing the effect of horsepower on MPG, mistakenly assuming acceleration already accounts for it.
- Sensitivity to Model Assumptions
- Problem: Many causal inference techniques, such as linear regression or instrumental variables, depend on certain assumptions about the data (e.g., linearity, no measurement error, independent variables). If these assumptions don’t hold, the results can be biased or misleading.
- Example: If the relationship between horsepower and MPG is non-linear, using a simple linear model might lead to inaccurate causal estimates.
Conclusion
While causal AI provides a robust framework for understanding cause and effect, its effectiveness relies heavily on the quality of the input data, the accuracy of the causal graph, and the validity of the underlying assumptions. As the field continues to evolve, more advanced methods will emerge to overcome these challenges, offering even more reliable and actionable insights.
By combining domain knowledge, high-quality data, and careful validation of assumptions, we can maximize the potential of causal AI and unlock deeper, more reliable insights into the true drivers of outcomes.
References
-
Messerli, F. H. (2012). Chocolate consumption, cognitive function, and Nobel laureates. New England Journal of Medicine, 367(16), 1562–1564. https://doi.org/10.1056/nejmon1211064
-
Maurage, P., Heeren, A., & Pesenti, M. (2013). Does chocolate consumption really boost Nobel Award chances? The peril of over-interpreting correlations in health studies. Journal of Nutrition, 143(6), 931–933. https://doi.org/10.3945/jn.113.174813
-
Pearl, J., Glymour, M., & Jewell, N. P. (2016). Causal Inference in Statistics: A Primer. Wiley. Available at: https://www.datascienceassn.org/sites/default/files/CAUSAL%20INFERENCE%20IN%20STATISTICS.pdf
-
Neal, B. (2020). Introduction to Causal Inference from a Machine Learning Perspective. Available at: https://www.bradyneal.com/Introduction_to_Causal_Inference-Dec17_2020-Neal.pdf
-
Pearl, J. (2009). Causality: Models, Reasoning, and Inference. 2nd edition. Cambridge University Press. DOI: 10.1017/CBO9780511803161
-
Pearl, J., & Mackenzie, D. (2018). The Book of Why: The New Science of Cause and Effect. Basic Books. ISBN: 978-0465097609.
-
DoWhy: A Python Library for Causal Inference: Sharma, M., & Kiciman, E. DoWhy: An End-to-End Library for Causal Inference. Available at: https://github.com/py-why/dowhy