With the proliferation of image-based content across various digital platforms, the demand for automatic image understanding and description has surged. This research presents an Image Captioning System, an approach for leveraging deep learning techniques to generate descriptive captions for images and converting them into speech. The system integrates state-of-the-art Convolutional Neural Networks (CNNs) for image feature extraction and Recurrent Neural Networks (RNNs) or Long Short-term memory (LSTM) for sequence generation. Through extensive training on large-scale image-caption datasets, the model learns to associate visual features with textual descriptions, enabling it to generate semantically meaningful captions for unseen images. This research also aims to explore the power of advanced neural network architectures in recognizing and solving the challenges of image understanding and natural language generation like attention mechanisms.
Introduction
Image captioning is the task of generating descriptions of images in natural language. It involves both the concepts of image processing and also natural language generation. It is a very pressing topic in current world and is a part of research to give machines the ability to understand and think like humans, and vital as the volume of digital media is growing rapidly. Generic object detection and classification models do not provide description of the objects within the image, but only specify the presence of various object in the image.
This task requires the use of a mixture of deep learning tasks, including convolutional neural networks (CNN) to process images and Recurrent neural networks (RNN) or long short term memory (LSTM) for processing corresponding captions. Here we can implement various pretrained algorithms like VGG16 for processing images because as these networks have already been trained on numerous images for object detection task and do not need any further training, alternatively we can build our own LSTM network to accomplish the same which will require a little longer training time.
Model Architecture
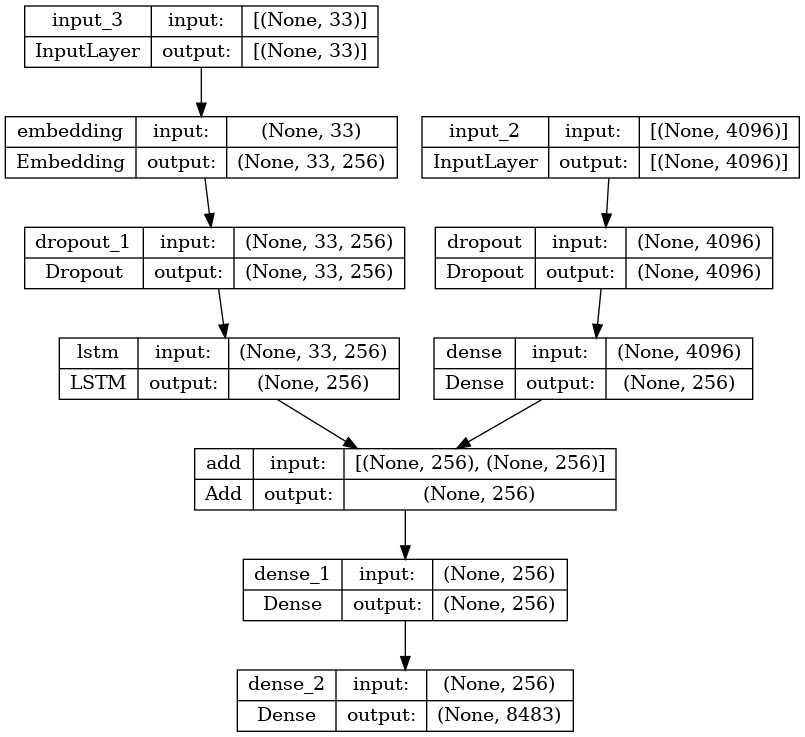
The input for this task would be an image which will then be processed by VGG16 model which will convert the image into corresponding embeddings, then these output embeddings are passed to an LSTM network with attention which then transforms these image embeddings into corresponding captions.
and the images are loaded into numpy arrays and resized to 224x224x3 size and converted into embeddings by passing them through VGG16 model defined to give output from the fc1 (fully connected layer 1) which outputs vectors of size 4096.
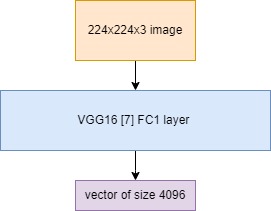
Then the output of 4096 is passes to a dense layer that reduces it into a 256-length vector.
The text is passed through an embedding layer whose input is the length of the maximum length caption (as it is to be passed to tokenizer function) then through an LSTM that outputs a vector of length 256 same as the length of final image vector length.
Then the two, image vector and the captions vector are added together. Then this new vector is passed through a Dense layer(same size as ‘add’ layer) and then through another dense layer that expands to the size of vocabulary (vocab-size) where the activation function to this last dense layer is soft-max to output a one hot encoded vector where the index of the word that is represented by true (1) is the predicted word from the tokenized words.
This diagram illustrates the overall architecture of the model:
.jpg?Expires=1782220938&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=buDMj2eA4Zw1SRJyxMgPgdnh70eAzRPpwhpIhpwMZLSZvx8XwzjNw6ZR0aL2EMiNa~cPOWB8lNOGN9rvFhpyi06REFUwp541ez4qqiMaIqDPXW5wNQT0LGTJ-Z-z2cZRdd8RM9gOmfM7SNiHrv2Ut7jk2qNTAblOrWYwZg2os6kjqhDaa1vrcWZ5SMGjcBkHdUxgCuRYW90CEMQgSf5-YjAq9msoX5KYyafO~I7l3w1aMnxqbdt5ooT57EZZRbvjj3prp0sXjCzIbs1kCDA5E-nq3286xlhTECtp~NE-m3wFKD4lNdddWRtI3fBQN3xtvfNFSl1CsSZVrOg2SsMYAg__)
The architecture designed in Tensorflow:
I have employed teacher forcing technique where instead of feeding the outputs of previous timestep to the LSTM we feed the actual output for the previous timestep. The main advantage of using such an approach is that it reduces the training time. And one precaution to be employed during employing this process is that during inference or testing we do not actually have the actual output to feed to the model therefore we use the previous stage output as the input to the present timestep.
.jpg?Expires=1782220938&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=mg9ZQ5fMuSWTZ4dAJlmAqIbiIVDMWIq7JLfZAteHOSPYHY1Gy1tyrP8kuRj-9MmB~OWP5yFB3OxNzfWVSwUxD29P7-aO8j6CO7cfoRNrcoHzdsvnq1pBddqj5KSrQe5UT9ZUYYMKtQjb3w1a1wwaZBfifsTmUvc3uwCn7p9OW0sOx3247BLZ-89OuaUKmTMWCqHeTMnacK6NTujq2Qcw012Na-uXPzNM2EU-KEc0dk1ZeutcFJVEdLXSTN9sYfSR2dHL4pb8oZ~Uv-GA5lTOUvm1xBqlxyTjKixni1Y8Shfm-v~N-85DHaqe9AFAWdQdkmoQOvNtedINl0sUw0gJDw__)
Results
The model was trained for 100 epochs, the following BLEU scores were obtained:
BLEU-1: 0.526863
BLEU-2: 0.295591
The model when tested on real world data and generalized well.
Example Results:


Conclusion
The model's ability to accurately translate visual content into descriptive captions in real-time opens up a variety of applications across various domains, including accessible technologies for the visually impaired, content creation automation, and assistive tools for individuals with communication impairments. By providing descriptive interpretations of images in the form of captions, the model enhances accessibility and enriches user experiences in digital environments.